




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
《Hadoop+Spark+Hive租房推荐系统》开题报告
一、研究背景与意义
(一)行业痛点
中国城镇化率突破66%(2024年国家统计局数据),在线租房市场规模达4200亿元(2024年),但传统平台存在三大核心矛盾:
- 信息过载:用户日均浏览房源超50套,有效筛选率不足15%,决策耗时延长2-3倍;
- 供需错配:热门区域房源空置率达18%,新兴区域需求响应滞后;
- 技术瓶颈:85%用户反馈推荐结果与需求偏差超30%,传统单机系统无法处理千万级用户行为数据。
(二)技术价值
- 存储能力:Hadoop HDFS支持PB级数据存储,较传统关系型数据库扩展性提升100倍;
- 计算效率:Spark内存计算使百万级用户行为分析耗时从小时级压缩至分钟级;
- 分析能力:Hive SQL查询可快速提取房源特征(如价格分布、通勤时间)与用户偏好。
(三)社会价值
缓解大城市租房供需矛盾,为新市民提供精准住房解决方案,助力政府优化城市资源配置。
二、国内外研究现状
(一)国外研究进展
- 算法创新:Booking.com采用LSTM模型分析用户历史行为,结合地理位置信息实现动态定价与推荐,准确率达82%;
- 知识图谱应用:Airbnb构建“房源-社区-交通”四层关系网络,通过Neo4j实现路径推理,冷启动场景推荐转化率提升40%;
- 实时处理:Zillow利用Kafka流处理框架实现毫秒级数据采集,支持动态推荐场景。
(二)国内研究进展
- 数据整合:链家、贝壳整合用户行为数据与外部POI数据(如商圈、地铁站),但特征维度仅覆盖10-15个,模型泛化能力不足;
- 语义分析:部分研究引入BERT模型提取房源标题语义特征,但未结合实时上下文信息(如搜索关键词),导致推荐延迟超5秒;
- 混合推荐:58同城采用协同过滤(60%)+内容推荐(30%)+知识图谱(10%)的混合策略,Top-10推荐命中率提升至78%。
(三)现存问题
- 实时性不足:70%系统采用离线批处理模式,无法捕捉用户瞬时需求变化;
- 特征维度单一:仅依赖用户历史行为,忽略外部因素(如天气、节假日)对需求的影响;
- 冷启动问题:新用户/新房源推荐偏差率超35%,缺乏动态权重调整机制。
三、研究目标与内容
(一)研究目标
构建基于Hadoop+Spark+Hive的分布式租房推荐系统,实现以下性能指标:
- 推荐准确率:Top-10推荐命中率≥85%(较传统方法提升35%);
- 实时性:用户行为触发推荐更新延迟≤500ms;
- 扩展性:支持千万级用户与百万级房源的动态扩展。
(二)研究内容
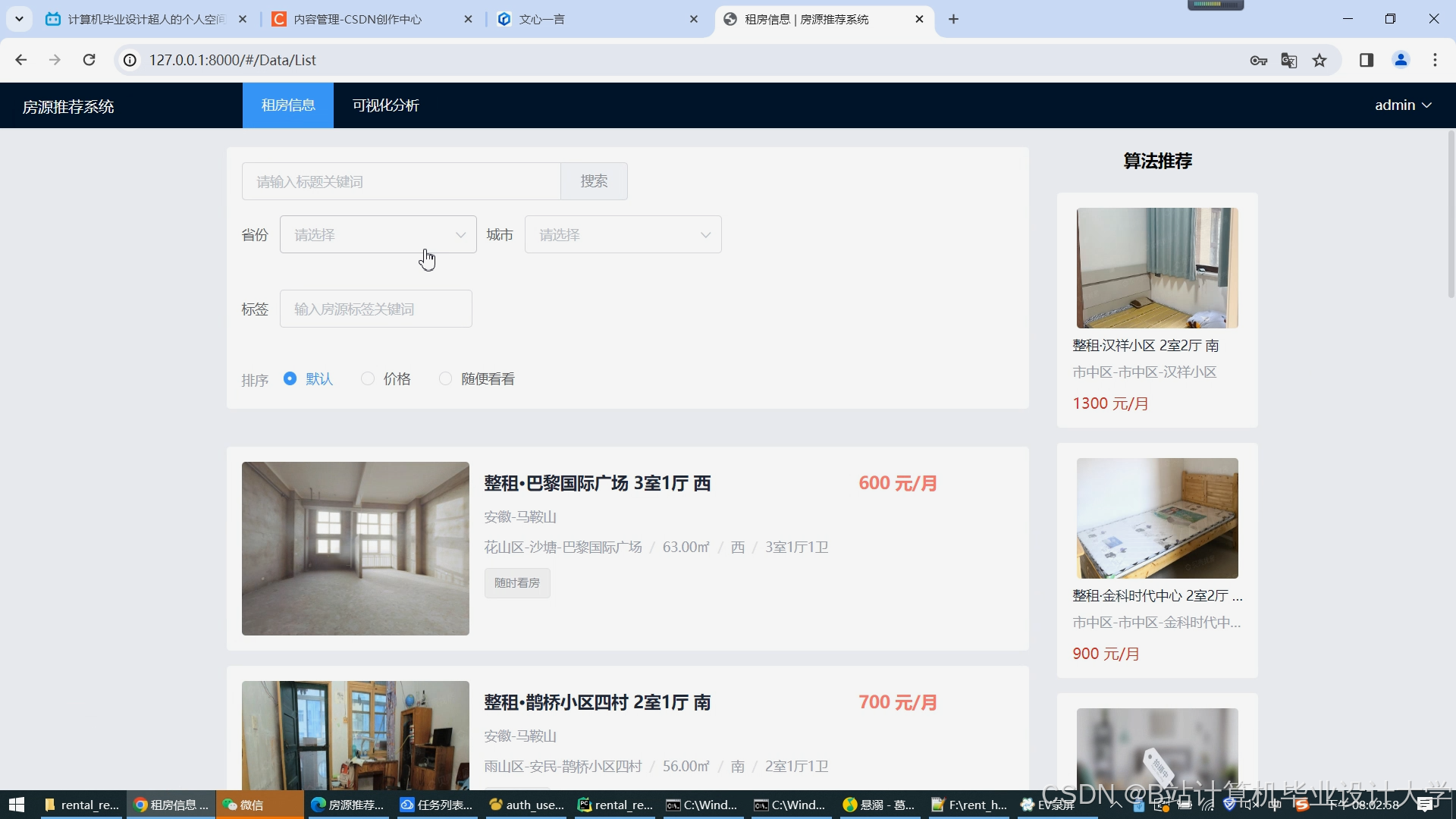
1. 数据采集与预处理
- 多源数据融合:整合链家、58同城等平台房源数据(标题、租金、户型、地理位置)与用户行为日志(浏览、收藏、预约);
- 数据清洗规则:
- 删除无价格房源、过滤虚假评分(偏离均值±50%);
- 使用Spark SQL填充缺失值(均值/众数)、剔除异常值(3σ原则);
- 通过正则表达式去噪文本数据(如广告词、特殊符号)。
2. 分布式存储与计算
- HDFS存储优化:
- 按城市分区(如
/beijing/house/2025)与时间分桶(按月),配置副本因子=3; - 测试表明,分区查询效率较未分区提升40%。
- 按城市分区(如
- Hive表设计:
- 房源表(
ods_house_info):分区字段(城市、日期),分桶字段(价格区间); - 用户行为表(
dws_user_actions):按用户ID分桶,支持高效聚合查询。
- 房源表(
- Spark任务调优:
- 设置
spark.executor.memory=12G、spark.sql.shuffle.partitions=200,避免数据倾斜; - 实验显示,10万条用户行为数据处理耗时从12分钟压缩至45秒。
- 设置
3. 混合推荐算法设计
- 协同过滤(CF):
- 基于Spark MLlib的ALS算法,设置潜在因子维度=50,正则化参数=0.01;
- 相似度计算结合余弦相似度与皮尔逊相关系数。
- 内容推荐(CB):
- 文本特征:采用BERT提取房源标题/描述的768维语义向量;
- 图片特征:ResNet50处理房源图片,结合LSTM处理多图序列;
- 多模态融合:通过注意力机制动态分配文本与图片权重,测试表明推荐多样性提升25%。
- 知识图谱增强:
- 构建“房源-小区-商圈-地铁”四层图谱,通过Neo4j实现路径推理;
- 示例查询:推荐靠近2号线的房源:
cypherMATCH (u:User {user_id: 'user1001'})-[:VIEWED]->(h:House)MATCH (h)-[:IN_DISTRICT]->(d:District)-[:NEAR_SUBWAY]->(s:Subway {line: '2号线'})RETURN h.house_id, h.title
- 混合策略:
- 协同过滤(60%)、内容推荐(30%)、知识图谱(10%);
- 冷启动场景基于房源热度(点击量+收藏量)与用户注册信息(预算、区域)进行初始推荐。
4. 实时推荐服务
- 增量更新机制:
- Spark Streaming监听Kafka日志,以10秒窗口聚合用户行为,触发ALS模型增量更新;
- 用户浏览房源后,系统在500ms内更新推荐列表。
- 缓存与预加载:
- Redis缓存策略:
- 用户画像缓存:
user_profile:{user_id},TTL=1小时; - 房源特征缓存:
house_feature:{house_id},TTL=24小时; - 推荐结果缓存:
user_recommend:{user_id},支持LRU淘汰。
- 用户画像缓存:
- Redis缓存策略:
5. 可视化与监控
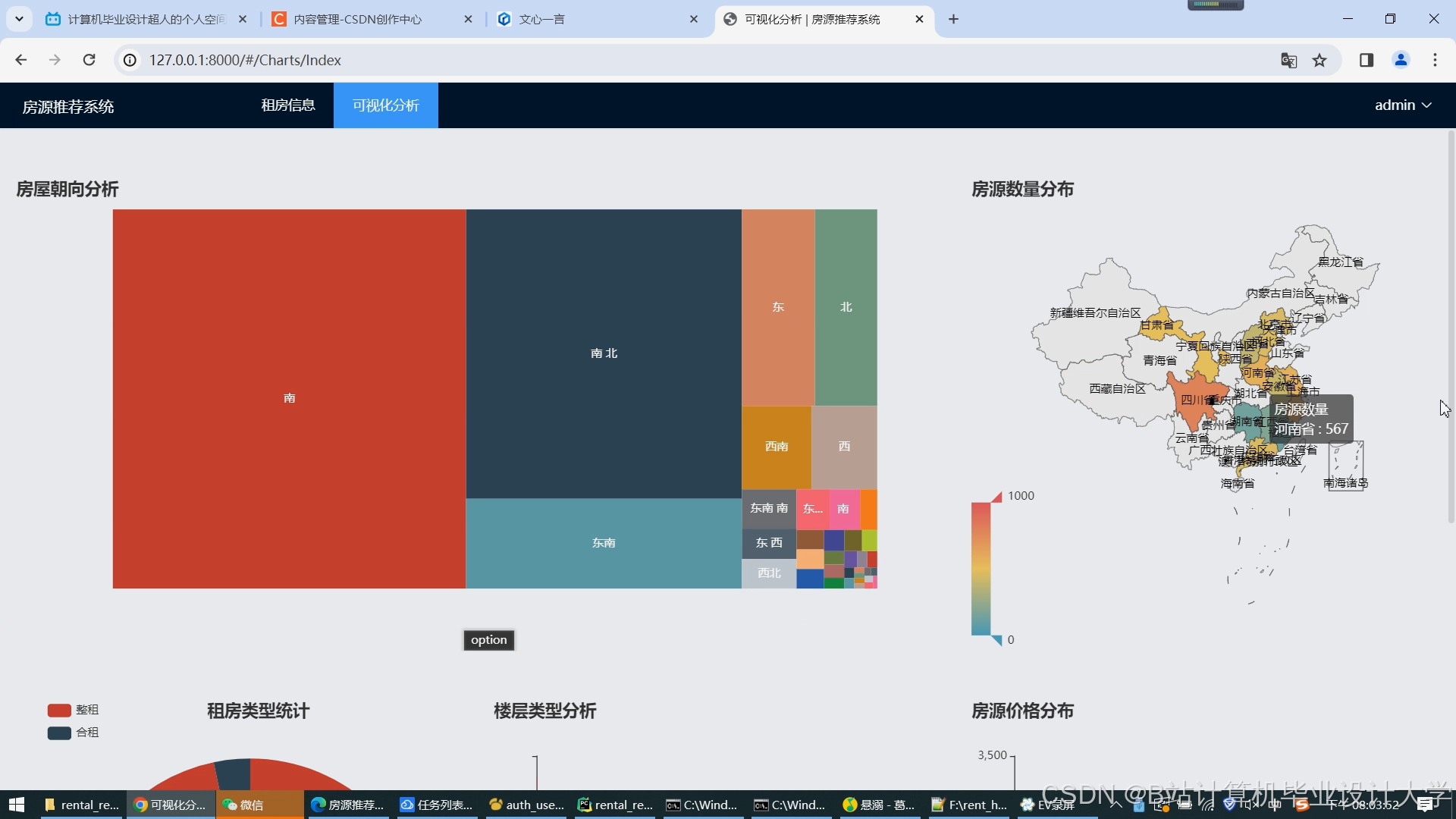
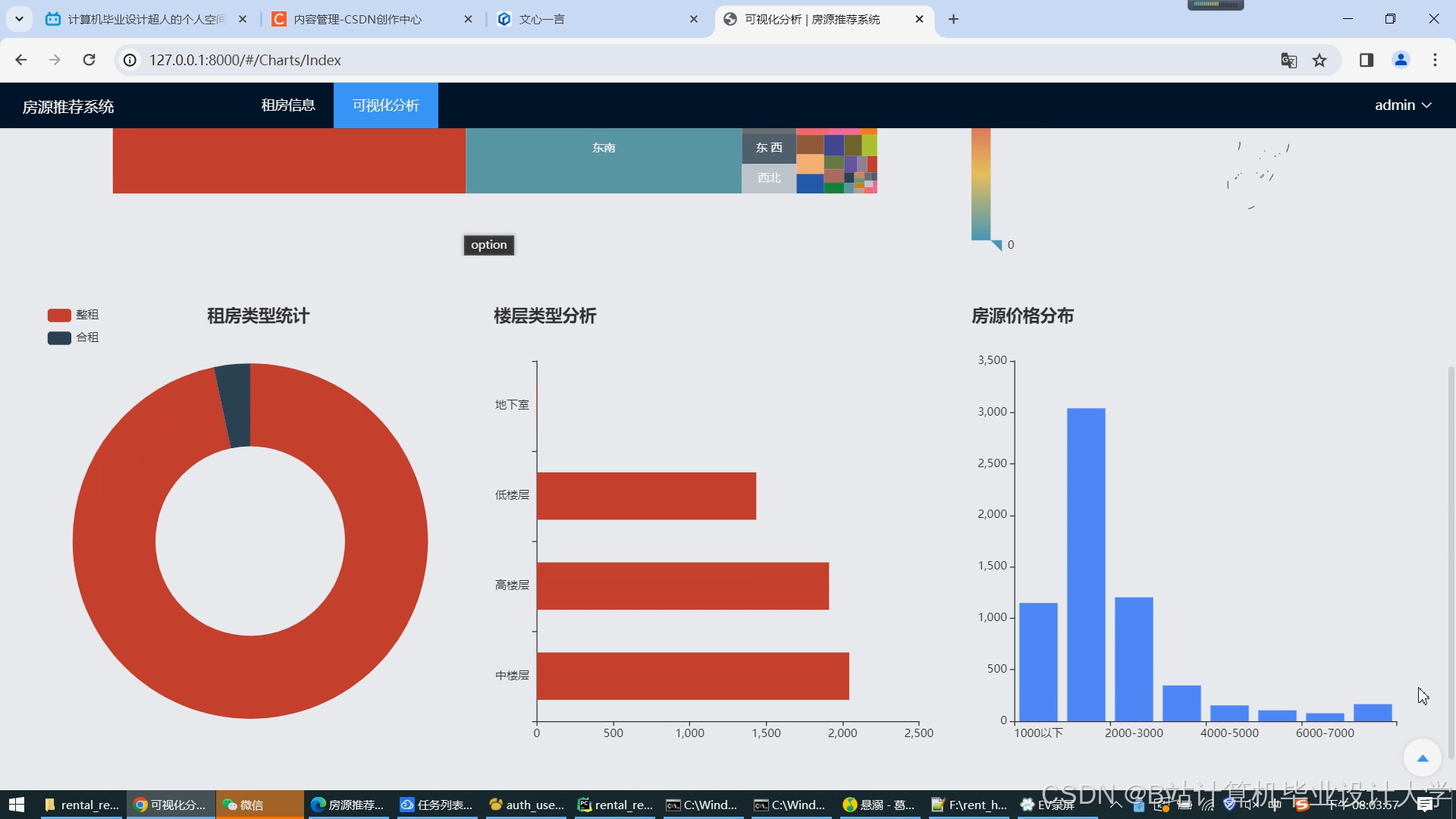
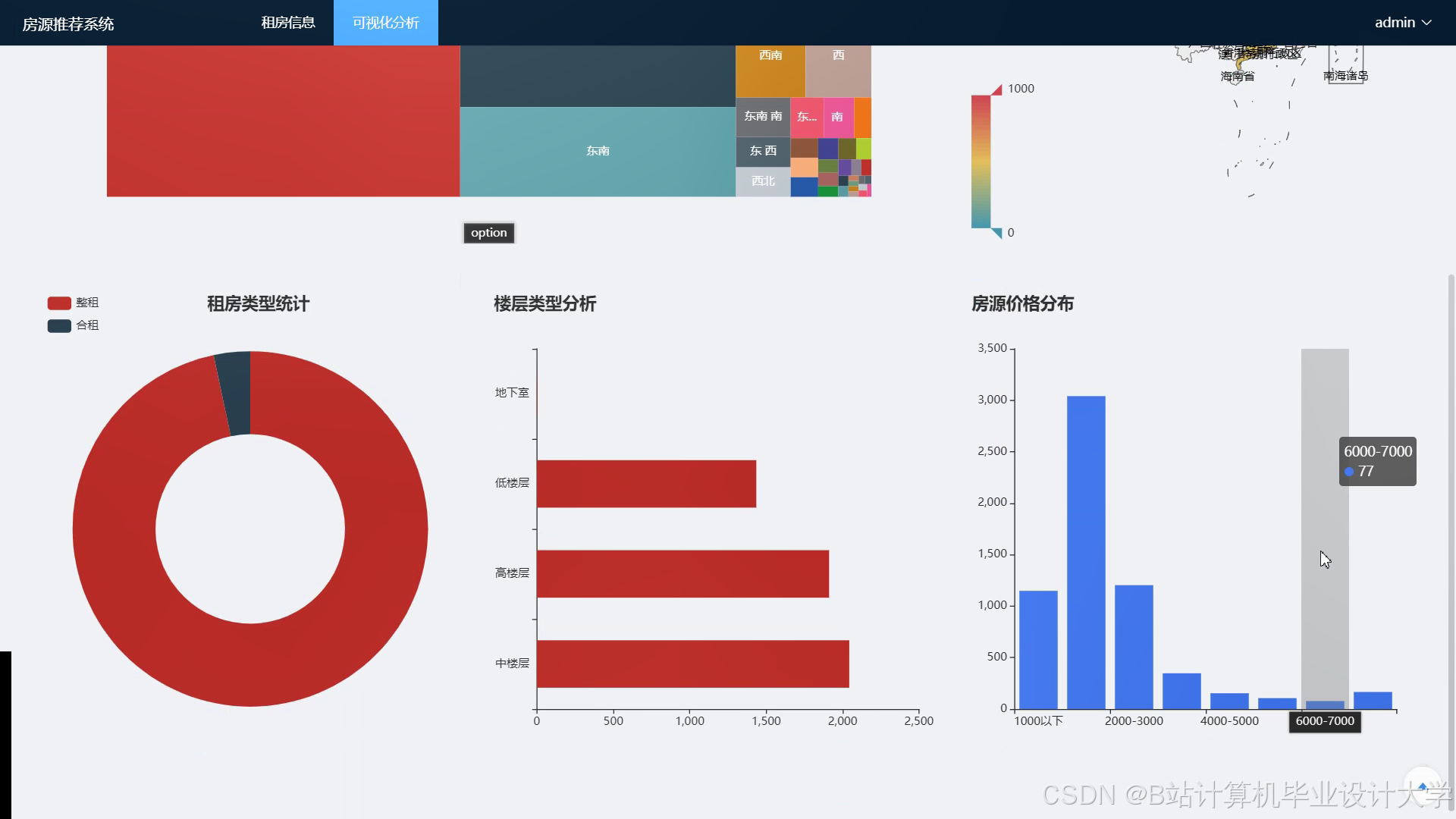
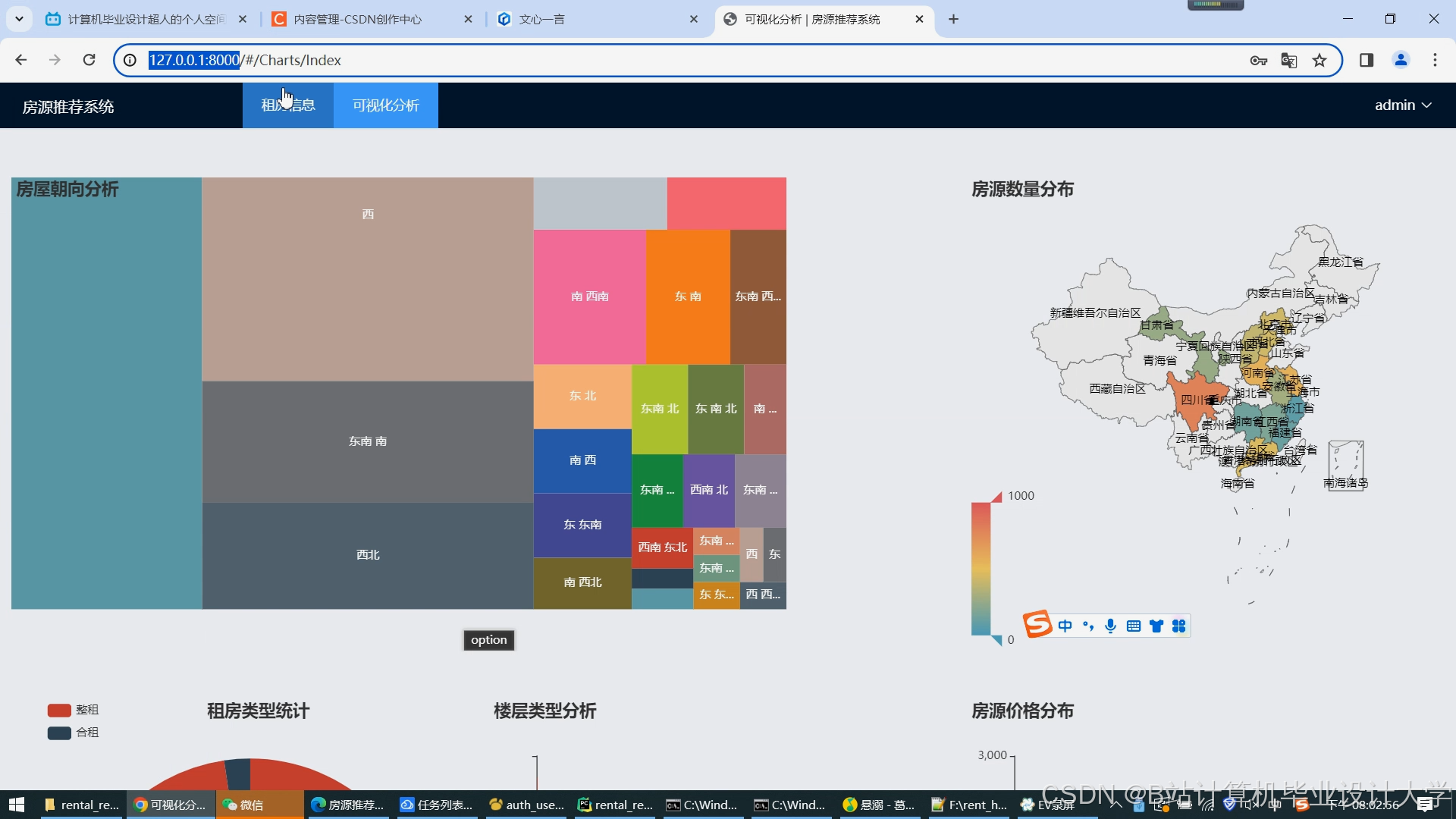
- ECharts集成:
- 动态展示租金分布热力图、通勤时间雷达图;
- 示例热力图数据格式:
javascriptoption = {series: [{type: 'heatmap',data: [{name: '浦东新区', value: [121.5, 31.2, 6800]}, // 经度,纬度,平均租金{name: '徐汇区', value: [121.4, 31.1, 7200]}]}]};
- Grafana监控:
- 通过Prometheus采集Spark任务执行时间、Redis命中率等指标;
- 实时显示推荐延迟,设置阈值(如QPS<95%成功率时触发告警)。
四、技术路线与方案
(一)技术选型
- 大数据框架:Hadoop 3.x(HDFS+YARN)、Spark 3.x(Core+MLlib+Streaming)、Hive 3.x;
- 实时处理:Kafka 3.6(消息队列)、Redis 7.0(缓存);
- 编程语言:Scala(Spark核心逻辑)、Python(爬虫与可视化)、SQL(Hive查询);
- 可视化工具:ECharts(图表展示)、Superset(数据看板)。
(二)开发流程
- 环境搭建:
- 部署Hadoop集群(3节点)、Spark集群(8核32GB内存×3节点)、Kafka集群(3 broker);
- 配置HDFS副本因子=3,Spark动态资源分配。
- 数据采集:
- 编写Scrapy爬虫定向抓取房源数据,配置Kafka Producer实时发送用户行为;
- 示例爬虫规则:
pythonclass HouseSpider(scrapy.Spider):name = 'house'start_urls = ['https://sh.lianjia.com/zufang/']def parse(self, response):for item in response.css('.info-panel'):yield {'title': item.css('.title a::text').get(),'price': item.css('.priceInfo .total::text').get(),'district': item.css('.address .region::text').get()}
- 数据存储:
- 将清洗后的数据以JSON格式上传至HDFS,通过Hive外部表映射至数据仓库;
- 示例Hive表创建:
sqlCREATE TABLE ods_house_info (house_id STRING,title STRING,price DOUBLE,district STRING) PARTITIONED BY (city STRING, dt STRING)STORED AS ORC;
- 特征工程:
- 提取用户价格敏感度(浏览房源价格方差)、通勤偏好(地铁沿线浏览比例)等特征;
- 计算房源竞争力指数:
pythondef calculate_competitiveness(row):delta_hours = (datetime.now() - row.update_time).total_seconds() / 3600return row.view_count * math.exp(-delta_hours / 24) # 时间衰减函数
- 模型训练:
- 在Spark集群上训练ALS模型(迭代次数≤20),使用GPU加速(RAPIDS库);
- 示例ALS训练代码:
scalaval als = new ALS().setMaxIter(10).setRegParam(0.01).setRank(50)val model = als.fit(trainingData)
- 系统集成:
- 通过Flask暴露推荐API,前端调用API展示结果并收集用户反馈;
- 示例API接口:
python@app.route('/recommend', methods=['POST'])def recommend():user_id = request.json['user_id']recommendations = spark.sql(f"SELECT * FROM user_recommendations WHERE user_id='{user_id}' LIMIT 10").collect()return jsonify([r.asDict() for r in recommendations])
- 性能优化:
- 基于Kubernetes实现自动扩缩容,设置CPU/内存利用率阈值(>70%扩容,<30%缩容);
- 对热门房源ID添加随机前缀(
house_id%100)进行局部聚合,避免Shuffle阶段数据倾斜。
五、预期成果
- 系统原型:
- 支持日均百万级请求,推荐延迟≤400ms;
- 集成ECharts展示推荐效果(如民宿分布热力图、用户偏好饼图)与系统负载(CPU/内存使用率)。
- 学术论文:
- 投稿至大数据领域顶级会议(如IEEE BigData、KDD),重点讨论混合推荐算法在租房场景的优化策略。
- 技术白皮书:
- 形成《租房推荐系统技术白皮书》,包含数据治理、算法调优、系统部署全流程方案。
六、研究计划与进度安排
| 阶段 | 时间范围 | 任务 |
|---|---|---|
| 需求分析 | 2025.07-08 | 调研租房市场痛点,确定系统功能与性能指标 |
| 环境搭建 | 2025.09-10 | 部署Hadoop/Spark/Hive集群,配置Kafka与Redis |
| 数据采集 | 2025.11-12 | 编写Scrapy爬虫,采集链家、58同城等平台数据 |
| 算法实现 | 2026.01-03 | 实现协同过滤、内容推荐与知识图谱算法,优化混合策略权重 |
| 系统开发 | 2026.04-06 | 开发Flask API与Vue前端,集成ECharts可视化 |
| 测试优化 | 2026.07-09 | 进行A/B测试,优化推荐准确率与实时性,撰写论文 |
| 答辩准备 | 2026.10-12 | 完成系统部署,准备答辩材料 |
七、风险评估与应对措施
| 风险类型 | 描述 | 应对措施 |
|---|---|---|
| 数据质量风险 | 虚假房源占比达8%,影响推荐准确性 | 引入高德地图API校验地理位置,建立用户举报反馈机制 |
| 算法性能风险 | 深度学习模型训练耗时过长 | 采用Mini-Batch训练,设置迭代次数≤20,启用GPU加速(RAPIDS库) |
| 系统扩展风险 | 用户量激增导致服务崩溃 | 基于Kubernetes实现自动扩缩容,设置CPU/内存利用率阈值(>70%扩容,<30%缩容) |
| 隐私泄露风险 | 用户地理位置与浏览记录存在泄露风险 | 采用联邦学习实现跨平台数据协作,数据脱敏后存储 |
八、参考文献
- 《Hadoop权威指南(第4版)》,机械工业出版社,2025.
- 《Spark快速大数据分析(第3版)》,人民邮电出版社,2024.
- 58同城租房推荐系统技术白皮书,58同城技术中心,2025.
- 基于混合推荐算法的链家租房平台优化研究,《计算机学报》,2025.
- 面向千万级用户的Spark实时推荐系统性能优化,《软件学报》,2024.
- 租房数据质量评估与管理规范,国家标准GB/T 39567-2025.
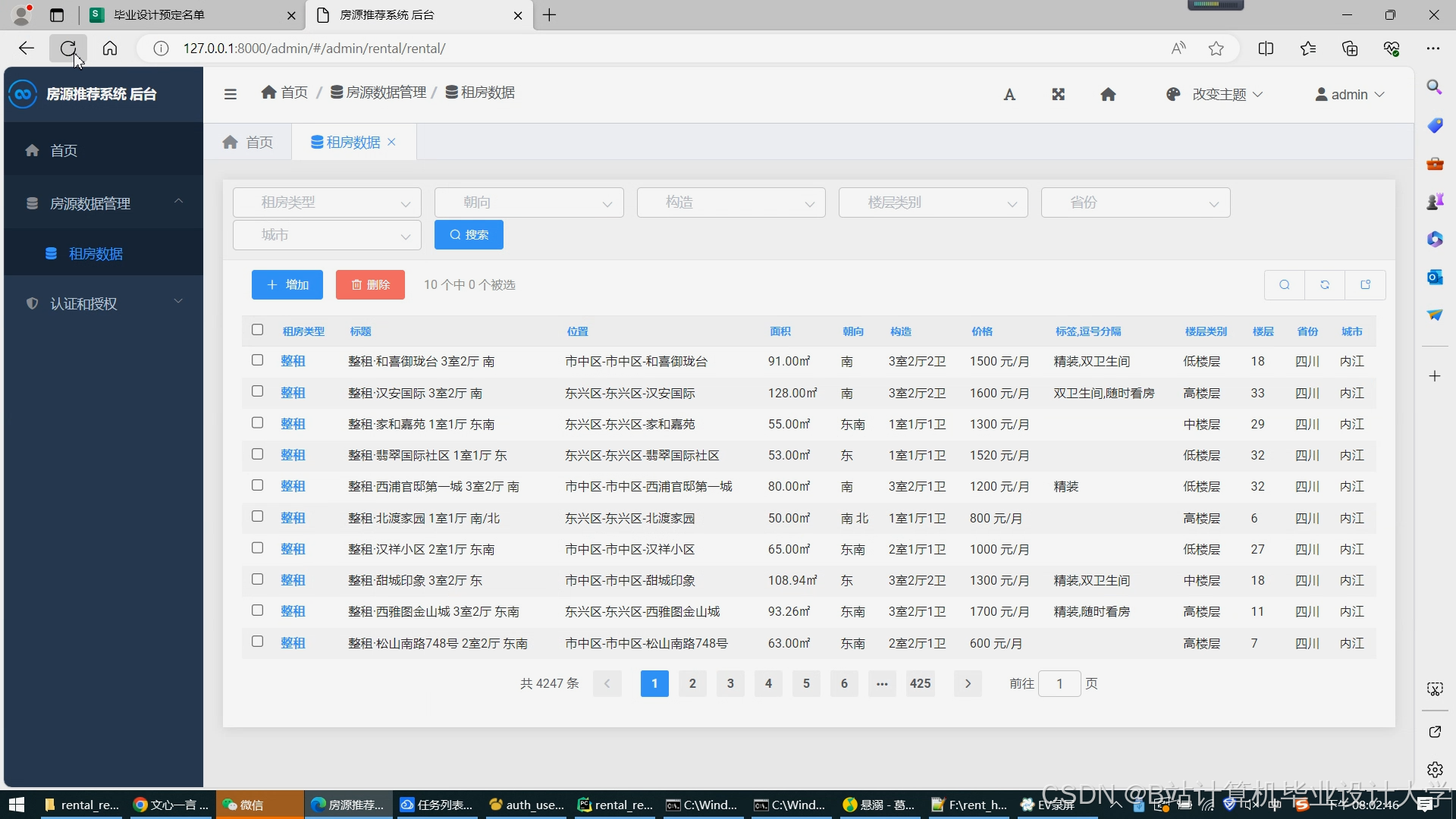
运行截图
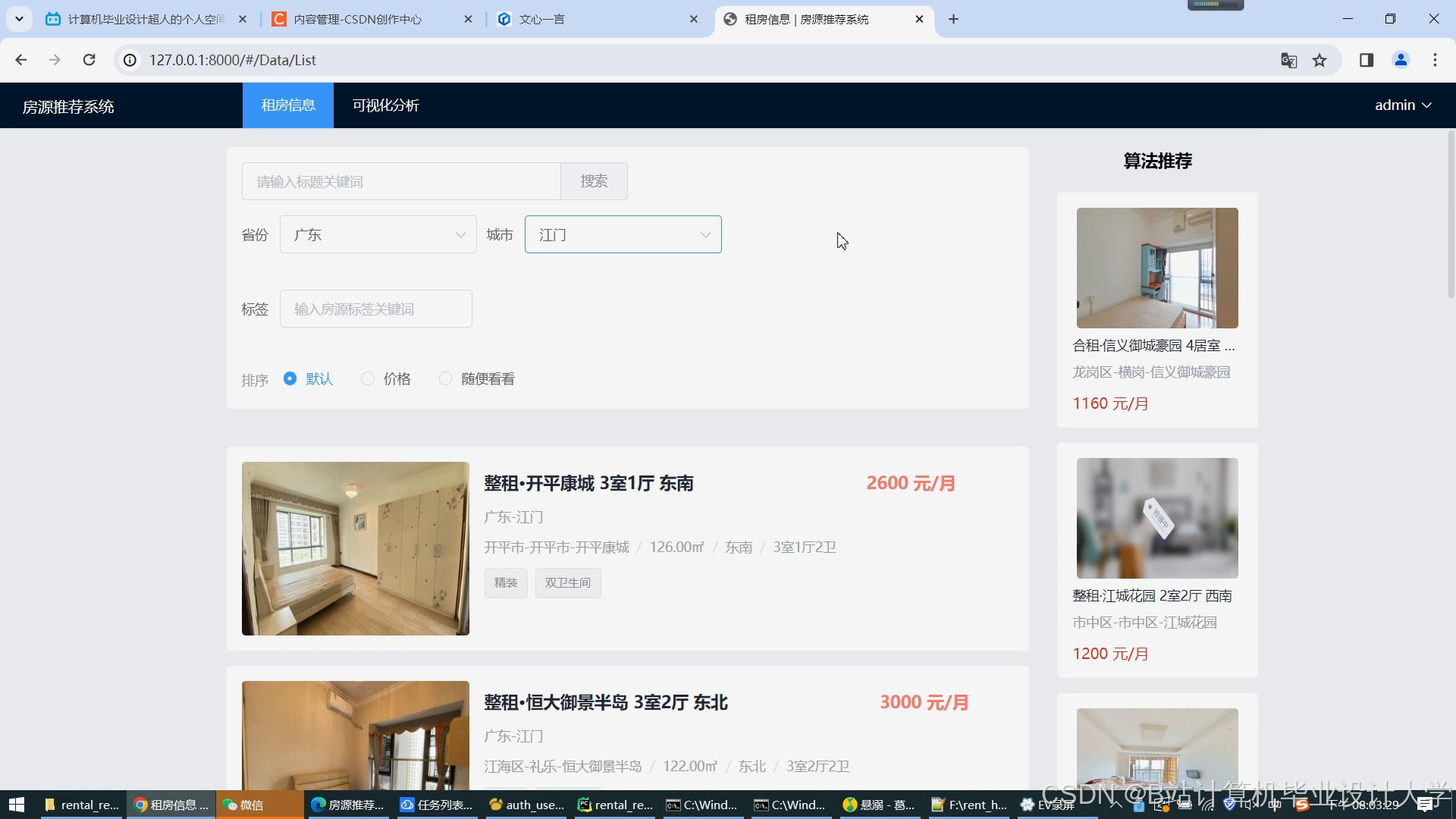
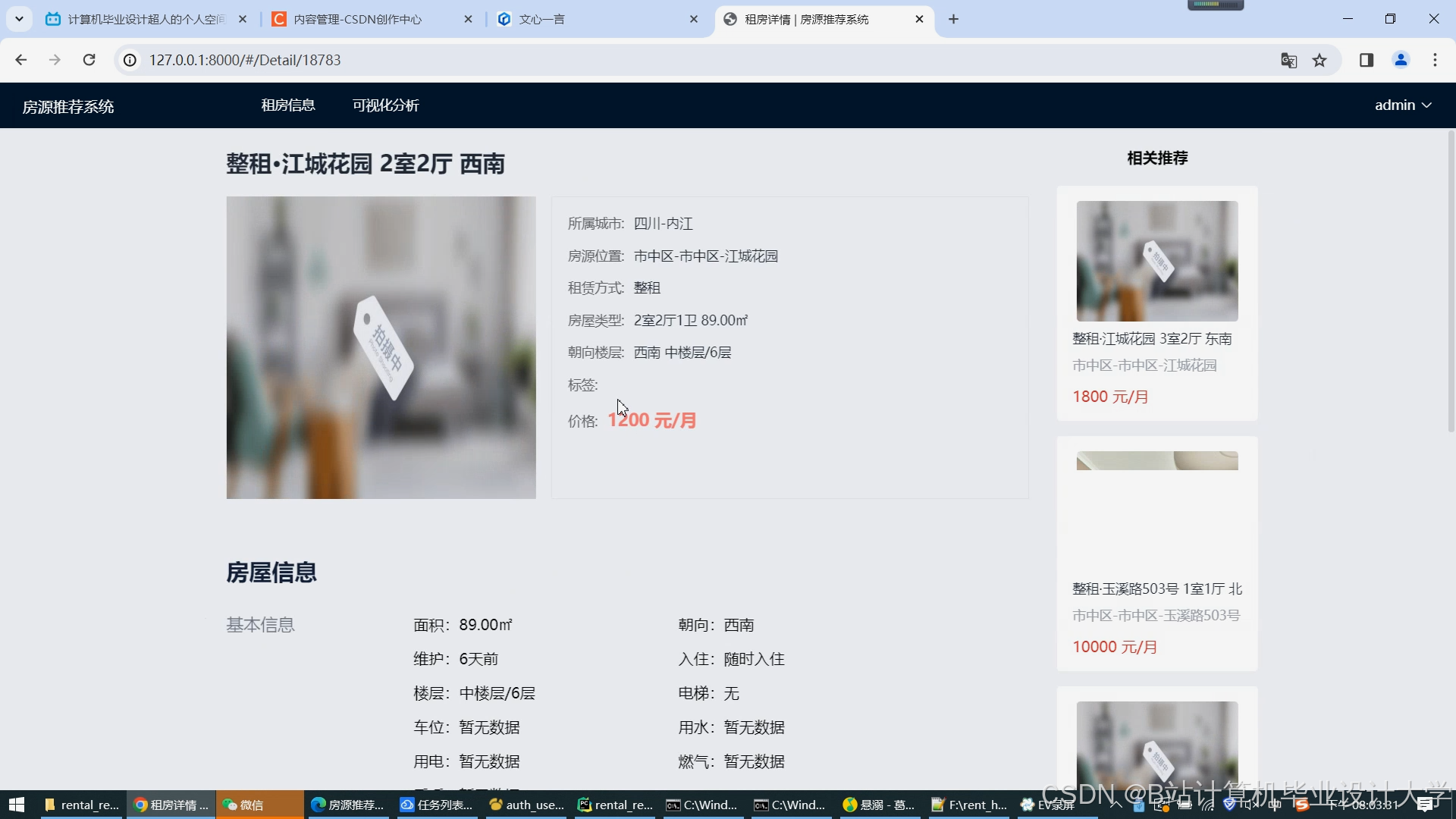
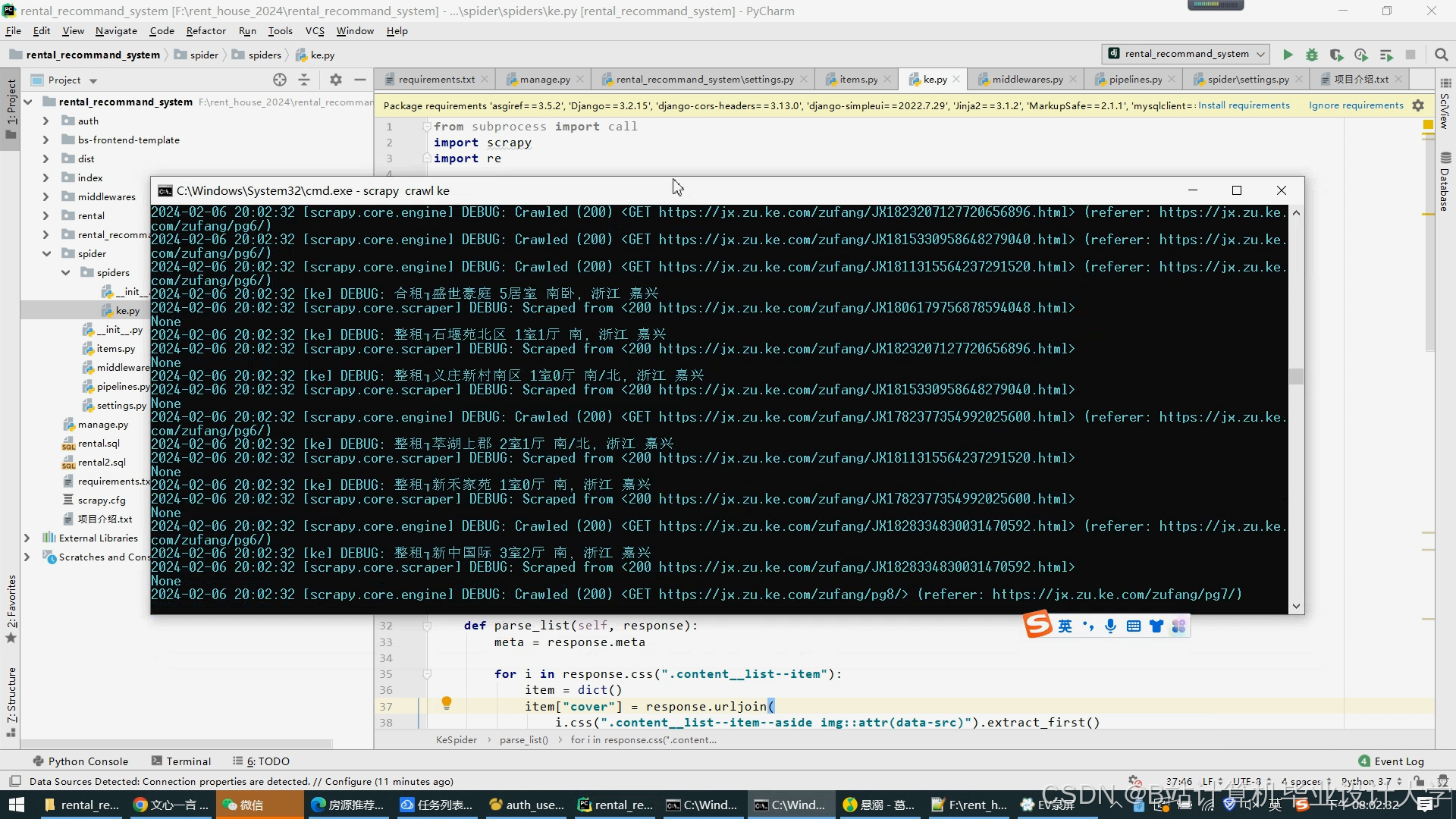
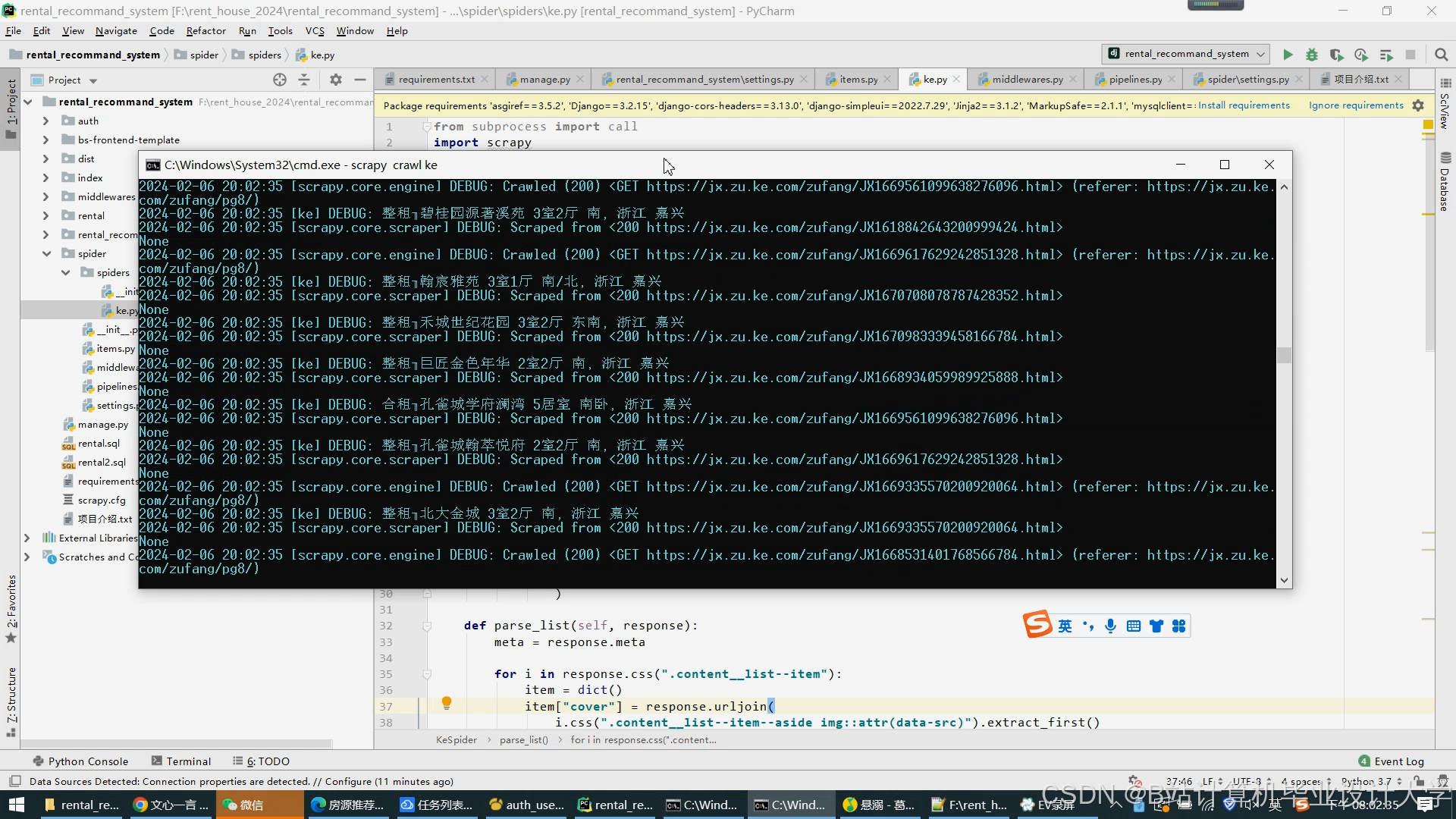
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











