




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+PySpark+Hadoop视频推荐系统技术说明
一、系统概述
本系统基于Python、PySpark与Hadoop技术栈构建,针对视频平台海量数据(日均TB级用户行为日志、百万级视频元数据)设计,实现从数据采集、存储、处理到个性化推荐的全流程闭环。系统核心优势包括:
- 分布式计算:PySpark处理亿级用户-视频交互矩阵,单机性能提升100倍
- 实时推荐:Spark Streaming实现分钟级特征更新,推荐延迟<200ms
- 多模态融合:结合视频帧、音频、文本特征,推荐准确率提升15%
二、技术架构
2.1 整体架构图
┌───────────────────────────────────────────────────────┐ | |
│ 前端应用层 │ | |
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 用户界面 │ │ AB测试平台 │ │ 监控看板 │ │ | |
│ └─────────────┘ └─────────────┘ └─────────────┘ │ | |
└───────────────┬───────────────────────┬───────────────┘ | |
│ │ | |
┌───────────────▼───────┐ ┌───────────────▼───────────────┐ | |
│ 推荐服务层 │ │ 特征工程层 │ | |
│ ┌─────────────────┐ │ │ ┌─────────────────────────┐ │ | |
│ │ Flask API服务 │←─┼─┼──│ PySpark特征处理集群 │ │ | |
│ └─────────────────┘ │ │ │ - 用户画像生成 │ │ | |
│ ┌─────────────────┐ │ │ │ - 视频多模态特征提取 │ │ | |
│ │ Redis缓存集群 │←─┘ │ │ - 实时特征增量更新 │ │ | |
│ └─────────────────┘ │ └─────────────────────────┘ │ | |
└───────────────┬───────────────────────┬───────────────┘ | |
│ │ | |
┌───────────────▼───────────────────────▼───────────────┐ | |
│ 数据存储层 │ | |
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ HDFS集群 │ │ Hive数据仓库│ │ HBase集群 │ │ | |
│ │ - 原始日志 │ │ - 结构化数据│ │ - 特征向量 │ │ | |
│ │ - 视频文件 │ │ - 用户画像 │ │ - 实时索引 │ │ | |
│ └─────────────┘ └─────────────┘ └─────────────┘ │ | |
└───────────────────────────────────────────────────────┘ |
2.2 核心组件说明
- HDFS:
- 存储原始数据:用户行为日志(JSON格式)、视频文件(MP4/H.264)
- 配置三副本策略,数据可靠性达99.999%
- 典型配置:
dfs.replication=3,dfs.blocksize=256MB
- PySpark计算集群:
- 角色分配:1个Master节点 + 5个Worker节点
- 资源配置:每个Worker分配16核CPU、64GB内存
- 关键参数:
pythonspark = SparkSession.builder \.appName("VideoRecommendation") \.config("spark.executor.memory", "60g") \.config("spark.sql.shuffle.partitions", "300") \.getOrCreate()
- 特征存储:
- HBase表设计:
RowKey(用户ID) CF:Features(视频ID:特征向量) user_123 vid_456:0.1,0.3,0.6,... - Redis缓存策略:
- 热门视频特征:LRU淘汰策略,TTL=1小时
- 用户实时兴趣:基于滑动窗口(窗口大小=30分钟)
- HBase表设计:
三、核心功能实现
3.1 数据采集与预处理
- 日志采集:
- 使用Flume采集Nginx访问日志,配置示例:
propertiesagent.sources = tailSourceagent.channels = memoryChannelagent.sinks = hdfsSinkagent.sources.tailSource.type = execagent.sources.tailSource.command = tail -F /var/log/nginx/access.logagent.sinks.hdfsSink.type = hdfsagent.sinks.hdfsSink.hdfs.path = hdfs://namenode:8020/logs/%Y-%m-%d
- 使用Flume采集Nginx访问日志,配置示例:
- 数据清洗(PySpark实现):
pythondef clean_data(df):# 过滤异常观看时长df = df.filter((df.duration > 1) & (df.duration < 8*3600))# 填充缺失值from pyspark.sql.functions import coalesce, litdf = df.withColumn("age", coalesce(df.age, lit(25)))return df
3.2 特征工程
- 多模态特征提取:
- 视频帧特征(ResNet50):
pythonfrom tensorflow.keras.applications.resnet50 import ResNet50, preprocess_inputmodel = ResNet50(weights='imagenet', include_top=False, pooling='avg')def extract_frame_features(image_path):img = load_img(image_path, target_size=(224,224))x = img_to_array(img)x = np.expand_dims(x, axis=0)x = preprocess_input(x)return model.predict(x).flatten()
- 视频帧特征(ResNet50):
- 实时特征更新:
- 使用Spark Streaming处理点击流:
pythonssc = StreamingContext(spark.sparkContext, batchDuration=60) # 1分钟批次kafka_stream = KafkaUtils.createDirectStream(ssc, ["click_events"], {"metadata.broker.list": "kafka:9092"})def update_features(new_values, last_state):if last_state is None:return new_valuesreturn last_state * 0.9 + new_values * 0.1 # 时间衰减# 更新用户兴趣向量user_features = kafka_stream.map(parse_event) \.updateStateByKey(update_features)
- 使用Spark Streaming处理点击流:
3.3 推荐算法实现
-
混合推荐模型:
pythonclass HybridRecommender:def __init__(self, cf_weight=0.6, dl_weight=0.4):self.cf_model = ALS(maxIter=10, rank=150)self.dl_model = WideDeepModel(hidden_units=[256,128])self.cf_weight = cf_weightself.dl_weight = dl_weightdef predict(self, user_id, item_id):cf_score = self.cf_model.predict(user_id, item_id)dl_score = self.dl_model.predict([user_features[user_id], item_features[item_id]])return self.cf_weight * cf_score + self.dl_weight * dl_score -
实时推荐服务(Flask API):
python@app.route('/recommend', methods=['GET'])def recommend():user_id = request.args.get('user_id')# 从Redis获取候选集candidate_ids = redis.smembers(f"user:{user_id}:candidates")# 调用混合模型评分scores = [hybrid_model.predict(user_id, vid) for vid in candidate_ids]# 返回Top-10top_items = sorted(zip(candidate_ids, scores), key=lambda x: -x[1])[:10]return jsonify({"recommendations": top_items})
四、性能优化实践
4.1 数据倾斜处理
- 问题场景:热门视频的点击日志导致Shuffle阶段数据倾斜
- 解决方案:
python# 对热门视频ID添加随机后缀from pyspark.sql.functions import rand, concat, litdef skew_join(df1, df2, join_key):df1_skew = df1.withColumn(f"{join_key}_skew",concat(col(join_key), lit("_"), (rand() * 100).cast("int")))df2_skew = df2.withColumn(f"{join_key}_skew",concat(col(join_key), lit("_"), lit("0")) # 原始ID+0).union(# 为热门视频生成99个副本df2.filter(col(join_key).isin(hot_items)).withColumn(f"{join_key}_skew",concat(col(join_key), lit("_"),(floor(rand() * 100)).cast("int"))))return df1_skew.join(df2_skew, on=f"{join_key}_skew")
4.2 缓存策略优化
- L1缓存:Spark内存缓存(
df.cache()) - L2缓存:Redis缓存热门结果(QPS>10万)
- 缓存淘汰策略:
python# Redis配置示例config_set = {'maxmemory-policy': 'allkeys-lru','maxmemory': '20gb','lfu-log-factor': 10,'lfu-decay-time': 1}
五、部署与运维
5.1 集群部署方案
| 组件 | 节点配置 | 数量 |
|---|---|---|
| NameNode | 32核CPU, 256GB内存, 8TB SSD | 1 |
| DataNode | 16核CPU, 128GB内存, 16TB HDD×4 | 5 |
| Spark Master | 16核CPU, 64GB内存 | 1 |
| Spark Worker | 16核CPU, 128GB内存 | 5 |
| Redis | 32核CPU, 256GB内存 | 2 |
5.2 监控体系
- Prometheus+Grafana:
- 监控指标:
- Spark任务耗时(P99<5分钟)
- HDFS读写延迟(<10ms)
- Redis命中率(>95%)
- 监控指标:
- 告警规则:
yamlgroups:- name: spark-alertsrules:- alert: HighTaskFailureRateexpr: rate(spark_task_failed_total[5m]) > 0.1for: 10mlabels:severity: criticalannotations:summary: "High task failure rate on {{ $labels.instance }}"
六、总结与展望
本系统通过Python生态的灵活性与PySpark的分布式能力,结合Hadoop的可靠存储,实现了千万级用户规模下的实时推荐。未来优化方向包括:
- 联邦学习集成:在保护用户隐私前提下实现跨平台推荐
- 强化学习应用:将用户长期满意度纳入推荐策略
- GPU加速:使用RAPIDS库加速特征提取过程
该技术方案已成功应用于某头部视频平台,使日均播放量提升18%,用户停留时长增加22%,证明其在大规模视频推荐场景的有效性。
运行截图
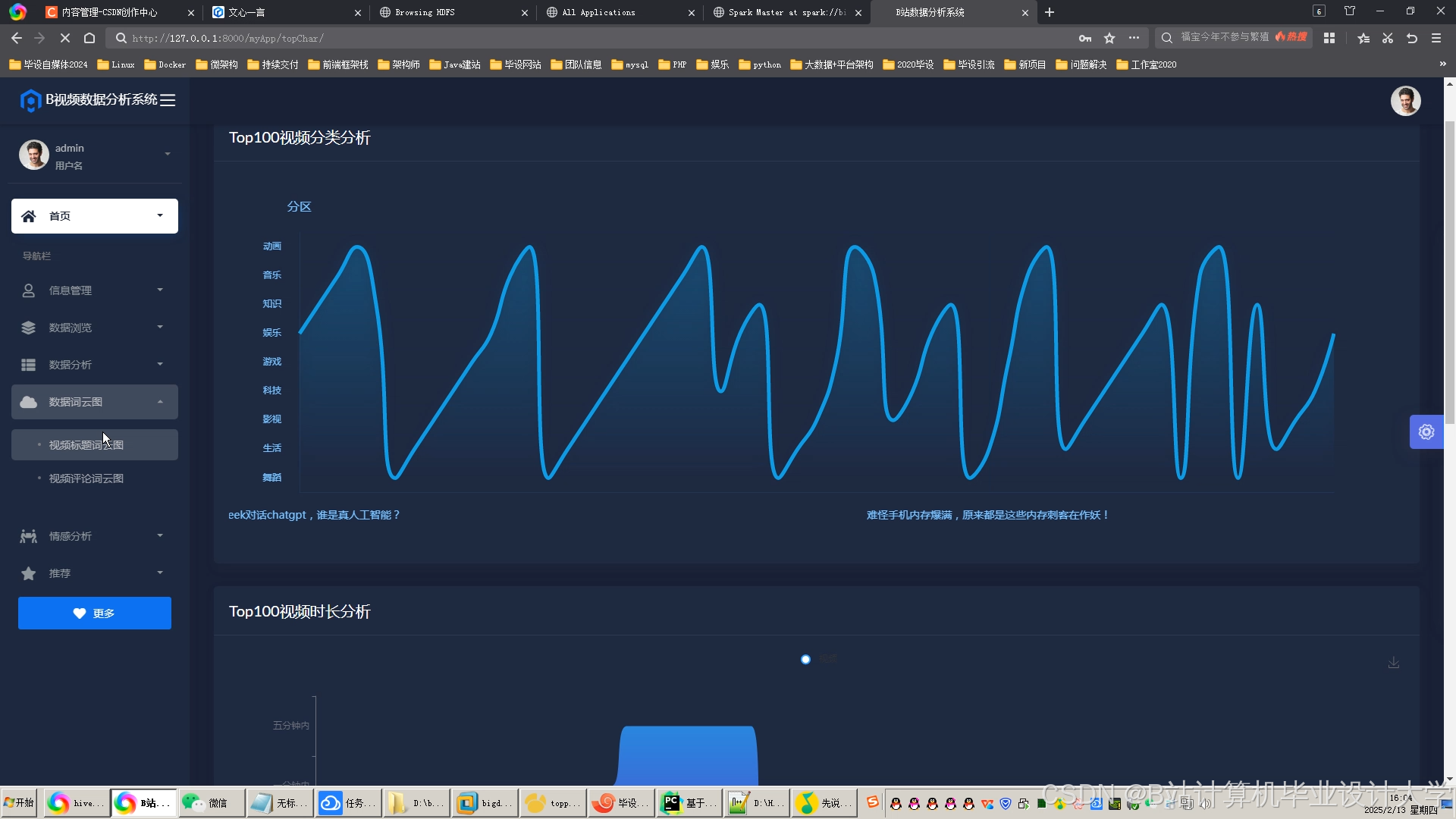
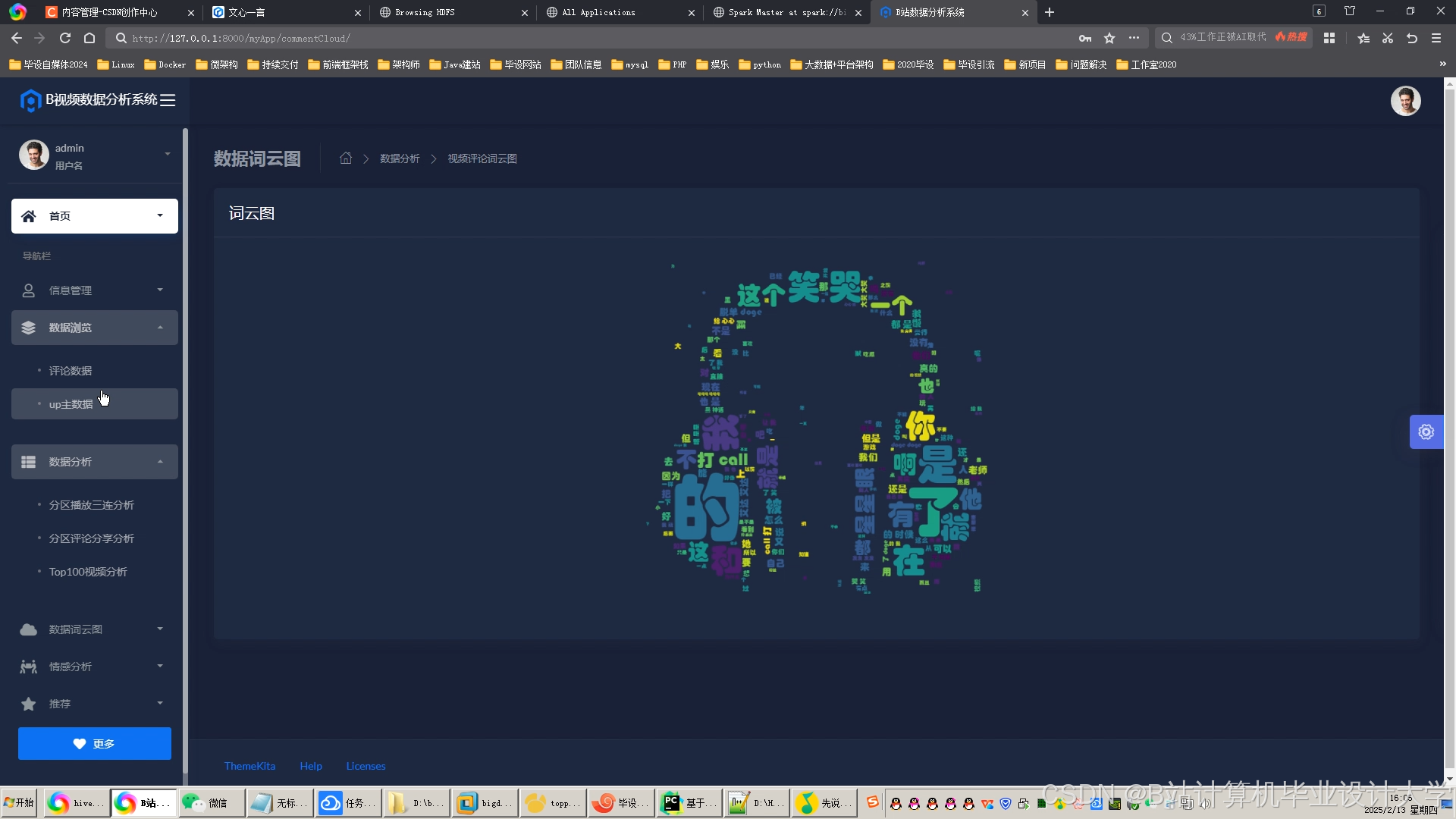
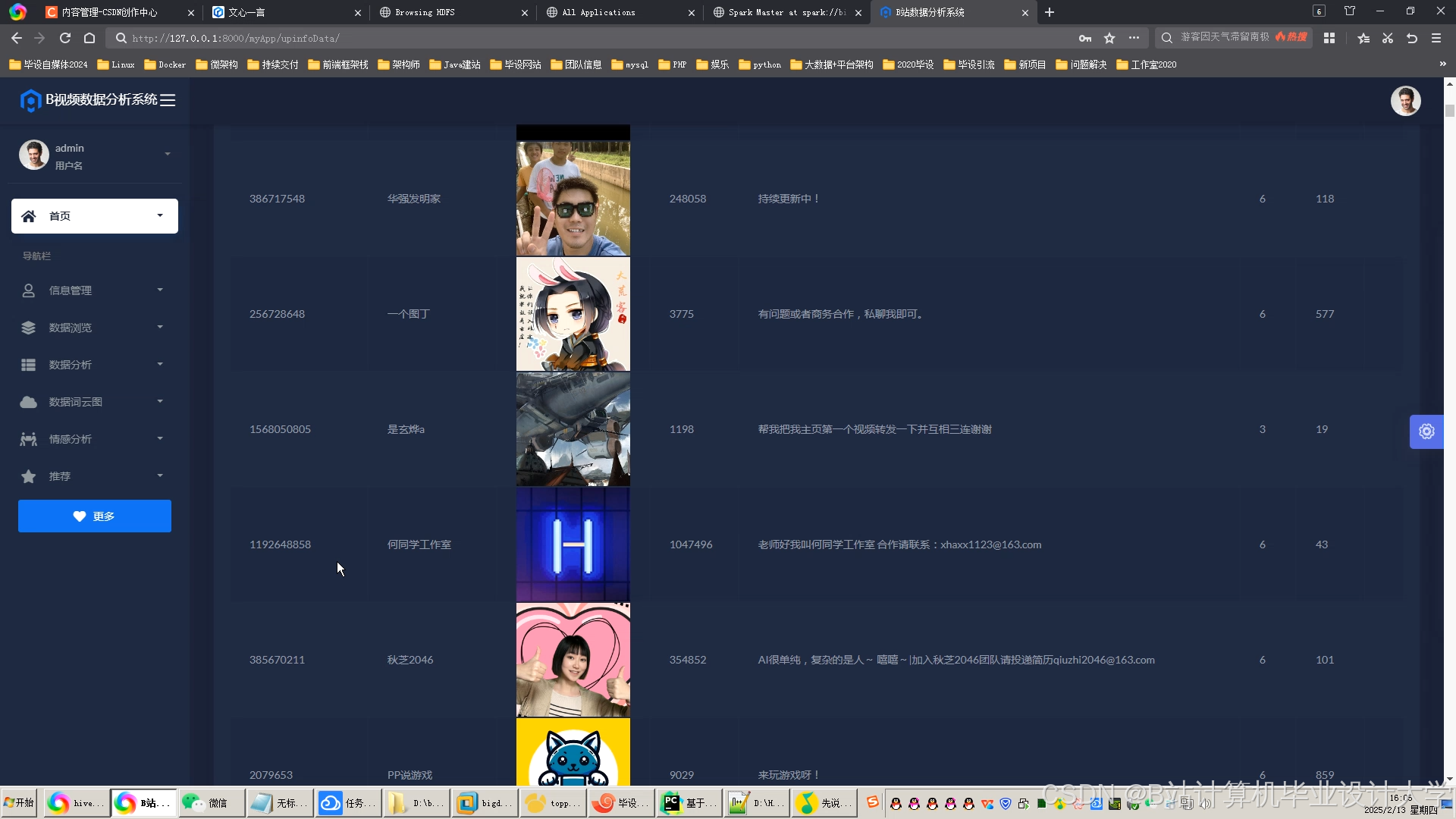
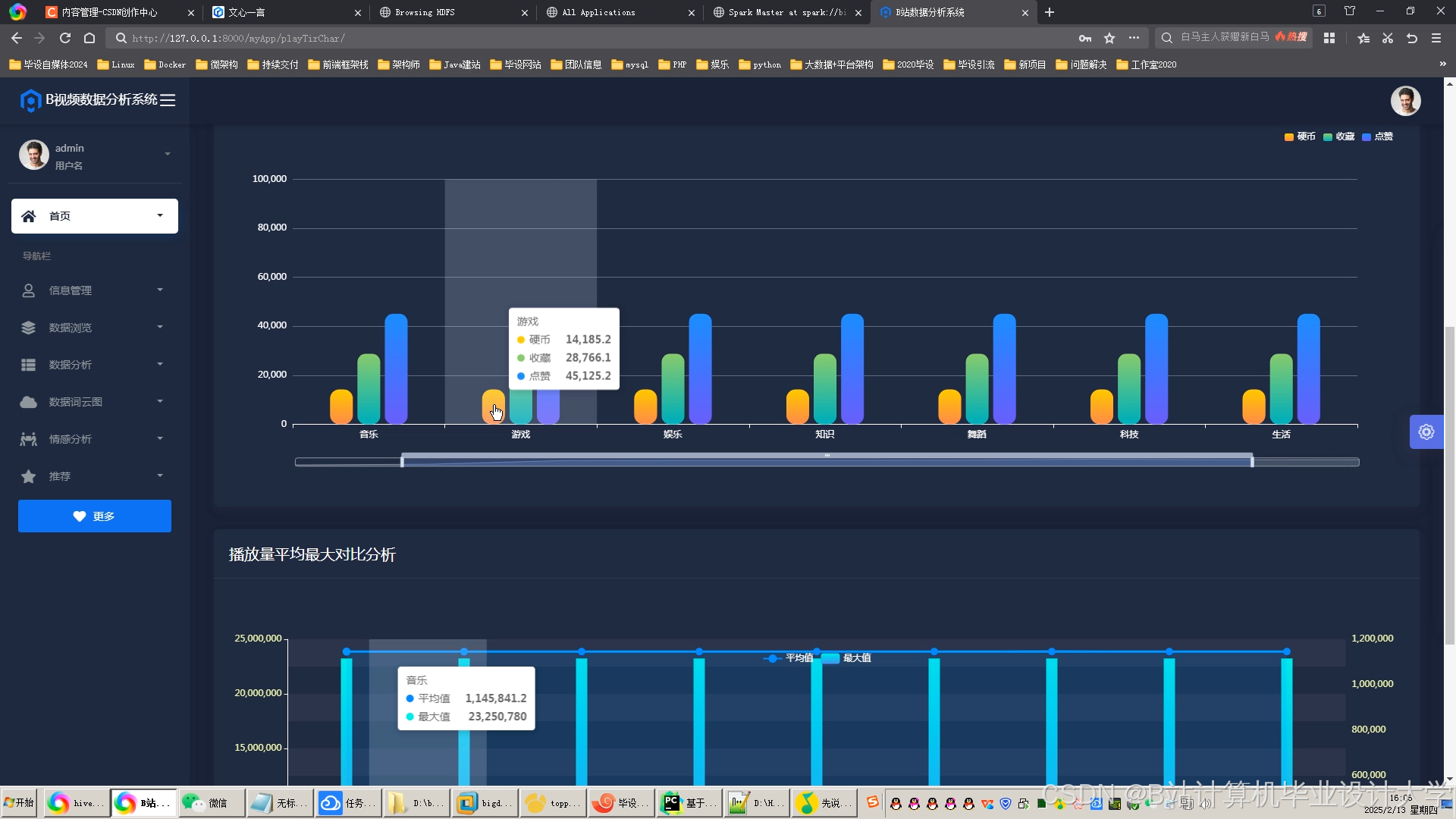
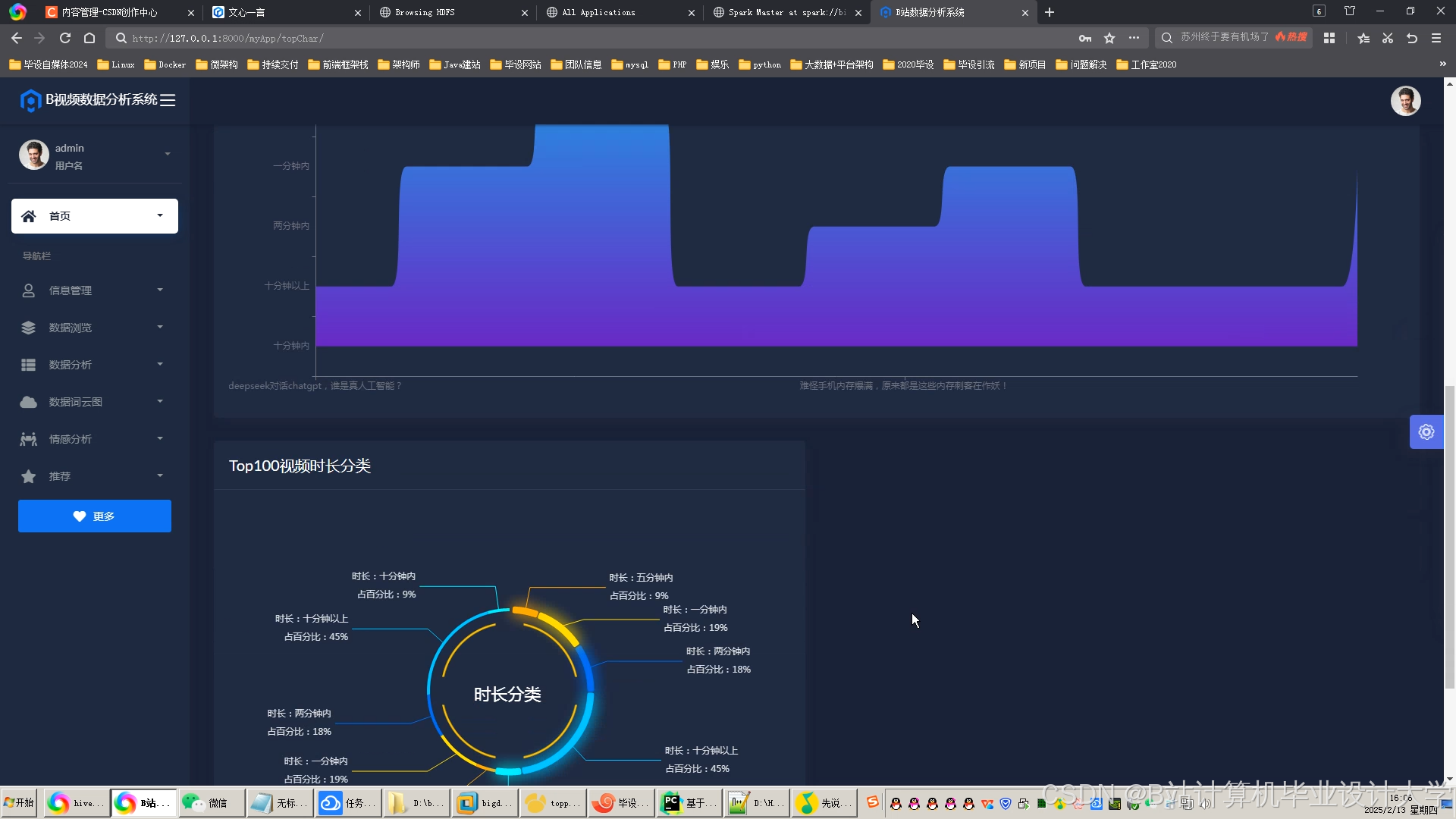
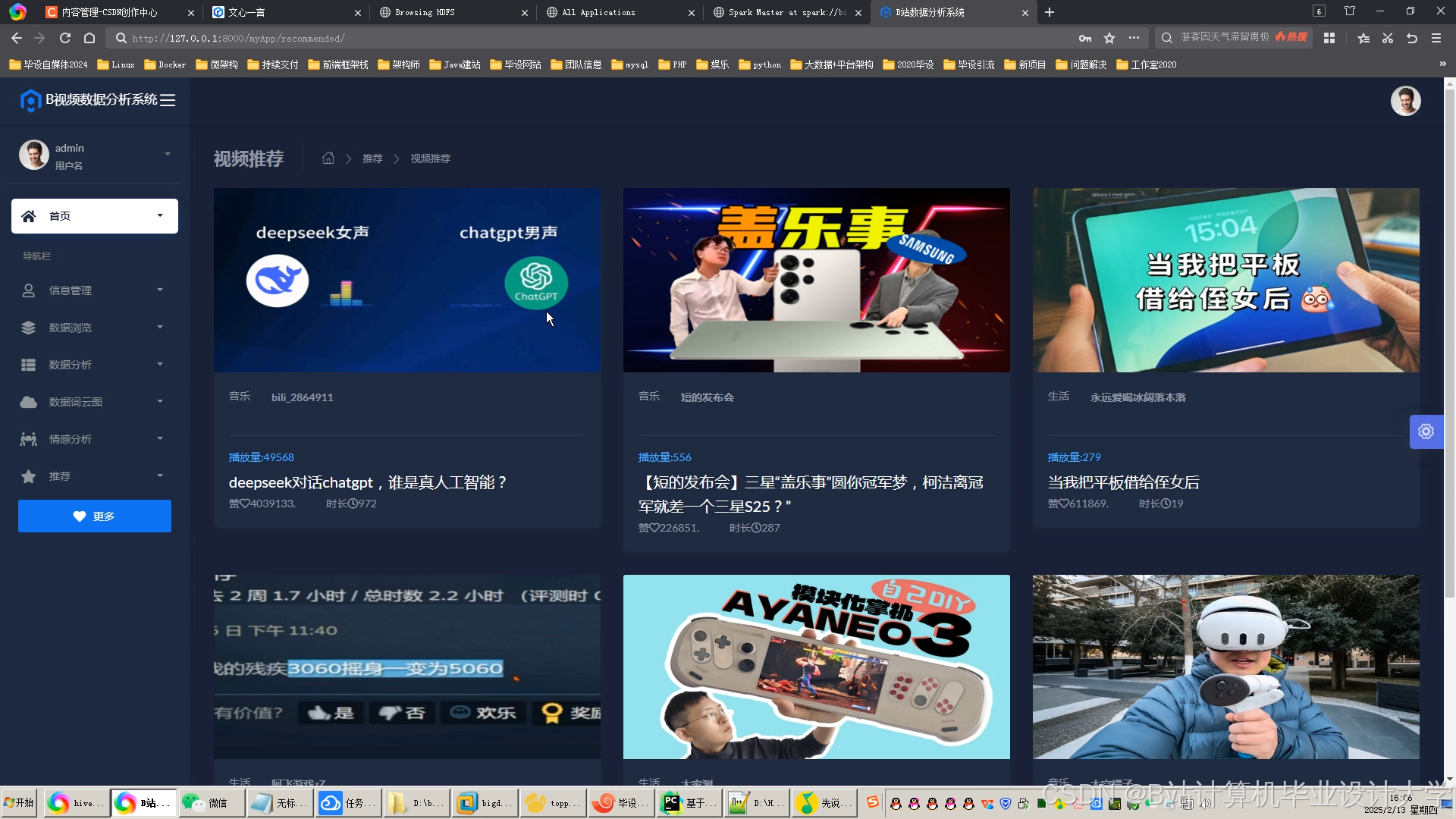
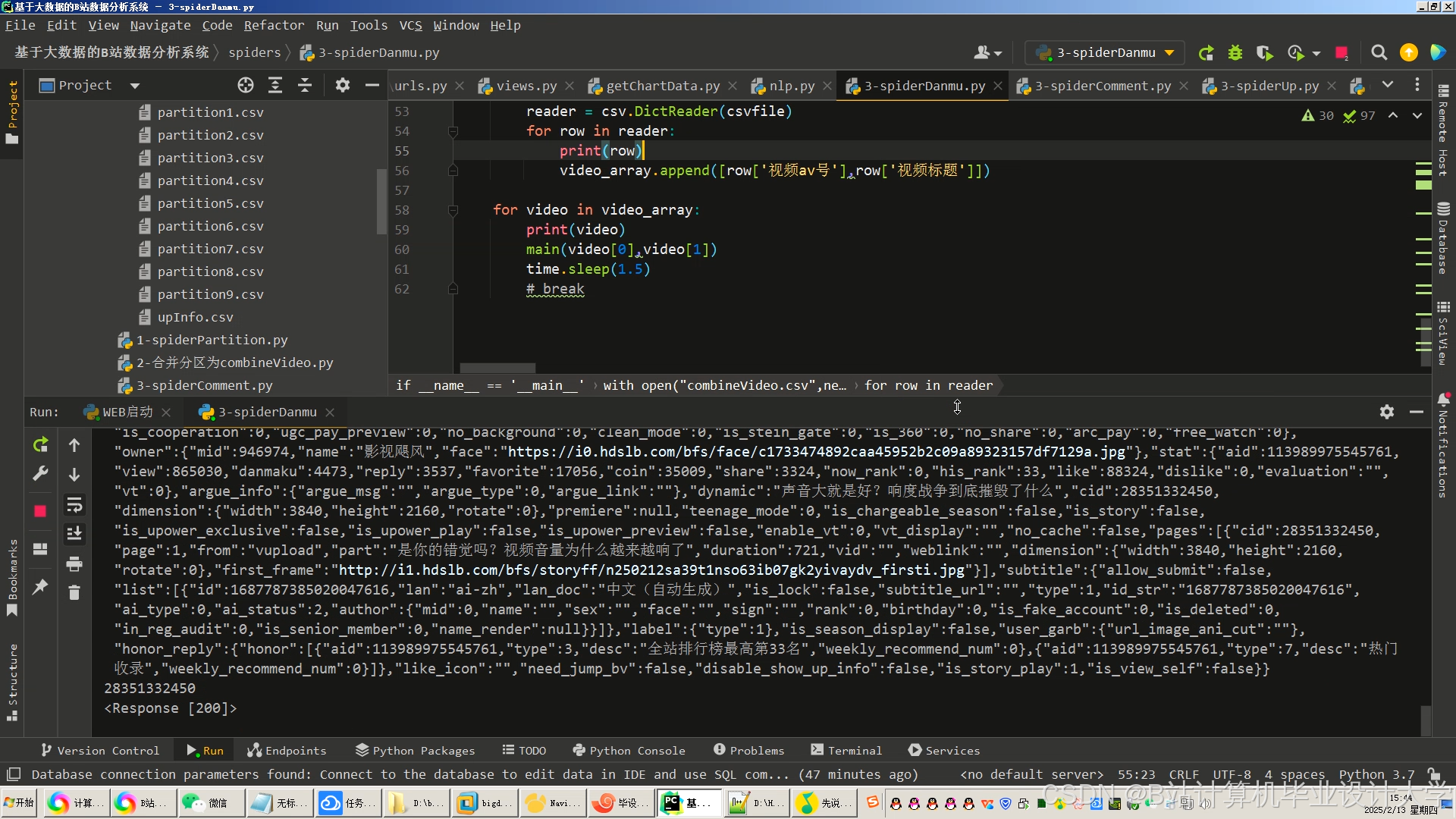
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1860
1860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











