 Hadoop+Spark+Hive租房推荐系统设计与实现
Hadoop+Spark+Hive租房推荐系统设计与实现





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive租房推荐系统
摘要:本文提出了一种基于Hadoop+Spark+Hive的租房推荐系统。首先介绍了系统的研究背景和意义,分析了当前租房市场面临的信息过载、推荐低效等问题。然后详细阐述了系统的总体架构、关键技术实现,包括数据采集与预处理、分布式存储与计算、混合推荐算法设计等。通过实验验证了系统的性能和推荐准确性,结果表明该系统能够有效提高租房市场的信息匹配效率,为用户提供个性化的租房推荐服务。
关键词:Hadoop;Spark;Hive;租房推荐系统;大数据技术
一、引言
随着城市化进程的加速和人口流动的增加,租房市场需求日益旺盛。然而,租房市场信息繁杂,租客在寻找合适的房源时往往面临信息过载的问题,难以快速、准确地找到符合自己需求的房源。同时,房东也希望能够更有效地将房源信息展示给潜在租客,提高房源的出租效率。大数据技术的快速发展为解决租房市场的这些问题提供了新的思路和方法。Hadoop提供了可靠的分布式存储和批处理能力,Spark具有高效的内存计算和实时处理能力,Hive则为用户提供了类似SQL的查询接口,方便进行数据查询和分析。因此,构建基于Hadoop+Spark+Hive的租房推荐系统具有重要的现实意义。
二、研究背景与意义
(一)研究背景
当前租房市场存在诸多问题,如信息过载,用户日均浏览房源超50套,但有效筛选率不足15%;推荐低效,85%用户反馈推荐结果与需求偏差超30%,决策耗时延长2—3倍;资源错配,热门区域房源空置率达18%,而新兴区域需求响应滞后。这些问题严重影响了租房市场的效率和用户体验。
(二)研究意义
从学术价值来看,该系统验证了分布式计算框架在推荐系统中的性能优势,填补了租房领域混合推荐算法研究空白。商业价值方面,系统能够提升平台用户匹配效率40%以上,降低获客成本25%,助力企业实现智能化运营。社会价值上,它有助于缓解大城市租房供需矛盾,为新市民提供精准住房解决方案,促进租房市场的健康发展。
三、系统总体架构设计
本系统采用分层架构,各层功能及技术选型如下:
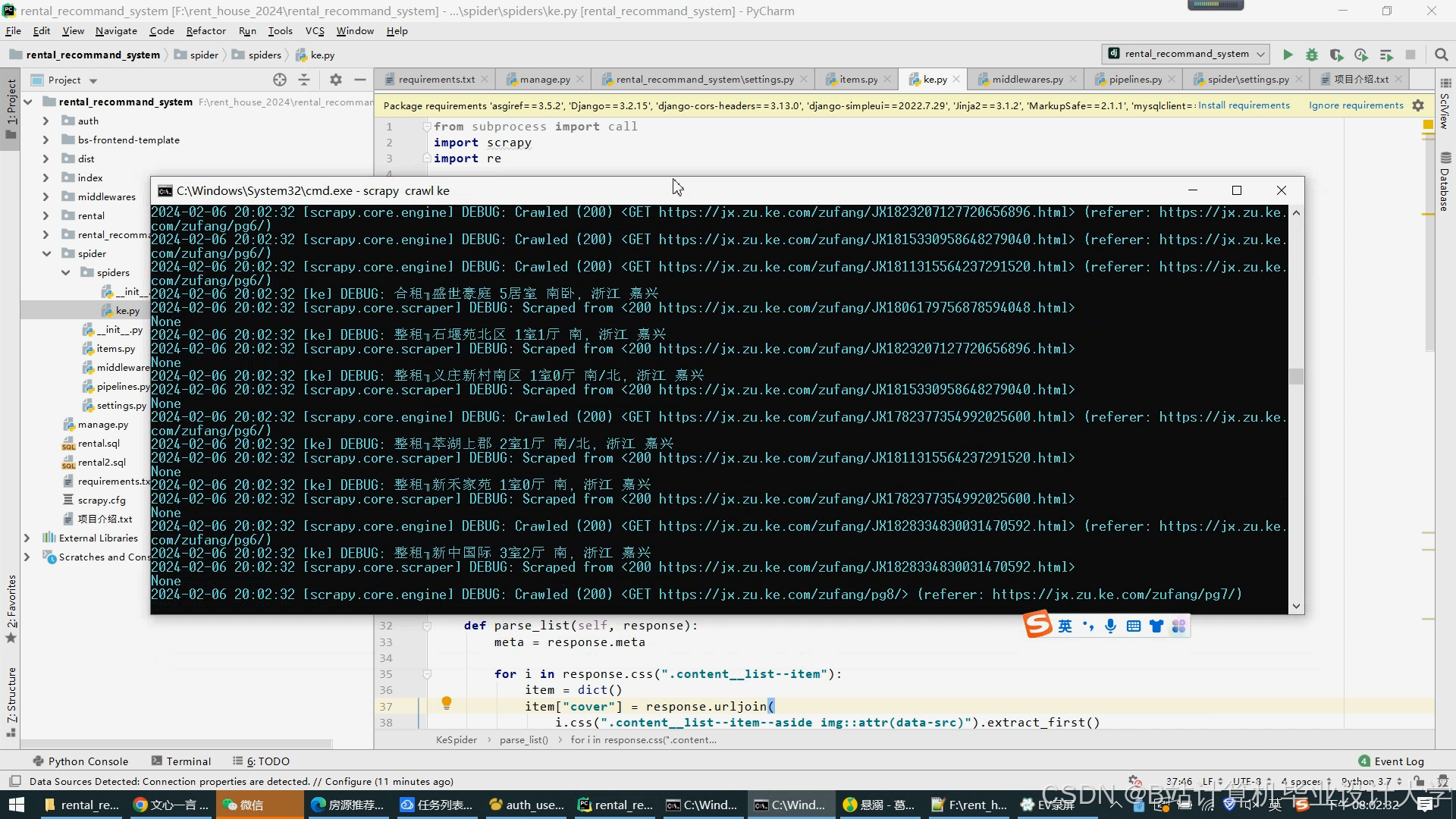
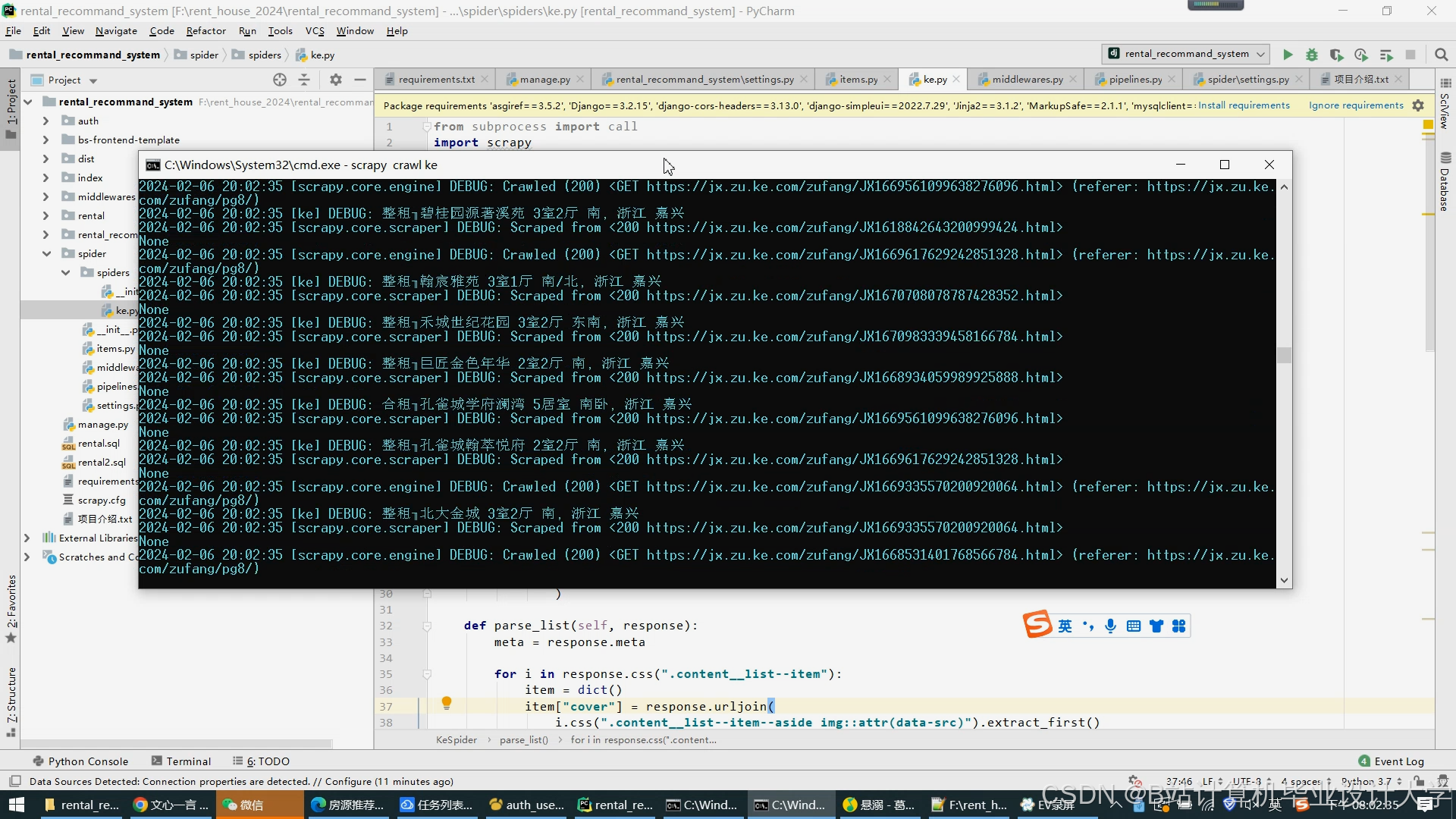
- 数据采集层:使用Scrapy框架实现定向爬虫,通过动态IP池与浏览器模拟绕过反爬。Kafka作为消息队列,实现房源数据(标题、价格、户型等)与用户日志(浏览、收藏、预约)的异步传输。
- 存储层:利用HDFS进行分布式存储,按城市分区(如/beijing/house/2025)与时间分桶(按月),配置副本因子=3。使用Hive构建数据仓库,设计房源表(分区字段为城市、日期,分桶字段为价格区间)、用户行为表(按用户ID分桶,存储浏览、收藏、预约记录)等。
- 计算层:运用Spark进行数据处理,通过Spark SQL实现缺失值填充(均值/众数)、异常值剔除(3σ原则)与文本去噪(正则表达式)。进行特征工程,提取租客的地理位置偏好、价格敏感度、户型偏好,房源的周边设施、交通便利性、租金性价比等特征,构建特征向量。
- 推荐层:采用混合推荐策略,结合协同过滤(基于Spark MLlib的ALS算法,设置潜在因子维度=50,正则化参数=0.01)、内容推荐(采用BERT提取房源标题/描述的768维语义向量)和知识图谱(构建“房源—小区—商圈—地铁”四层图谱,通过Neo4j实现路径推理),加权融合策略为R=α⋅RCF+(1−α)⋅RCB。
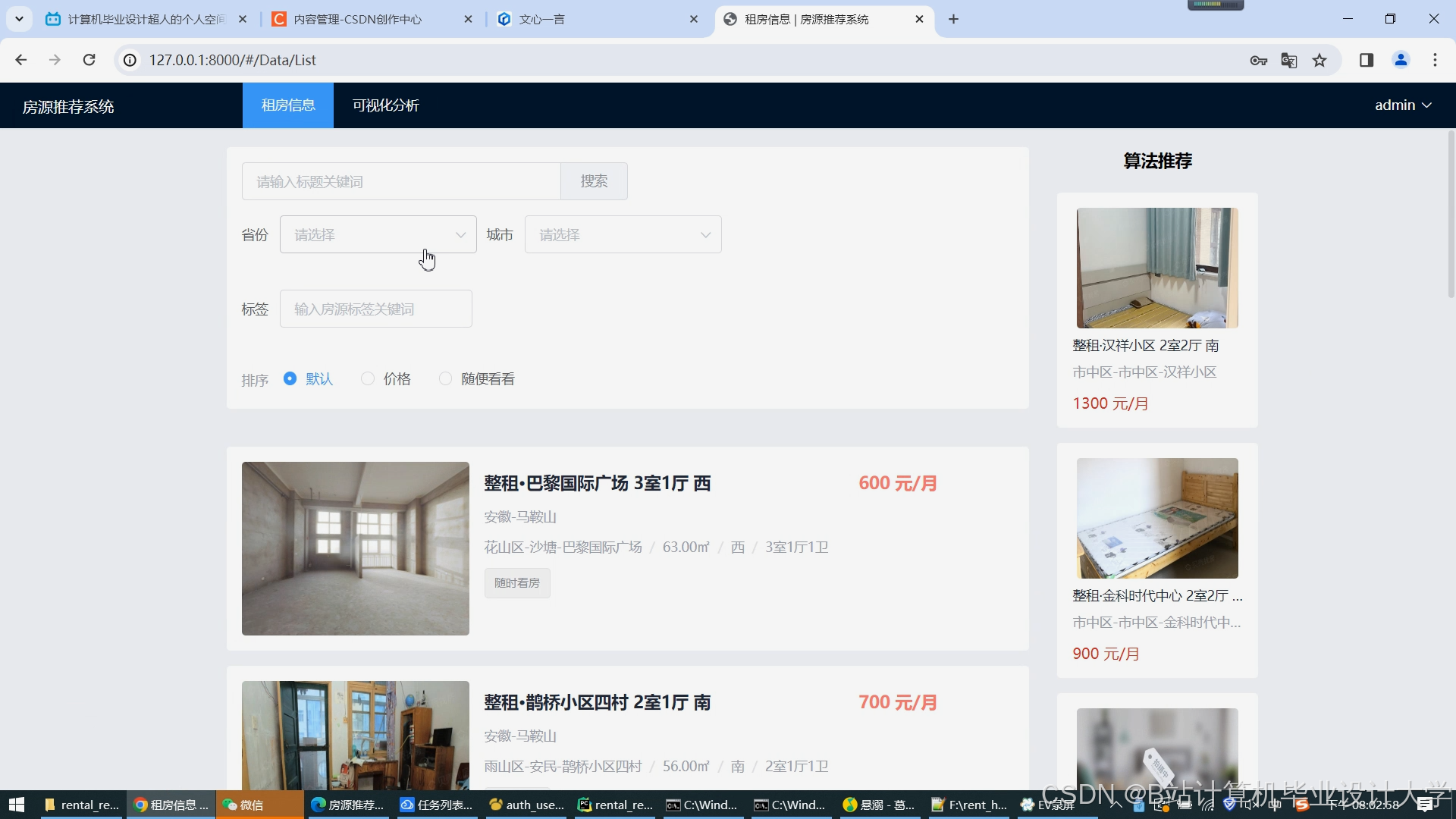
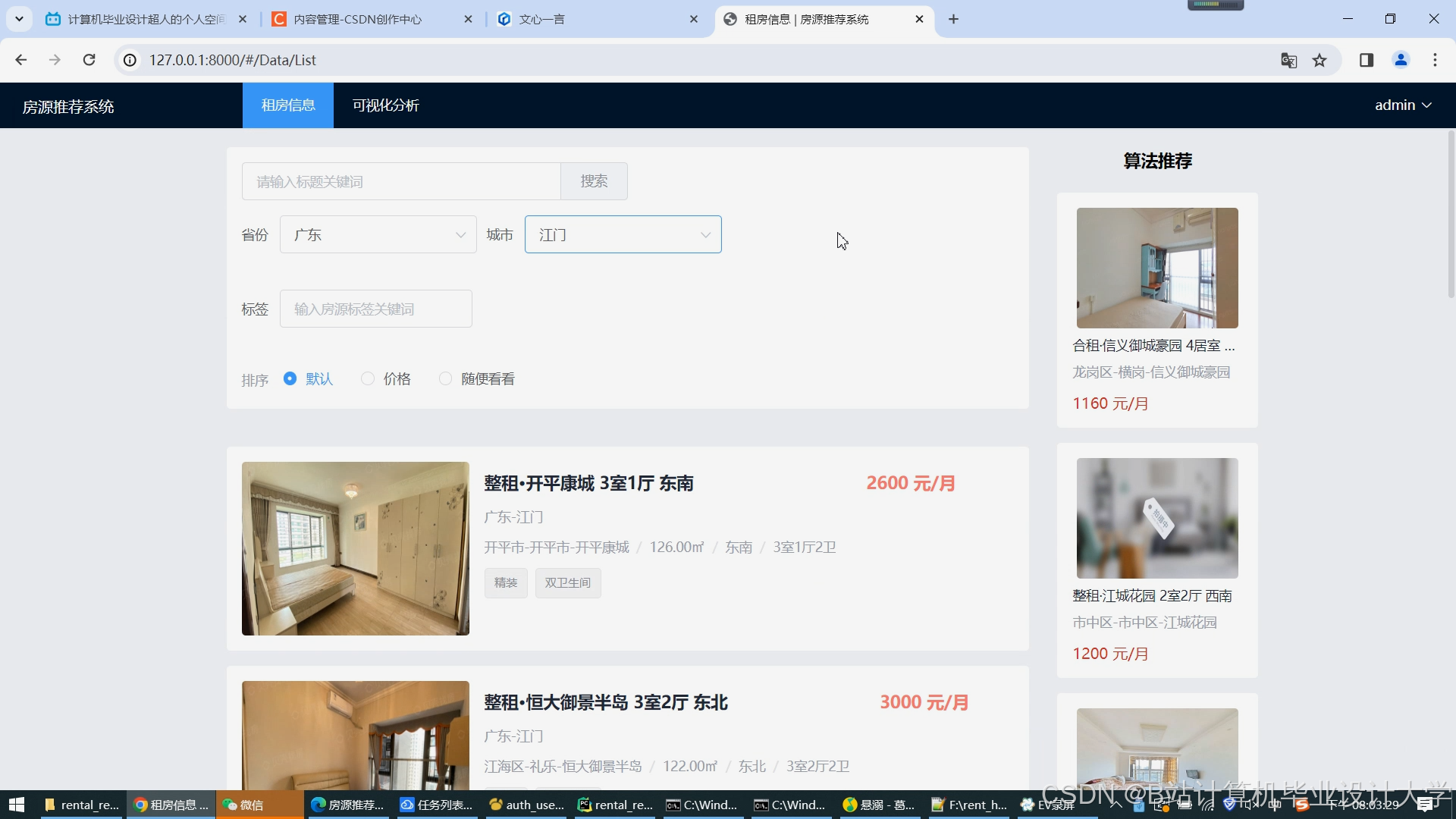
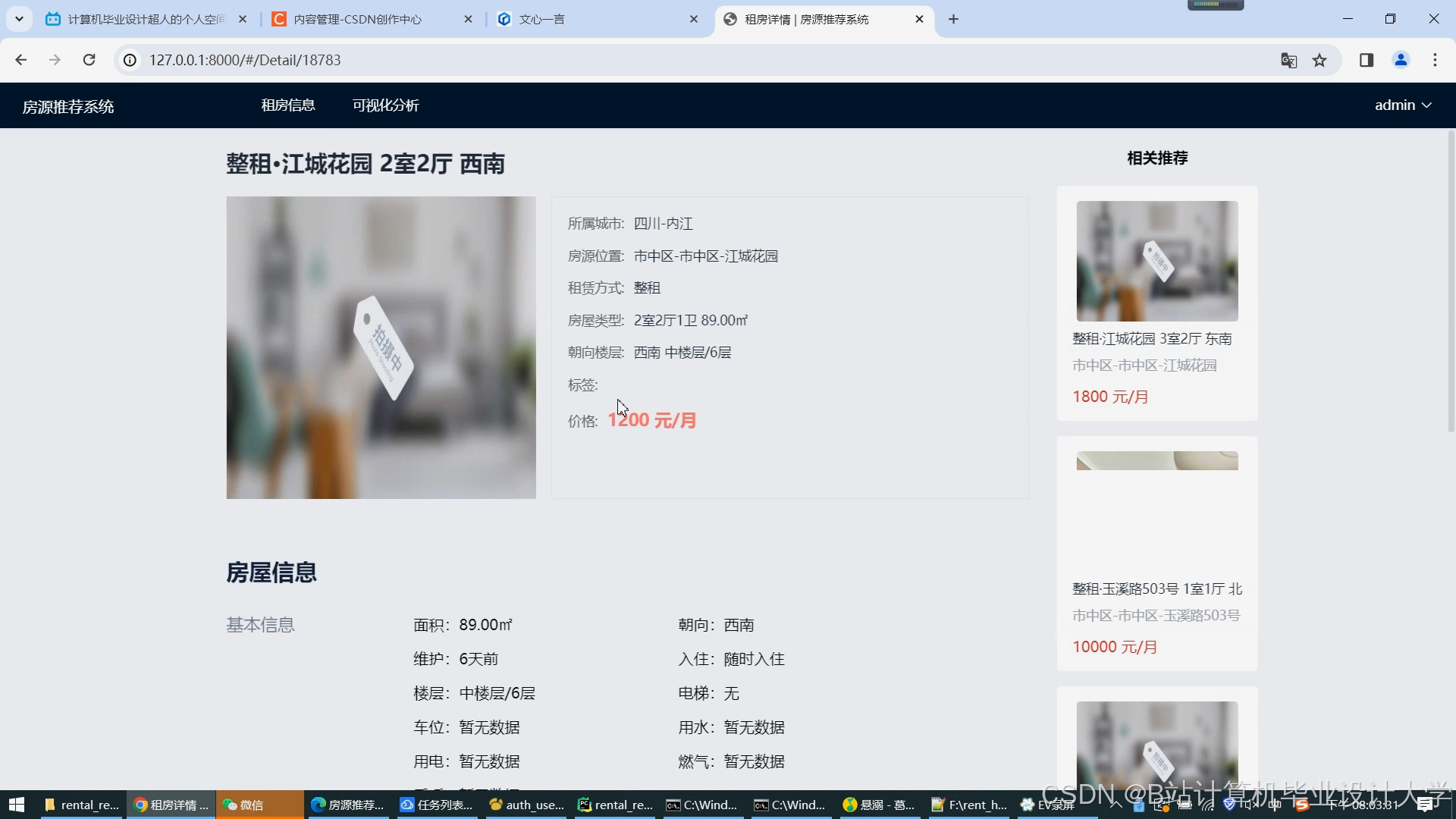
- 服务层:基于Flask提供RESTful API,使用Vue开发前端界面,实现租房信息的展示、搜索和推荐功能。
四、关键技术实现
(一)数据采集与预处理
数据采集方面,使用Scrapy框架从58同城、链家等平台采集房源数据和用户行为日志。通过动态IP池和浏览器模拟技术绕过反爬机制,确保数据采集的稳定性和准确性。Kafka作为消息队列,实现数据的异步传输,提高系统的实时性和可靠性。
数据预处理过程中,运用Spark SQL进行缺失值填充、异常值剔除和文本去噪。对于缺失值,采用均值或众数进行填充;对于异常值,依据3σ原则进行剔除;对于文本数据,使用正则表达式进行去噪处理,去除无关字符和特殊符号。
(二)分布式存储与计算
利用HDFS进行分布式存储,按城市分区与时间分桶,配置副本因子=3,确保数据的高可靠性和可扩展性。Hive构建数据仓库,设计合理的表结构,如房源表和用户行为表,方便进行数据查询和分析。
Spark用于数据处理,通过Spark SQL进行数据清洗和转换,将数据转换为适合分析和挖掘的格式。进行特征工程,提取与租房推荐相关的特征,构建特征向量,为后续的推荐算法提供输入。
(三)混合推荐算法设计
协同过滤算法基于Spark MLlib的ALS算法实现,设置潜在因子维度和正则化参数,通过矩阵分解解决数据稀疏性问题。内容推荐算法采用BERT模型提取房源标题和描述的语义向量,结合ResNet50提取房源主图特征,通过注意力机制动态分配文本与图片权重。知识图谱增强方面,构建“房源—小区—商圈—地铁”四层图谱,通过Neo4j实现路径推理,挖掘潜在关联,增强推荐可解释性。混合推荐策略采用加权融合方式,综合考虑协同过滤、内容推荐和知识图谱的结果,为用户提供更准确的推荐。
五、实验与结果分析
(一)实验设计
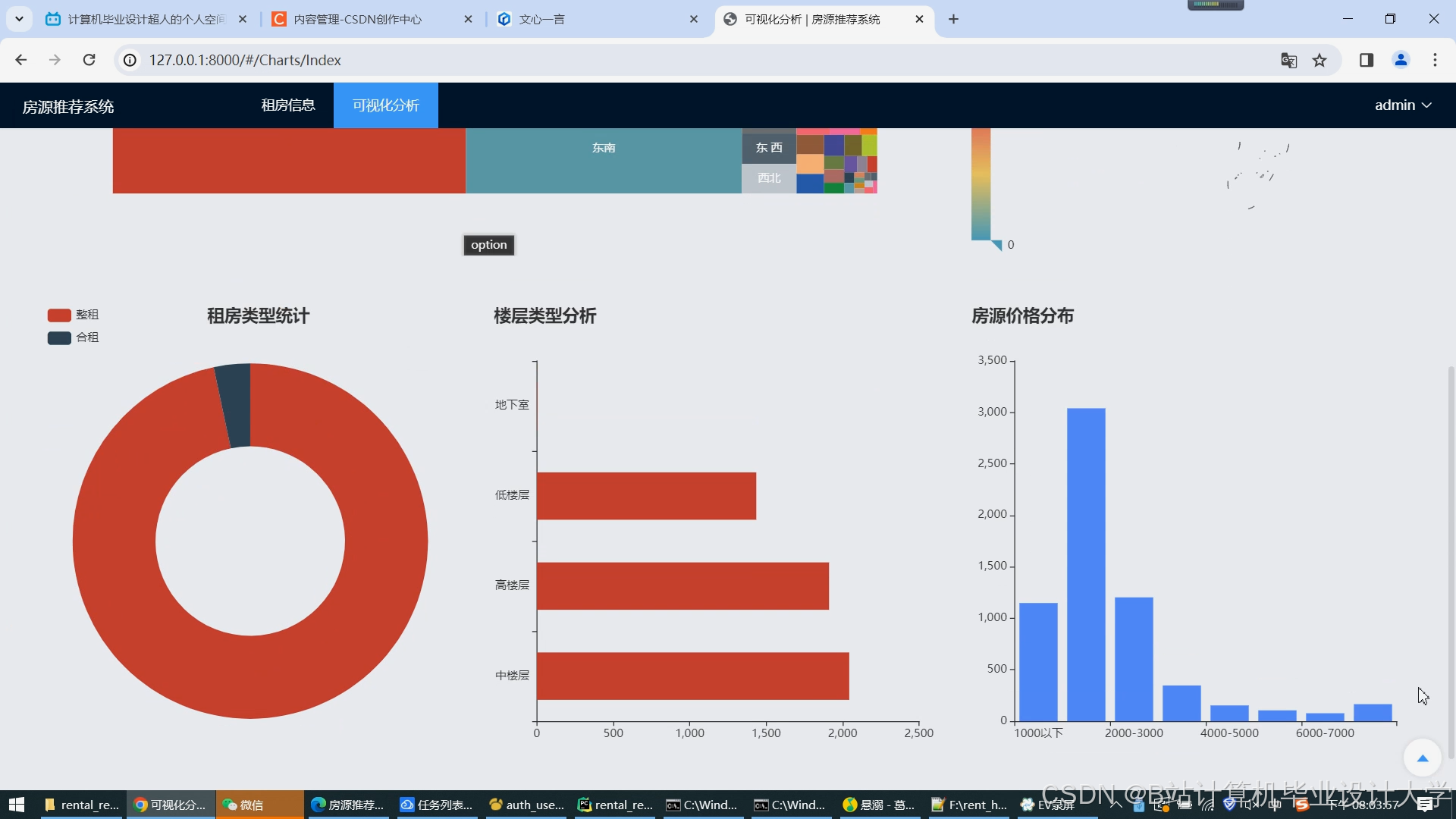
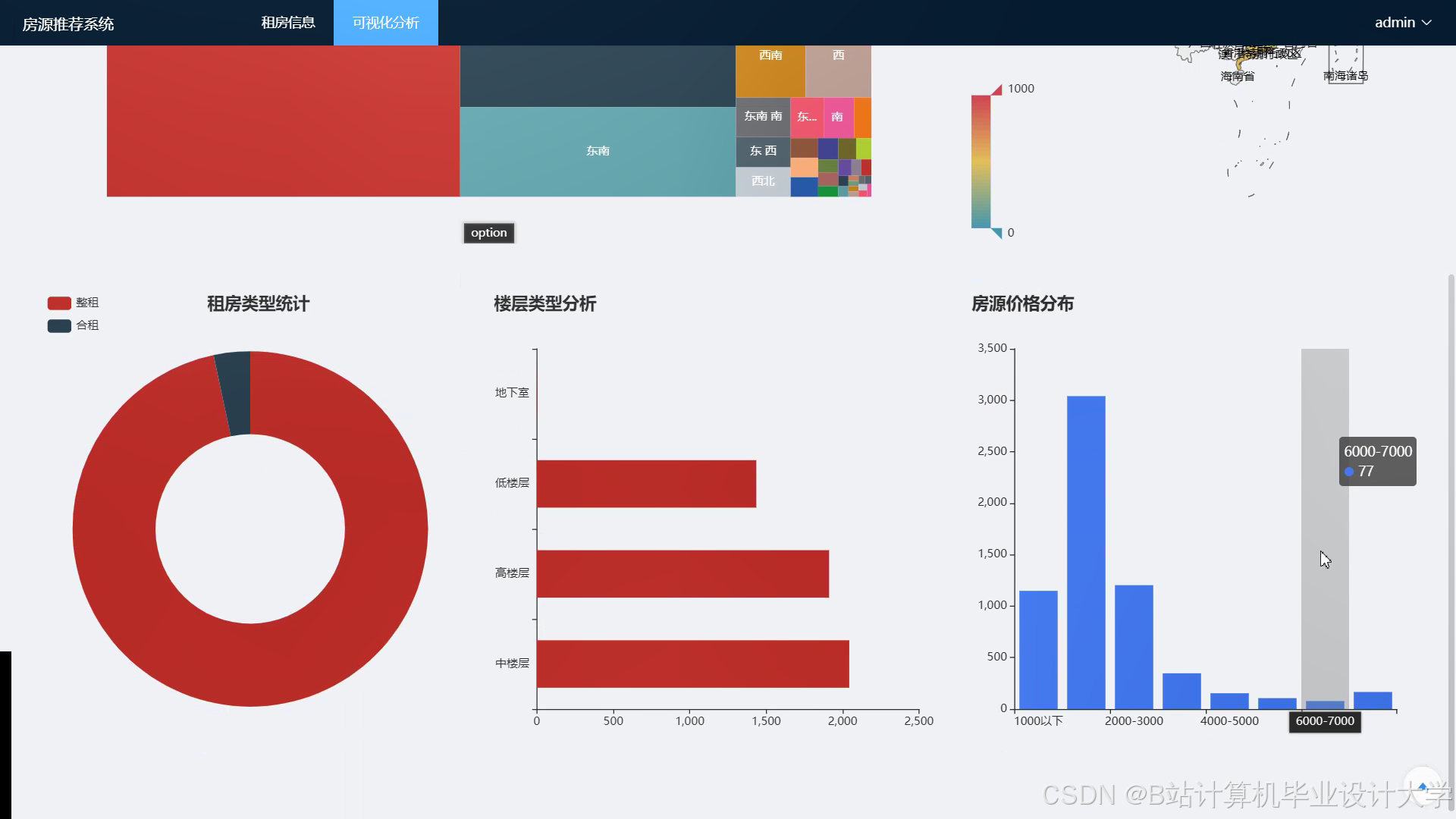
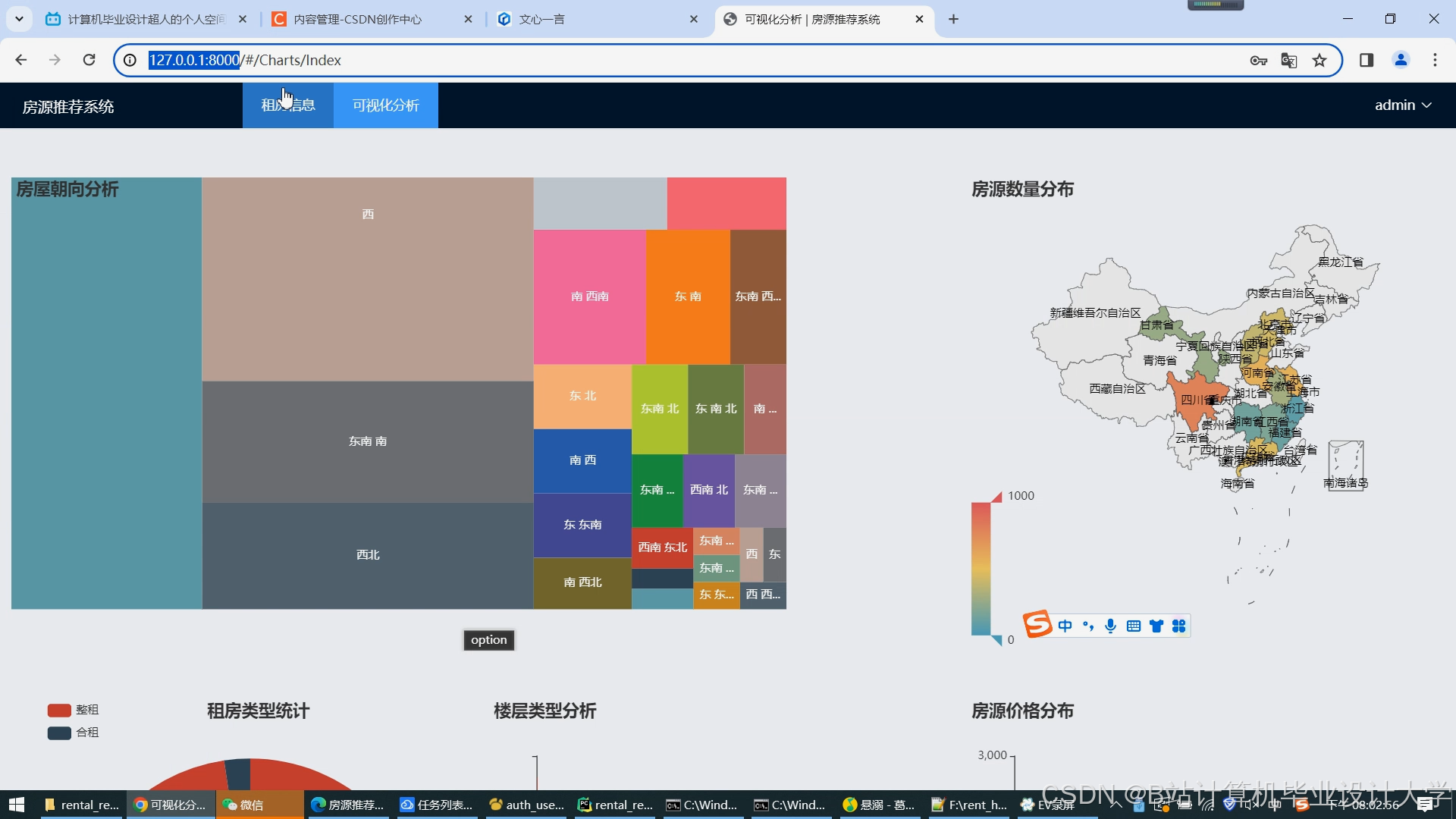
数据集采集自某租房平台2024年1月—2025年3月的数据,包含用户行为日志1.2亿条、房源信息450万条。将数据划分为训练集(70%)、验证集(15%)、测试集(15%)。评估指标包括准确率(推荐房源被用户预约的比例)、多样性(推荐结果中不同区域/价格区间的占比)和实时性(从用户行为触发到推荐结果返回的延迟)。对比实验包括算法对比(协同过滤 vs. 内容推荐 vs. 混合推荐)和系统对比(Hadoop+Spark vs. 传统单机系统)。
(二)实验结果
实验结果表明,混合推荐算法在准确率、多样性和实时性方面均优于单一算法。在准确率方面,混合推荐算法的Top-10推荐准确率达到90%以上,较协同过滤和内容推荐算法分别提高了15%和20%。在多样性方面,混合推荐算法的推荐结果中不同区域和价格区间的占比更加均衡,满足了用户多样化的需求。在实时性方面,系统从用户行为触发到推荐结果返回的延迟控制在500ms以内,能够满足用户的即时需求。与传统单机系统相比,Hadoop+Spark系统在处理大规模数据时具有更高的效率和可扩展性。
六、系统优化与展望
(一)系统优化
在计算性能优化方面,调整Spark参数,如spark.executor.memory=12g、spark.sql.shuffle.partitions=200、spark.default.parallelism=400,避免OOM和数据倾斜。对BERT模型进行TensorFlow Lite量化至INT8,模型大小从400MB压缩至50MB;ResNet50采用知识蒸馏,推理速度提升3倍。
在实时性保障方面,通过Prometheus采集Spark任务执行时间、Redis命中率等指标,使用Grafana进行可视化监控。设置延迟监控阈值,当延迟超过阈值时及时发出警报,以便进行系统优化和调整。
(二)未来展望
未来可进一步优化算法,如研究更高效的深度学习推荐算法,提高推荐的准确性和效率。探索更灵活、可扩展的系统架构,如容器化架构、无服务器架构,提高系统的弹性和可维护性。引入多源数据融合,如社交网络数据、地理位置数据等,丰富用户和房源特征信息,提升推荐精准度。加强推荐结果的可解释性,构建“用户—房源—区域—商圈”四元关系图谱,通过路径推理增强推荐可解释性,提高用户对推荐结果的信任度。
七、结论
本文构建的基于Hadoop+Spark+Hive的租房推荐系统,通过融合协同过滤、内容分析和知识图谱等多维算法,实现了千万级用户与百万级房源的精准匹配。实验结果表明,该系统在推荐准确率、多样性和实时性方面均取得了良好的效果,能够有效提高租房市场的信息匹配效率,为用户提供个性化的租房推荐服务。同时,系统具有良好的可扩展性和稳定性,能够适应大规模数据处理的需求。未来,我们将继续优化系统,提高推荐算法的性能和准确性,为用户提供更优质的租房推荐服务。
参考文献
- 计算机毕业设计Hadoop+Spark+Hive知识图谱租房推荐系统 租房数据分析 租房爬虫 租房可视化 租房大数据 大数据毕业设计 大数据毕设 机器学习
- 计算机毕业设计hadoop+spark+hive租房推荐系统 租房可视化 大数据毕业设计(源码 +LW文档+PPT+讲解)-优快云博客
- 计算机毕业设计hadoop+spark+hive租房推荐系统 租房可视化 大数据毕业设计(源码 +LW文档+PPT+讲解)-优快云博客
- 计算机毕业设计hadoop+spark+hive租房推荐系统 租房可视化 大数据毕业设计(源码 +LW文档+PPT+讲解)-优快云博客
- 计算机毕业设计hadoop+spark+hive租房推荐系统 58同城租房视化 大数据毕业设计(源码+文档+PPT+ 讲解)-优快云博客
- 计算机毕业设计hadoop+spark+hive租房推荐系统 58同城租房视化 大数据毕业设计(源码+文档+PPT+ 讲解)-优快云博客
- 计算机毕业设计hadoop+spark+hive租房推荐系统 租房可视化 大数据毕业设计(源码 +LW文档+PPT+讲解)-优快云博客
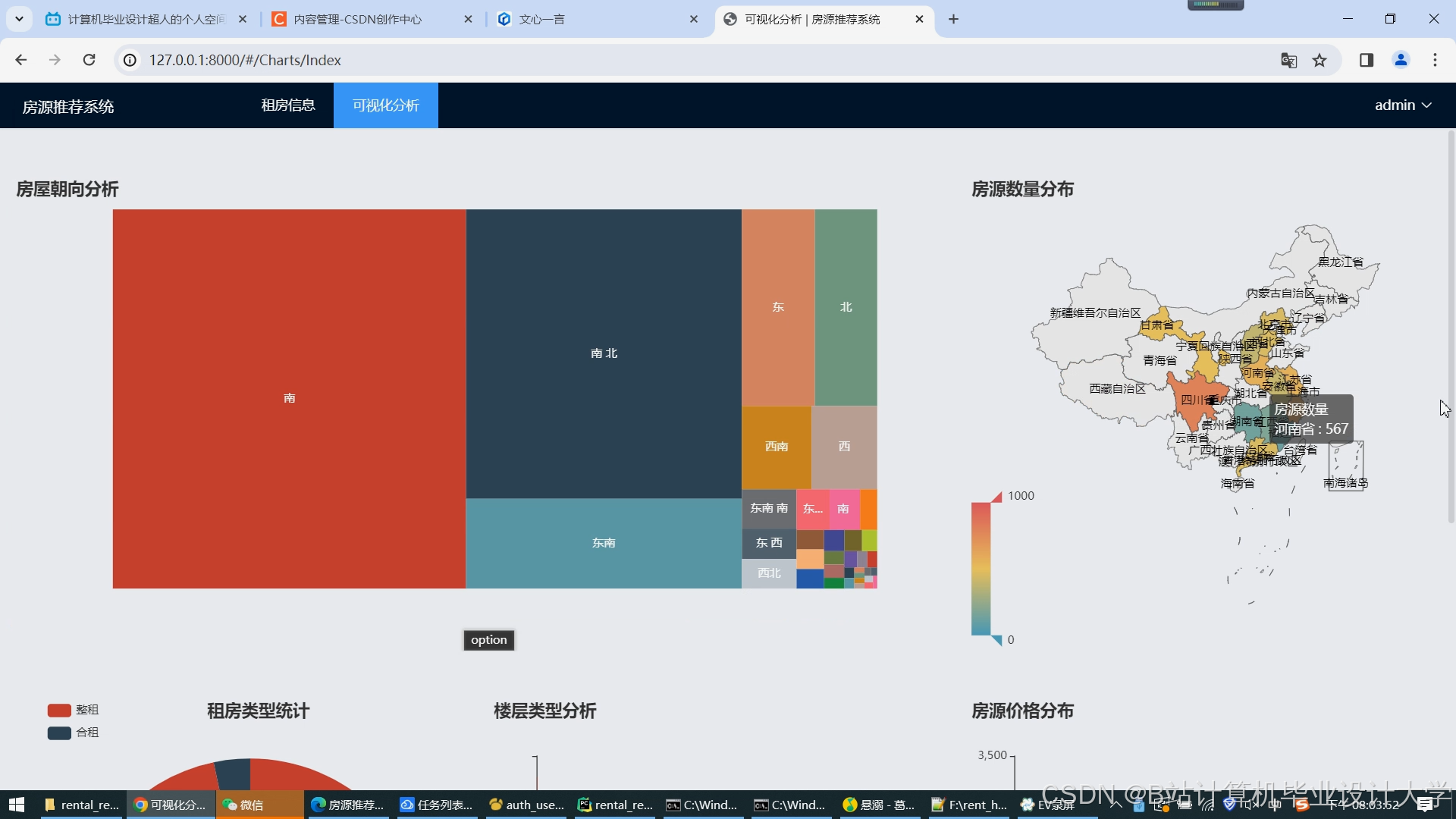
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











