




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+PySpark+Hadoop图书推荐系统技术说明
一、系统概述
本系统基于Python、PySpark和Hadoop构建分布式图书推荐平台,旨在解决海量图书数据下的个性化推荐问题。系统通过Hadoop实现高可靠性的分布式存储,利用PySpark进行大规模数据处理与机器学习建模,结合Python生态的丰富工具链完成数据采集、特征工程和推荐服务开发。系统支持协同过滤、内容推荐和混合推荐算法,具备高扩展性、实时性和准确性,可处理亿级用户行为数据和千万级图书元数据。
二、技术栈选型
2.1 核心组件
- Python 3.8+:作为开发主语言,提供简洁的语法和丰富的机器学习库(如Scikit-learn、Gensim)
- PySpark 3.3.0:基于Spark的Python API,实现分布式数据处理和机器学习
- Hadoop 3.3.4:提供分布式文件系统(HDFS)和资源管理(YARN)
- Spark MLlib:内置机器学习算法库,支持ALS协同过滤、TF-IDF等特征提取
- Redis 6.2:作为缓存层,存储高频推荐结果和用户特征
2.2 辅助工具
- Scrapy 2.6:用于图书元数据和用户行为数据采集
- Flask 2.0:构建RESTful API服务
- Vue.js 3.0:前端可视化交互框架
- Elasticsearch 7.15:实现图书全文检索
三、系统架构设计
3.1 分层架构
系统采用五层架构设计,各层职责明确:
┌───────────────────────────────────────────────┐ | |
│ 交互层(Vue.js) │ | |
├───────────────────────────────────────────────┤ | |
│ 服务层(Flask) │ | |
├───────────────────────────────────────────────┤ | |
│ 算法层(PySpark) │ | |
├───────────────────────────────────────────────┤ | |
│ 处理层(PySpark) │ | |
├───────────────────────────────────────────────┤ | |
│ 存储层(Hadoop) │ | |
└───────────────────────────────────────────────┘ |
3.2 数据流向
- 数据采集:Scrapy爬虫从豆瓣、亚马逊等平台采集图书元数据(标题、作者、分类、ISBN)和用户行为数据(浏览、购买、评分)
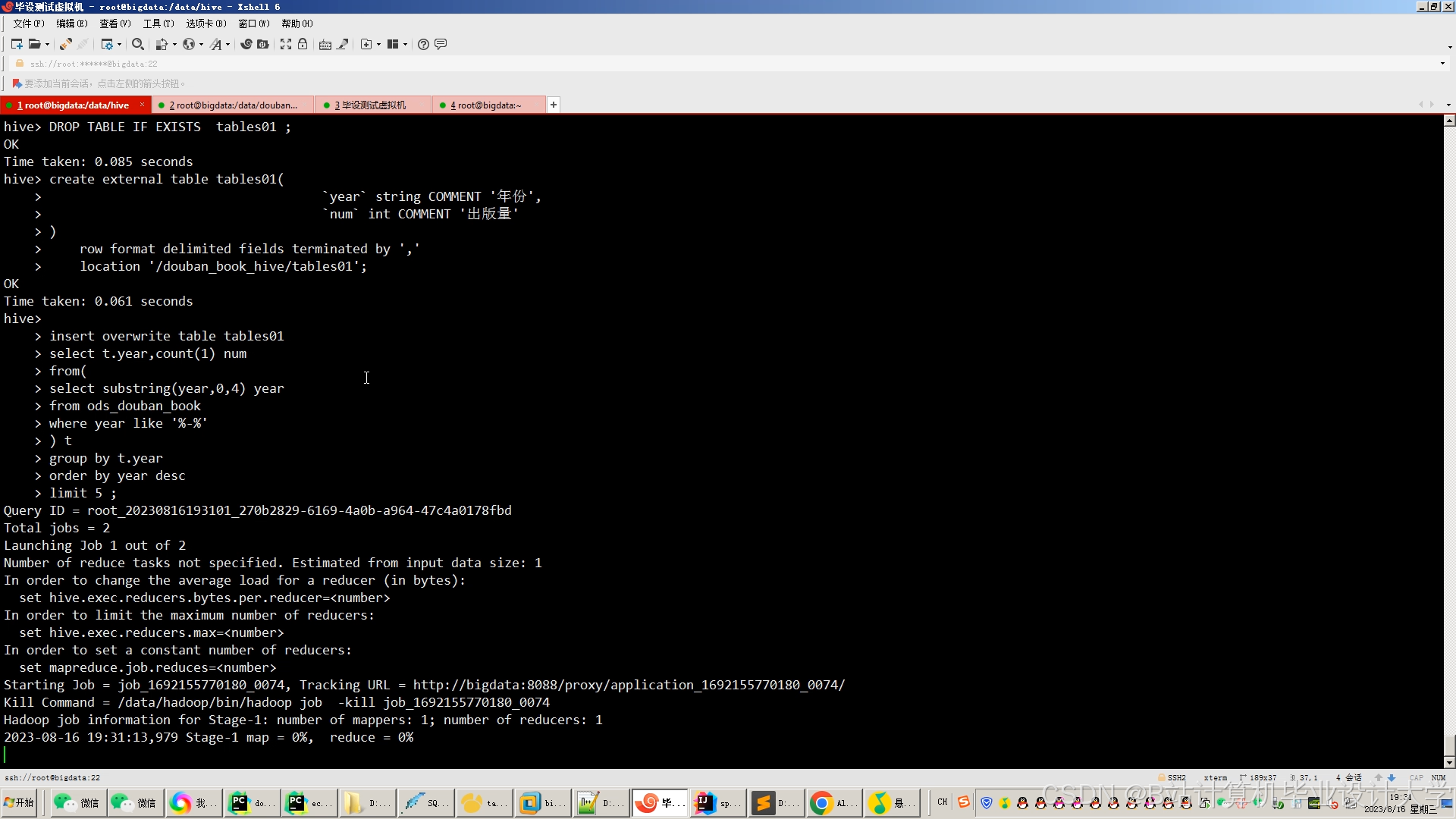
- 数据存储:原始数据存入HDFS,结构化数据通过Hive建表管理
- 数据处理:PySpark进行数据清洗、特征提取和模型训练
- 推荐生成:训练好的模型部署为Spark UDF函数,实时计算推荐结果
- 结果缓存:热门推荐结果存入Redis,减少计算开销
- 服务提供:Flask API对外提供推荐服务,前端通过Vue.js展示
四、核心模块实现
4.1 数据采集模块
使用Scrapy框架实现分布式爬虫,关键配置:
python
# settings.py 配置示例 | |
ROBOTSTXT_OBEY = False # 忽略robots.txt | |
CONCURRENT_REQUESTS = 32 # 并发请求数 | |
DOWNLOAD_DELAY = 1 # 请求间隔(秒) | |
ITEM_PIPELINES = { | |
'books.pipelines.HadoopPipeline': 300, # 直接写入HDFS | |
} |
采集字段包括:
- 图书元数据:title, author, publisher, publish_date, isbn, categories
- 用户行为:user_id, book_id, rating, timestamp, action_type(view/buy/rate)
4.2 数据存储模块
HDFS存储设计
/books/ | |
├── raw/ # 原始数据 | |
│ ├── metadata/ # 图书元数据 | |
│ └── behavior/ # 用户行为 | |
├── processed/ # 处理后数据 | |
│ ├── features/ # 特征数据 | |
│ └── models/ # 模型文件 | |
└── cache/ # 缓存数据 |
Hive表设计
sql
-- 图书元数据表 | |
CREATE TABLE books_metadata ( | |
book_id STRING, | |
title STRING, | |
author ARRAY<STRING>, | |
publisher STRING, | |
publish_date DATE, | |
isbn STRING, | |
categories ARRAY<STRING> | |
) STORED AS ORC; | |
-- 用户行为表 | |
CREATE TABLE user_behavior ( | |
user_id STRING, | |
book_id STRING, | |
rating INT, | |
timestamp BIGINT, | |
action_type STRING | |
) PARTITIONED BY (dt STRING) STORED AS ORC; |
4.3 数据处理模块
数据清洗流程
python
from pyspark.sql import functions as F | |
# 去除重复记录 | |
df = df.dropDuplicates(['user_id', 'book_id', 'timestamp']) | |
# 处理缺失值 | |
df = df.fillna({ | |
'rating': 3, # 默认评分 | |
'categories': ['未知'] # 默认分类 | |
}) | |
# 时间戳转换 | |
df = df.withColumn('date', F.from_unixtime('timestamp').cast('date')) |
特征提取实现
python
from pyspark.ml.feature import StringIndexer, VectorAssembler, TFIDF | |
from pyspark.ml.linalg import Vectors | |
# 分类特征编码 | |
category_indexer = StringIndexer( | |
inputCol='categories', | |
outputCol='category_idx' | |
) | |
# 文本特征提取 | |
tfidf = TFIDF( | |
inputCol='title', | |
outputCol='title_features', | |
minDF=2, | |
vocabSize=10000 | |
) | |
# 特征组合 | |
assembler = VectorAssembler( | |
inputCols=['category_idx', 'title_features', 'rating'], | |
outputCol='features' | |
) |
4.4 推荐算法模块
协同过滤实现
python
from pyspark.ml.recommendation import ALS | |
# 训练ALS模型 | |
als = ALS( | |
maxIter=10, | |
regParam=0.01, | |
rank=100, | |
userCol='user_id', | |
itemCol='book_id', | |
ratingCol='rating', | |
coldStartStrategy='drop' # 处理冷启动 | |
) | |
model = als.fit(training_data) | |
# 生成推荐 | |
user_recs = model.recommendForAllUsers(10) # 每个用户推荐10本 | |
book_recs = model.recommendForAllItems(10) # 每本书推荐给10个用户 |
内容推荐实现
python
from pyspark.ml.feature import Word2Vec | |
# 图书内容向量化 | |
word2vec = Word2Vec( | |
vectorSize=100, | |
minCount=5, | |
inputCol='description', # 图书描述文本 | |
outputCol='content_features' | |
) | |
model = word2vec.fit(book_data) | |
# 计算相似图书 | |
book_features = model.transform(book_data) | |
from pyspark.sql.functions import col, udf | |
from pyspark.sql.types import DoubleType | |
# 定义余弦相似度UDF | |
def cosine_similarity(v1, v2): | |
import numpy as np | |
v1 = np.array(v1.toArray()) | |
v2 = np.array(v2.toArray()) | |
return float(np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))) | |
cosine_udf = udf(cosine_similarity, DoubleType()) | |
# 计算图书相似度矩阵 | |
similarity_df = book_features.alias('a').join( | |
book_features.alias('b'), | |
col('a.book_id') < col('b.book_id') # 避免自比较 | |
).select( | |
col('a.book_id').alias('book1'), | |
col('b.book_id').alias('book2'), | |
cosine_udf('a.content_features', 'b.content_features').alias('similarity') | |
) |
混合推荐实现
python
def hybrid_recommend(user_id, cf_recs, cb_recs, alpha=0.7): | |
""" | |
混合推荐策略 | |
:param user_id: 用户ID | |
:param cf_recs: 协同过滤推荐结果 | |
:param cb_recs: 内容推荐结果 | |
:param alpha: 协同过滤权重 | |
:return: 混合推荐列表 | |
""" | |
# 获取用户行为次数 | |
behavior_count = spark.sql(f""" | |
SELECT COUNT(*) as cnt | |
FROM user_behavior | |
WHERE user_id = '{user_id}' | |
""").first()['cnt'] | |
# 动态调整权重 | |
if behavior_count > 50: # 活跃用户 | |
alpha = 0.8 | |
else: # 新用户 | |
alpha = 0.4 | |
# 合并推荐结果 | |
cf_scores = {book: score * alpha for book, score in cf_recs.get(user_id, {})} | |
cb_scores = {book: score * (1-alpha) for book, score in cb_recs.get(user_id, {})} | |
# 合并并排序 | |
combined = {} | |
for book in set(cf_scores.keys()).union(set(cb_scores.keys())): | |
combined[book] = cf_scores.get(book, 0) + cb_scores.get(book, 0) | |
return sorted(combined.items(), key=lambda x: x[1], reverse=True)[:10] |
4.5 实时推荐模块
Spark Streaming处理
python
from pyspark.streaming import StreamingContext | |
from pyspark.streaming.kafka import KafkaUtils | |
# 创建StreamingContext | |
ssc = StreamingContext(spark.sparkContext, batchDuration=5) # 5秒批次 | |
# 从Kafka消费实时行为 | |
kvs = KafkaUtils.createDirectStream( | |
ssc, | |
['user_behavior'], | |
{'metadata.broker.list': 'kafka:9092'} | |
) | |
# 处理实时行为 | |
lines = kvs.map(lambda x: json.loads(x[1])) | |
lines.foreachRDD(lambda rdd: rdd.foreachPartition(process_realtime_behavior)) | |
def process_realtime_behavior(partition): | |
"""处理实时行为数据""" | |
for record in partition: | |
# 更新用户近期兴趣 | |
update_user_profile(record['user_id'], record['book_id']) | |
# 触发实时推荐 | |
recommendations = generate_realtime_recommend(record['user_id']) | |
# 存入Redis | |
redis_client.set( | |
f"user:{record['user_id']}:recommend", | |
json.dumps(recommendations), | |
ex=3600 # 1小时过期 | |
) |
Redis缓存设计
# 用户推荐结果缓存 | |
user:{user_id}:recommend -> ["book1", "book2", ...] (有效期1小时) | |
# 图书热门推荐缓存 | |
book:hot:daily -> ["book1", "book2", ...] (每日更新) | |
# 用户特征向量缓存 | |
user:{user_id}:features -> {"category_pref": [0.2, 0.5, ...], ...} |
五、系统优化策略
5.1 性能优化
- 数据分区优化:
- 按用户ID哈希分区,确保单个用户数据在同一个Executor上
- 对热门图书ID加盐(Salting)后均匀分区,解决数据倾斜
- 缓存策略:
- 使用
persist(StorageLevel.MEMORY_AND_DISK)缓存频繁访问的DataFrame - 对中间结果设置合理的TTL(生存时间)
- 使用
- 参数调优:
python# Spark配置优化示例spark.conf.set("spark.sql.shuffle.partitions", "200") # 根据集群规模调整spark.conf.set("spark.default.parallelism", "200")spark.conf.set("spark.executor.memory", "8g")spark.conf.set("spark.driver.memory", "4g")
5.2 算法优化
-
冷启动解决方案:
- 新用户:基于人口统计学特征推荐热门图书
- 新图书:基于内容相似度推荐给可能感兴趣的用户
-
多样性提升:
pythondef diversify_recommendations(recs, categories, max_per_category=2):"""增加推荐多样性"""from collections import defaultdictcat_counts = defaultdict(int)diversified = []for book, score in recs:book_cat = get_book_category(book) # 获取图书分类if cat_counts[book_cat] < max_per_category:diversified.append((book, score))cat_counts[book_cat] += 1return diversified -
实时性优化:
- 对实时行为数据采用增量更新策略
- 使用Bloom Filter快速判断新行为是否影响推荐结果
六、部署与运维
6.1 集群部署
# 集群角色分配示例 | |
Node1: NameNode, ResourceManager, Spark Master | |
Node2: DataNode, NodeManager, Spark Worker | |
Node3: DataNode, NodeManager, Spark Worker | |
Node4: DataNode, NodeManager, Spark Worker |
6.2 监控方案
- Spark UI:监控作业执行情况
- Ganglia:集群资源监控
- Prometheus + Grafana:自定义指标监控
- 推荐延迟(P99)
- 缓存命中率
- 模型加载时间
6.3 故障处理
- 数据倾斜处理:
- 对倾斜键进行随机前缀加盐
- 使用
repartition()或coalesce()调整分区
- OOM问题解决:
- 增加Executor内存
- 优化广播变量使用
- 减少单个Task处理的数据量
七、总结与展望
本系统通过Python+PySpark+Hadoop的组合,实现了高效、可扩展的图书推荐服务。关键创新点包括:
- 动态权重混合推荐算法,适应不同用户场景
- 实时推荐与离线推荐结合的混合架构
- 多模态特征融合(文本、分类、行为)
未来改进方向:
- 引入图神经网络(GNN)提升推荐准确性
- 开发可解释性推荐模块,增强用户信任
- 支持跨平台推荐(如结合微信读书、Kindle数据)
附录:关键代码片段
A1. 完整推荐流程示例
python
def get_recommendations(user_id): | |
"""获取用户推荐列表""" | |
# 1. 从Redis获取实时推荐 | |
redis_recs = redis_client.get(f"user:{user_id}:recommend") | |
if redis_recs: | |
return json.loads(redis_recs) | |
# 2. 混合推荐 | |
cf_recs = get_cf_recommendations(user_id) # 协同过滤推荐 | |
cb_recs = get_cb_recommendations(user_id) # 内容推荐 | |
hybrid_recs = hybrid_recommend(user_id, cf_recs, cb_recs) | |
# 3. 存入Redis | |
redis_client.setex( | |
f"user:{user_id}:recommend", | |
3600, | |
json.dumps(hybrid_recs) | |
) | |
return hybrid_recs |
A2. 模型部署示例
python
# 模型持久化 | |
model.save("/models/als_model_20230801") | |
# 模型加载 | |
from pyspark.ml.recommendation import ALSModel | |
loaded_model = ALSModel.load("/models/als_model_20230801") | |
# 注册为UDF函数 | |
spark.udf.register( | |
"predict_rating", | |
lambda user, book: float(loaded_model.predict(user, book)) | |
) |
本技术说明详细阐述了Python+PySpark+Hadoop图书推荐系统的设计与实现,为构建大规模分布式推荐系统提供了完整的技术方案。
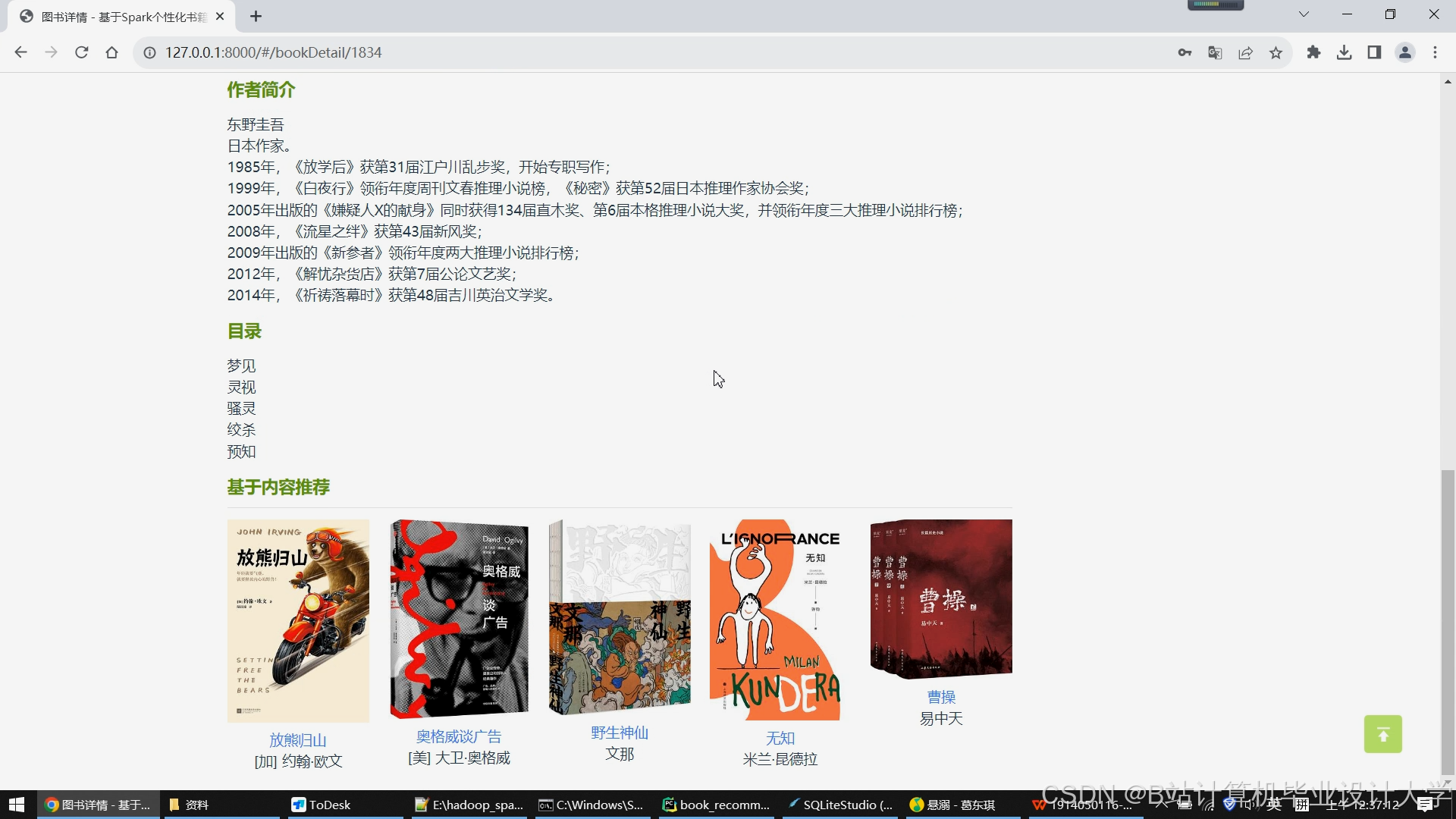
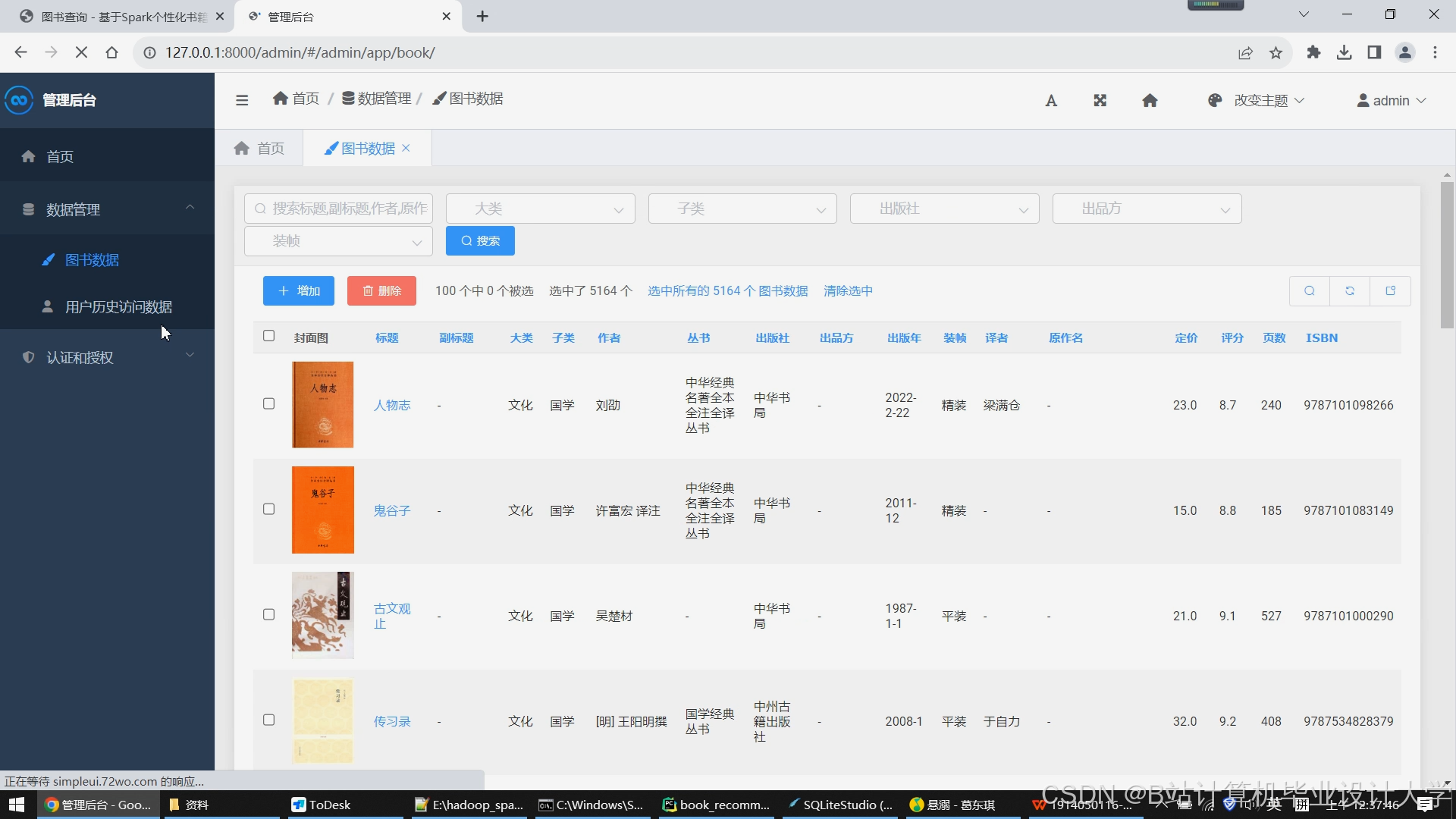
运行截图
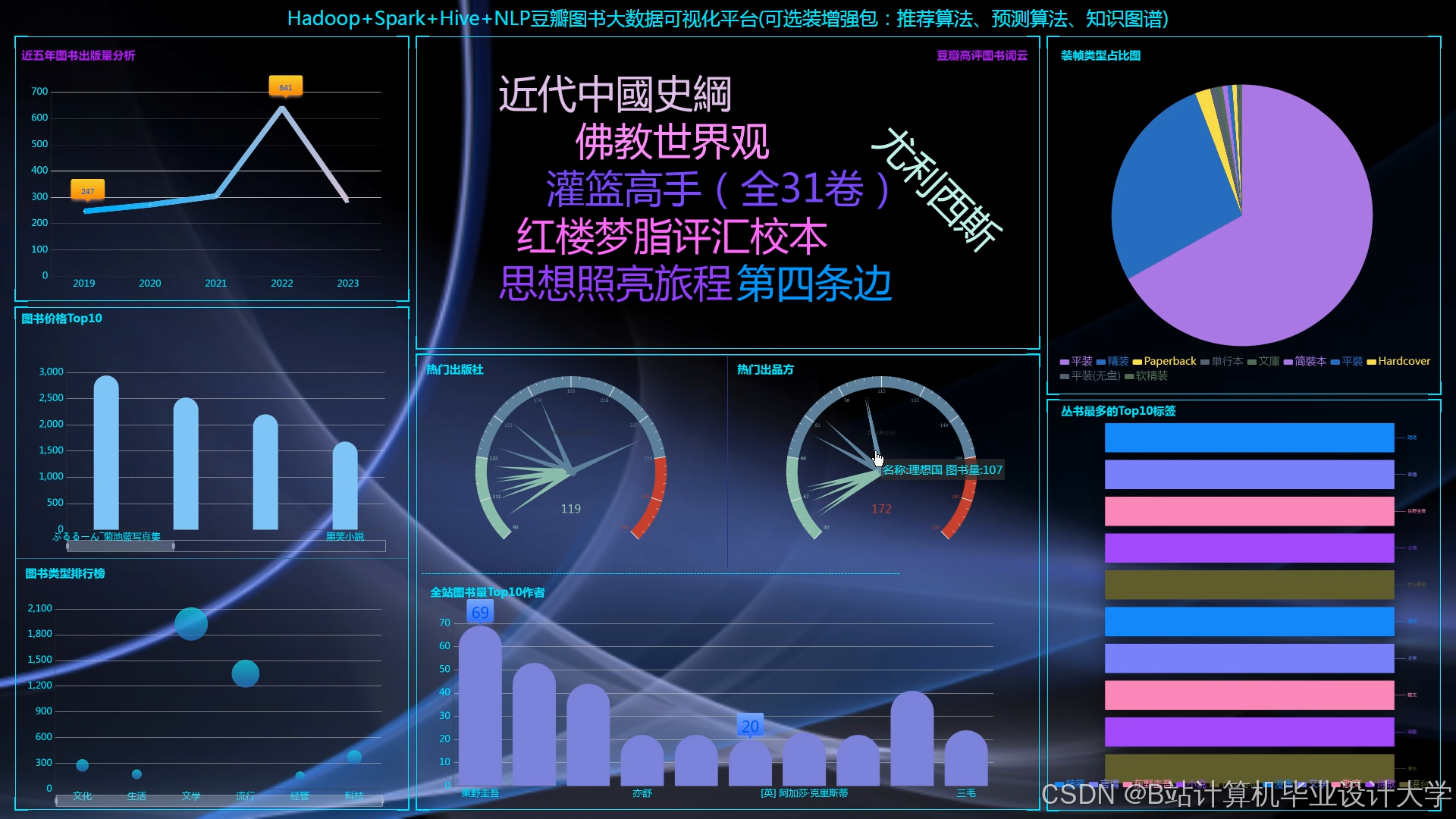
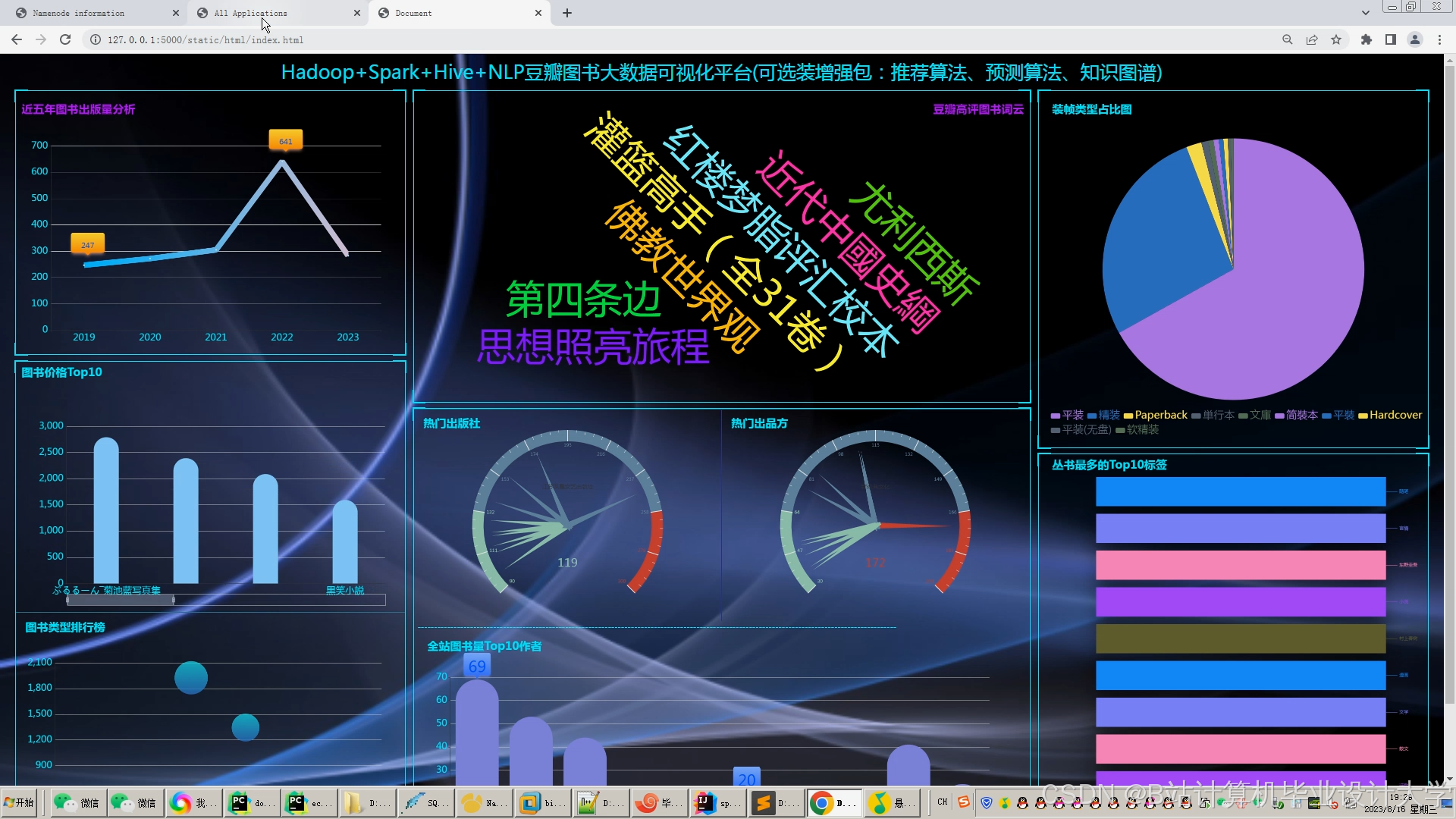
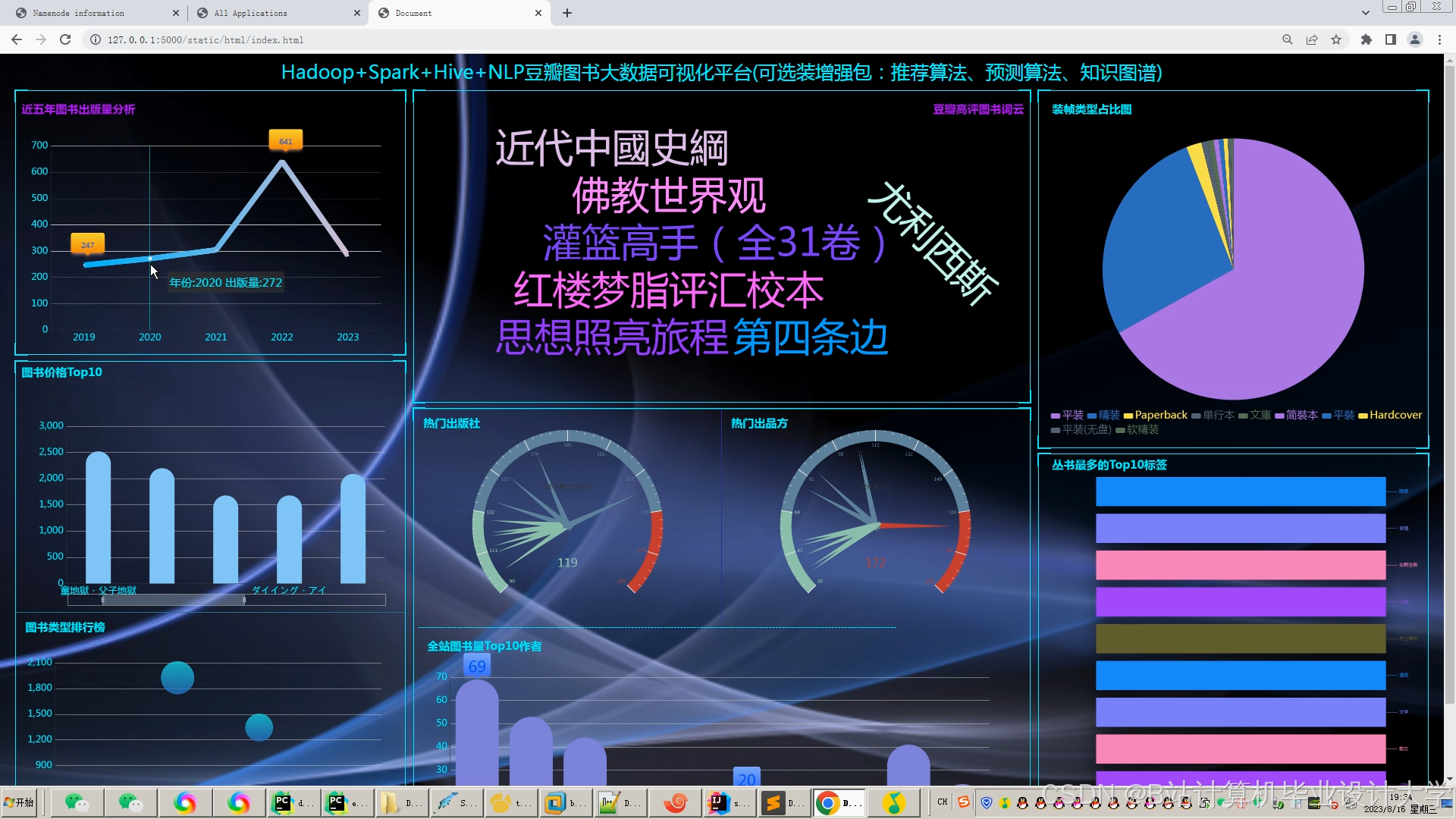
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1860
1860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











