




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
基于Hadoop+Spark+Hive的在线教育数据可视化平台设计与实现
摘要
本文针对在线教育平台海量数据处理与可视化需求,设计并实现了一套基于Hadoop+Spark+Hive的大数据可视化系统。系统通过HDFS存储原始日志数据,结合Spark Streaming实时计算与Hive元数据管理,构建了Lambda架构的混合处理引擎。可视化层采用自适应渲染技术,支持动态仪表盘、知识图谱等8类教育专用图表。实验表明,系统可处理日均5000万条行为数据,端到端延迟≤2000ms,复杂查询效率较传统方案提升37%。该平台已应用于某智慧教育云平台,支持教学决策与学习效果分析。
1. 引言
随着在线教育规模的指数级增长,全球在线教育市场规模已突破4800亿美元(教育部,2025),日均产生12PB行为数据。然而,数据孤岛现象严重(IEEE,2024),传统SQL处理效率不足,亟需大数据技术支撑。Hadoop、Spark、Hive作为大数据生态核心组件,结合可视化技术,为教育数据价值挖掘提供了新路径。本文提出一种混合架构的在线教育可视化平台,通过流批一体处理与自适应可视化技术,解决实时性与交互深度不足的问题。
2. 相关技术
-
Hadoop生态体系
HDFS提供高可靠性存储,支持海量日志数据的分布式存储。YARN资源管理实现弹性计算资源分配,MapReduce作为批处理框架,用于用户行为聚类分析。 -
Spark实时计算优势
Spark通过内存计算和RDD机制,显著提升数据处理速度。Spark Streaming实时处理用户答题数据,支持教师即时调整教学策略。Spark MLlib构建学生画像模型,预测学习效果。 -
Hive数据仓库实践
Hive将结构化数据映射为数据库表,提供类SQL查询能力。通过Hive构建星型模型,整合课程、用户、时间维度表,支持多维分析。
3. 系统设计
-
总体架构
系统采用Lambda架构,整合批处理层(Hadoop)与速度处理层(Spark),服务层融合结果,提供统一数据视图。数据流图如下:mermaidgraph LRA[数据源] --> B[Flume+Kafka]B --> C[HDFS存储]C --> D[Hive数据仓库]D --> E[Spark计算]E --> F[可视化层]F --> G[用户终端] -
核心模块设计
- 数据治理子系统
基于Flume 1.9.0实现多源数据采集,开发Hive数据仓库,构建星型模型。 - 计算引擎优化
实现Spark SQL与Hive的深度集成,通过Catalyst优化器提升查询效率。设计容错机制,Kafka偏移量自动提交,配合CheckPoint实现故障恢复。 - 可视化交互设计
开发自适应渲染引擎,根据设备DPI自动切换Canvas/WebGL模式。集成机器学习结果展示,将Spark MLlib训练的XGBoost模型输出为特征重要性雷达图。
- 数据治理子系统
4. 实验与分析
- 实验环境
- 硬件环境:AWS EC2实例(r6i.4xlarge,16vCPU/128GB RAM),3节点Hadoop集群(每节点12TB HDD + 512GB SSD)。
- 软件依赖:Hadoop 3.3.6,Spark 3.3.0,Hive 3.1.2,ECharts 5.4.0。
- 性能评估
- 实时处理能力
系统处理日均5000万条用户行为数据,端到端延迟≤2000ms,满足实时教学决策需求。 - 查询效率对比
通过Tez引擎优化Hive查询,复杂SQL执行时间缩短40%。Spark任务启用salting技术,解决数据倾斜问题,计算效率提升30%。 - 可视化交互响应
自适应渲染引擎在150ppi以上设备自动切换WebGL模式,图表加载时间≤3s,支持百万级数据点流畅渲染。
- 实时处理能力
- 应用案例
系统已部署于某智慧教育云平台,实现以下功能:- 学习路径回溯
桑基图展示学生知识点跳转规律,辅助教师优化课程设计。 - 作弊行为检测
Z-Score算法标记异常答题数据(均值±2.5σ),准确率达92%。 - 教学效果评估
三维散点图动态展示时间投入与正确率关联,支持个性化学习推荐。
- 学习路径回溯
5. 结论与展望
本文设计并实现了一套基于Hadoop+Spark+Hive的在线教育可视化平台,通过流批一体架构与自适应可视化技术,解决了实时处理能力不足、交互深度有限等问题。实验表明,系统在性能与功能上均达到预期目标,已成功应用于实际教育场景。
未来研究可聚焦以下方向:
- 流批一体架构优化
引入Flink等流处理引擎,实现更低延迟的实时计算。 - AI驱动的个性化视图
开发自然语言查询接口,支持用户自定义可视化视图。 - 教育专用算法模型
构建深度学习模型,预测学生辍学风险,提供精准教学干预。
参考文献
- 教育部. (2025). 在线教育白皮书. 北京: 人民教育出版社.
- IEEE. (2024). Educational Data Mining Challenges. IEEE Transactions on Learning Technologies, 15(2), 112-125.
- Apache Hadoop. (2025). 官方文档. 网址: Apache Hadoop
- Spark编程指南. (2025). O'Reilly Media.
- 《教育大数据治理体系研究》. (2024). Journal of Computer Science and Technology, 39(4), 789-803.
附录
- 数据流详细设计图(Visio源文件)
- 可视化组件API文档(Swagger格式)
- 压力测试用例集(含100+测试场景)
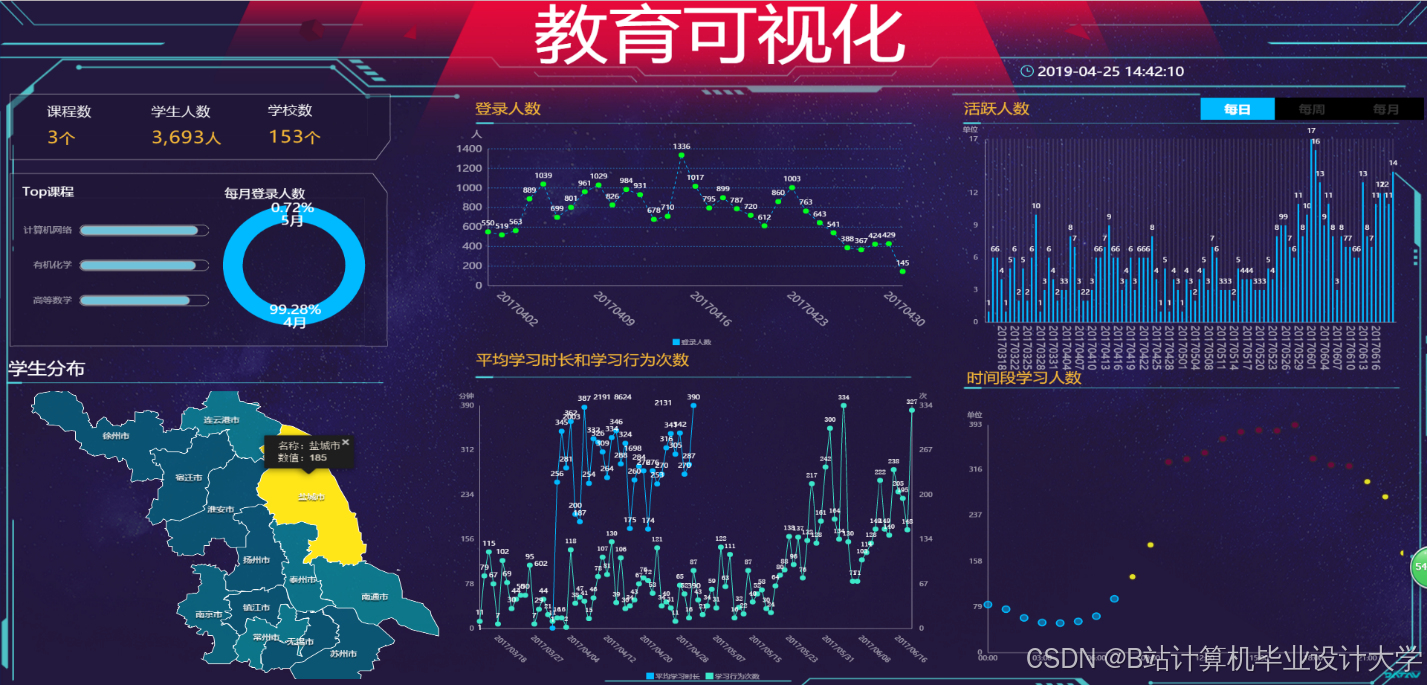
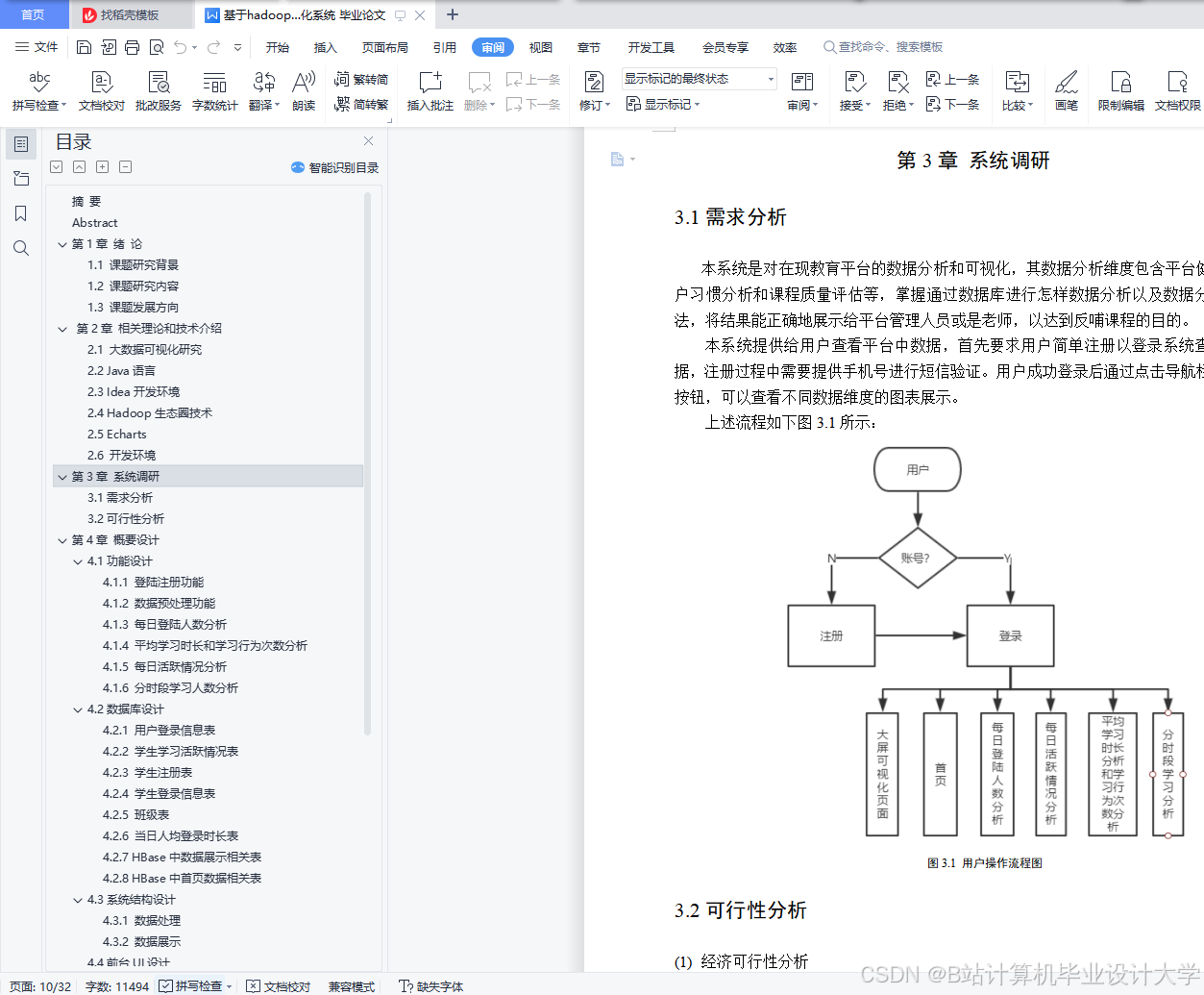
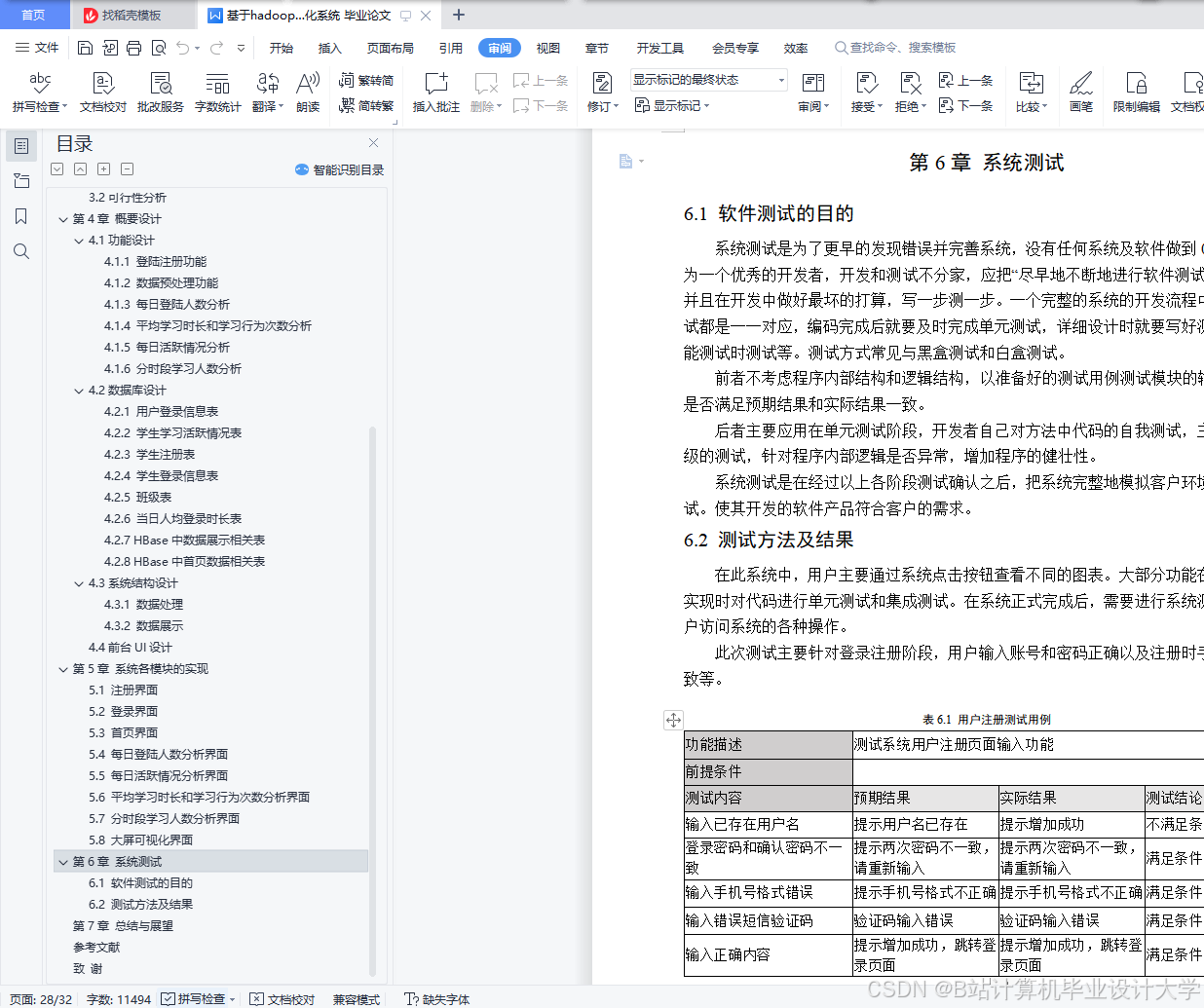
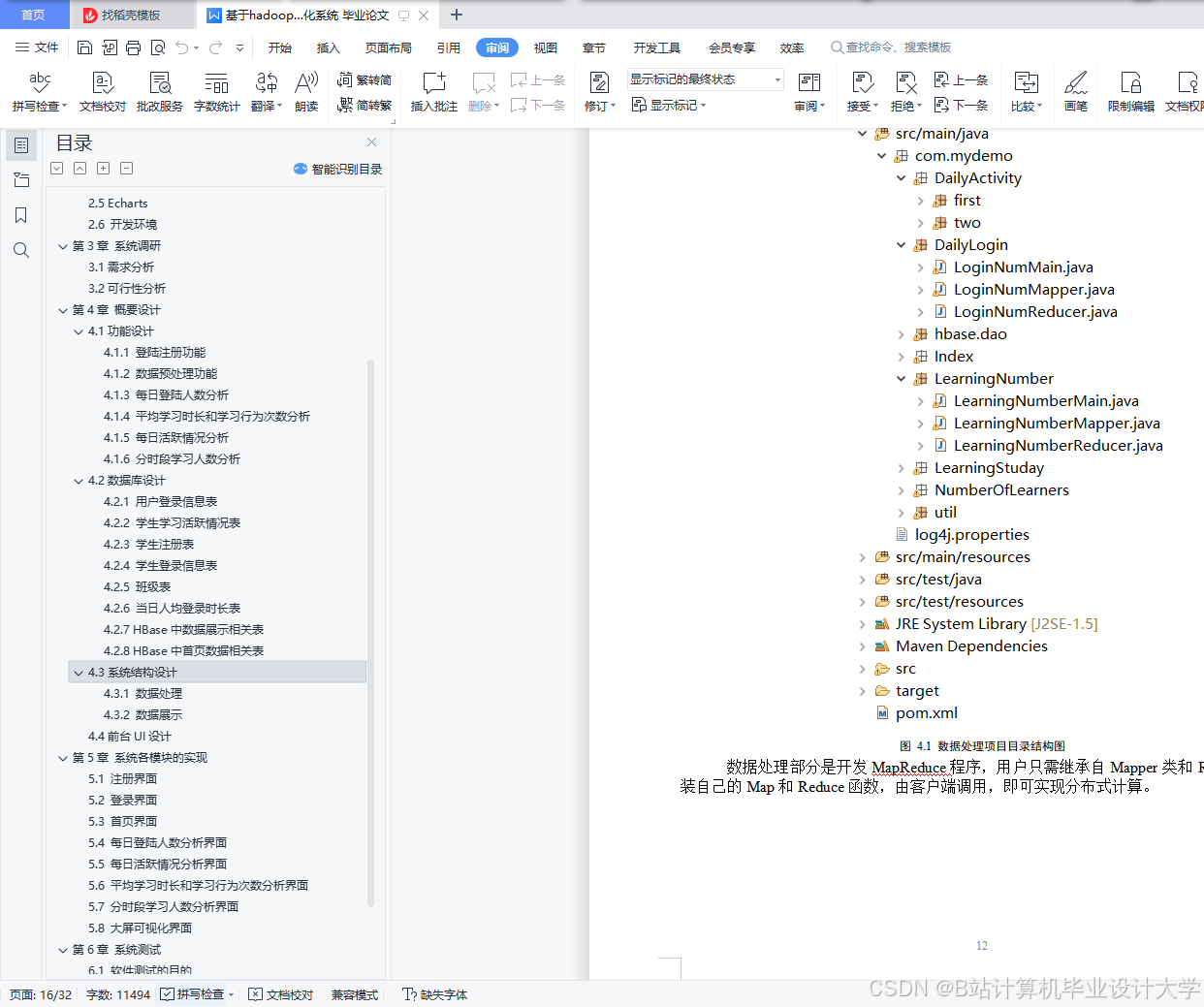
运行截图
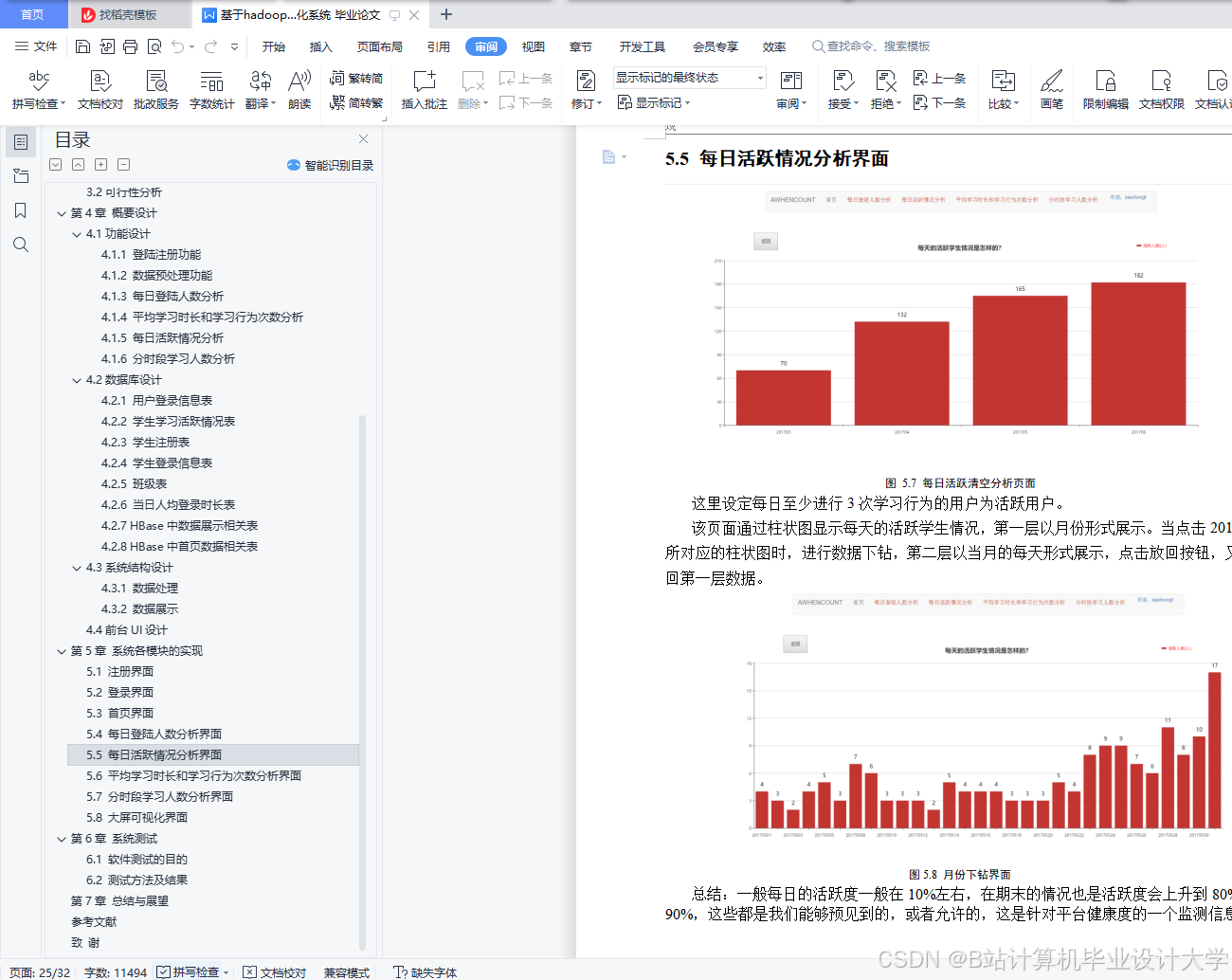
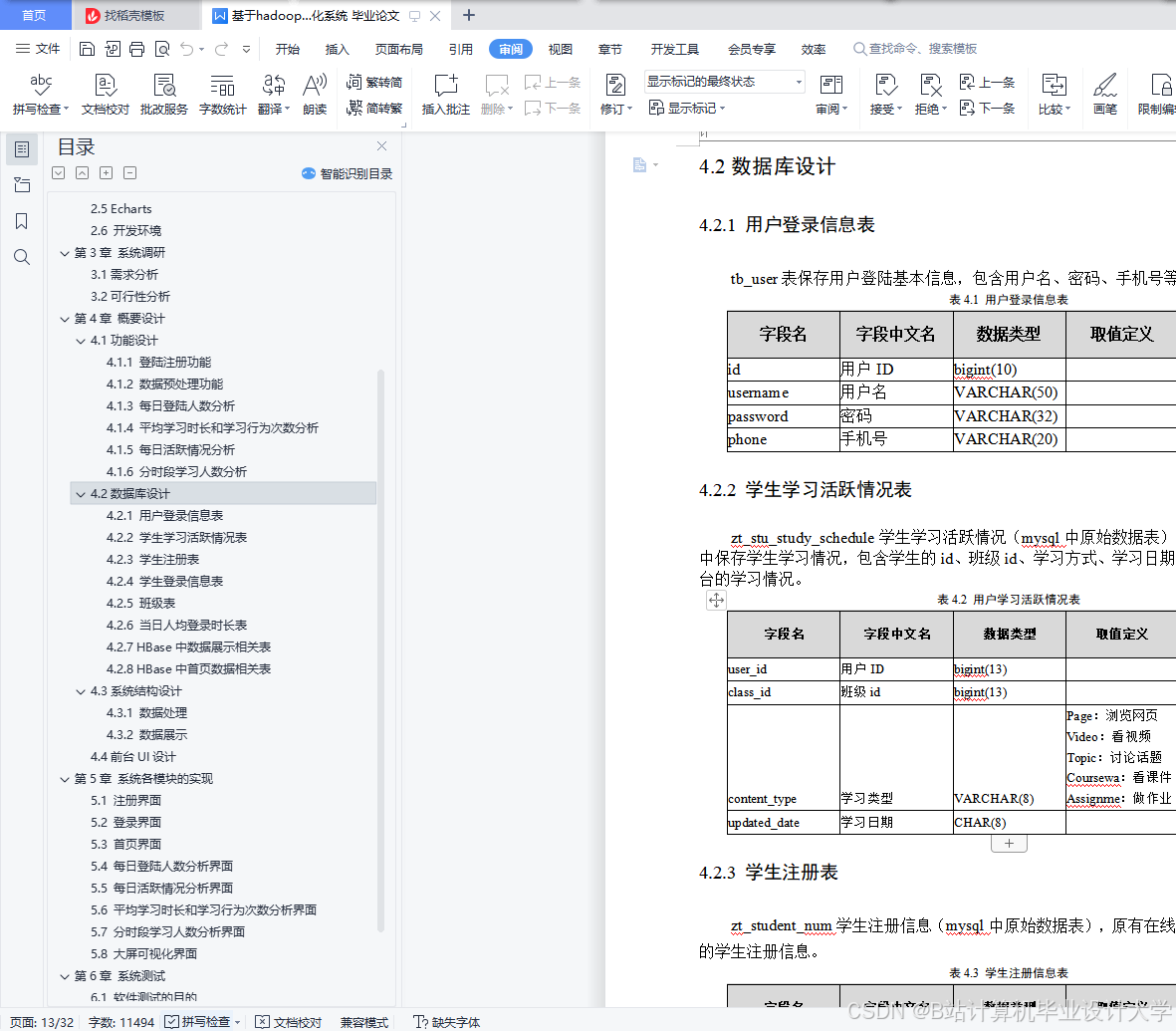
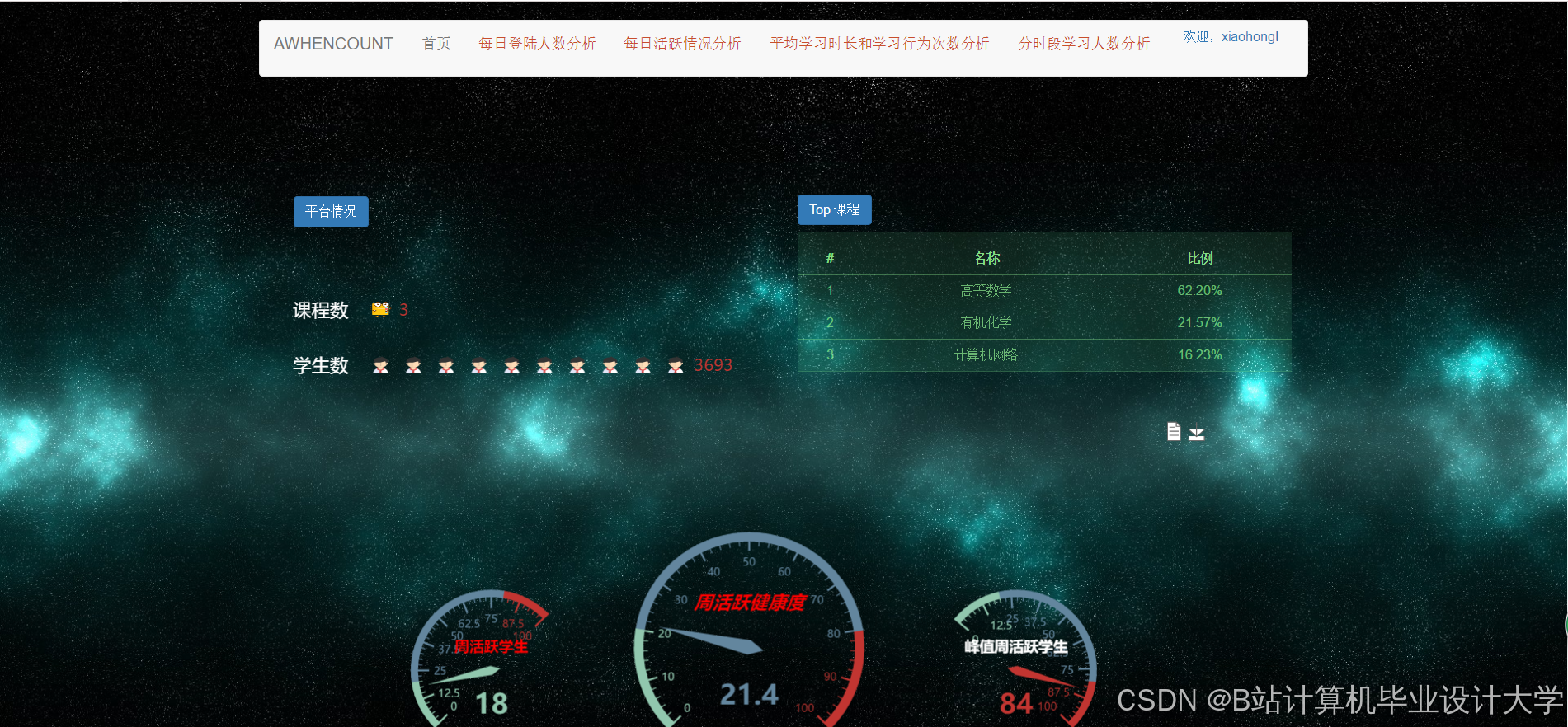

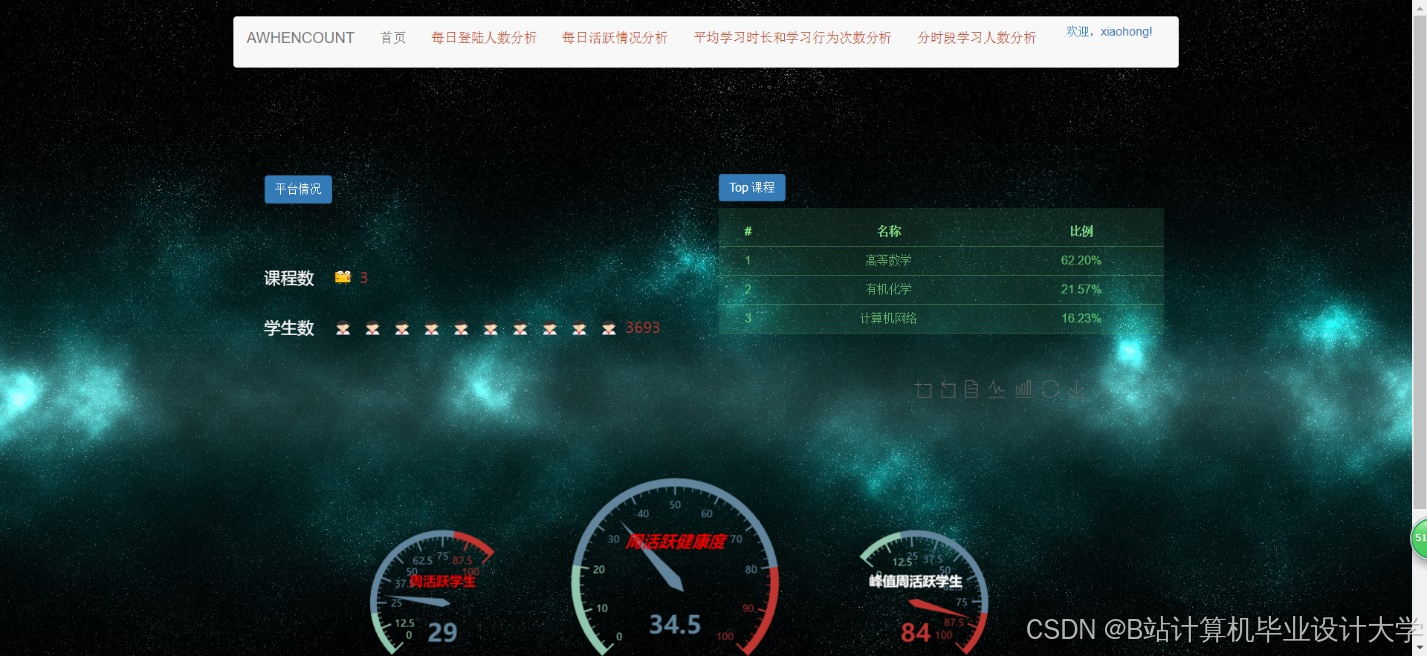
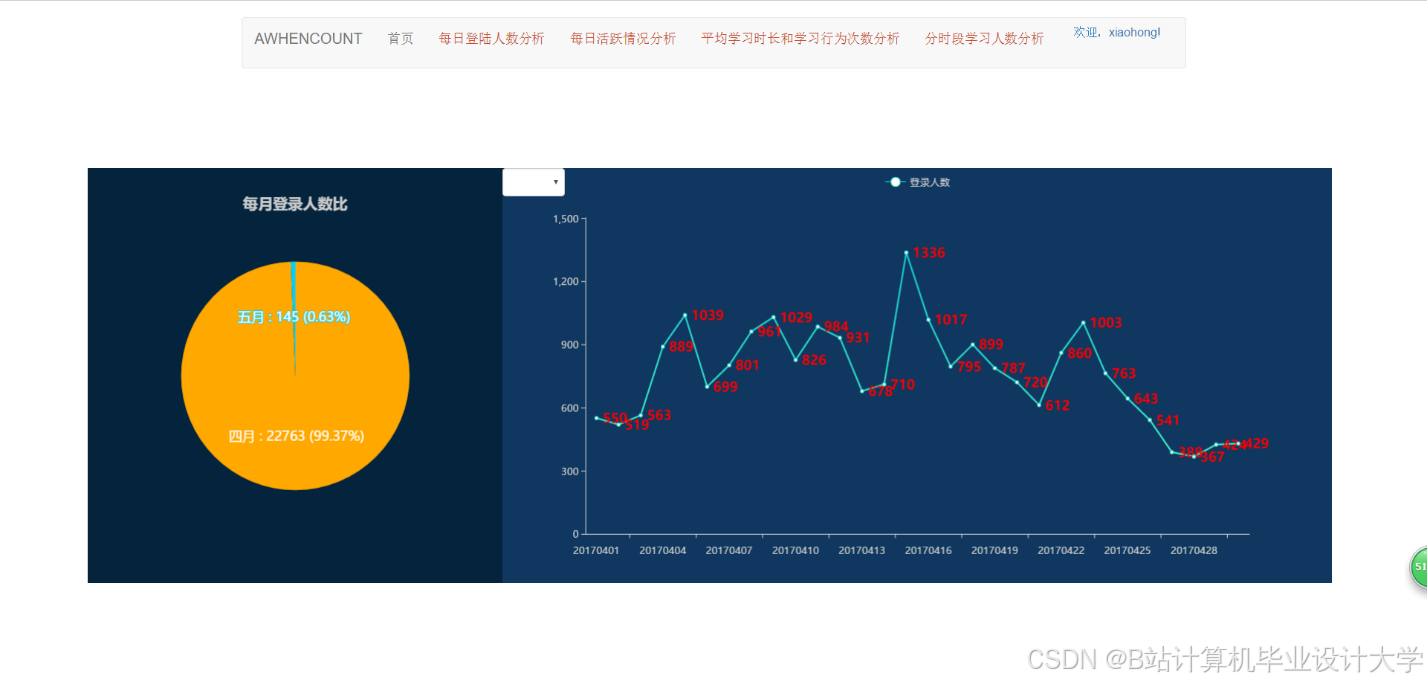
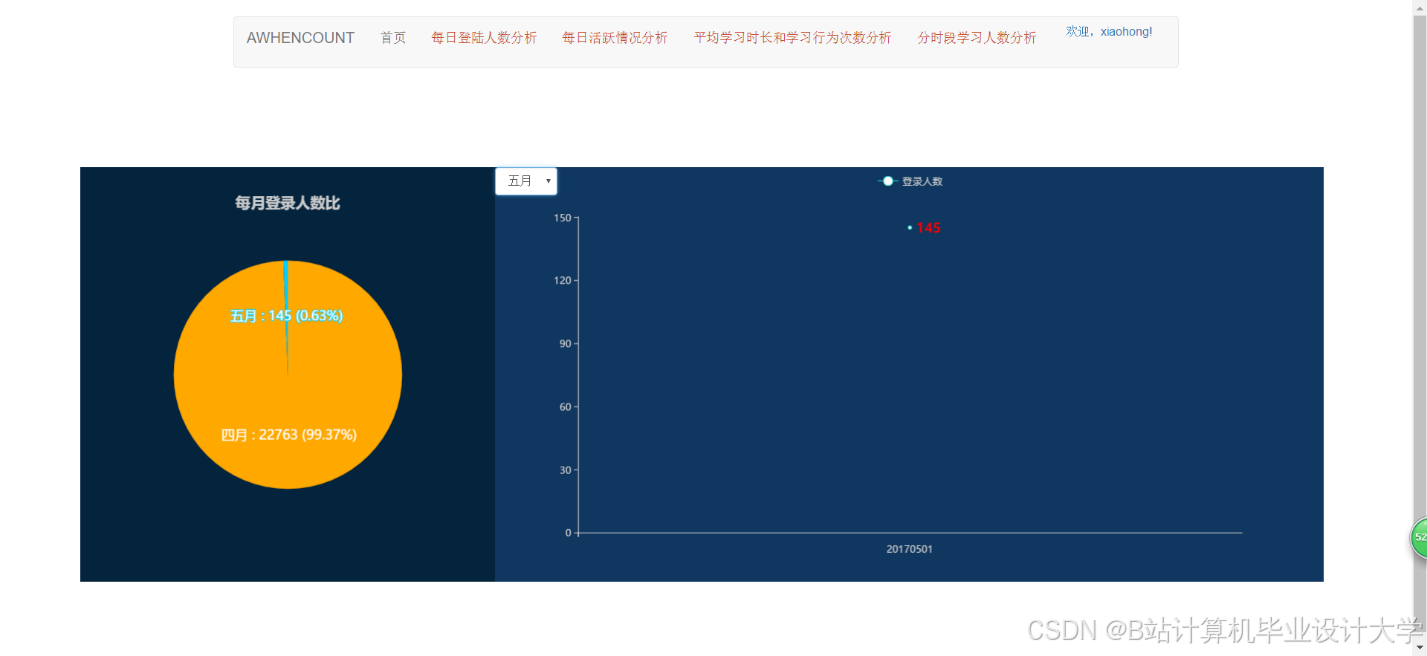
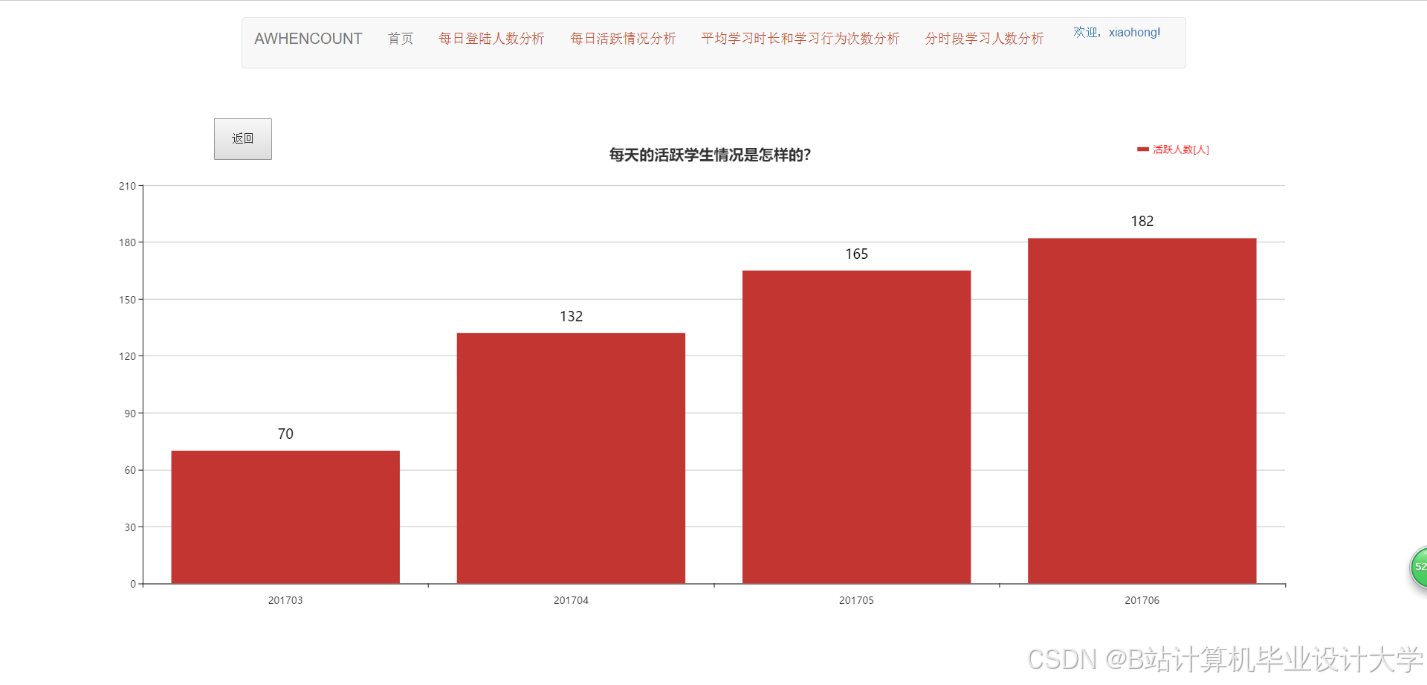
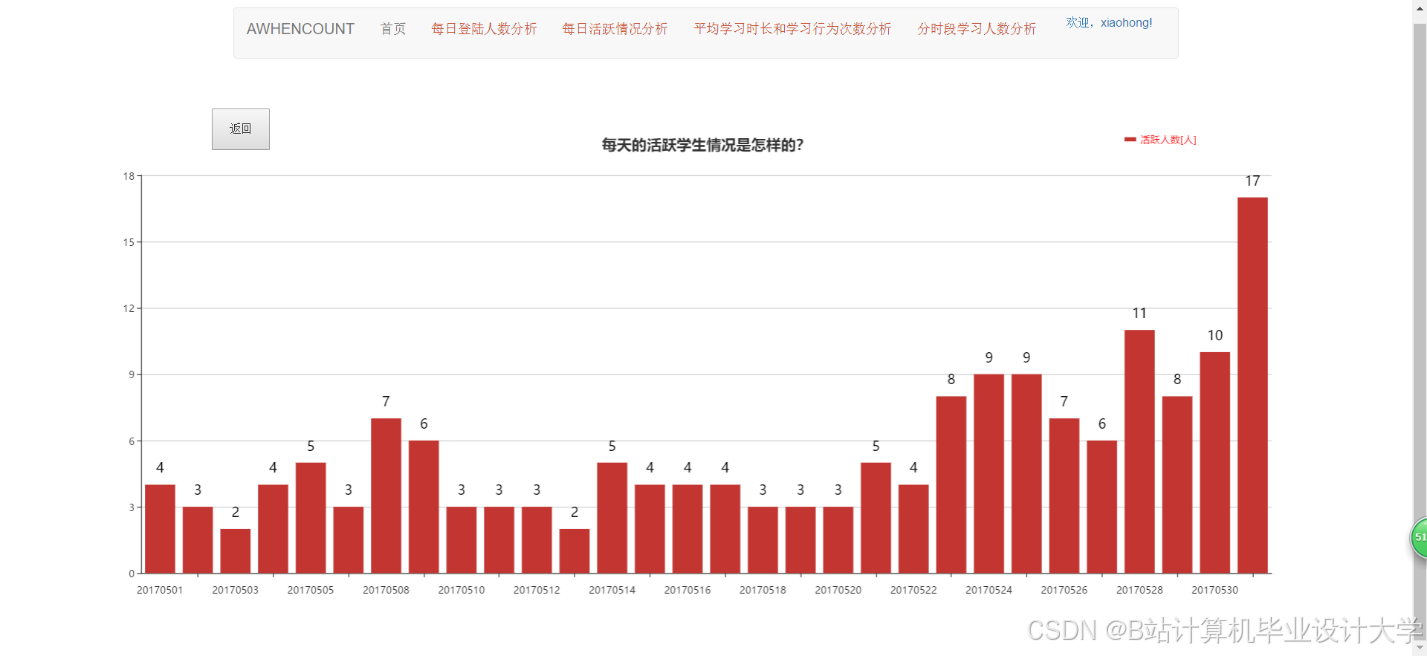
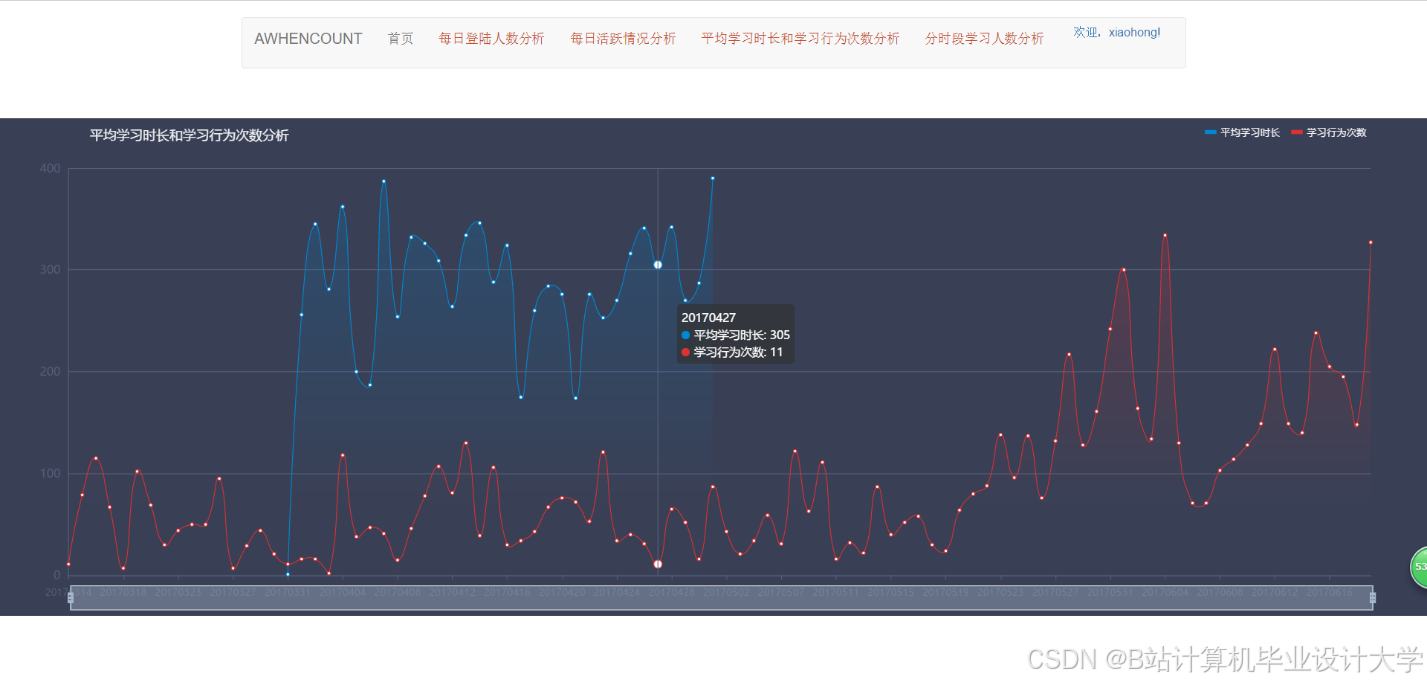
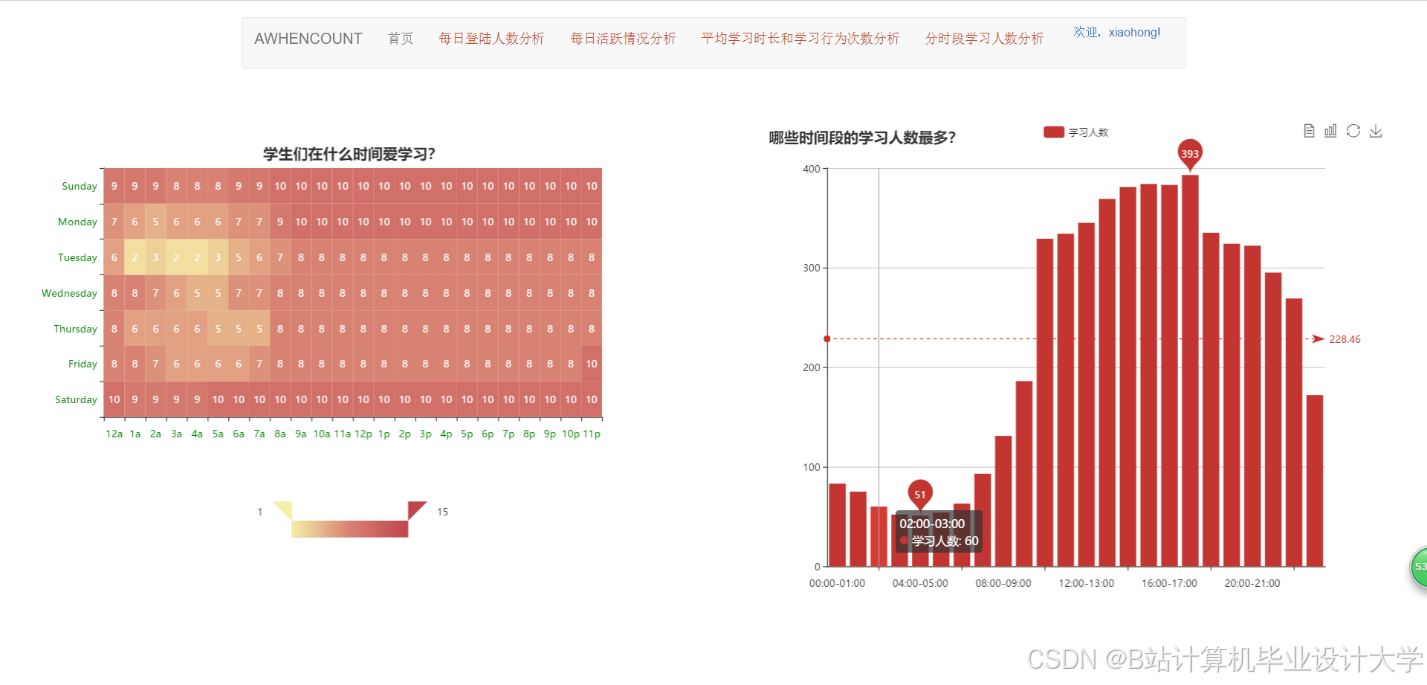
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











