




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python 新闻推荐系统:新闻标题自动分类与新闻可视化技术说明
一、引言
在信息爆炸的时代,新闻资讯呈海量增长态势,用户面临着从海量新闻中快速获取感兴趣内容的难题。新闻推荐系统应运而生,它依据用户兴趣偏好和行为数据,为用户精准推送个性化新闻。Python 凭借其丰富的库资源和简洁易用的语法,成为开发新闻推荐系统的热门选择。在新闻推荐系统中,新闻标题自动分类能精准标识新闻主题,为推荐提供基础;新闻可视化则以直观方式呈现新闻数据,提升用户体验。本技术说明将详细阐述基于 Python 的新闻推荐系统中新闻标题自动分类与新闻可视化的实现技术。
二、新闻标题自动分类技术
(一)数据采集与预处理
- 数据采集
利用 Python 的网络爬虫技术获取新闻标题数据。常用的库有requests和BeautifulSoup。例如,通过requests库发送 HTTP 请求获取新闻网页的 HTML 内容,再使用BeautifulSoup解析 HTML,提取新闻标题。对于一些大型新闻网站,可能需要处理反爬机制,如设置请求头、使用代理 IP 等。
python
import requests | |
from bs4 import BeautifulSoup | |
url = 'https://www.example-news.com' | |
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'} | |
response = requests.get(url, headers=headers) | |
soup = BeautifulSoup(response.text, 'html.parser') | |
titles = [title.get_text() for title in soup.find_all('h2', class_='news-title')] # 假设标题在 h2 标签且 class 为 news-title |
- 数据预处理
- 文本清洗:去除新闻标题中的特殊字符、HTML 标签、多余的空格等。可以使用正则表达式实现。
- 分词处理:对于中文新闻标题,使用
jieba分词库进行分词;对于英文标题,可以使用nltk库的分词功能。 - 停用词过滤:去除常见的无意义词汇,如“的”“是”“在”等。可以预先构建停用词表,在分词后过滤掉停用词。
python
import re | |
import jieba | |
# 文本清洗示例 | |
def clean_text(text): | |
text = re.sub(r'<[^>]+>', '', text) # 去除 HTML 标签 | |
text = re.sub(r'[^\w\s]', '', text) # 去除特殊字符 | |
return text.strip() | |
# 分词和停用词过滤示例 | |
stop_words = ['的', '是', '在'] # 示例停用词表 | |
title = "新冠疫苗研发取得重大突破" | |
cleaned_title = clean_text(title) | |
seg_list = jieba.cut(cleaned_title) | |
filtered_words = [word for word in seg_list if word not in stop_words] |
(二)特征提取
- TF-IDF 方法
计算每个词在文档中的词频(TF)和在整个文档集合中的逆文档频率(IDF),将文本转换为 TF-IDF 特征矩阵。使用scikit-learn库中的TfidfVectorizer实现。
python
from sklearn.feature_extraction.text import TfidfVectorizer | |
corpus = ["新冠疫苗研发取得重大突破", "美国国会通过新经济法案"] # 示例语料库 | |
vectorizer = TfidfVectorizer() | |
X = vectorizer.fit_transform(corpus) | |
print(X.toarray()) # 输出 TF-IDF 特征矩阵 |
- 词嵌入技术
将每个词映射为一个低维的稠密向量,能够更好地捕捉词之间的语义关系。常用的词嵌入模型有 Word2Vec 和 BERT。可以使用gensim库实现 Word2Vec,使用transformers库调用预训练的 BERT 模型。
(三)分类模型选择与训练
- 传统机器学习模型
如朴素贝叶斯、支持向量机等。使用scikit-learn库实现。
python
from sklearn.naive_bayes import MultinomialNB | |
from sklearn.model_selection import train_test_split | |
from sklearn.metrics import accuracy_score | |
# 假设已经有特征矩阵 X 和标签 y | |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) | |
clf = MultinomialNB() | |
clf.fit(X_train, y_train) | |
y_pred = clf.predict(X_test) | |
print("Accuracy:", accuracy_score(y_test, y_pred)) |
- 深度学习模型
如卷积神经网络(CNN)、循环神经网络(RNN)及其变体。可以使用Keras或PyTorch库实现。
三、新闻可视化技术
(一)可视化工具选择
- Matplotlib
一个功能强大的绘图库,可以绘制各种类型的图表,如折线图、柱状图、散点图等。适合简单的可视化需求。 - Seaborn
基于 Matplotlib,提供了更高级的接口和更美观的默认样式,适合绘制统计图表。 - PyEcharts
基于 ECharts 的 Python 可视化库,支持交互式可视化,能够生成更生动、直观的可视化图表,适合在网页中展示。
(二)可视化形式设计
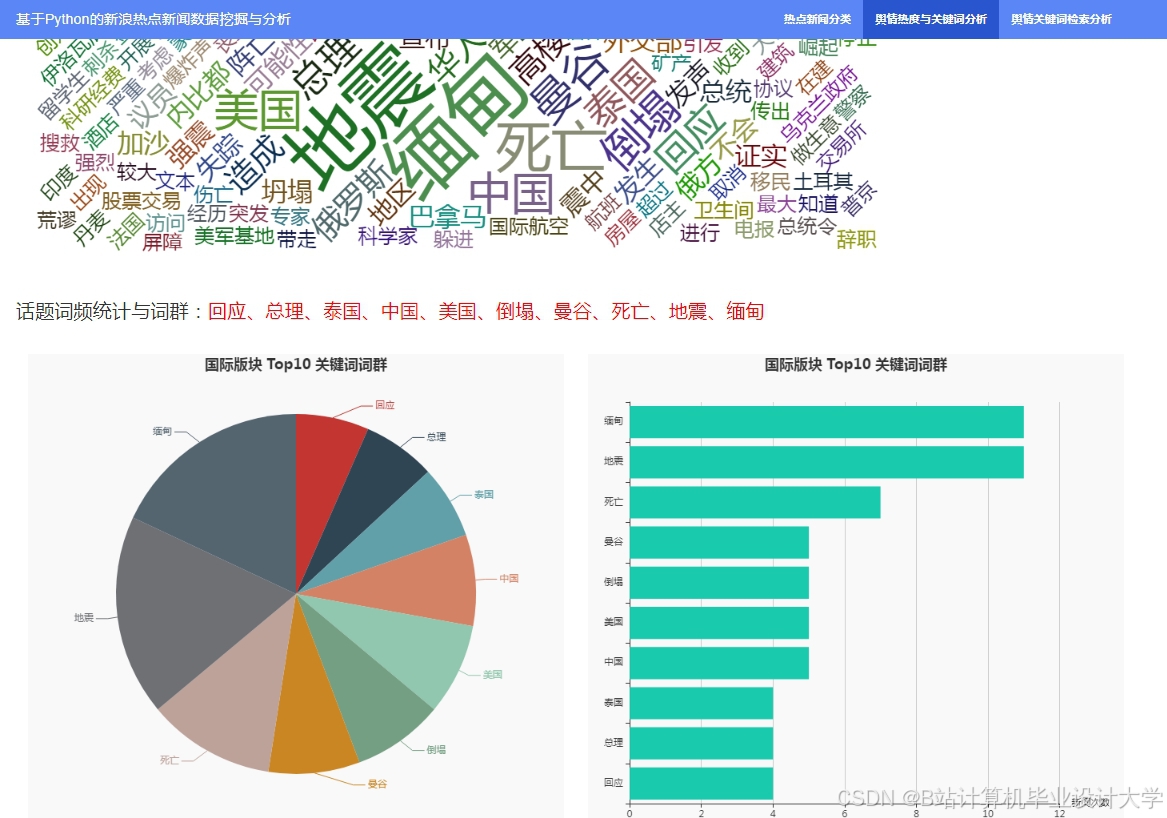
- 词云图
展示新闻标题中的热门词汇,直观反映新闻主题。可以使用wordcloud库或PyEcharts实现。
python
from wordcloud import WordCloud | |
import matplotlib.pyplot as plt | |
text = " ".join(["新冠疫苗研发取得重大突破", "人工智能技术在医疗领域的应用", "美国经济政策调整"]) | |
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text) | |
plt.figure(figsize=(10, 5)) | |
plt.imshow(wordcloud, interpolation='bilinear') | |
plt.axis('off') | |
plt.show() |
- 柱状图
比较不同类别新闻的数量。使用Matplotlib或PyEcharts实现。
python
from pyecharts.charts import Bar | |
from pyecharts import options as opts | |
categories = ['科技', '政治', '经济'] | |
counts = [10, 8, 12] | |
bar = ( | |
Bar() | |
.add_xaxis(categories) | |
.add_yaxis("新闻数量", counts) | |
.set_global_opts(title_opts=opts.TitleOpts(title="不同类别新闻数量统计")) | |
) | |
bar.render("bar_chart.html") |
- 折线图
展示新闻发布时间的变化趋势。
python
from pyecharts.charts import Line | |
dates = ['2023-01-01', '2023-01-02', '2023-01-03'] | |
counts = [5, 8, 6] | |
line = ( | |
Line() | |
.add_xaxis(dates) | |
.add_yaxis("新闻发布数量", counts) | |
.set_global_opts(title_opts=opts.TitleOpts(title="新闻发布时间趋势")) | |
) | |
line.render("line_chart.html") |
(三)可视化实现与集成
将生成的可视化图表集成到新闻推荐系统的前端界面中。如果使用 PyEcharts,生成的图表是 HTML 文件,可以通过前端框架(如 Flask、Django)将 HTML 文件嵌入到网页中。
四、在新闻推荐系统中的集成与应用
(一)与推荐算法的结合
新闻标题自动分类的结果可以作为推荐算法的重要输入。例如,在基于内容的推荐算法中,根据新闻标题的分类标签,计算新闻之间的相似度,为用户推荐与其历史浏览新闻相似的新闻。在协同过滤推荐算法中,分类标签可以用于用户聚类或物品聚类,提高推荐的准确性。
(二)提升用户体验
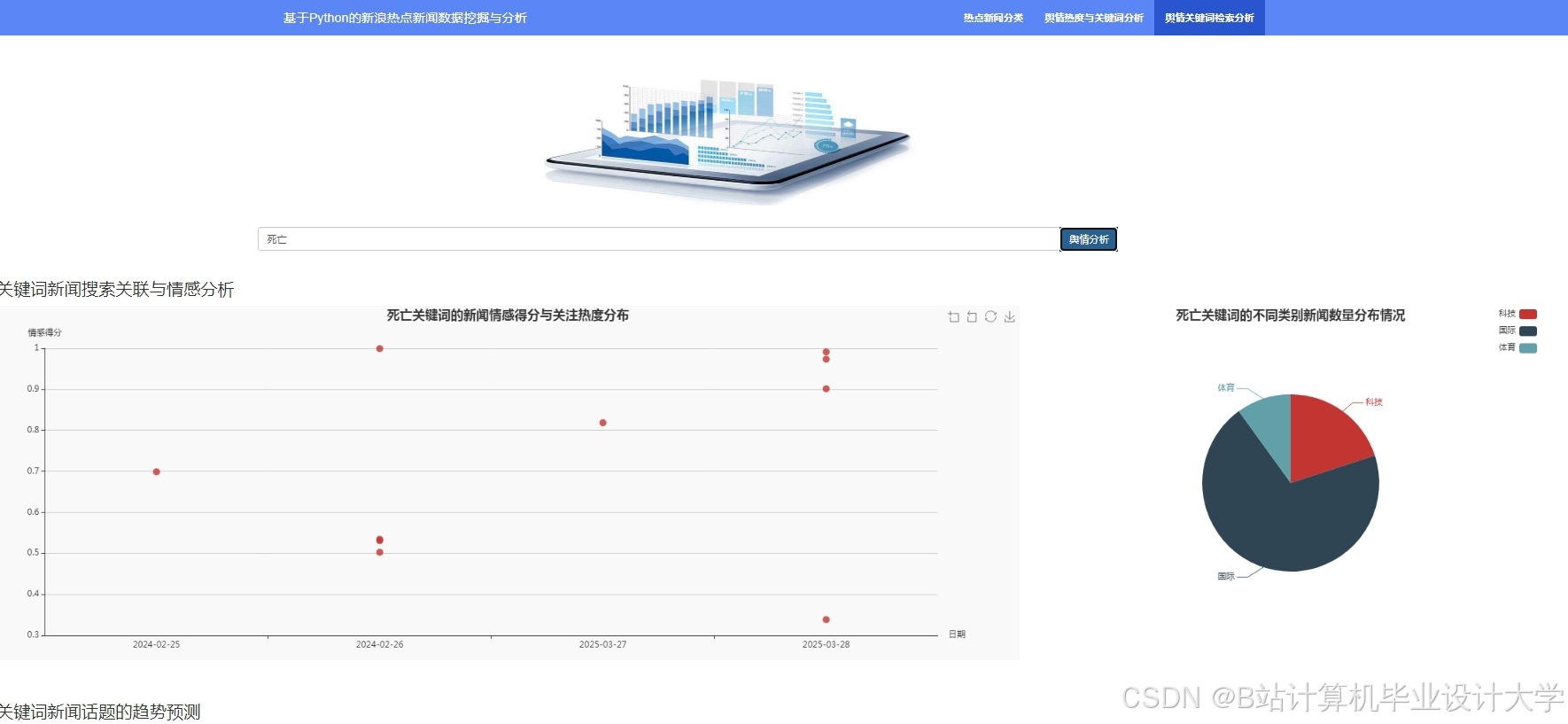
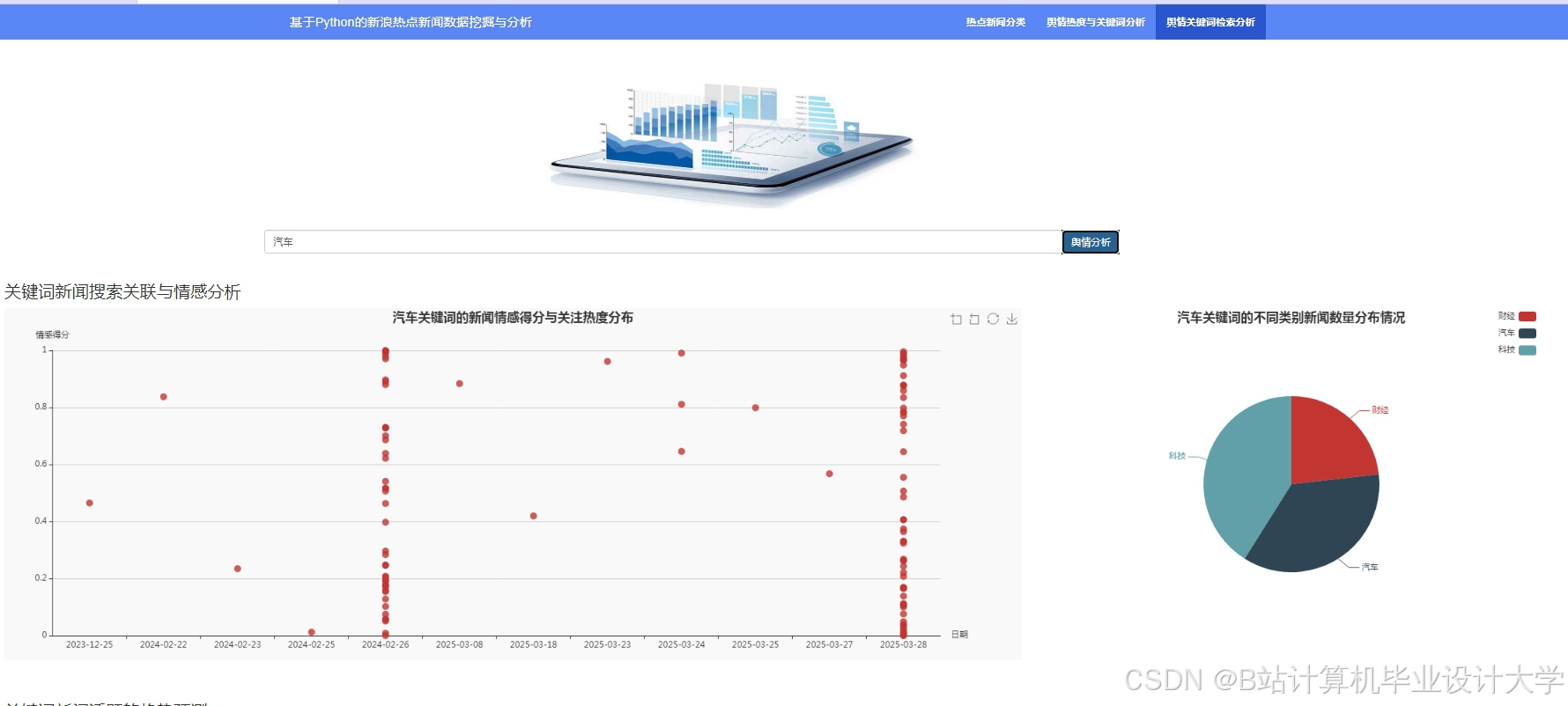
新闻可视化将推荐结果以直观的方式呈现给用户。用户可以通过查看词云图快速了解推荐新闻的热门话题,通过柱状图和折线图了解新闻的类别分布和发布趋势,从而更方便地筛选自己感兴趣的新闻。
五、总结
基于 Python 的新闻推荐系统中的新闻标题自动分类与新闻可视化技术,通过数据采集、预处理、特征提取、分类模型训练和可视化设计等步骤,实现了新闻标题的自动分类和新闻数据的直观展示。这些技术能够有效提高新闻推荐系统的准确性和用户体验,帮助用户在海量新闻中快速找到感兴趣的内容。在实际应用中,可以根据具体需求选择合适的算法和可视化工具,不断优化系统性能。
运行截图
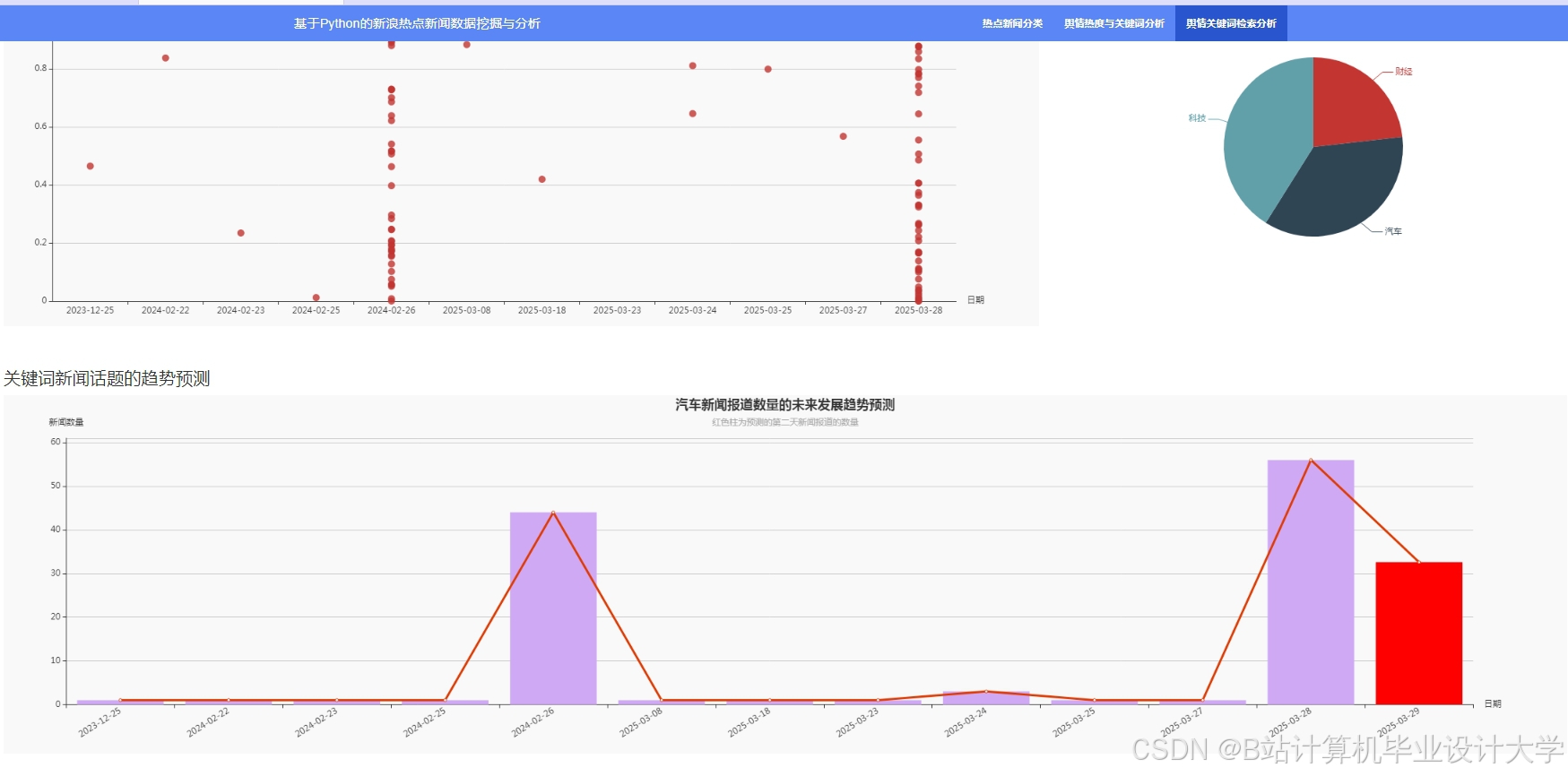
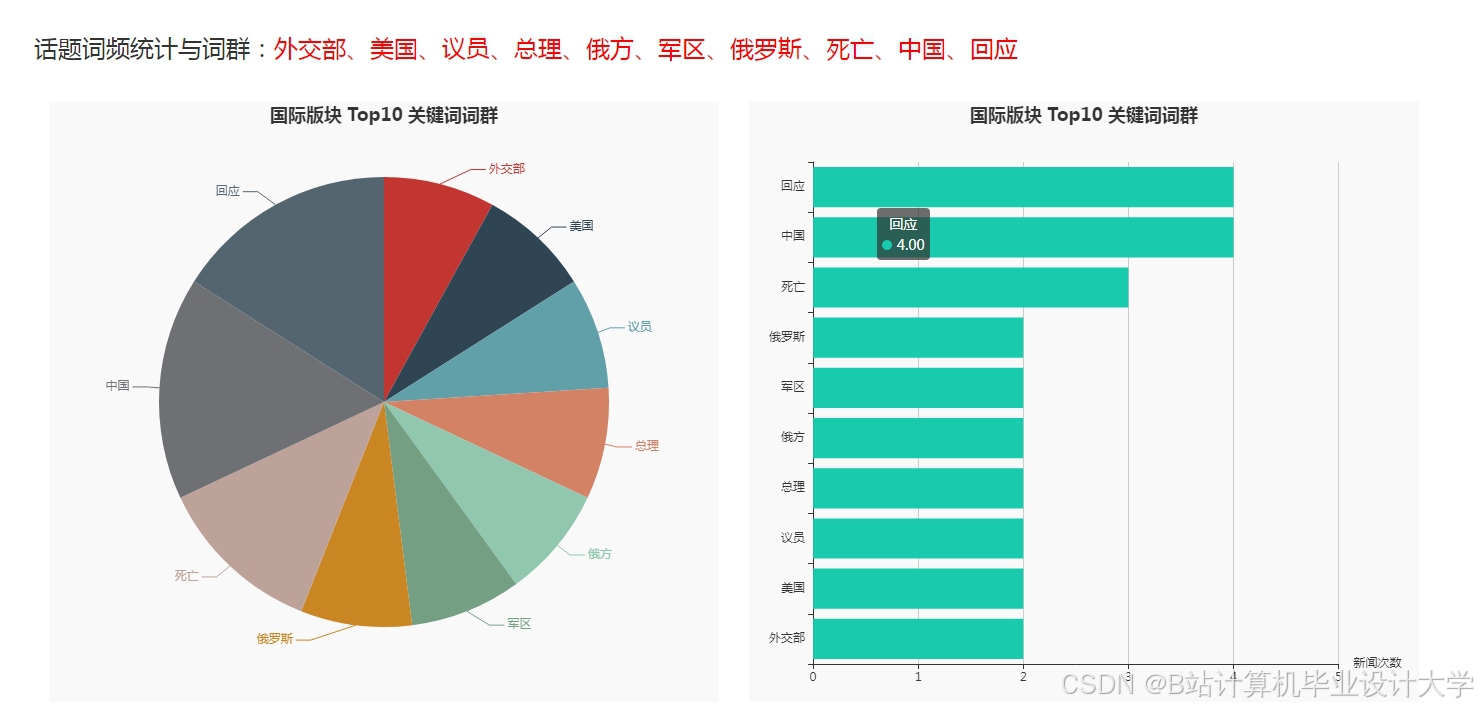
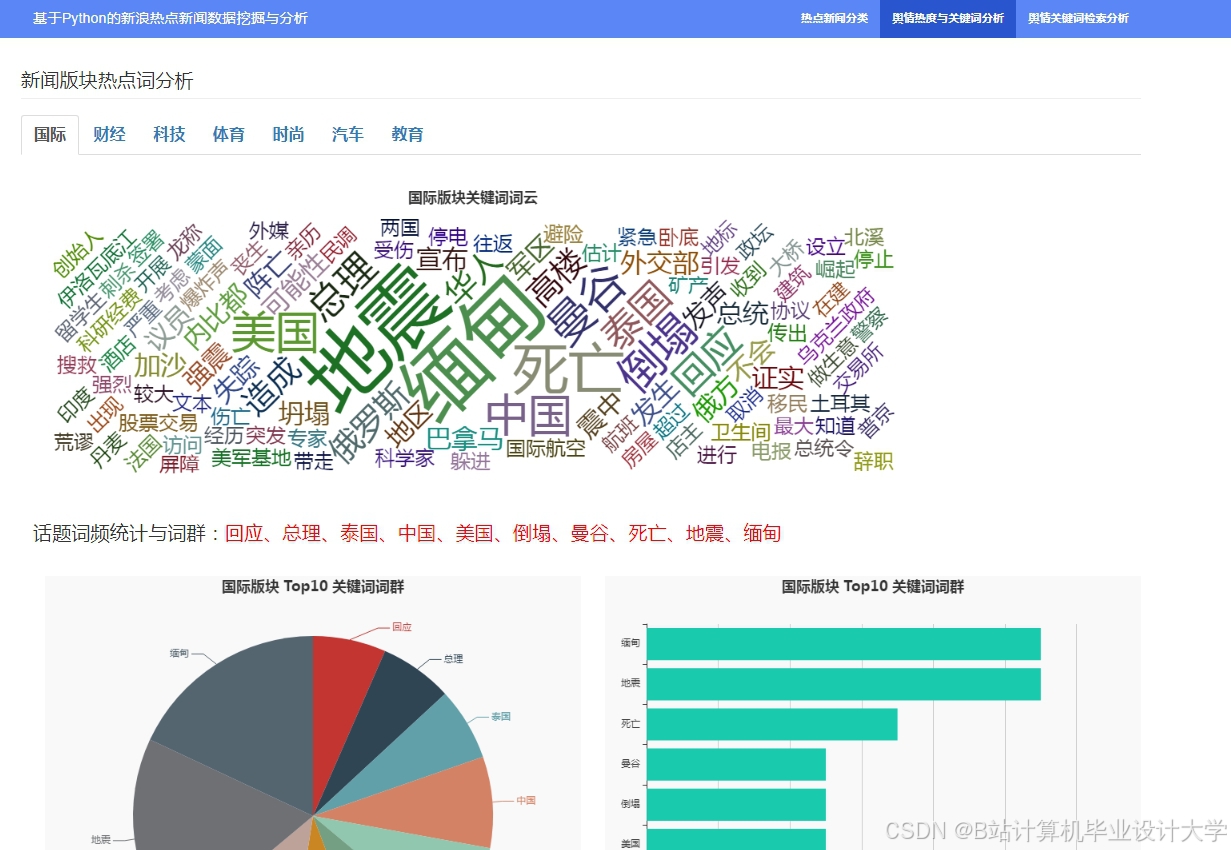
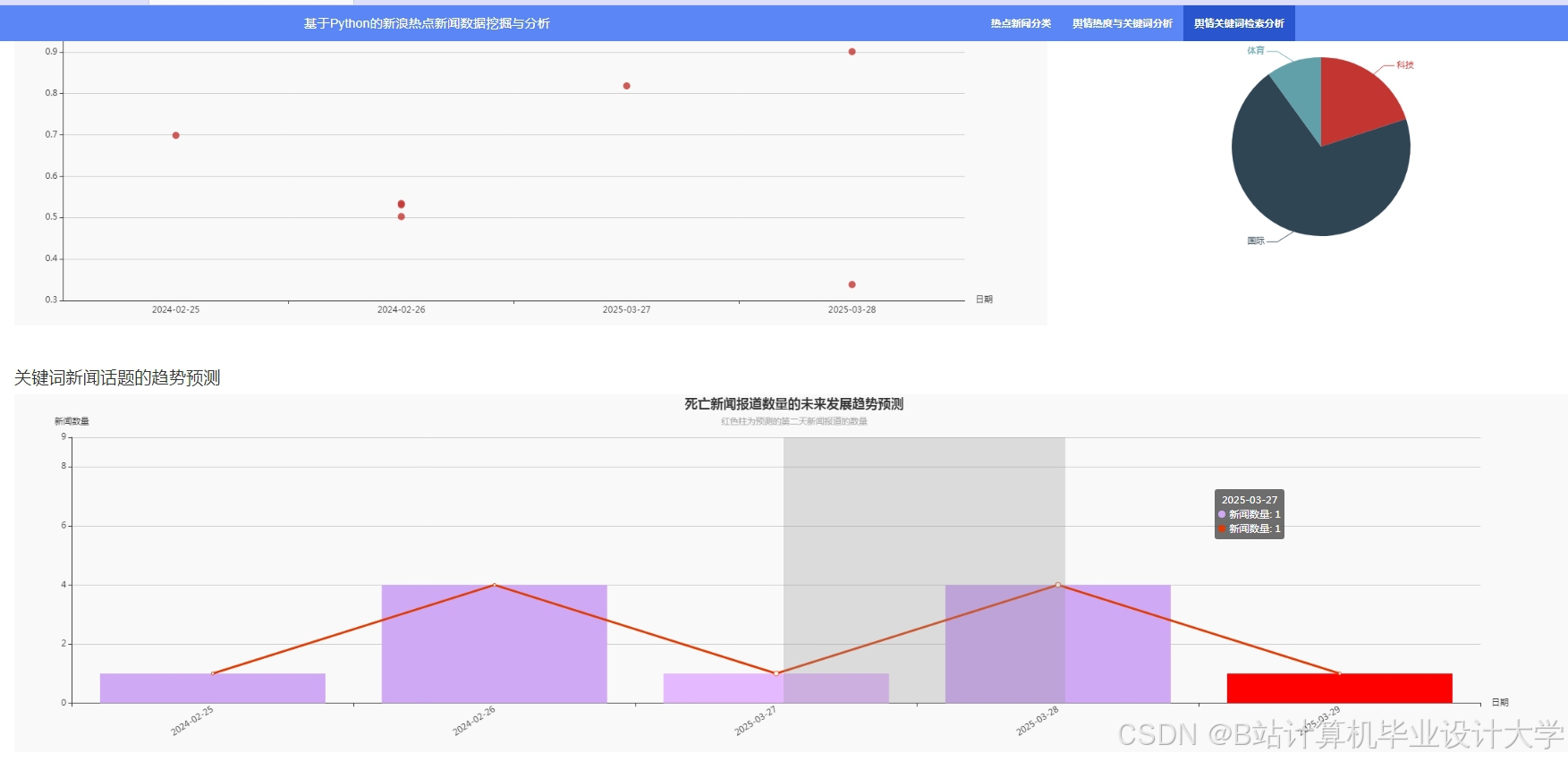
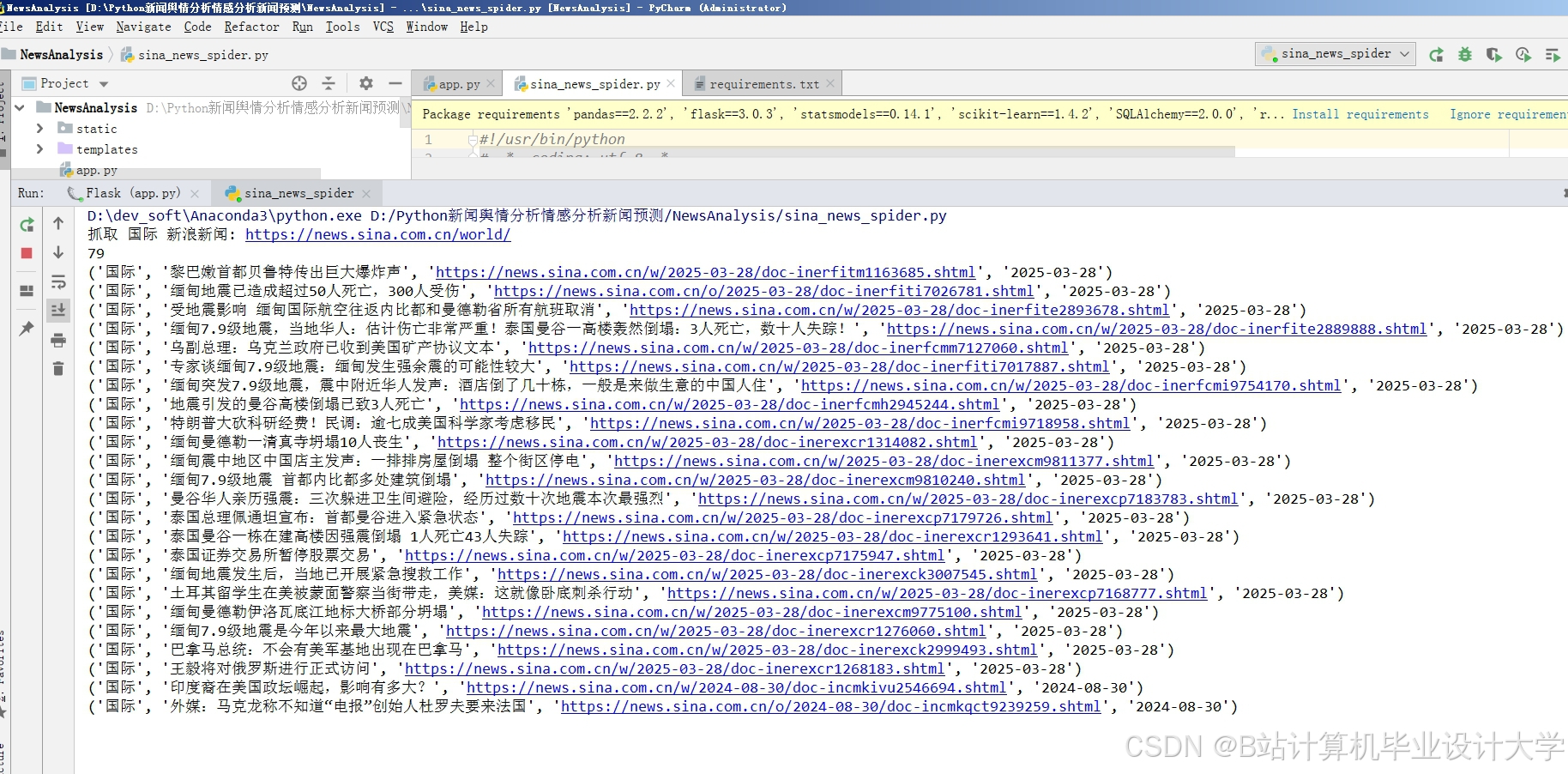
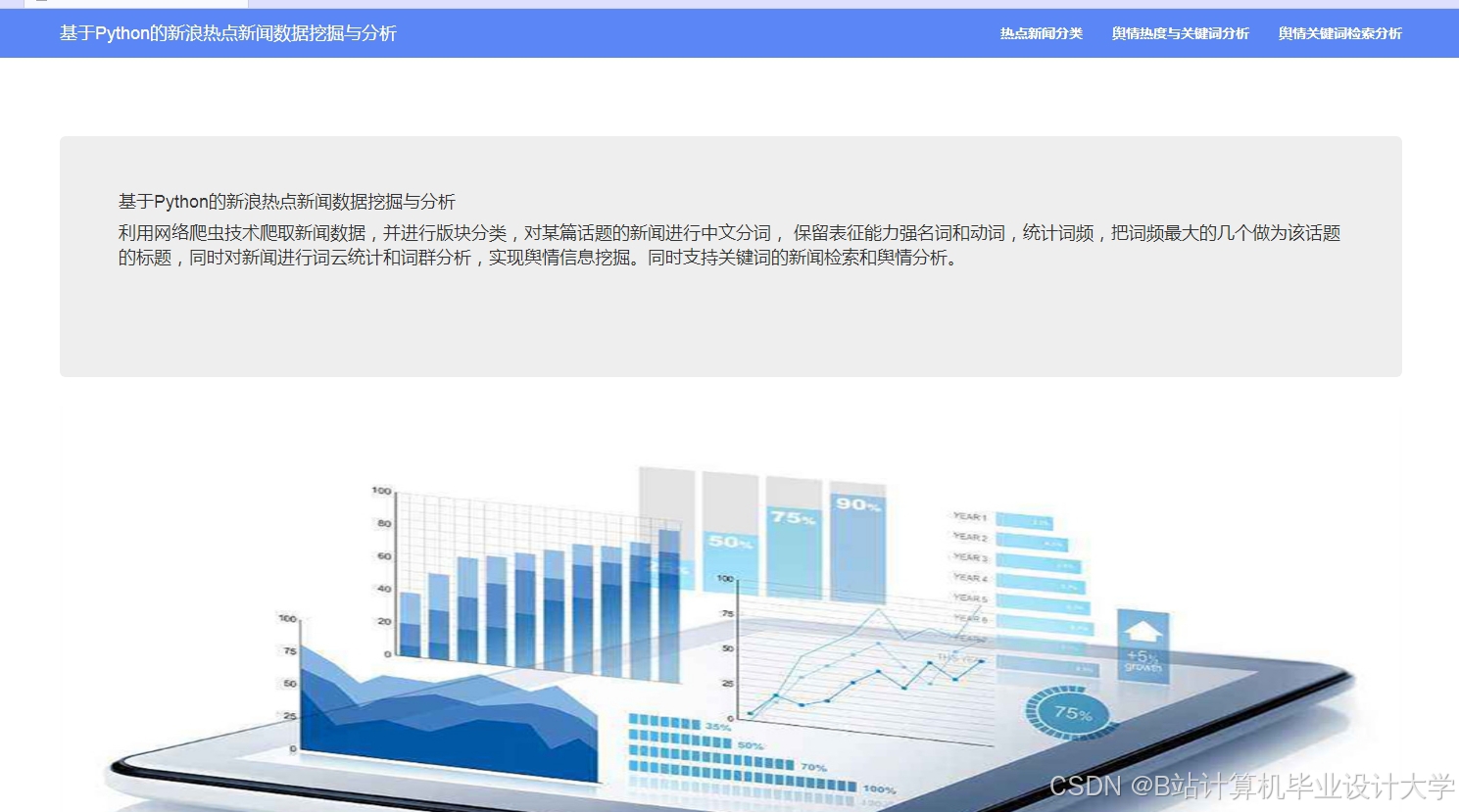
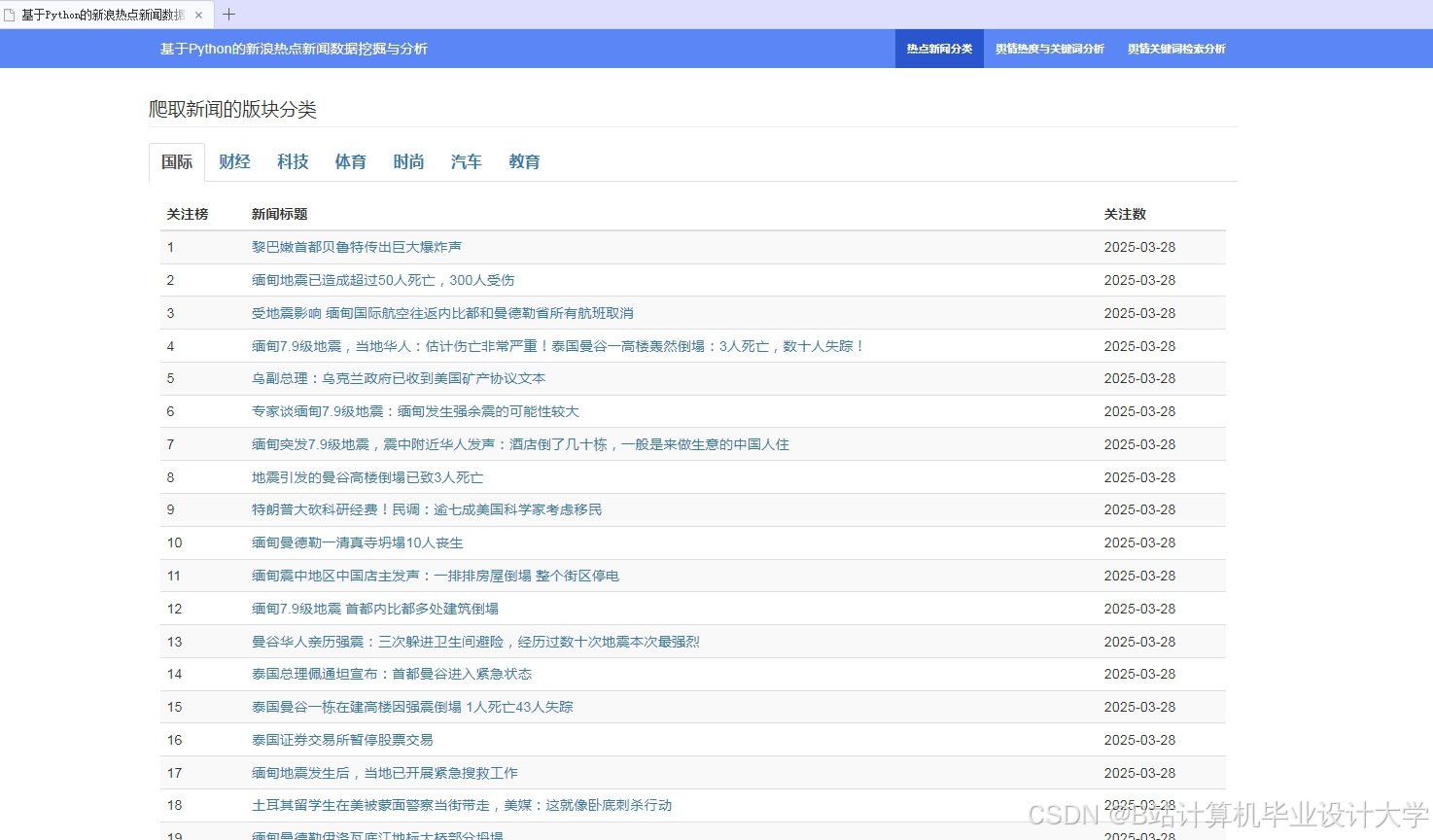
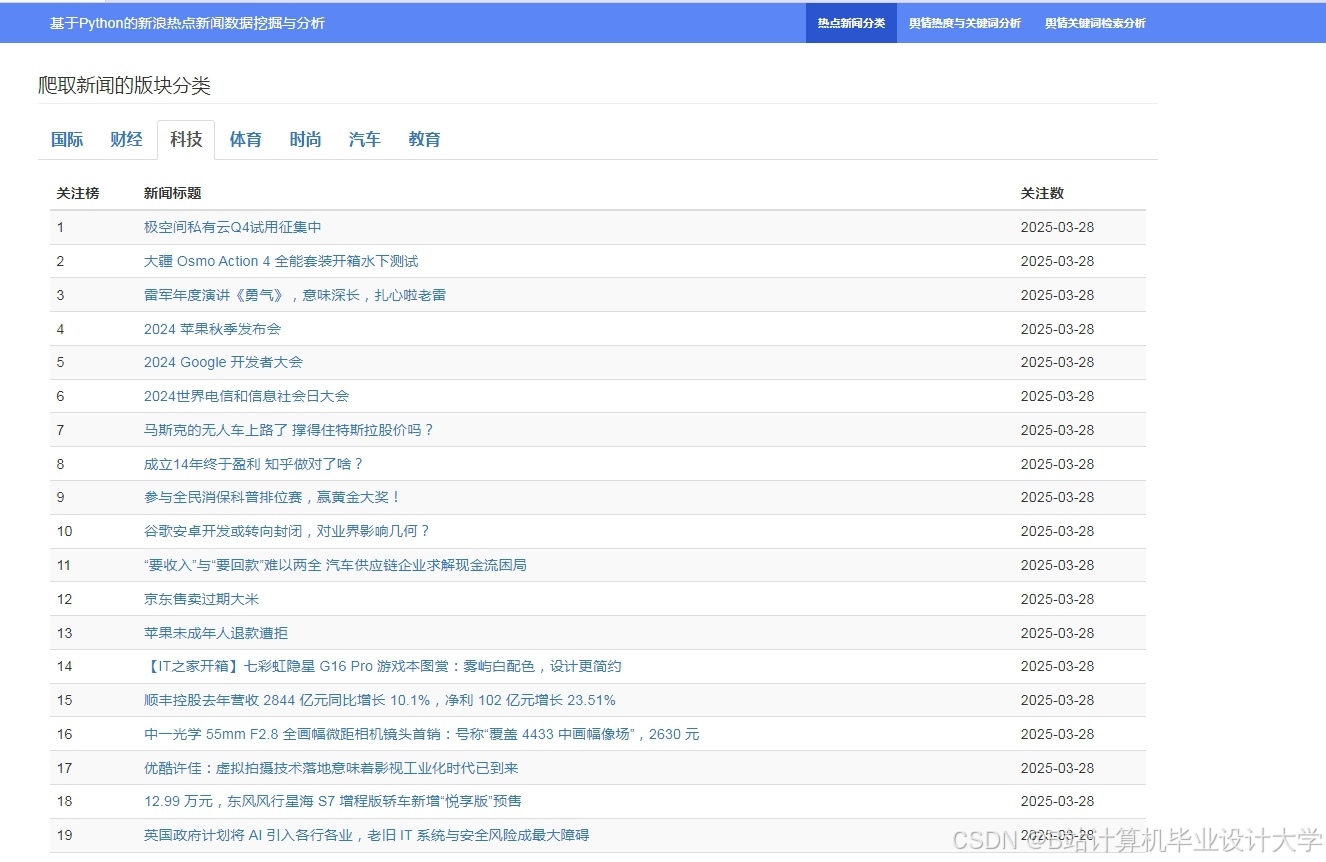
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1855
1855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











