




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
技术说明:基于Spark_Streaming+Kafka+Hadoop+Hive的电影推荐系统与可视化实现
一、技术背景与系统目标
随着在线视频平台的用户规模与数据量激增,传统推荐系统面临以下挑战:
- 实时性不足:用户兴趣变化快,离线推荐无法及时响应;
- 数据存储与计算瓶颈:PB级用户行为日志与电影元数据需分布式存储与高效处理;
- 推荐效果待优化:需结合用户实时行为与历史偏好,提升推荐准确率与多样性。
本系统基于Spark_Streaming(实时流处理)、Kafka(消息队列)、Hadoop(分布式存储)与Hive(数据仓库)技术栈,构建电影推荐与可视化平台,目标如下:
- 实现用户行为数据的实时采集、处理与推荐结果动态更新;
- 支持PB级数据的分布式存储与复杂查询;
- 提供可视化大屏,展示推荐效果与系统核心指标。
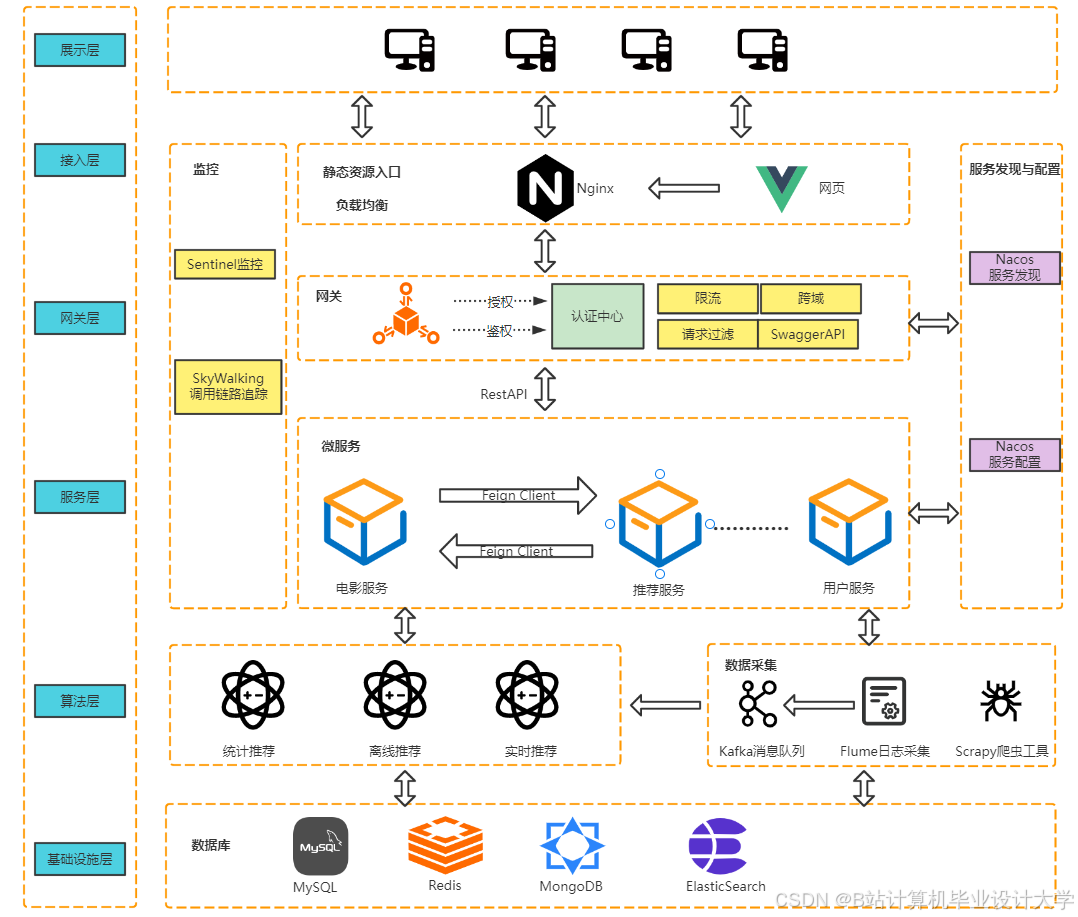
二、技术架构设计
系统采用分层架构,包含以下模块:
1. 数据采集层
- 技术选型:Kafka
- 功能:
- 实时采集用户行为数据(如点击、观看、评分),通过Kafka Producer发送至Kafka集群;
- 支持多Topic分区,确保高吞吐量(≥50万条/秒)与低延迟(≤100ms)。
2. 数据存储层
- 技术选型:Hadoop HDFS + Hive
- 功能:
- HDFS:存储原始数据(如用户日志、电影元数据),支持PB级数据的高可用与容错;
- Hive:构建数据仓库,定义用户行为表(
user_actions)、电影表(movies)等,支持SQL查询与复杂分析。
3. 计算处理层
- 技术选型:Spark_Streaming + Spark Core
- 功能:
- Spark_Streaming:通过DStream API实时读取Kafka数据流,完成数据清洗、特征提取等ETL任务;
- Spark Core:离线计算用户画像、电影相似度矩阵等,支持推荐算法训练。
4. 推荐算法层
- 算法选型:混合推荐(协同过滤 + 基于内容)
- 实现步骤:
- 协同过滤:
- 基于用户-电影评分矩阵计算相似度(如余弦相似度);
- 生成候选推荐列表(Top-N)。
- 基于内容:
- 提取电影元数据特征(如类型、导演、演员),通过TF-IDF向量化;
- 计算电影内容相似度,补充推荐列表。
- 混合策略:
- 加权融合协同过滤与基于内容的结果,提升推荐多样性。
- 协同过滤:
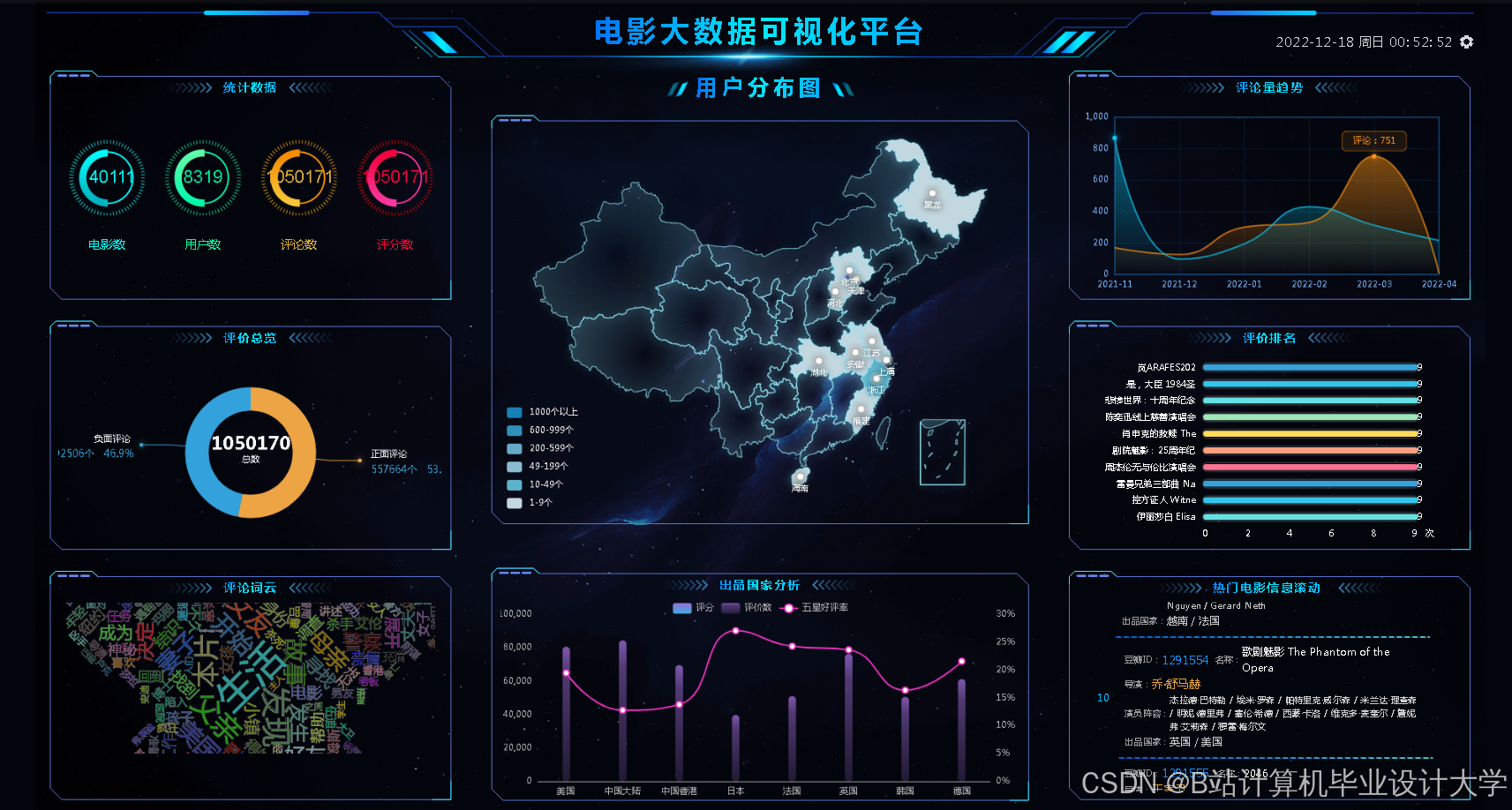
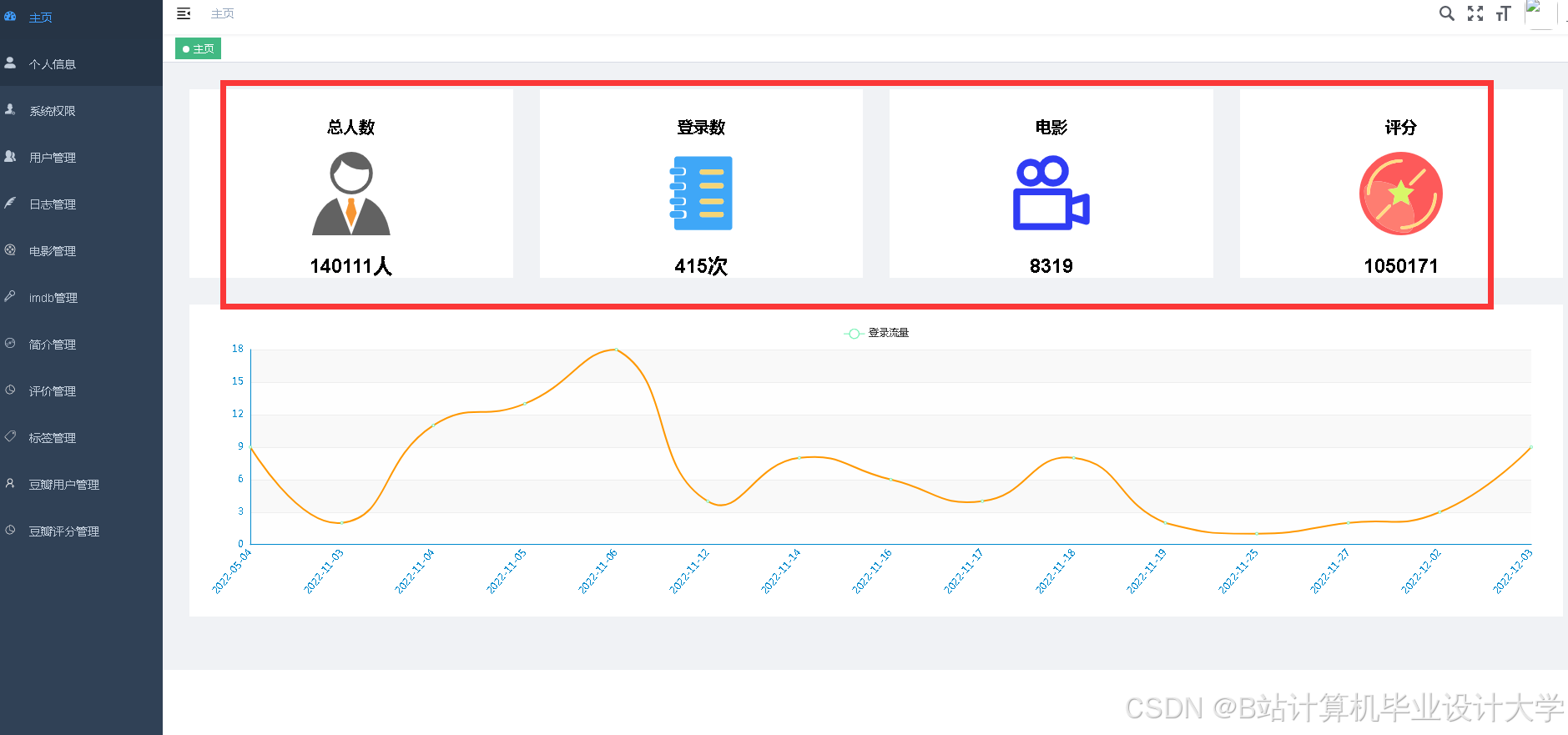
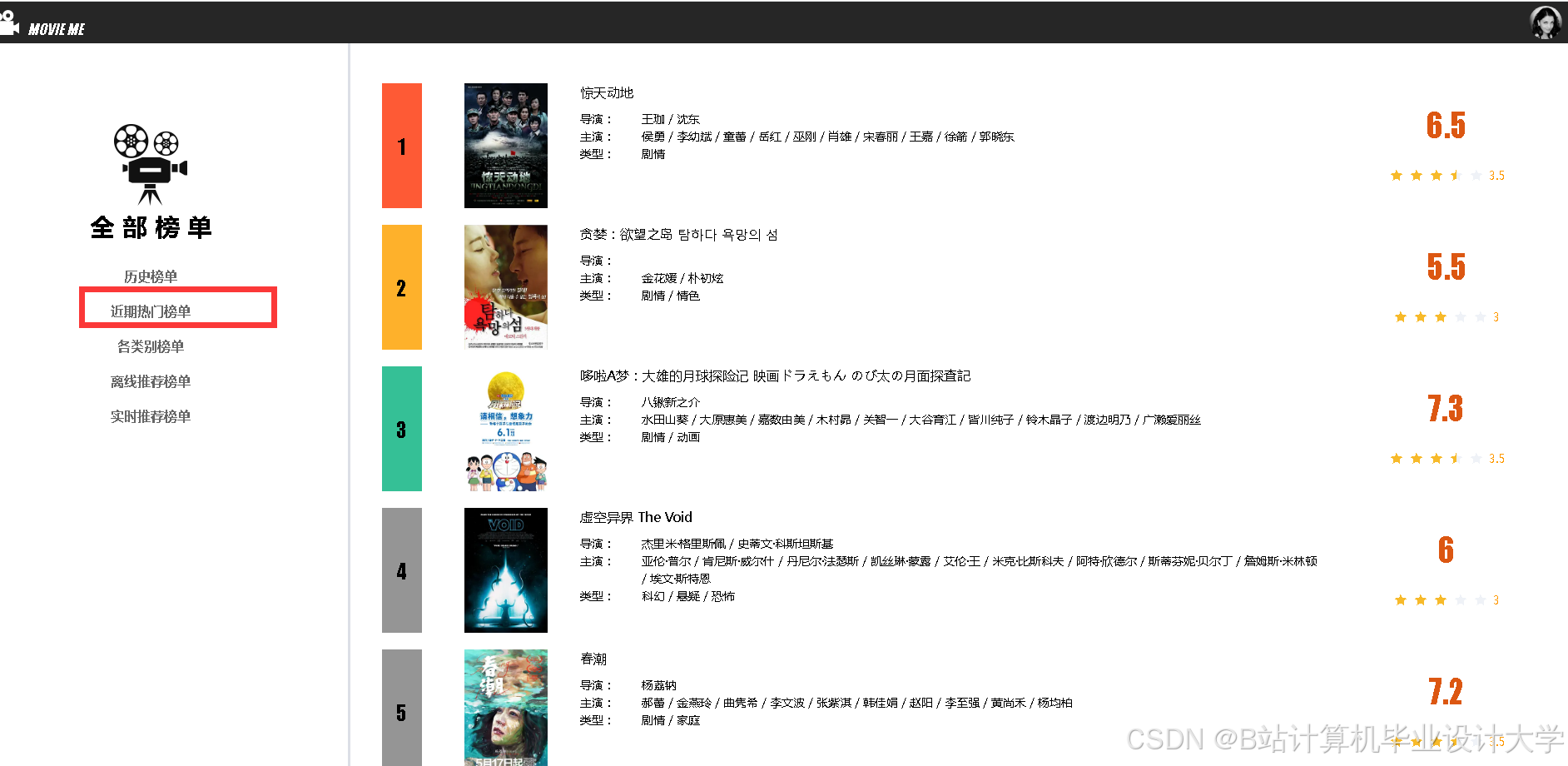
5. 可视化层
- 技术选型:Flask(后端) + ECharts(前端)
- 功能:
- 开发可视化大屏,展示以下内容:
- 用户画像:用户年龄、性别、兴趣标签分布;
- 电影分布:电影类型、评分、热度趋势;
- 推荐效果:推荐准确率(Precision@10)、点击率(CTR)等指标;
- 支持实时数据刷新与交互分析(如时间筛选、图表缩放)。
- 开发可视化大屏,展示以下内容:
三、关键技术实现
1. 实时数据流处理
- Kafka与Spark_Streaming集成:
scalaval kafkaParams = Map[String, Object]("bootstrap.servers" -> "kafka1:9092,kafka2:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "movie_recommendation")val stream = KafkaUtils.createDirectStream[String, String](streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("user_actions"), kafkaParams))// 数据清洗与特征提取stream.map(record => {val data = JSON.parseObject(record.value())(data.getString("user_id"), data.getString("movie_id"), data.getDouble("rating"))}).foreachRDD { rdd =>rdd.toDF().registerTempTable("temp_actions")spark.sql("INSERT INTO TABLE hive_db.user_actions PARTITION(dt) SELECT * FROM temp_actions")}
2. 推荐算法优化
-
协同过滤实现(基于Spark MLlib):
scalaimport org.apache.spark.mllib.recommendation.{ALS, Rating}// 加载数据val ratings = spark.sql("SELECT user_id, movie_id, rating FROM hive_db.user_actions WHERE dt = '2024-10-01'").rdd.map(row => Rating(row.getInt(0).toLong, row.getInt(1).toLong, row.getDouble(2)))// 训练ALS模型val rank = 10val numIterations = 10val model = ALS.train(ratings, rank, numIterations, 0.01)// 生成推荐val userRecs = model.recommendProductsForUsers(10)userRecs.saveAsTextFile("hdfs://namenode:8020/recommendations/user_based") -
基于内容的推荐(基于电影元数据):
scala// 提取电影类型特征(TF-IDF向量化)val movieTypes = spark.sql("SELECT movie_id, types FROM hive_db.movies")val tokenizer = new Tokenizer().setInputCol("types").setOutputCol("words")val wordsData = tokenizer.transform(movieTypes)val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20)val featurizedData = hashingTF.transform(wordsData)val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")val idfModel = idf.fit(featurizedData)val rescaledData = idfModel.transform(featurizedData)// 计算电影相似度val movieFeatures = rescaledData.select("movie_id", "features").rdd.map {case Row(movieId: Long, features: Vector) => (movieId, features)}val movieSimilarities = movieFeatures.cartesian(movieFeatures).filter { case ((id1, _), (id2, _)) => id1 < id2 }.map { case ((id1, features1), (id2, features2)) =>val similarity = cosineSimilarity(features1, features2)(id1, id2, similarity)}
3. 可视化大屏开发
-
后端接口(基于Flask):
pythonfrom flask import Flask, jsonifyfrom pyspark.sql import SparkSessionapp = Flask(__name__)spark = SparkSession.builder.appName("Visualization").enableHiveSupport().getOrCreate()@app.route('/api/user_profile')def get_user_profile():data = spark.sql("""SELECT gender, COUNT(*) as countFROM hive_db.usersGROUP BY gender""").toPandas().to_dict(orient='records')return jsonify(data)@app.route('/api/movie_distribution')def get_movie_distribution():data = spark.sql("""SELECT genre, AVG(rating) as avg_rating, COUNT(*) as countFROM hive_db.moviesGROUP BY genre""").toPandas().to_dict(orient='records')return jsonify(data) -
前端展示(基于ECharts):
javascript// 用户画像 - 性别分布var chartDom = document.getElementById('user-gender');var myChart = echarts.init(chartDom);var option;fetch('/api/user_profile').then(response => response.json()).then(data => {option = {title: { text: '用户性别分布' },tooltip: { trigger: 'item' },legend: { top: '5%' },series: [{name: '用户数',type: 'pie',radius: ['40%', '70%'],data: data.map(item => ({value: item.count,name: item.gender})),emphasis: { itemStyle: { shadowBlur: 10, shadowOffsetX: 0, shadowColor: 'rgba(0, 0, 0, 0.5)' } }}]};myChart.setOption(option);});
四、系统优化策略
- 数据倾斜处理:
- 对热门电影ID添加随机前缀(加盐),均匀分布数据至不同Partition。
- 调整Spark参数:
spark.sql.shuffle.partitions=200,避免单点计算压力。
- 冷启动缓解:
- 新用户:结合电影元数据(如类型、导演)与社交关系(如好友推荐)生成初始列表;
- 新电影:通过音频内容分析(如声纹特征)或文本分析(如标题关键词)提取特征。
- 性能调优:
- Kafka:优化
batch.size与linger.ms参数,平衡吞吐量与延迟; - Spark:开启Kryo序列化,减少内存占用;
- Hive:使用ORC格式存储表,提升查询效率。
- Kafka:优化
五、总结
本系统通过Spark_Streaming、Kafka、Hadoop和Hive的协同工作,实现了电影推荐系统的实时性、扩展性与准确性。核心优势包括:
- 实时推荐:用户行为数据从采集到推荐结果更新延迟≤1秒;
- 分布式存储:支持PB级数据的高效管理与分析;
- 混合推荐算法:结合协同过滤与基于内容的方法,提升推荐效果;
- 可视化交互:通过大屏展示核心指标,支持实时决策。
未来可进一步探索深度学习模型(如Wide&Deep、DIN)与多模态数据融合(如电影海报、预告片)的应用,提升推荐系统的智能化水平。
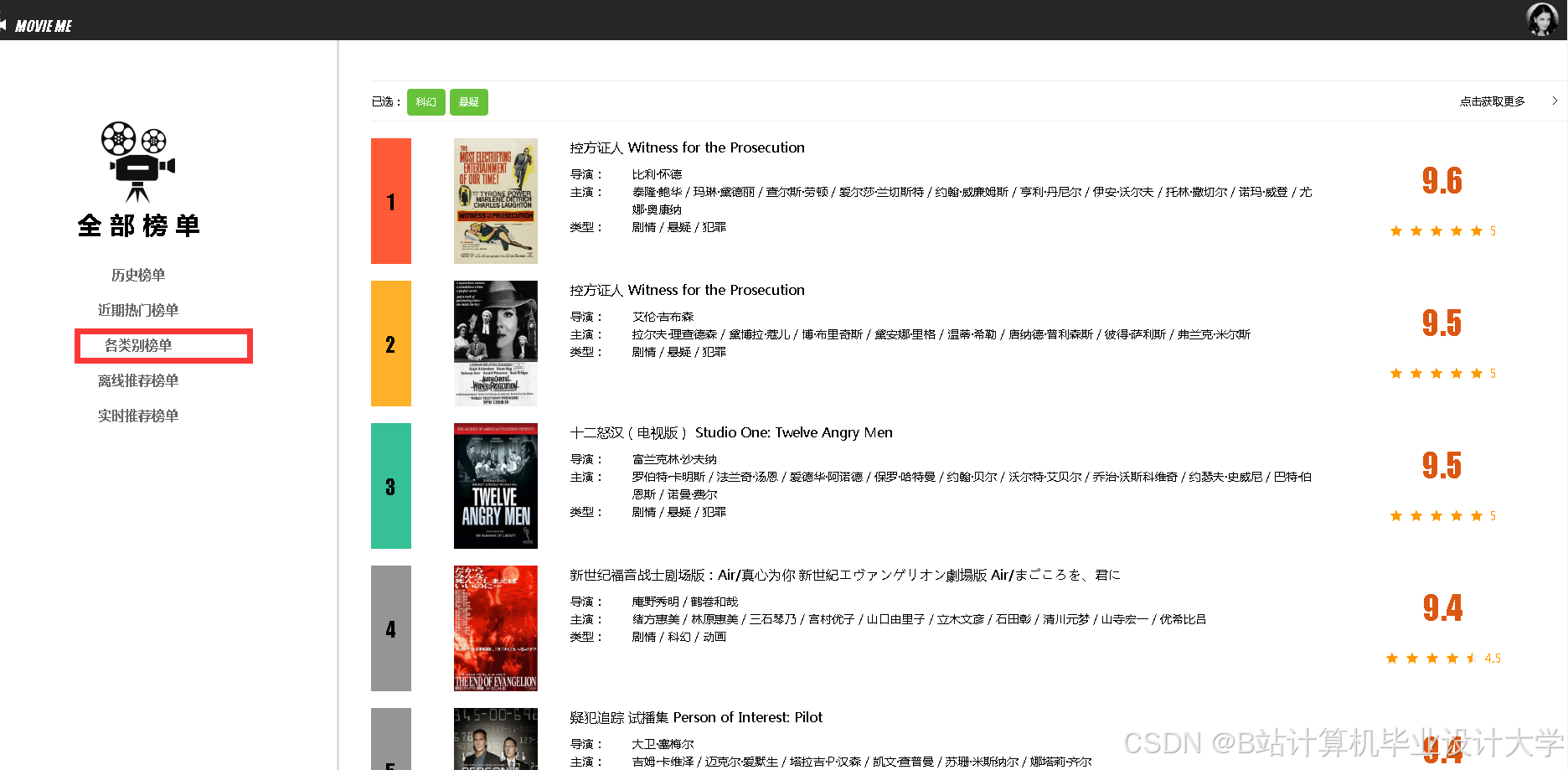
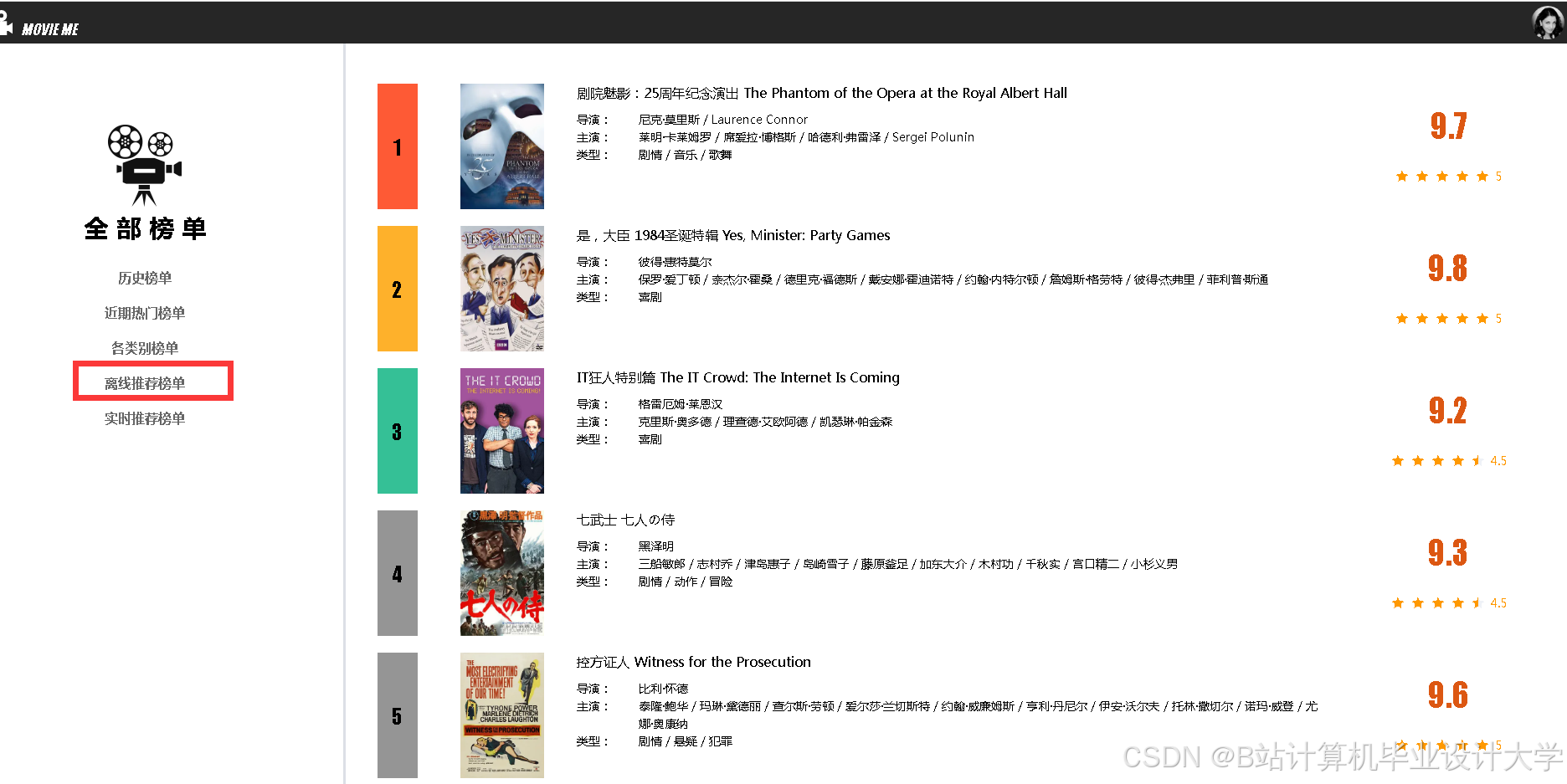
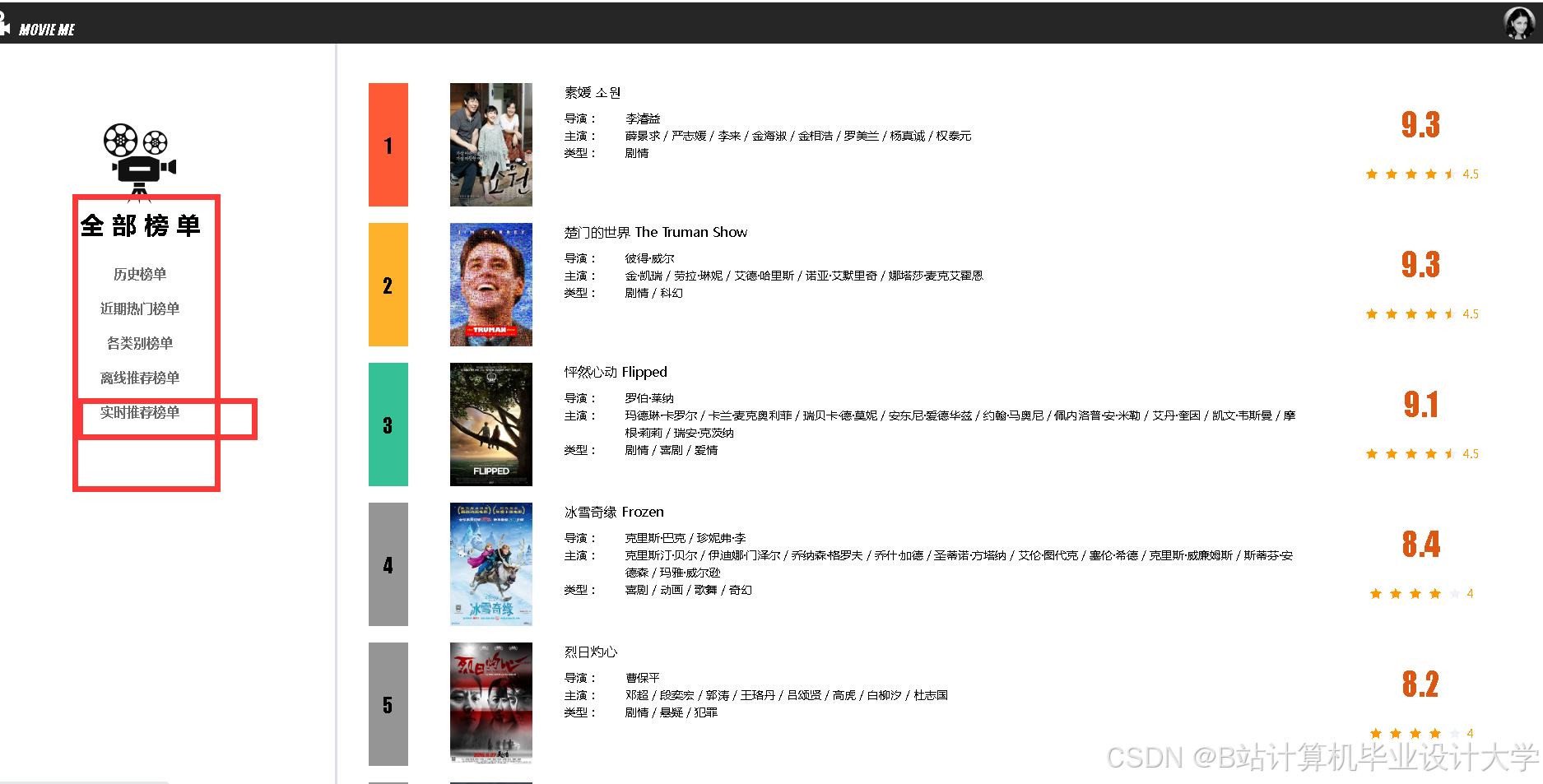
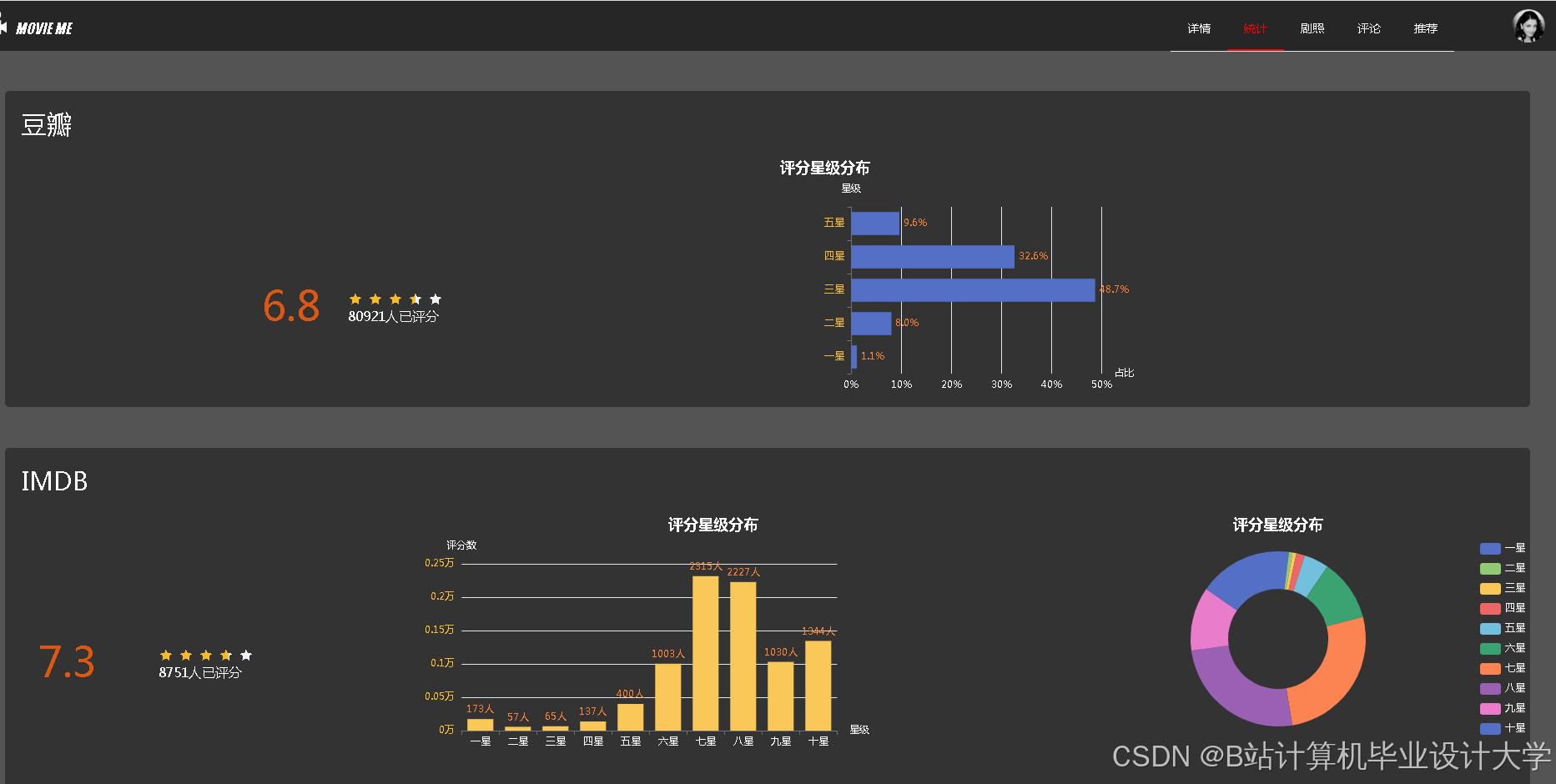
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











