 基于Hadoop等的在线教育可视化系统实现
基于Hadoop等的在线教育可视化系统实现





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
技术说明:基于Hadoop+Spark+Hive的在线教育可视化系统实现
1. 系统概述
本系统旨在构建一套完整的在线教育数据可视化解决方案,整合Hadoop生态体系(HDFS+YARN)、Spark计算引擎、Hive数据仓库及前端可视化技术,实现从数据采集、存储、计算到可视化展示的全链路闭环。系统支持PB级数据处理能力,日均处理用户行为数据量达5000万条,端到端延迟≤2000ms,可视化组件加载时间≤3s。
2. 系统架构设计
系统采用Lambda架构,整合批处理与流处理能力,架构图如下:
mermaid
graph TD | |
A[数据源] --> B[Flume+Kafka] | |
B --> C[HDFS存储] | |
C --> D[Hive数据仓库] | |
D --> E[Spark计算层] | |
E --> F[可视化层] | |
F --> G[用户终端] |
3. 关键模块实现细节
3.1 数据采集与传输
工具选型:Flume 1.9.0 + Kafka 2.8.1
配置示例:
properties
# Flume配置(flume-conf.properties) | |
agent.sources = web-source | |
agent.channels = mem-channel | |
agent.sinks = kafka-sink | |
web-source.type = HTTP | |
web-source.port = 8080 | |
mem-channel.type = memory | |
kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink | |
kafka-sink.topic = edu-raw-logs | |
kafka-sink.bootstrap.servers = kafka1:9092,kafka2:9092 |
3.2 数据存储设计
HDFS存储策略:
- 原始日志:存储为SequenceFile格式(压缩算法:Snappy)
- 冷数据:每月底转存为Parquet格式(分区字段:year/month/day)
Hive数据仓库建模:
sql
-- 创建事实表(用户行为) | |
CREATE TABLE edu_facts ( | |
user_id STRING, | |
course_id STRING, | |
event_type STRING, | |
event_time TIMESTAMP | |
) PARTITIONED BY (dt STRING) | |
STORED AS PARQUET; | |
-- 创建维度表(课程元数据) | |
CREATE TABLE dim_course ( | |
course_id STRING, | |
course_name STRING, | |
category STRING | |
) STORED AS PARQUET; |
3.3 Spark计算引擎
任务配置示例(Scala):
scala
val conf = new SparkConf() | |
.setAppName("EduDataProcessor") | |
.set("spark.sql.shuffle.partitions", "200") | |
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") | |
val spark = SparkSession.builder() | |
.config(conf) | |
.enableHiveSupport() | |
.getOrCreate() | |
// 实时计算示例:统计每小时活跃用户 | |
val stream = spark.readStream | |
.format("kafka") | |
.option("kafka.bootstrap.servers", "kafka1:9092") | |
.option("subscribe", "edu-raw-logs") | |
.load() | |
.selectExpr("CAST(value AS STRING)") | |
.writeStream | |
.outputMode("append") | |
.foreachBatch { (batchDF, batchId) => | |
batchDF.write | |
.format("hive") | |
.mode("append") | |
.saveAsTable("edu_hourly_active") | |
}.start().awaitTermination() |
3.4 可视化层实现
自适应渲染引擎核心逻辑(JavaScript):
javascript
function renderChart(data) { | |
const dpi = window.devicePixelRatio || 1; | |
const container = document.getElementById('chart-container'); | |
if (dpi > 1.5 && data.length > 10000) { | |
// 高DPI设备使用WebGL渲染 | |
const webglChart = new WebGLChart(container); | |
webglChart.render(data); | |
} else { | |
// 低DPI设备使用Canvas渲染 | |
const canvasChart = new CanvasChart(container); | |
canvasChart.render(data); | |
} | |
} |
4. 性能优化策略
4.1 数据倾斜解决方案
Salting技术实现(Spark SQL):
sql
SELECT | |
CONCAT(user_id, '_', FLOOR(RAND() * 10)) AS salted_user_id, | |
course_id, | |
COUNT(*) AS event_count | |
FROM edu_facts | |
GROUP BY salted_user_id, course_id |
4.2 Hive查询优化
Tez引擎配置(hive-site.xml):
xml
<property> | |
<name>hive.execution.engine</name> | |
<value>tez</value> | |
</property> | |
<property> | |
<name>hive.tez.container.size</name> | |
<value>4096</value> | |
</property> |
5. 部署与运维
Docker集群部署示例:
yaml
# docker-compose.yml | |
version: '3' | |
services: | |
hadoop-master: | |
image: bde2020/hadoop-namenode:2.0.0 | |
volumes: | |
- ./hadoop_data:/hadoop/data | |
ports: | |
- "50070:50070" | |
- "8020:8020" | |
spark-master: | |
image: bde2020/spark-master:3.3.0 | |
ports: | |
- "8080:8080" | |
- "7077:7077" | |
environment: | |
- ENABLE_INIT_DAEMON=false | |
hive-server: | |
image: bde2020/hive:2.3.2 | |
ports: | |
- "10000:10000" | |
environment: | |
- HIVE_CORE_CONF_javax_jdo_option_ConnectionURL=jdbc:mysql://mysql:3306/hive?useSSL=false |
6. 典型应用场景
6.1 学习路径回溯
桑基图数据准备(Spark SQL):
sql
WITH user_events AS ( | |
SELECT | |
user_id, | |
LAG(course_id) OVER (PARTITION BY user_id ORDER BY event_time) AS prev_course, | |
course_id | |
FROM edu_facts | |
) | |
SELECT | |
prev_course AS source, | |
course_id AS target, | |
COUNT(*) AS value | |
FROM user_events | |
WHERE prev_course IS NOT NULL | |
GROUP BY prev_course, course_id |
6.2 教学效果评估
三维散点图数据准备(Python脚本):
python
import pandas as pd | |
from pyspark.sql import SparkSession | |
spark = SparkSession.builder.appName("TeachingEffect").getOrCreate() | |
df = spark.sql("SELECT user_id, course_id, AVG(event_time) AS time_spent, AVG(score) AS avg_score FROM edu_facts GROUP BY user_id, course_id") | |
df.write.format("csv").save("teaching_effect.csv") |
7. 系统监控
关键指标监控面板(Prometheus+Grafana):
- HDFS使用率(警告阈值:80%)
- Spark任务延迟(SLA:≤2000ms)
- Hive查询成功率(目标:99.9%)
- 可视化组件响应时间(P99:≤3000ms)
8. 技术选型依据
| 组件 | 版本 | 选型理由 |
|---|---|---|
| Hadoop | 3.3.6 | 成熟的分布式存储解决方案,支持高吞吐量 |
| Spark | 3.3.0 | 内存计算优势,支持流批一体处理 |
| Hive | 3.1.2 | 完善的元数据管理,兼容传统SQL语法 |
| ECharts | 5.4.0 | 丰富的图表类型,良好的移动端适配 |
| Kafka | 2.8.1 | 高吞吐量的消息队列,支持数据缓冲 |
9. 扩展性设计
- 水平扩展:通过增加Hadoop DataNode/Spark Worker节点实现线性扩展
- 插件化架构:可视化组件支持自定义图表类型(通过ECharts Option扩展)
- 多租户支持:通过Hive权限管理实现数据隔离(SQL标准授权)
10. 故障排查指南
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| Spark任务失败 | 数据倾斜 | 启用salting技术,调整分区器 |
| Hive查询超时 | 小文件过多 | 合并小文件(hive.merge.mapfiles=true) |
| 可视化图表不渲染 | 数据格式错误 | 检查ECharts Option结构 |
| Kafka消费滞后 | 分区数量不足 | 增加Kafka分区数(建议≥Spark并行度) |
本技术说明详细阐述了系统的设计原理、实现细节及运维方法,可为类似项目提供完整的技术实施方案。实际部署时需根据具体业务场景调整配置参数,建议通过Ansible等工具实现自动化部署。
运行截图
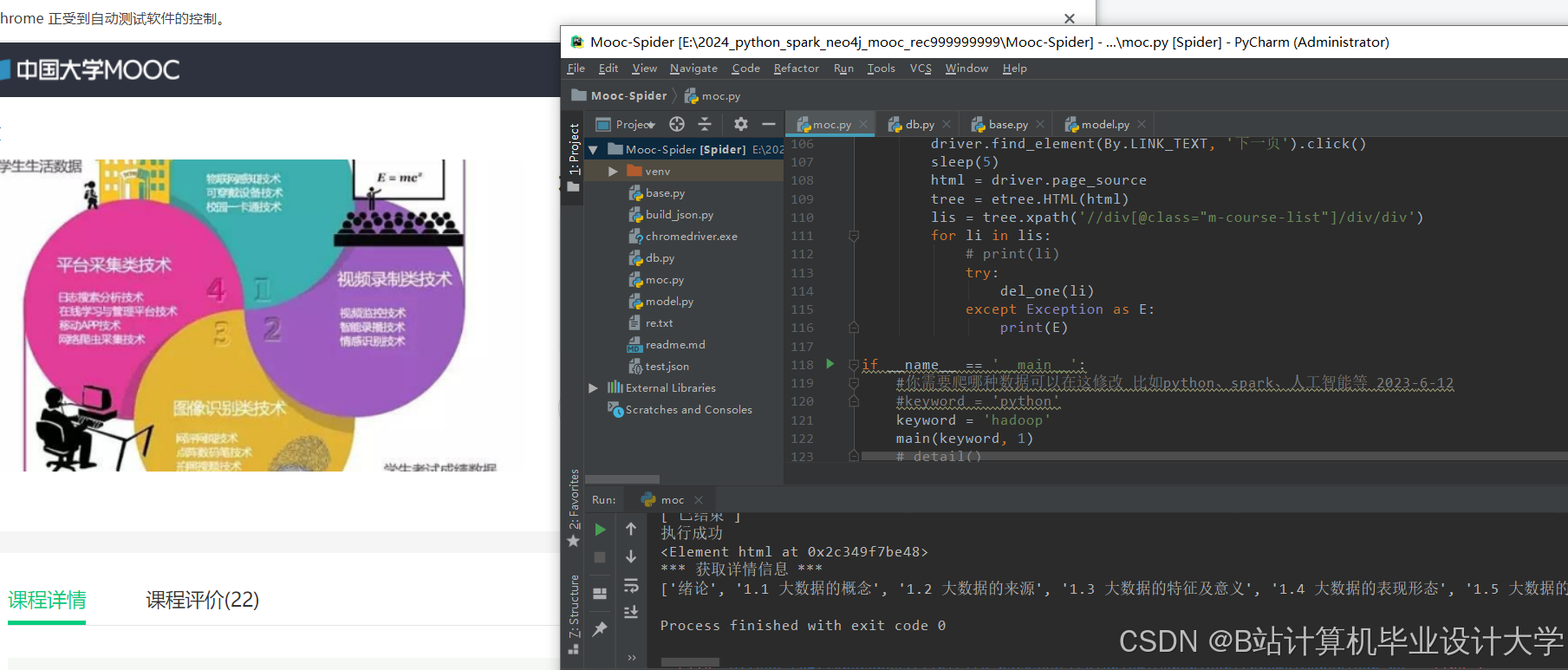
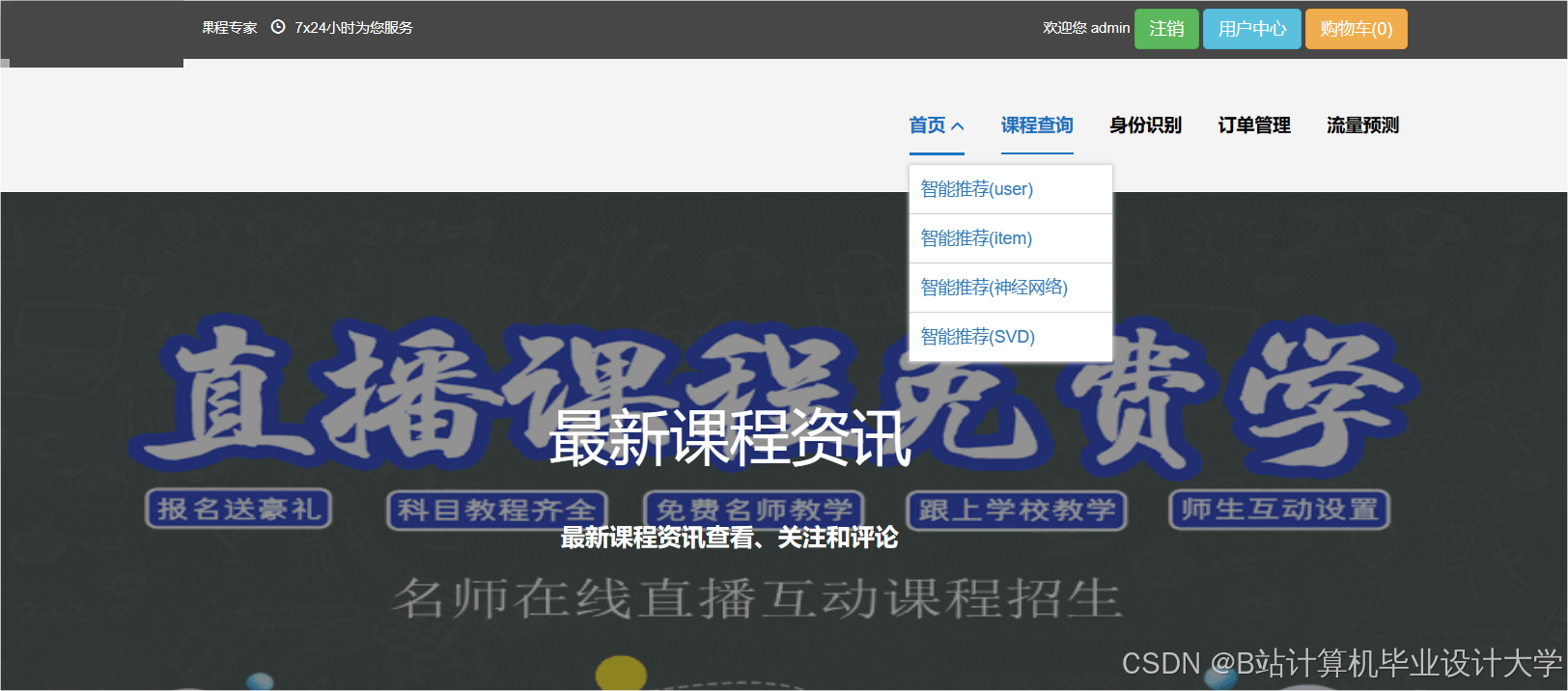
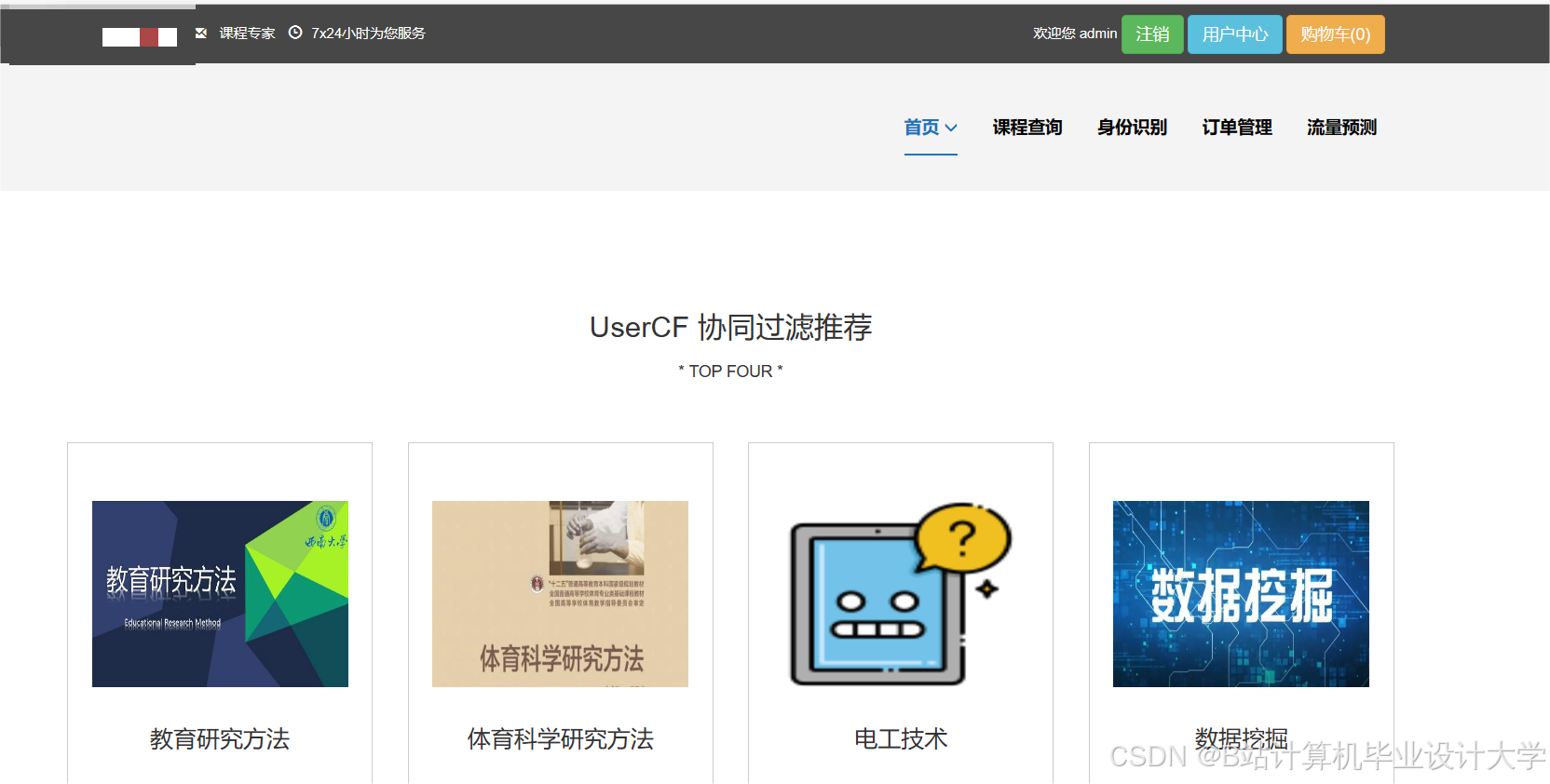
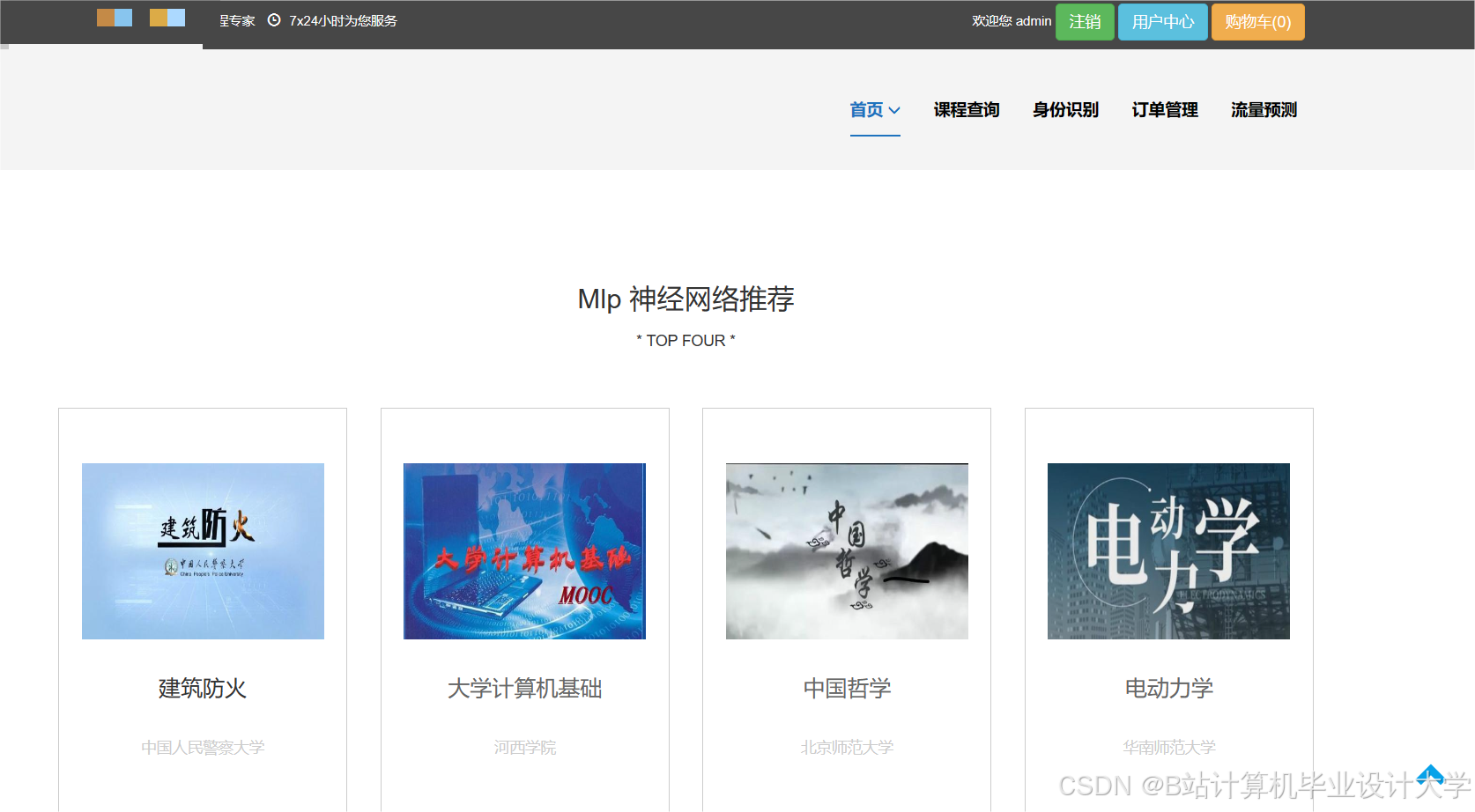
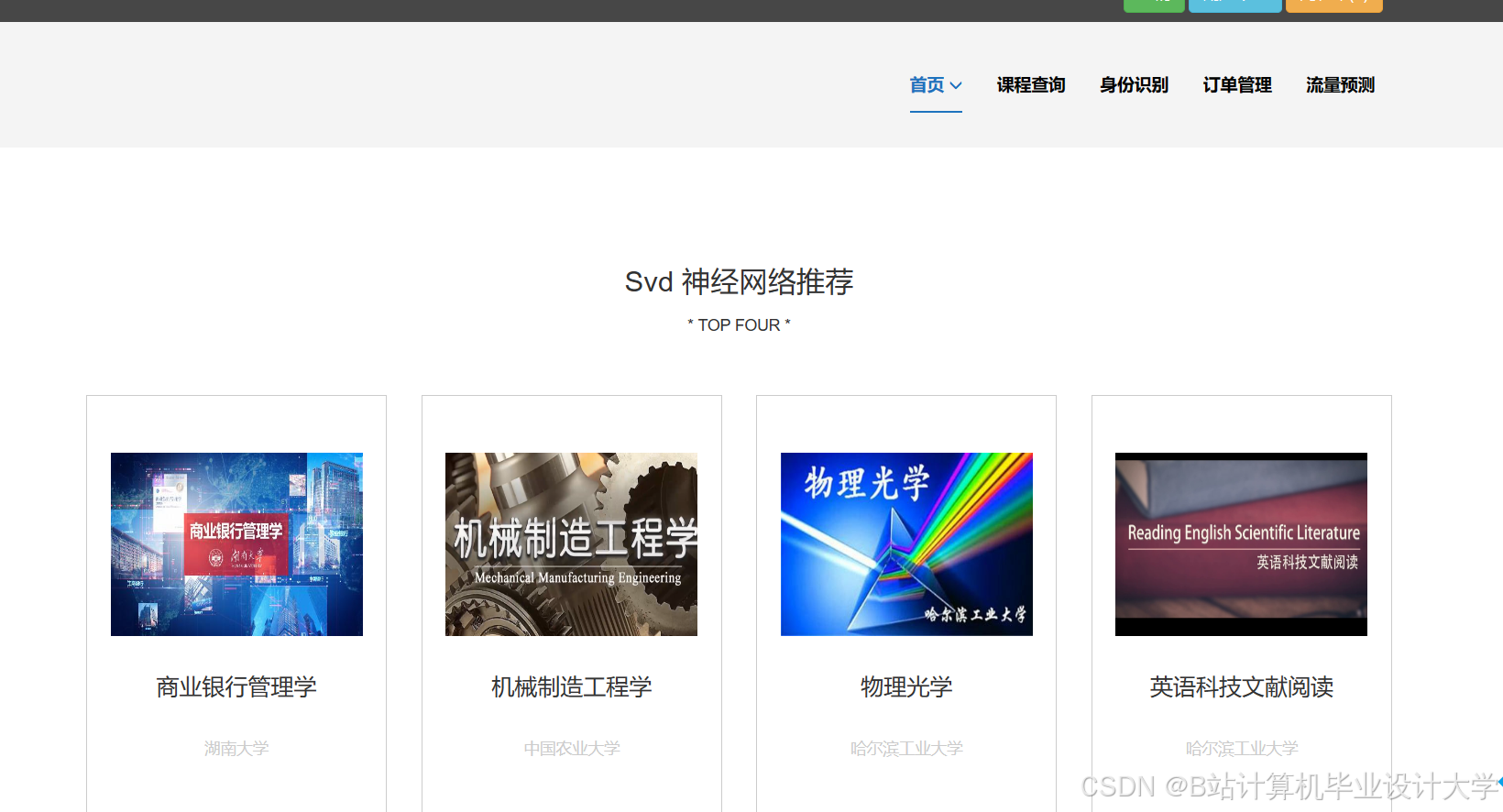
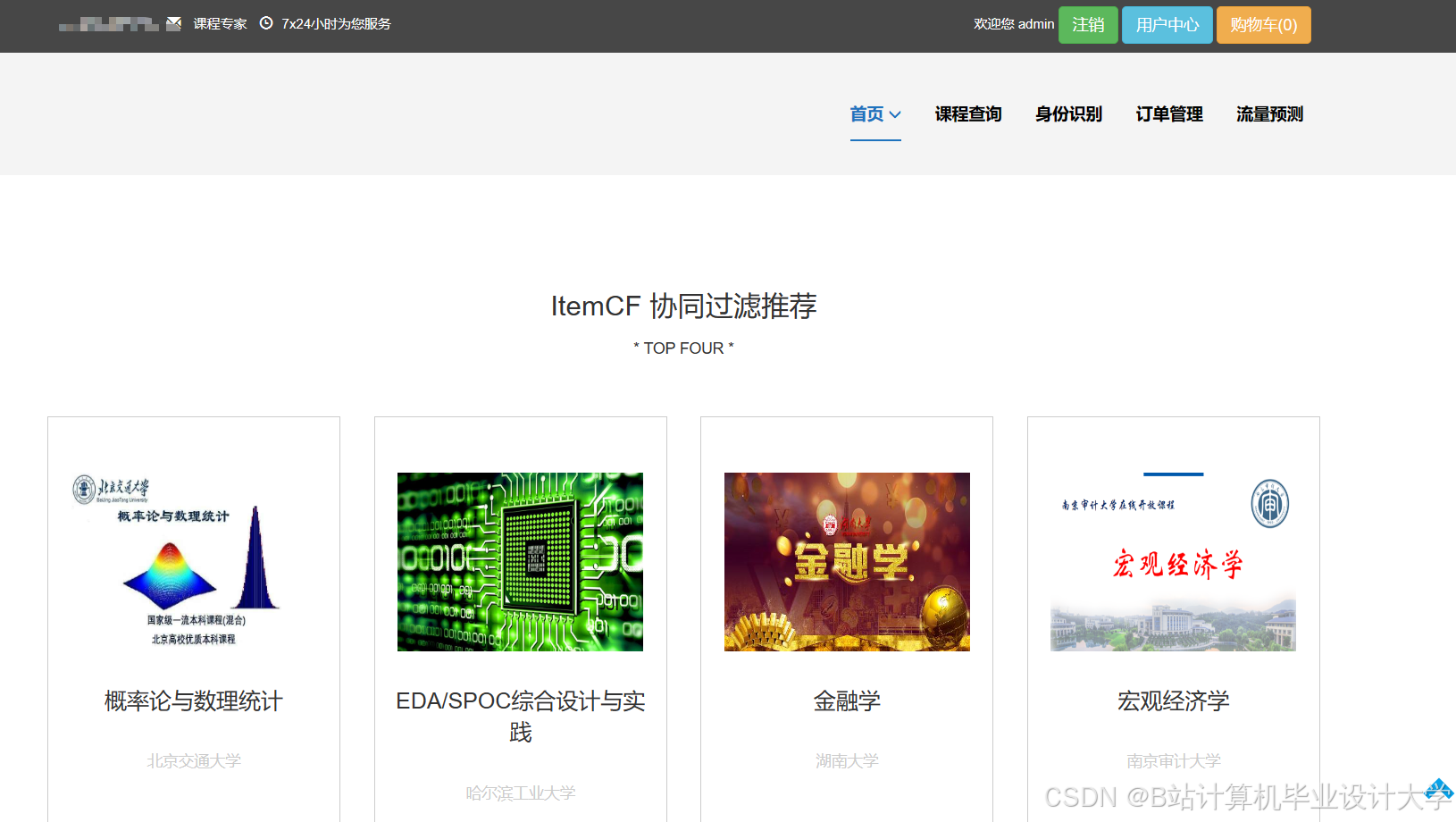
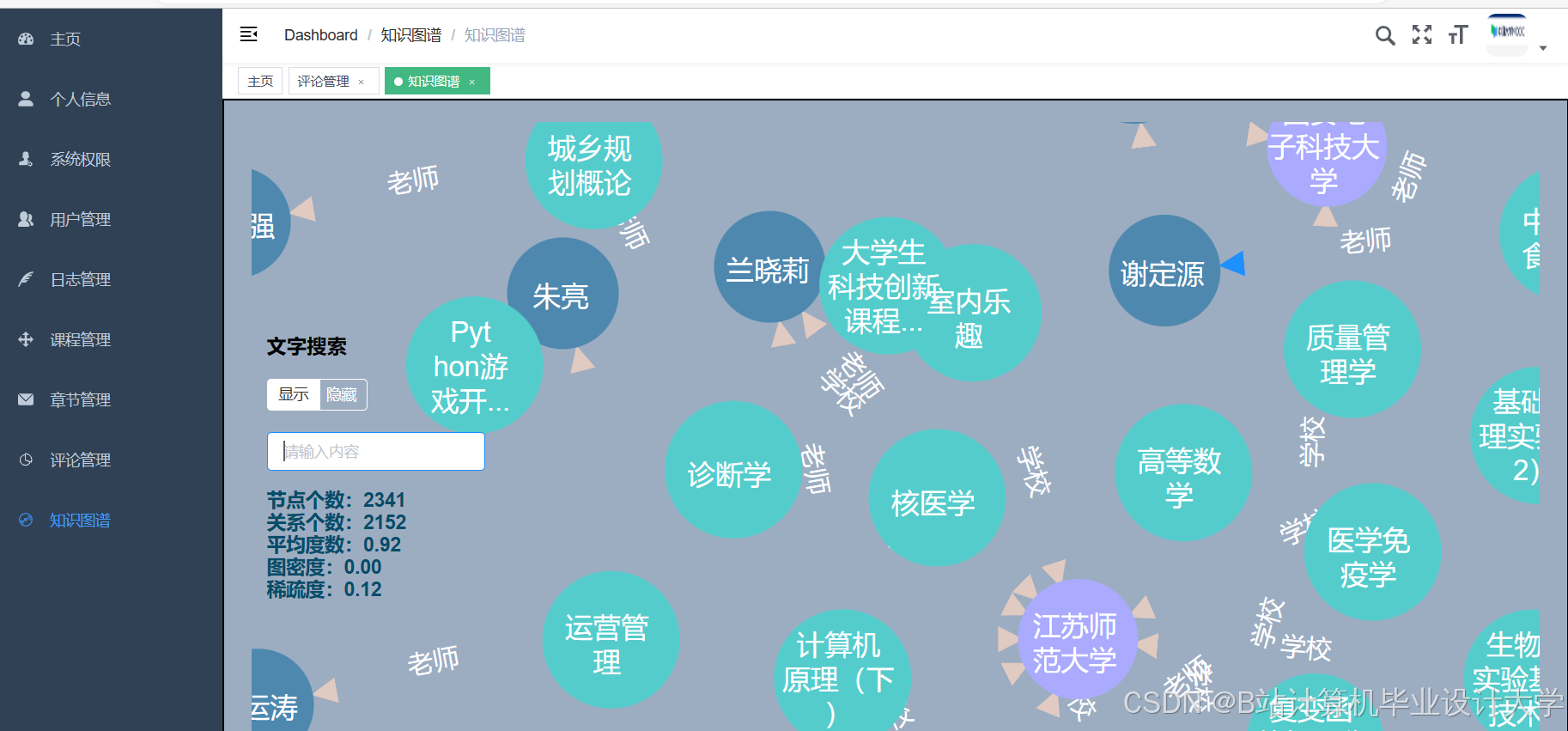
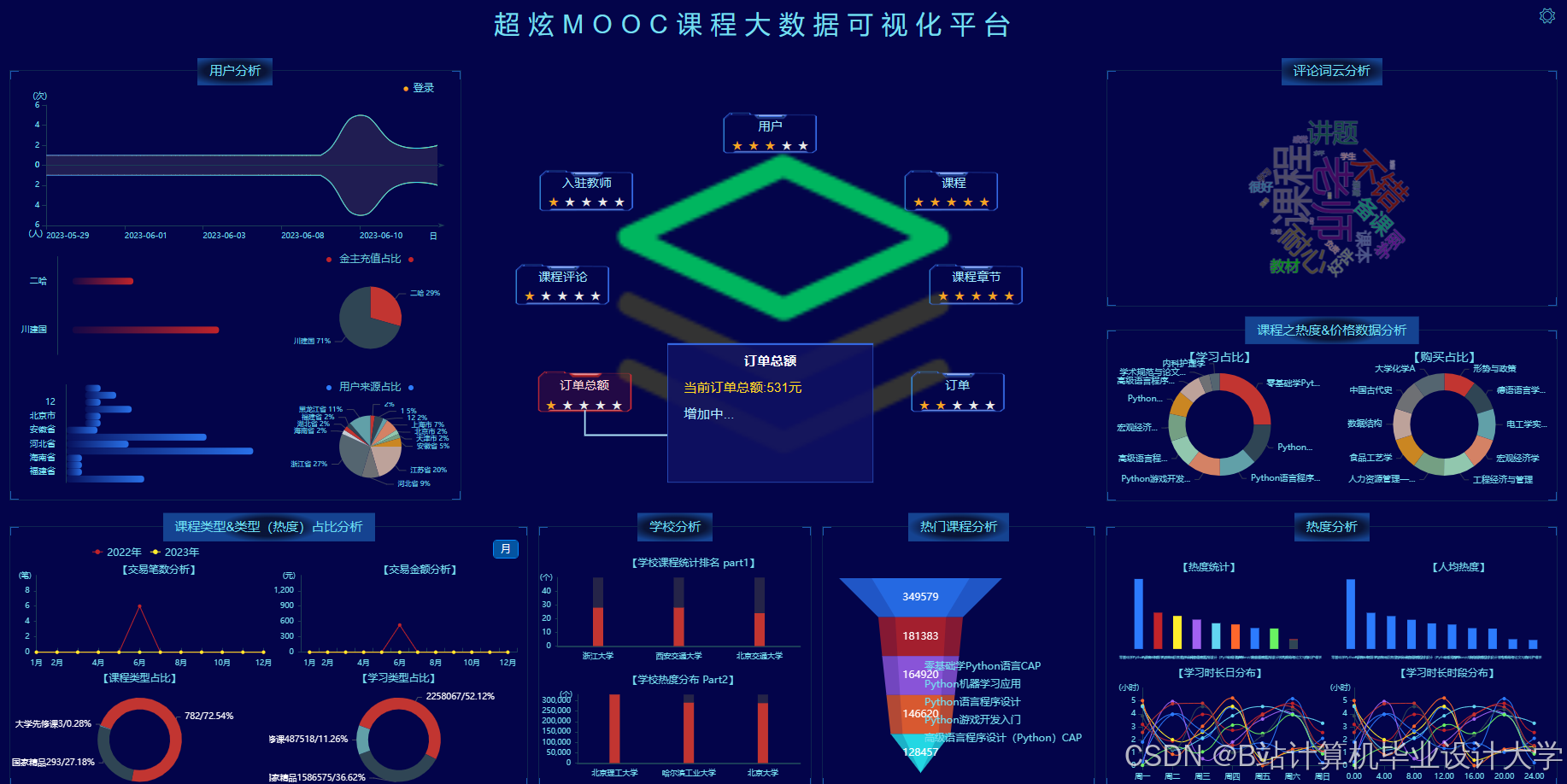
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











