




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive考研院校推荐系统与考研分数线预测系统技术说明
一、系统概述
本系统基于Hadoop、Spark和Hive技术构建,旨在为考研学子提供个性化的院校推荐与精准的分数线预测服务。系统整合多源异构考研数据,通过分布式存储与计算技术实现数据的高效处理,结合混合推荐算法与多模型融合预测方法,提升推荐准确率与预测精度。
二、技术架构
2.1 系统分层架构
系统采用分层架构设计,包括数据采集层、数据存储与处理层、模型训练与预测层和应用层。
- 数据采集层:利用Scrapy框架编写爬虫程序,从研招网、高校官网、考研论坛等渠道采集院校信息、历年分数线、招生计划、考生评价等多维度数据。爬虫程序支持动态网页抓取(如AJAX加载内容)与反爬机制应对,配置代理IP池与请求频率限制,降低被封禁风险。
- 数据存储与处理层:使用Hadoop HDFS分布式存储爬取的数据,提供高容错性与扩展性。利用Hive构建数据仓库,对清洗后的数据进行建模和存储,方便数据查询和分析。采用PySpark进行数据清洗、特征提取和模型训练,基于RDD/DataFrame API进行数据处理,提高数据处理效率。
- 模型训练与预测层:在院校推荐方面,设计混合推荐算法(协同过滤+内容推荐),开发考生画像生成引擎(含基础属性+行为特征),并实现动态权重调整机制(考虑政策变化)。在分数线预测方面,综合考虑多种影响因素,提取报考人数增长率、招生计划变化率、考试难度系数等特征,构建特征向量。选择时间序列模型(ARIMA、Prophet)、机器学习模型(随机森林、XGBoost)和深度学习模型(LSTM)等多种算法,使用Python的机器学习库(如Scikit-learn、TensorFlow、PyTorch)结合Spark的分布式计算能力进行模型训练,并采用集成学习策略提高预测精度和稳定性。
- 应用层:开发用户友好的前端界面,包括系统首页、院校推荐页面、分数线预测页面、个人中心页面等,提供简洁明了的操作流程和良好的用户体验。使用前端开发技术(如HTML、CSS、JavaScript、Vue.js/React.js等)实现前端界面的布局和交互功能,与后端系统进行数据交互和通信。
2.2 核心组件功能
- Hadoop HDFS:提供分布式存储能力,存储海量考研数据,支持PB级数据存储需求。
- Hive数据仓库:构建结构化数据模型,通过SQL查询语言实现复杂数据分析。
- Spark计算引擎:基于内存计算框架,提供快速数据处理能力,支持PySpark API进行特征工程与模型训练。
三、关键技术实现
3.1 数据采集与清洗
- 动态网页抓取:通过Scrapy-Splash或Selenium技术处理AJAX加载内容,确保数据完整性。
- 反爬机制应对:配置代理IP池与请求频率限制,降低被封禁风险。
- 数据清洗流程:去除重复数据、填充缺失值(如报考人数缺失时填充中位数)、处理异常值,通过Pandas库实现数据标准化。
3.2 混合推荐算法
- 协同过滤算法:基于用户相似性进行推荐,通过计算考生历史行为数据的余弦相似度,找到目标考生的相似用户群体。
- 基于内容的推荐算法:提取院校特征(如专业排名、地理位置)与考生画像(如成绩水平、兴趣偏好)进行匹配,使用TF-IDF算法对院校描述文本进行向量化处理。
- 动态权重调整机制:结合政策变化(如新增硕士点)、院校招生动态(如推免比例调整)等因素,通过实时计算调整推荐算法权重。
3.3 多模型融合预测
- 特征工程:提取时间序列特征(如年份、季度)、统计特征(如报录比、专业热度指数)、文本特征(如考生评价情感分析),使用随机森林进行特征重要性评估。
- 模型训练:
- 时间序列模型:ARIMA模型处理线性趋势,Prophet模型自动识别节假日效应。
- 机器学习模型:随机森林处理多特征融合,XGBoost优化非线性关系。
- 深度学习模型:LSTM网络捕捉分数线的长期依赖性,通过PyTorch实现端到端训练。
- 集成学习策略:采用Stacking方法融合多模型预测结果,使用线性回归作为元学习器,降低预测方差。
四、系统优势
- 数据维度丰富:整合结构化数据(如历年分数线)与非结构化数据(如考生评论文本),提升推荐与预测的准确性。
- 实时响应能力强:基于Spark Streaming的实时数据处理模块,使系统能够快速响应政策变化与考生行为更新。
- 可解释性强:通过知识图谱嵌入与特征重要性分析,为推荐与预测结果提供可解释性支持。
五、应用场景
- 考生端:提供个性化院校推荐、分数线预测、志愿填报模拟等功能,支持考生根据成绩、地域偏好、专业兴趣等条件筛选目标院校。
- 高校端:分析招生趋势,优化招生计划与资源配置,通过考生画像挖掘潜在优质生源。
- 教育机构:提供数据驱动的决策支持,辅助制定考研培训策略与课程设计。
六、总结
本系统通过Hadoop+Spark+Hive技术架构,实现了考研院校推荐与分数线预测的智能化升级。混合推荐算法与多模型融合预测方法显著提升了系统的准确性与稳定性,为考生、高校及教育机构提供了高效、精准的决策支持工具。未来,系统将进一步探索多模态数据融合与实时预测技术,推动考研信息服务向更高水平发展。
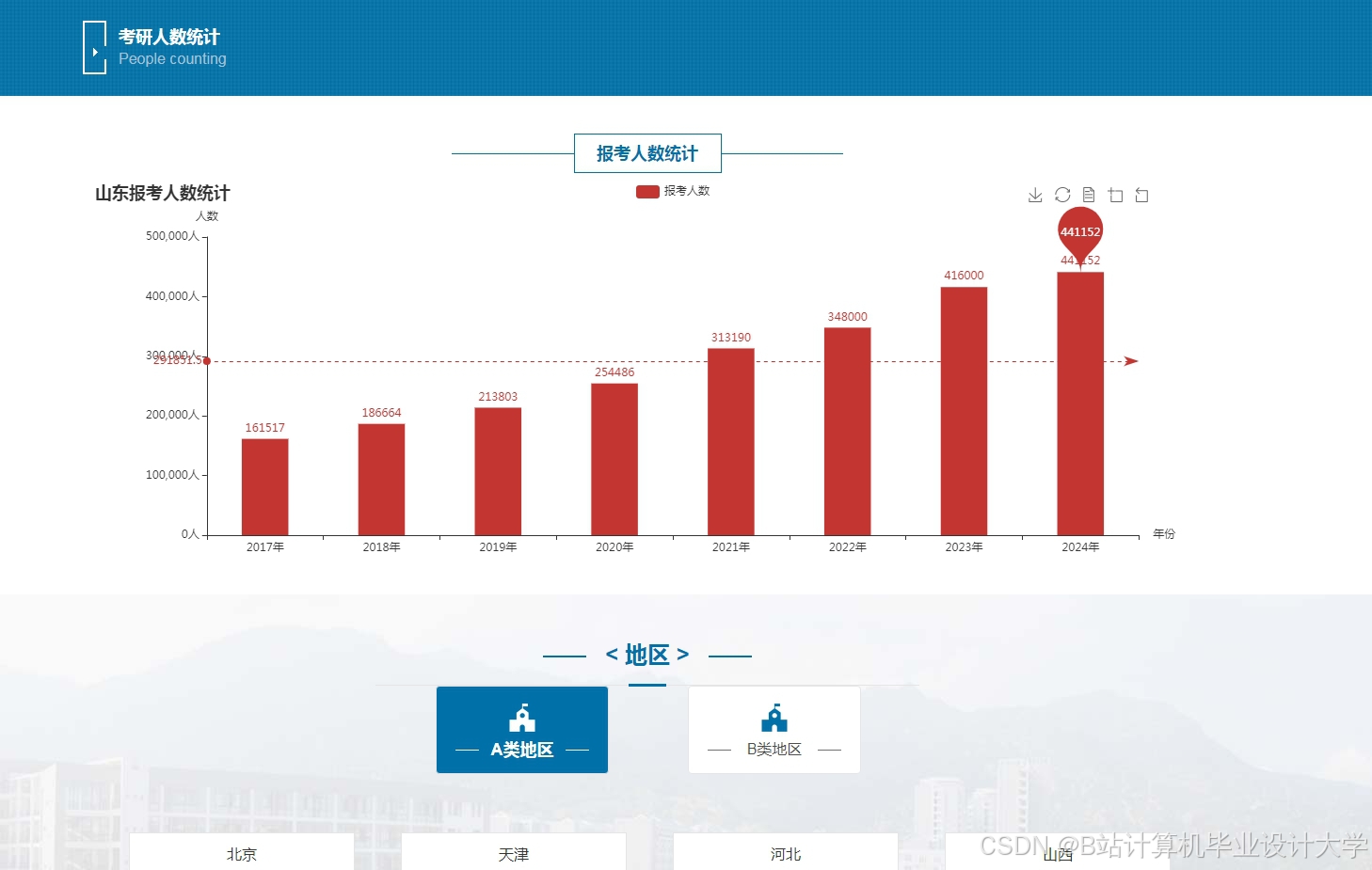
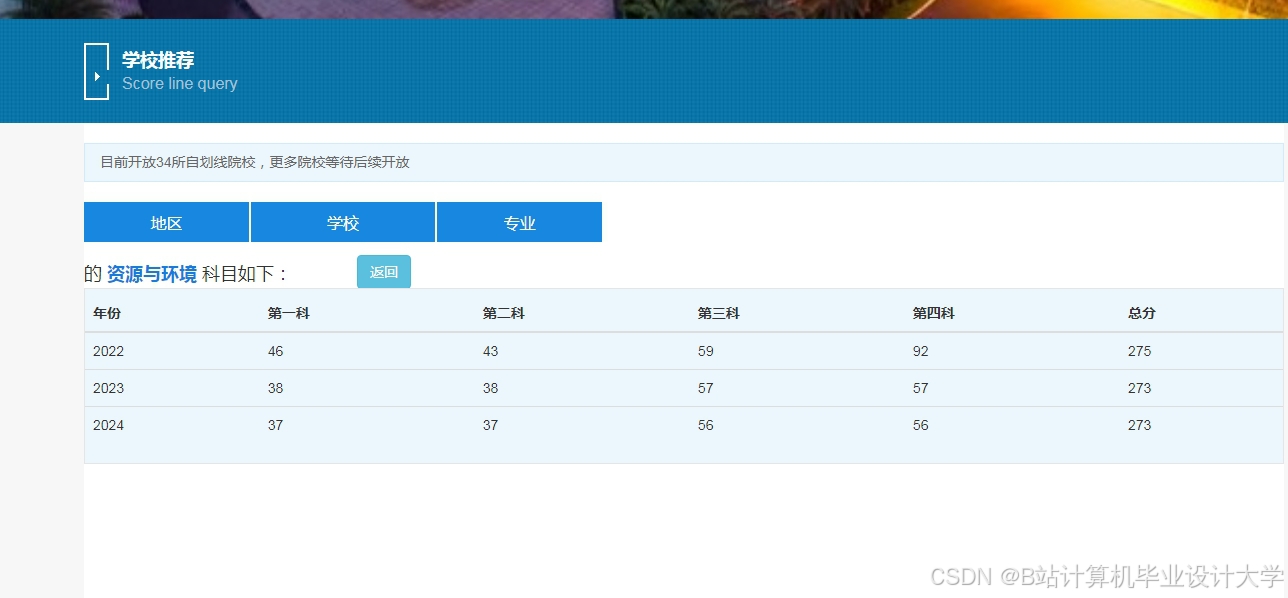
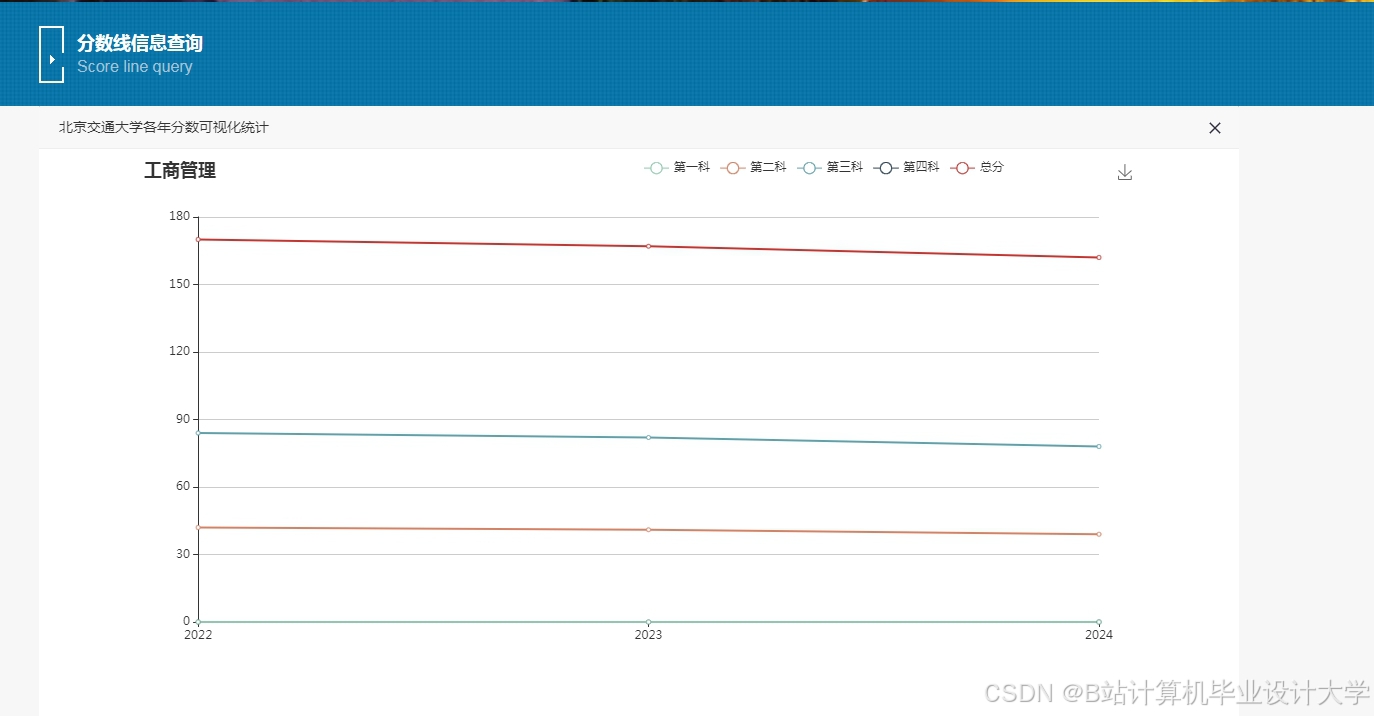
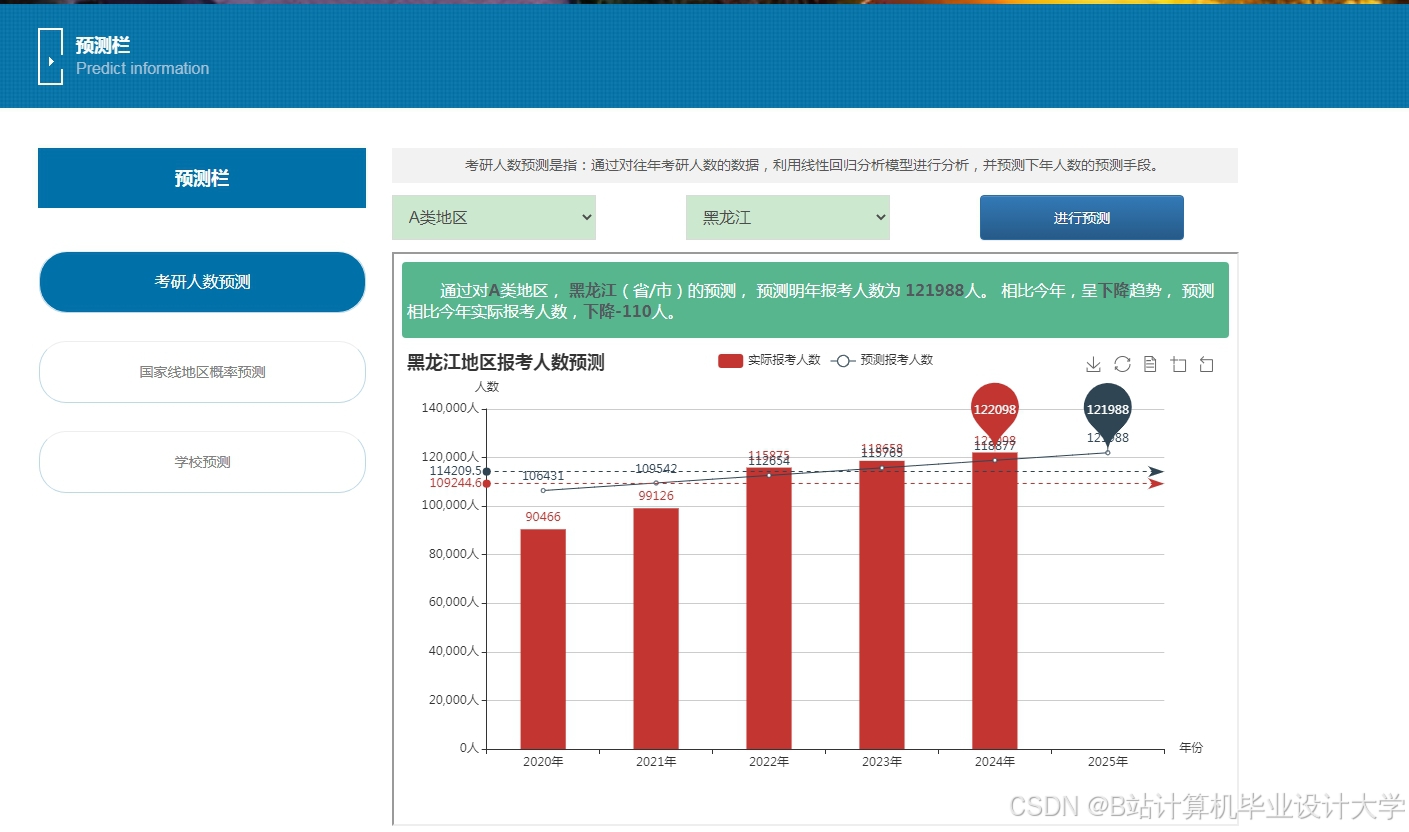
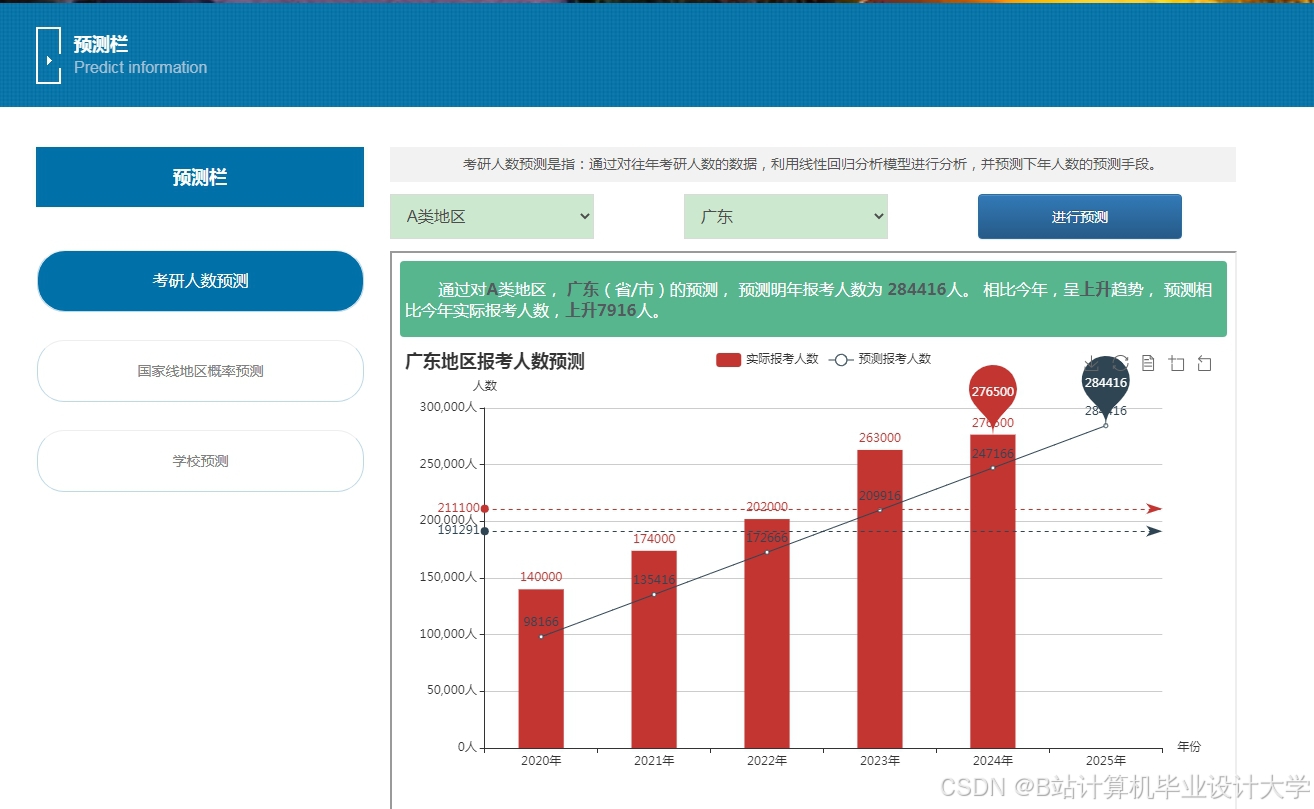
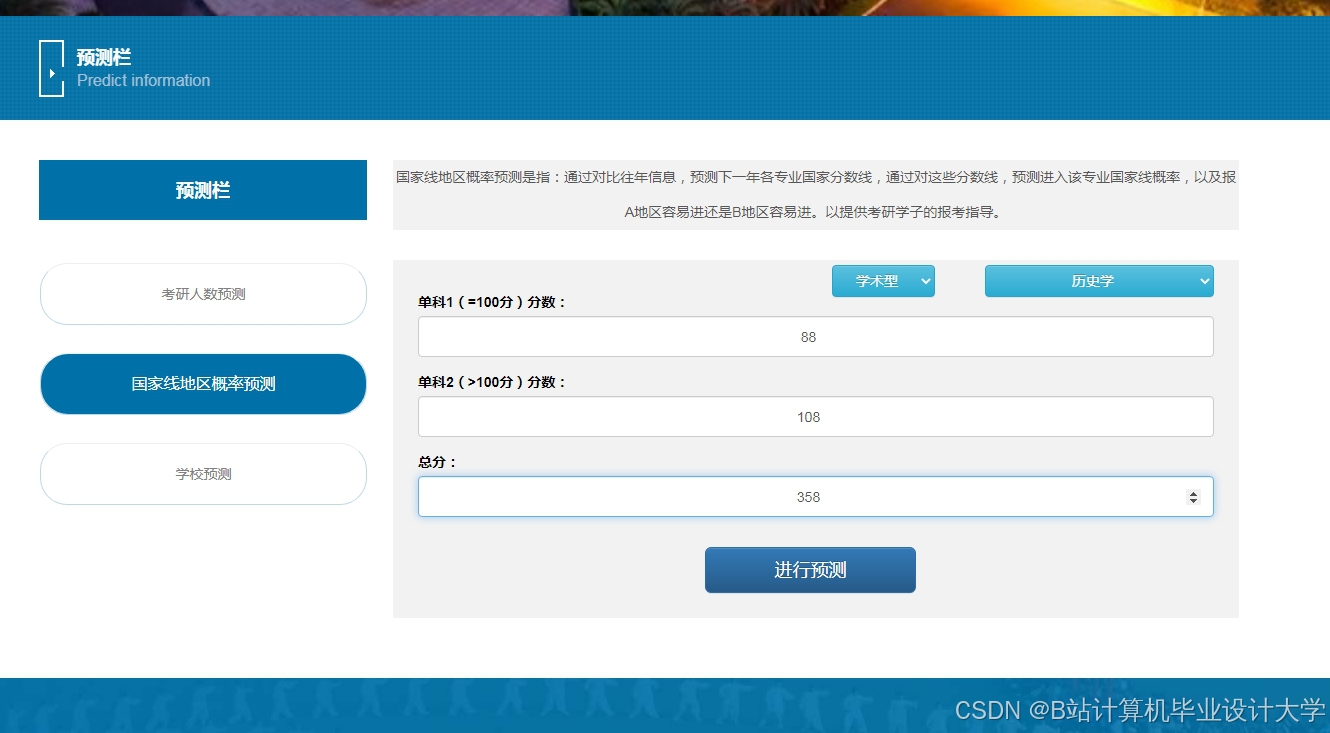
运行截图
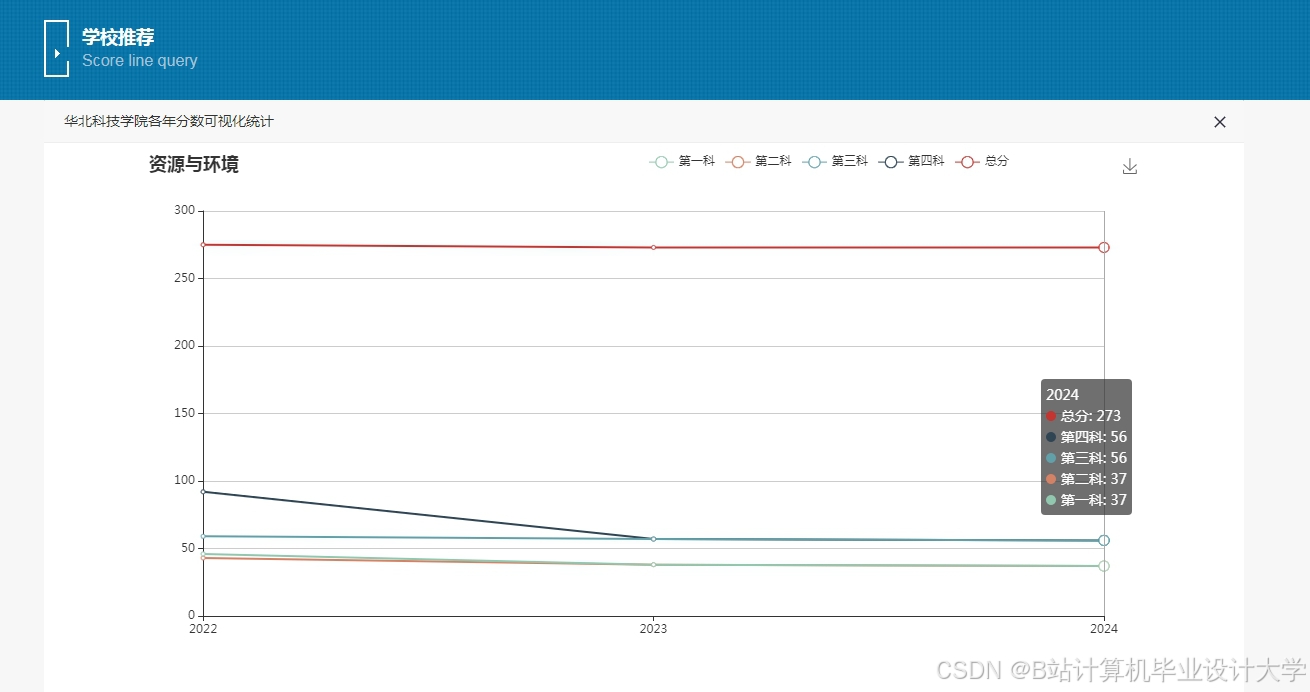
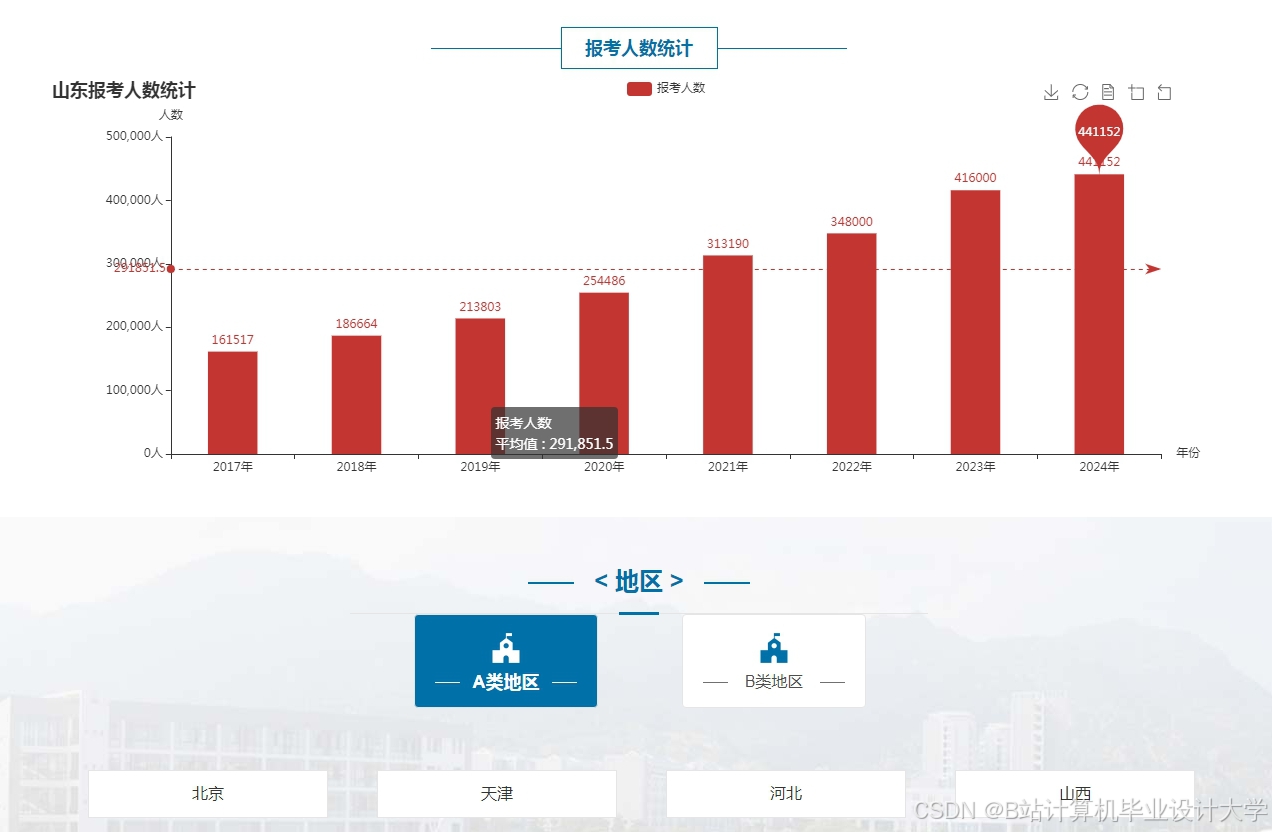
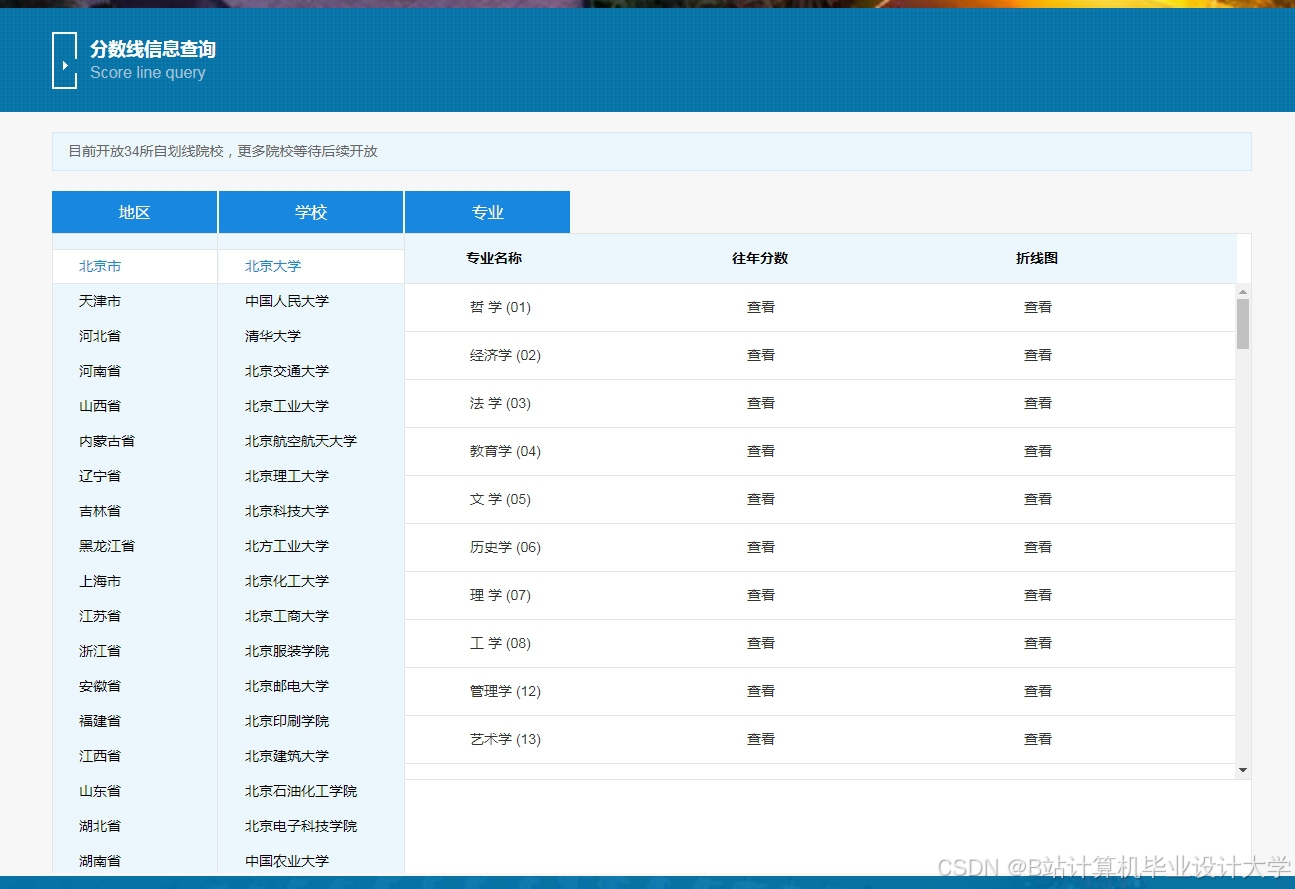
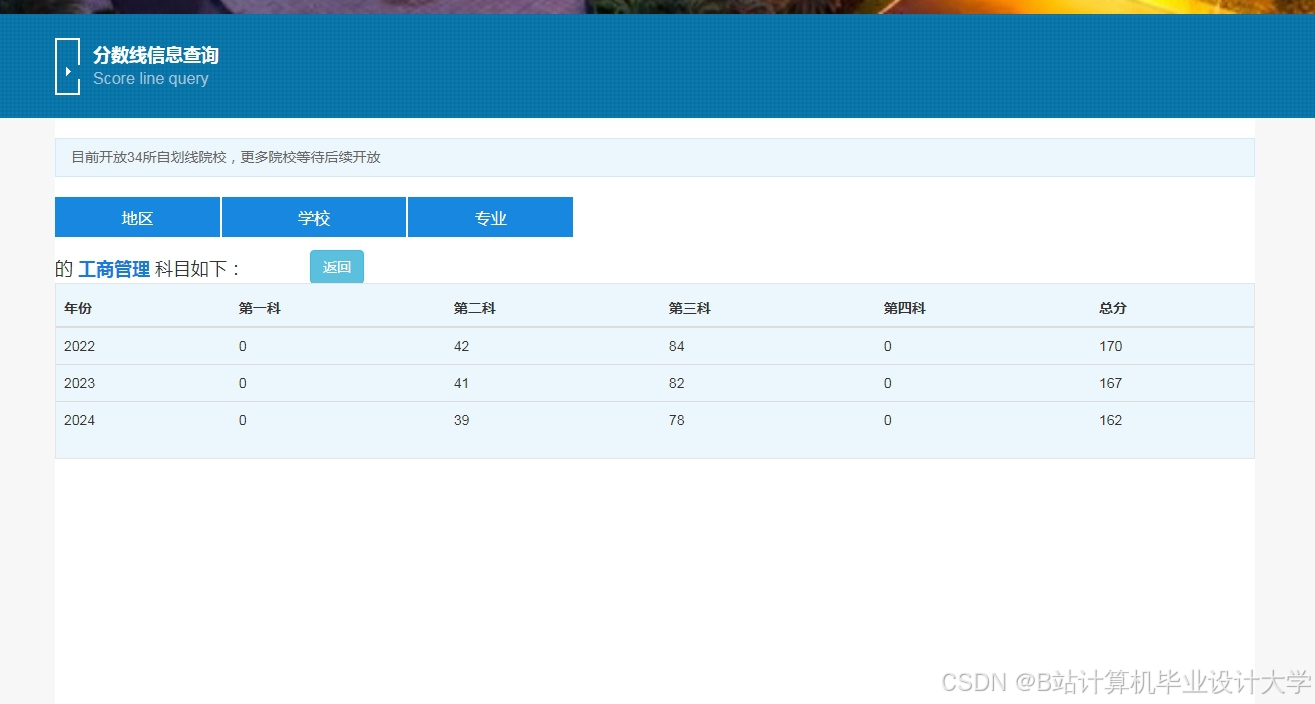
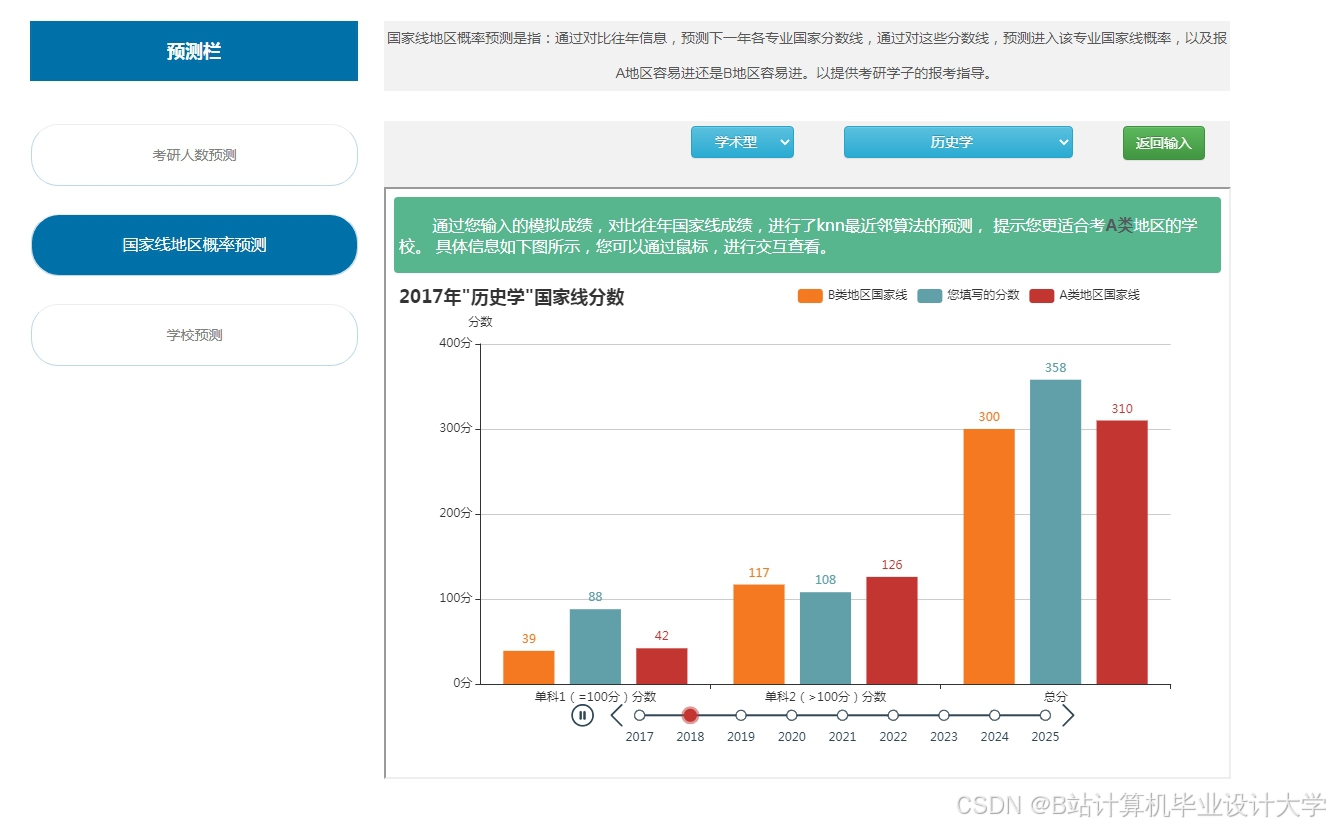
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











