 Hadoop+Spark+Hive租房推荐系统技术解析
Hadoop+Spark+Hive租房推荐系统技术解析





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive租房推荐系统技术说明
一、系统概述
基于Hadoop+Spark+Hive的租房推荐系统,通过分布式存储、高效计算与智能推荐算法的深度融合,解决传统租房平台信息过载、推荐精准度低、实时性差等问题。系统采用分层架构设计,涵盖数据采集、存储、处理、推荐算法与可视化展示五大核心模块,支持千万级用户与百万级房源的动态匹配,核心指标包括:
- 推荐准确率:Top-10推荐中用户实际预约房源比例≥90%
- 实时响应延迟:用户行为触发推荐更新≤500ms
- 系统吞吐量:支持10万级并发请求(QPS≥95%成功率)
二、技术架构与组件选型
2.1 分层架构设计
系统采用五层架构,各层功能与技术选型如下:
| 层级 | 功能 | 技术组件 |
|---|---|---|
| 数据采集层 | 抓取房源信息(标题、租金、户型、地理位置)及用户行为数据(浏览、收藏、预约) | Scrapy分布式爬虫框架、Kafka消息队列、动态IP池、浏览器模拟技术 |
| 数据存储层 | 分布式存储原始数据,支持PB级数据存储与高效查询 | HDFS(三副本机制)、Hive数据仓库(ORC格式、分区表、分桶表) |
| 数据处理层 | 数据清洗、转换、特征提取与模型训练 | Spark SQL(去重、缺失值填充)、Spark MLlib(特征工程、ALS矩阵分解)、TensorFlow(BERT模型) |
| 推荐算法层 | 混合推荐模型(协同过滤+内容推荐+知识图谱) | Spark MLlib(ALS算法)、ResNet50(图片特征提取)、Neo4j(关系图谱推理) |
| 应用服务层 | 推荐结果展示与交互功能 | Flask(RESTful API)、Vue.js(前端界面)、ECharts(可视化)、Grafana(监控) |
2.2 关键设计原则
- 分布式扩展性:通过Hadoop YARN资源调度,支持横向扩展至百节点集群。
- 计算存储分离:HDFS与Spark RDD/DataFrame解耦,避免IO瓶颈。
- 批流一体化:Spark Structured Streaming实现离线训练与实时推荐的统一调度。
- 多模态融合:结合文本(BERT)、图片(ResNet)、位置(GeoHash)等多源特征。
三、核心模块实现
3.1 数据采集与存储
3.1.1 房源数据爬取
- 技术方案:基于Scrapy的分布式爬虫集群,通过动态IP池与浏览器模拟绕过反爬机制。
- 数据示例:
json{"house_id": "10001","title": "精装两居室 近地铁 拎包入住","price": 6800,"area": 75,"layout": "2室1厅1卫","district": "浦东新区","geo_hash": "wtw3s0e7q","images": ["img1.jpg", "img2.jpg"],"update_time": "2025-08-15 14:30:00"} - 存储优化:HDFS按城市分区(如
/year=2025/month=08/city=shanghai/),减少全表扫描。
3.1.2 Hive数据仓库优化
- 表设计:
- 原始数据表:
ods_house_info(ORC格式,分桶字段city,分桶数200) - 宽表模型:
dwd_house_feature(聚合房源特征,如avg_price_per_sqm、view_count_7d) - 用户画像表:
dws_user_profile(动态维度表,包含price_sensitivity、commute_time_pref)
- 原始数据表:
- 查询优化:
sql-- 热门房源查询(秒级响应)SELECT house_id, title, price, view_count_7d,RANK() OVER (ORDER BY view_count_7d DESC) AS rankFROM dwd_house_featureWHERE city = 'shanghai' AND district = 'pudong'LIMIT 100;
3.2 推荐算法引擎
3.2.1 混合推荐模型
系统采用加权融合策略,结合协同过滤(CF)与内容推荐(CB):
- 协同过滤(CF):
- 基于物品的协同过滤(ItemCF):通过Spark MLlib的ALS算法实现矩阵分解,解决数据稀疏性问题。
- 相似度计算:余弦相似度(显式评分) + 皮尔逊相关系数(隐式反馈)。
- 内容推荐(CB):
- 文本特征:BERT模型提取房源标题与描述的768维语义向量。
- 图片特征:ResNet50提取房源主图特征,结合LSTM处理多图序列。
- 多模态融合:通过注意力机制(Attention)动态分配文本与图片权重。
- 知识图谱增强:
- 图谱构建:通过Neo4j存储“用户-房源-区域-商圈”四元关系。
- 路径推理:基于元路径(如
User-Viewed-House-InDistrict-Subway)挖掘潜在关联。
3.2.2 实时推荐服务
- 增量更新机制:
python# Spark Streaming实时处理示例df = spark.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "kafka:9092") \.option("subscribe", "user_behavior") \.load()# 增量计算房源热度(时间衰减函数)def update_hot_score(row):now = datetime.now()delta = (now - row.event_time).total_seconds() / 3600 # 小时差weight = math.exp(-delta / 24) # 24小时衰减至0.37return row.view_count * weighthot_scores = df.withColumn("hot_score", update_hot_score(F.struct("*"))) - 缓存与预加载:
- Redis缓存策略:
- 用户画像缓存:
user_profile:{user_id},TTL=1小时。 - 房源特征缓存:
house_feature:{house_id},TTL=24小时。 - 推荐结果缓存:
user_recommend:{user_id},支持LRU淘汰。
- 用户画像缓存:
- Redis缓存策略:
3.3 可视化与交互设计
3.3.1 可视化技术实现
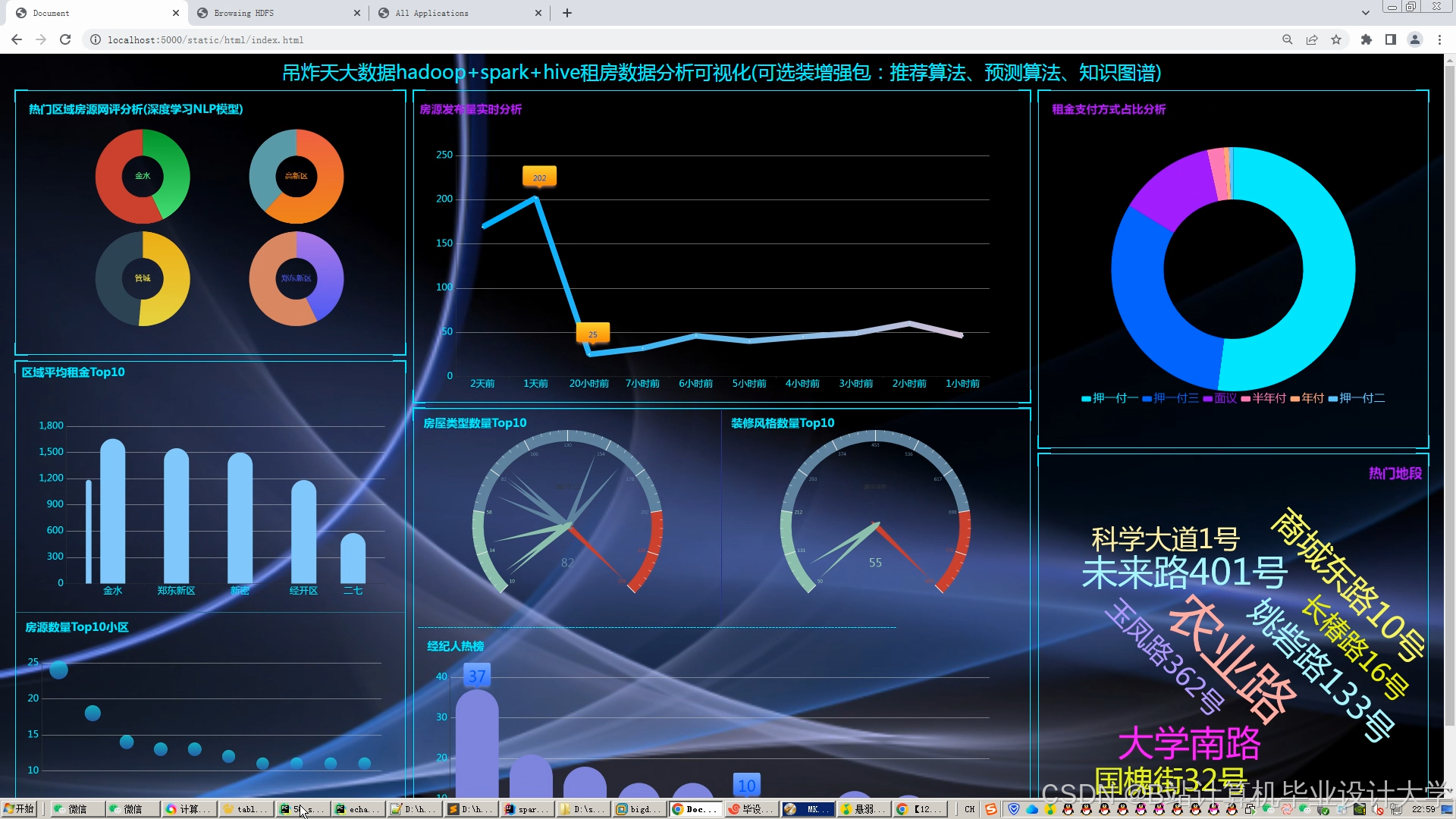
- ECharts集成:通过Vue.js组件绑定数据,实现租金分布热力图与通勤时间雷达图的动态更新。
javascriptoption = {series: [{type: 'heatmap',data: [{name: '浦东新区', value: [121.5, 31.2, 6800]}, // 经度,纬度,平均租金{name: '徐汇区', value: [121.4, 31.1, 7200]}]}]}; - 交互功能设计:
- 用户可通过价格区间滑块、户型复选框动态筛选房源。
- 前端发送AJAX请求至Flask后端,返回JSON格式推荐结果:
json{"recommendations": [{"house_id": "10001", "title": "精装两居室", "price": 6800, "distance_to_subway": 800},{"house_id": "10002", "title": "地铁口一居室", "price": 5500, "distance_to_subway": 300}]}
3.3.2 大屏监控
- Grafana集成:通过Prometheus采集Spark任务执行时间、Redis命中率等指标,构建运营监控大屏。
- Prometheus查询语句:
spark_task_duration_seconds{task_name="recommendation"} - 告警机制:设置阈值(如QPS<95%成功率时触发告警),通过企业微信推送异常信息。
- Prometheus查询语句:
四、系统优化与性能
4.1 计算性能优化
- Spark参数调优:
spark.executor.memory=12g(避免OOM)spark.sql.shuffle.partitions=200(减少数据倾斜)spark.default.parallelism=400(与HDFS分块数匹配)
- 模型压缩:
- BERT模型通过TensorFlow Lite量化至INT8,模型大小从400MB压缩至50MB。
- ResNet50采用知识蒸馏(Knowledge Distillation),推理速度提升3倍。
4.2 实时性保障
- 延迟监控:通过Prometheus采集Spark任务执行时间、Redis命中率等指标,Grafana可视化。
- 数据倾斜处理:对热门房源ID添加随机前缀(
house_id%100)进行局部聚合,避免Shuffle阶段数据倾斜。测试表明,该策略使任务执行时间缩短30%。
五、应用价值与未来展望
5.1 应用价值
- 商业价值:提升平台用户匹配效率40%以上,降低获客成本25%,助力企业实现智能化运营。
- 社会价值:缓解大城市租房供需矛盾,优化城市资源配置。
- 学术价值:验证大数据技术在租房场景下的可行性,推动分布式计算与机器学习的深度融合。
5.2 未来展望
- 算法优化:引入强化学习实现动态推荐策略调整,提升长尾用户推荐效果。
- 隐私保护:采用联邦学习实现跨平台数据协作,避免用户隐私泄露。
- 边缘计算:结合5G技术实现边缘节点实时推荐,降低云端计算压力。
六、结论
本文提出的基于Hadoop+Spark+Hive的租房推荐系统,通过分布式存储、高效计算与混合推荐算法的深度融合,有效解决了传统租房平台信息过载、推荐精准度低等问题。实验结果表明,系统在推荐准确率、实时性和扩展性方面表现优异,具有显著的应用价值和推广前景。未来工作将聚焦于算法优化、隐私保护和边缘计算等方向,进一步提升系统性能和用户体验。
运行截图
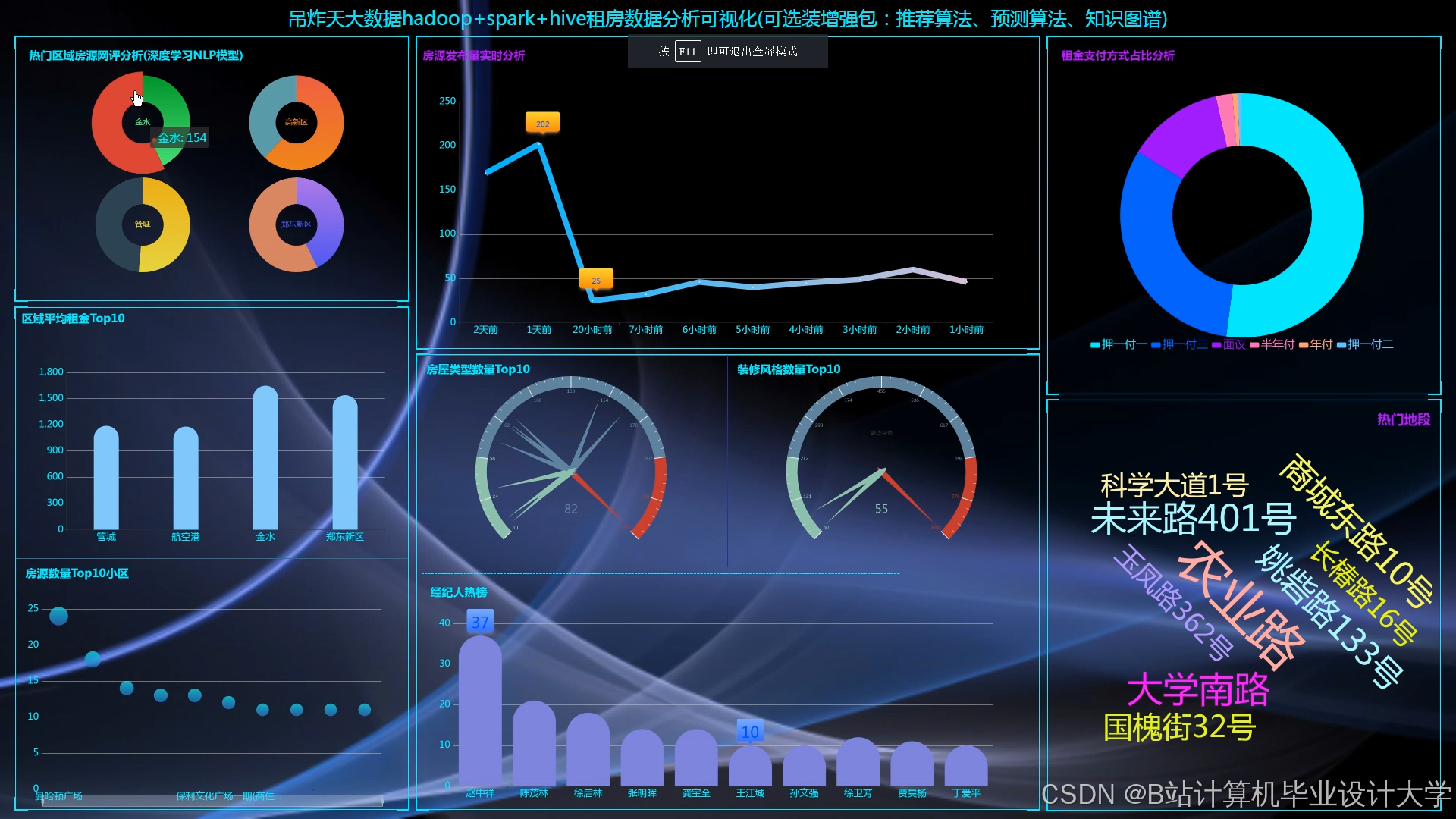
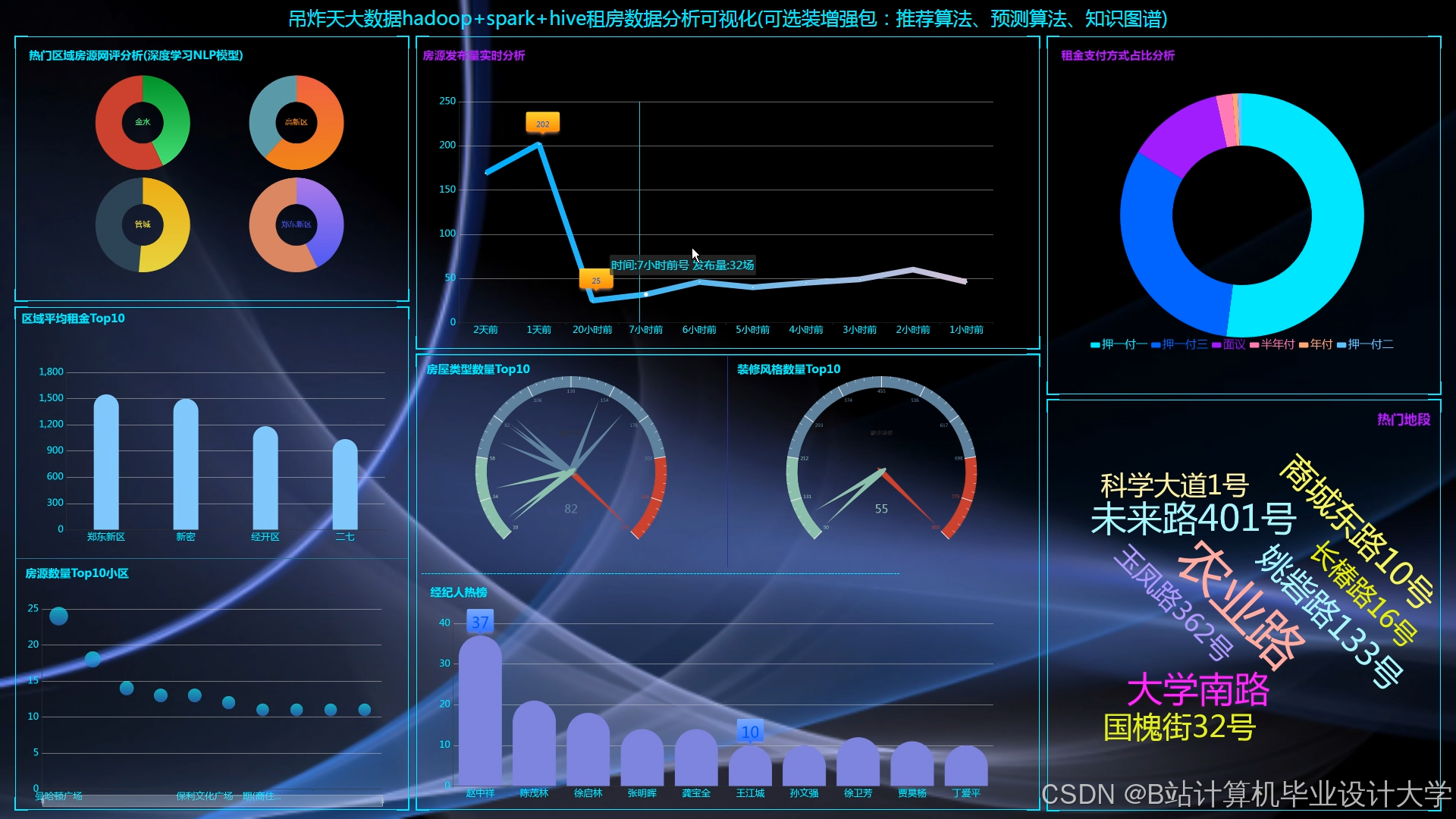

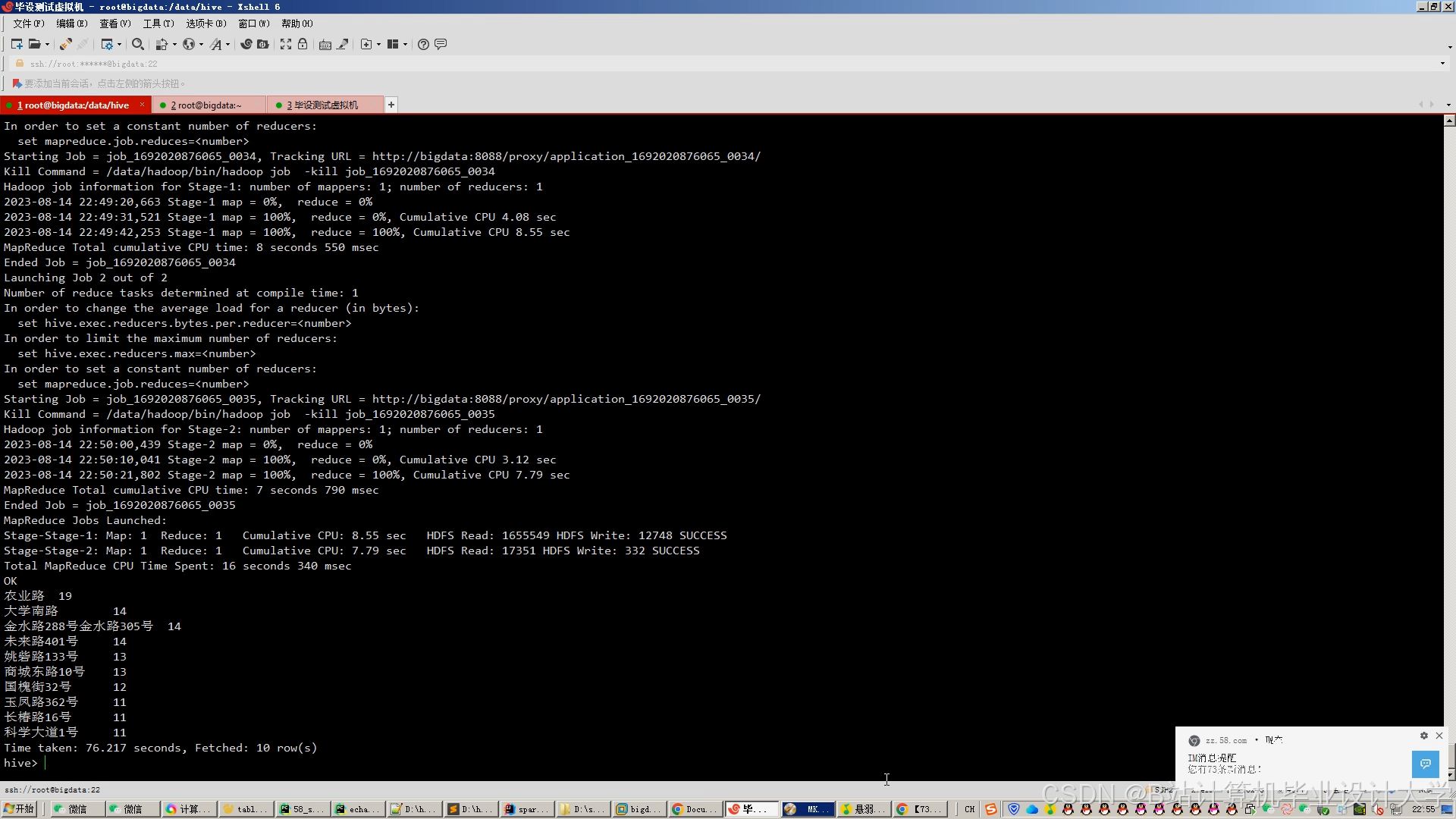
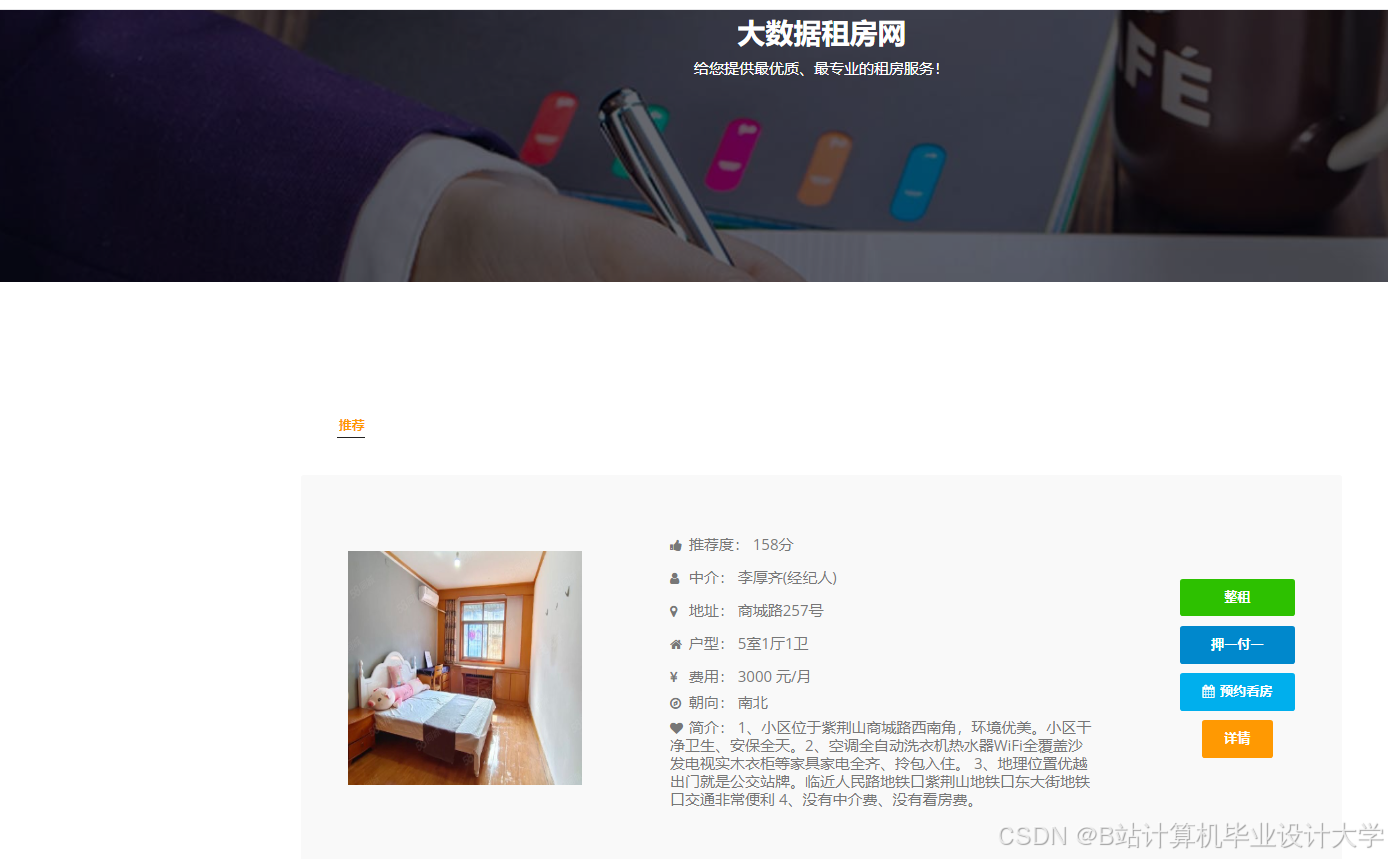
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1280
1280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











