




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
技术说明:基于Django+Vue.js的微博舆情分析系统与微博可视化实现
1. 系统概述
本系统旨在通过Django(后端)与Vue.js(前端)技术栈,构建一个集微博数据采集、情感分析、主题建模与可视化展示于一体的全栈舆情分析平台。系统核心功能包括:
- 实时数据采集:从微博API或网页抓取热门话题与用户评论。
- 情感倾向分析:判断用户对特定事件或话题的情感态度(正面/负面/中性)。
- 主题演化追踪:识别热点话题及其时间、地域分布特征。
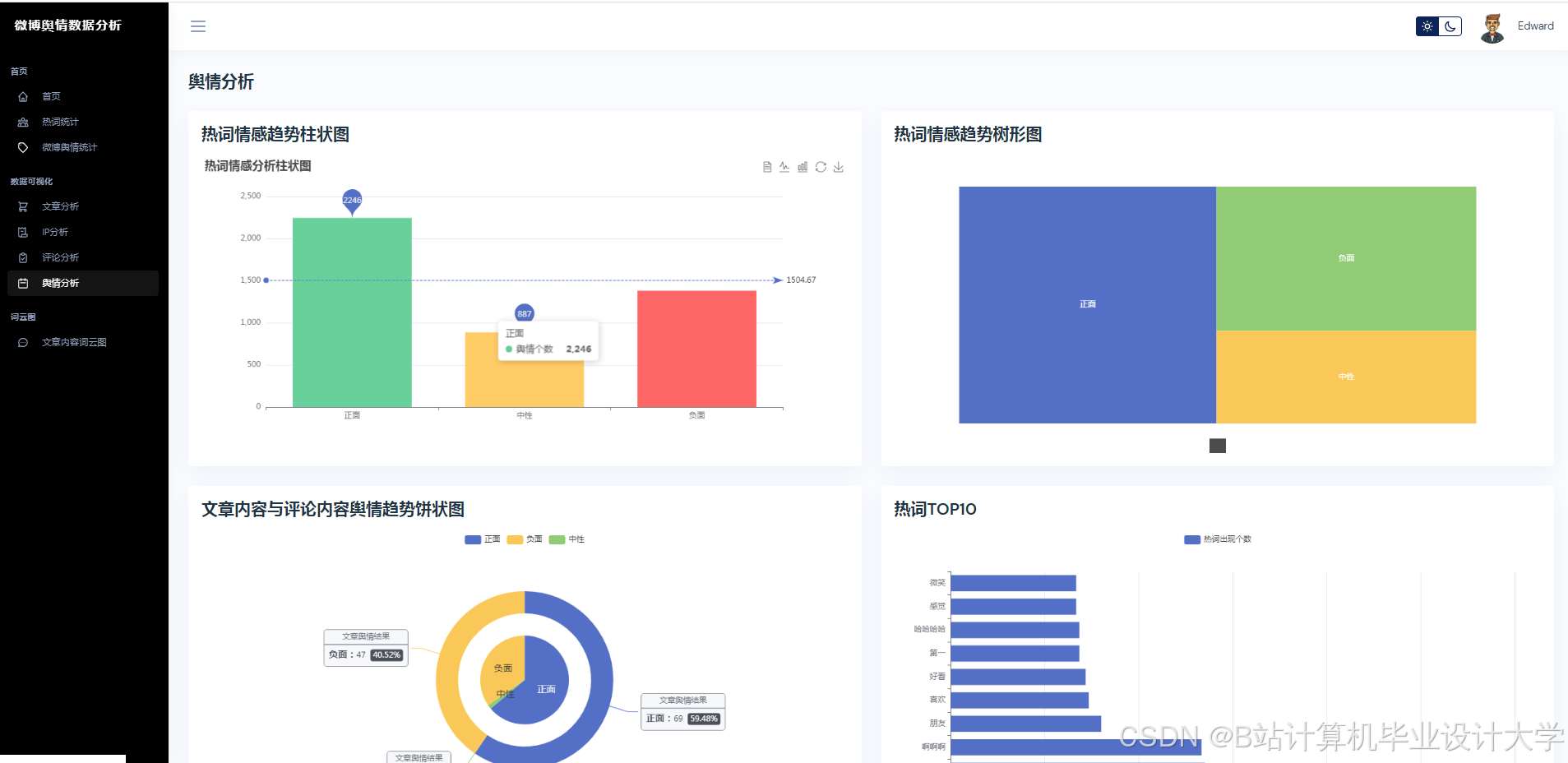
- 可视化交互:通过图表、词云、地理热力图等形式直观呈现分析结果。
2. 技术选型与架构设计
2.1 后端技术栈
- Django框架:
- 核心功能:处理业务逻辑、数据存储与API接口开发。
- 扩展工具:
- Django REST Framework(DRF):构建RESTful API,支持前端异步请求。
- Django ORM:与MySQL/PostgreSQL数据库交互,存储原始数据与分析结果。
- Celery任务队列:实现异步任务(如数据清洗、模型推理)。
- 数据采集:
- Scrapy爬虫框架:分布式抓取微博热搜、评论数据。
- 微博开放平台API:通过OAuth2.0认证获取用户授权数据。
- 情感分析模型:
- SnowNLP:基于词典的情感分析工具,适用于快速原型开发。
- BERT/RoBERTa:深度学习模型,通过迁移学习提升情感分类准确率。
2.2 前端技术栈
- Vue.js框架:
- 核心功能:构建响应式用户界面,实现前后端数据交互。
- 扩展工具:
- Vue Router:管理页面路由,支持单页应用(SPA)开发。
- Vuex:全局状态管理,共享用户认证信息与实时数据。
- 可视化组件库:
- ECharts:实现折线图、柱状图、词云等二维可视化。
- Three.js:构建三维舆情地图,展示话题传播网络与地域分布。
2.3 系统架构
系统采用前后端分离架构,数据流如下:
微博平台 → Scrapy爬虫/API → Django后端(数据存储+分析) → Vue.js前端(可视化展示) |
3. 核心功能实现
3.1 数据采集与预处理
- 爬虫实现:
- 使用Scrapy框架编写爬虫脚本,定期抓取微博热搜榜与评论数据。
- 示例代码(Python):
pythonimport scrapyfrom myproject.items import WeiboItemclass WeiboSpider(scrapy.Spider):name = 'weibo'start_urls = ['https://s.weibo.com/top/summary']def parse(self, response):for item in response.css('.td-02 a'):yield WeiboItem(title=item.css('::text').get().strip(),url=response.urljoin(item.css('::attr(href)').get()))
- 数据清洗:
- 去除HTML标签、特殊字符、重复内容。
- 使用jieba分词与SnowNLP进行中文文本预处理。
3.2 情感分析
- 基于SnowNLP的快速分析:
pythonfrom snownlp import SnowNLPtext = "这个产品真的很好用!"s = SnowNLP(text)print(s.sentiments) # 输出情感得分(0~1) - 基于BERT的深度学习模型:
- 使用Hugging Face Transformers库加载预训练模型(如
bert-base-chinese)。 - 示例代码(PyTorch):
pythonfrom transformers import BertTokenizer, BertForSequenceClassificationimport torchtokenizer = BertTokenizer.from_pretrained('bert-base-chinese')model = BertForSequenceClassification.from_pretrained('path/to/fine-tuned-model')text = "我对这次服务非常不满意。"inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)outputs = model(**inputs)sentiment = torch.argmax(outputs.logits, dim=1).item() # 0:负面, 1:正面
- 使用Hugging Face Transformers库加载预训练模型(如
3.3 可视化展示
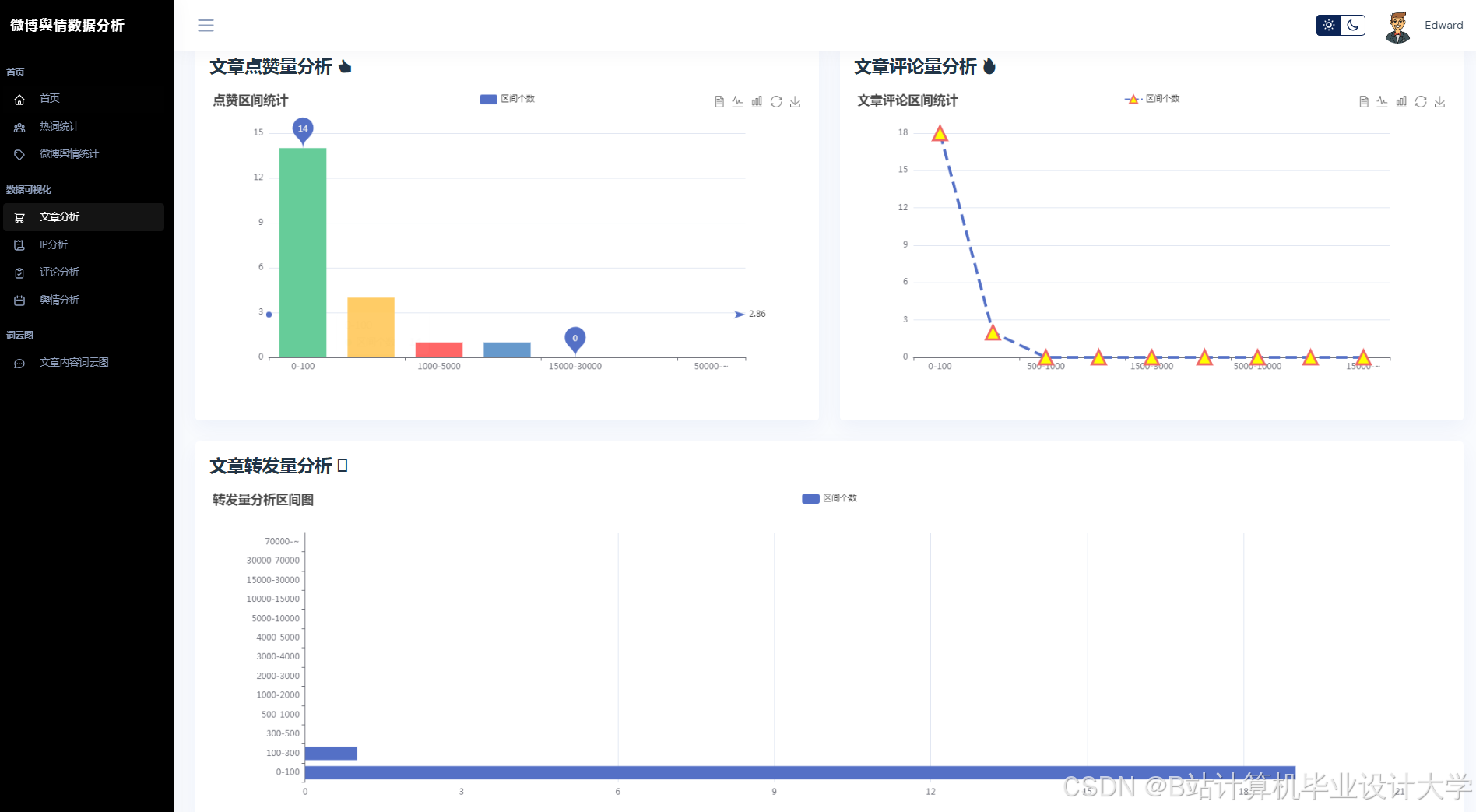
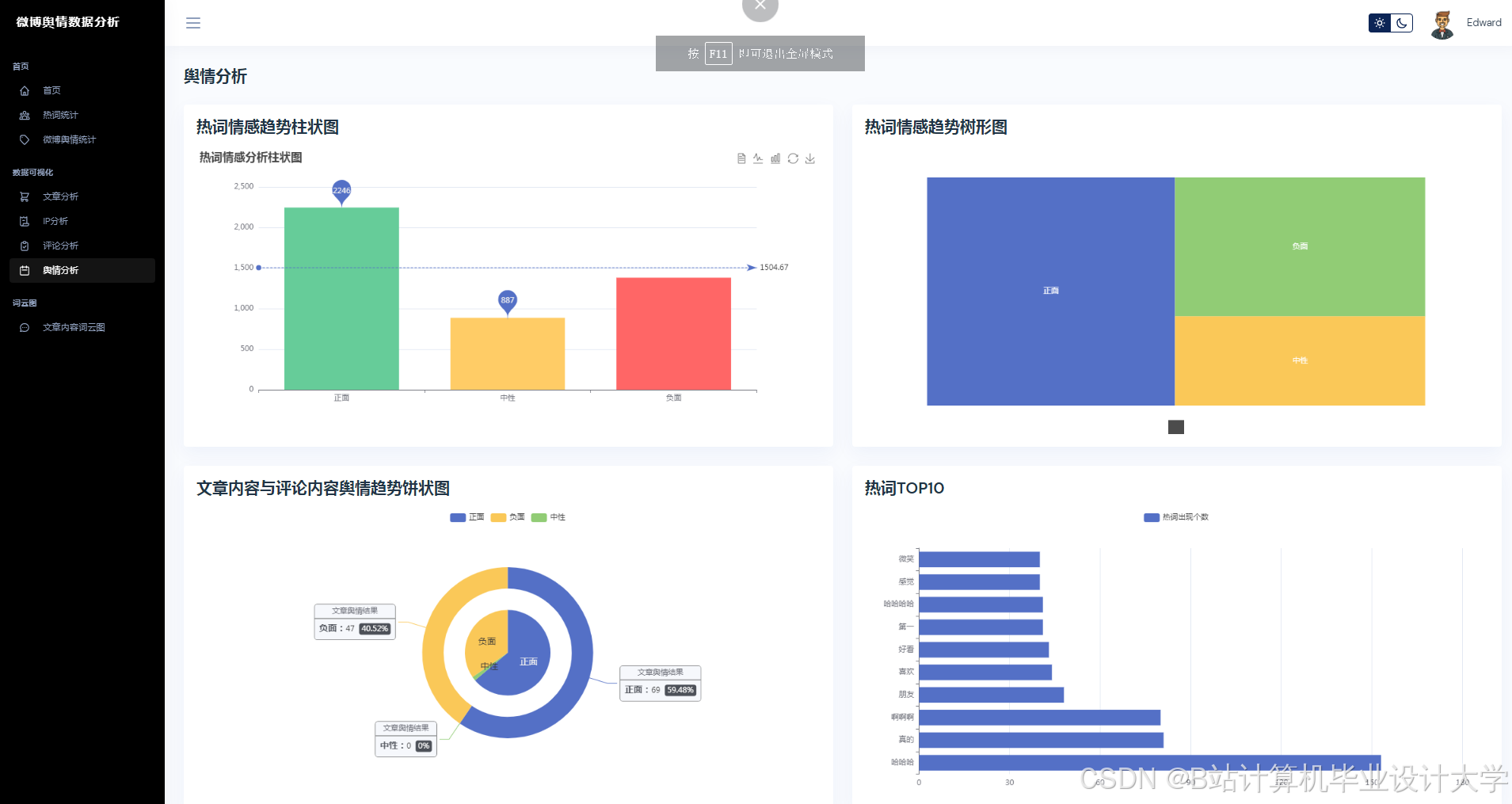
- 情感趋势图:
使用ECharts绘制时间序列图,展示情感得分随时间的变化。 - 话题传播网络:
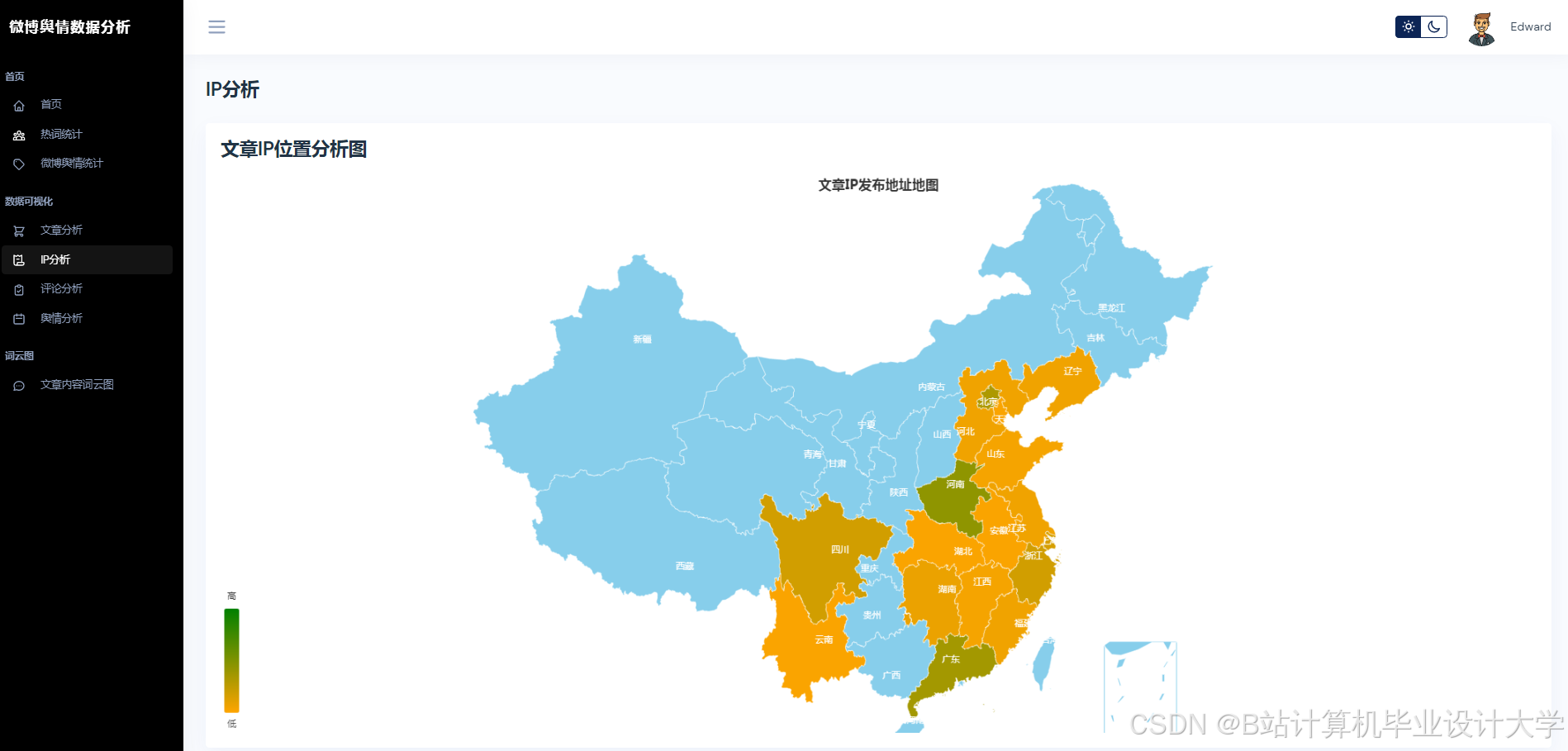
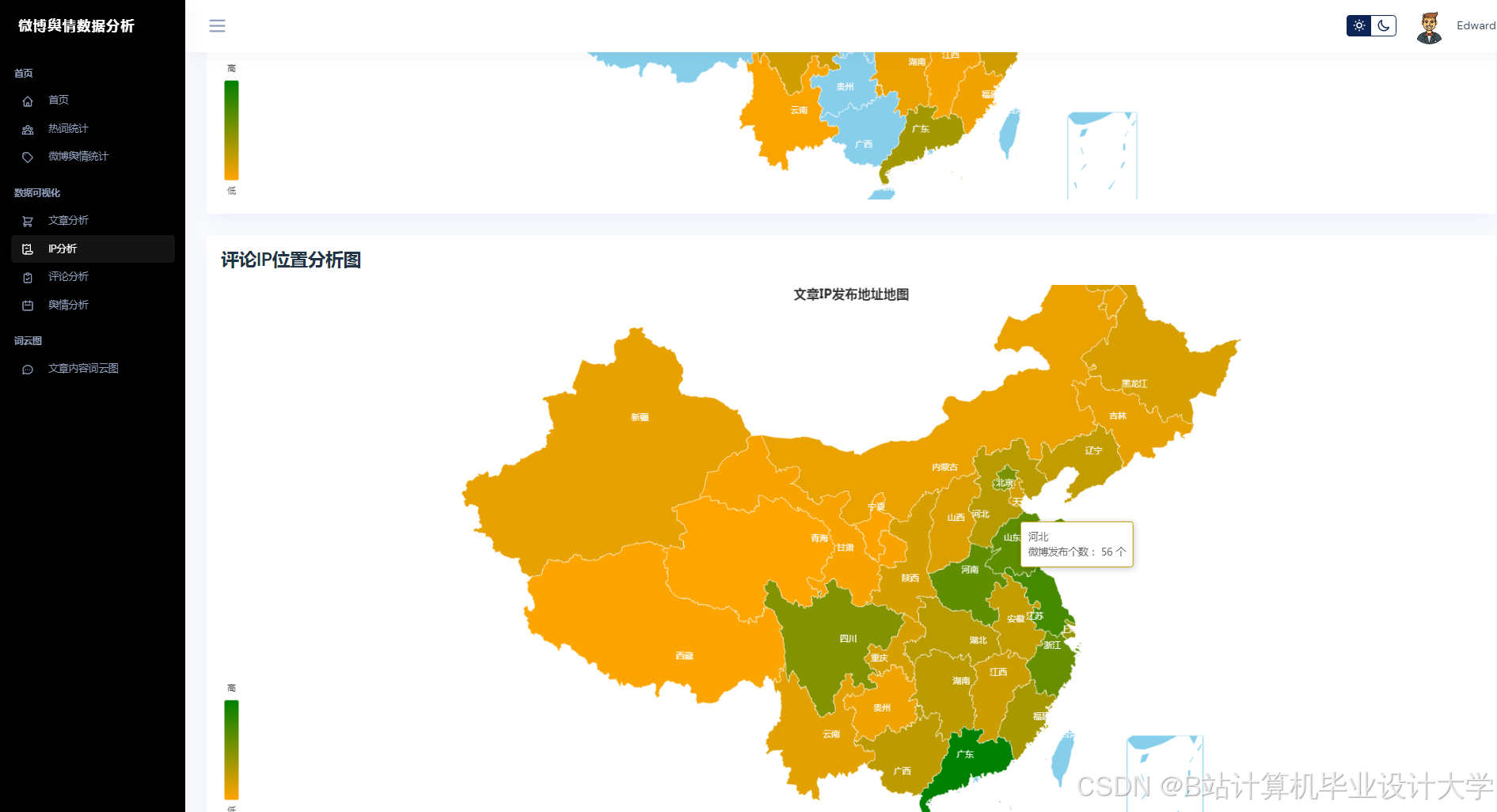
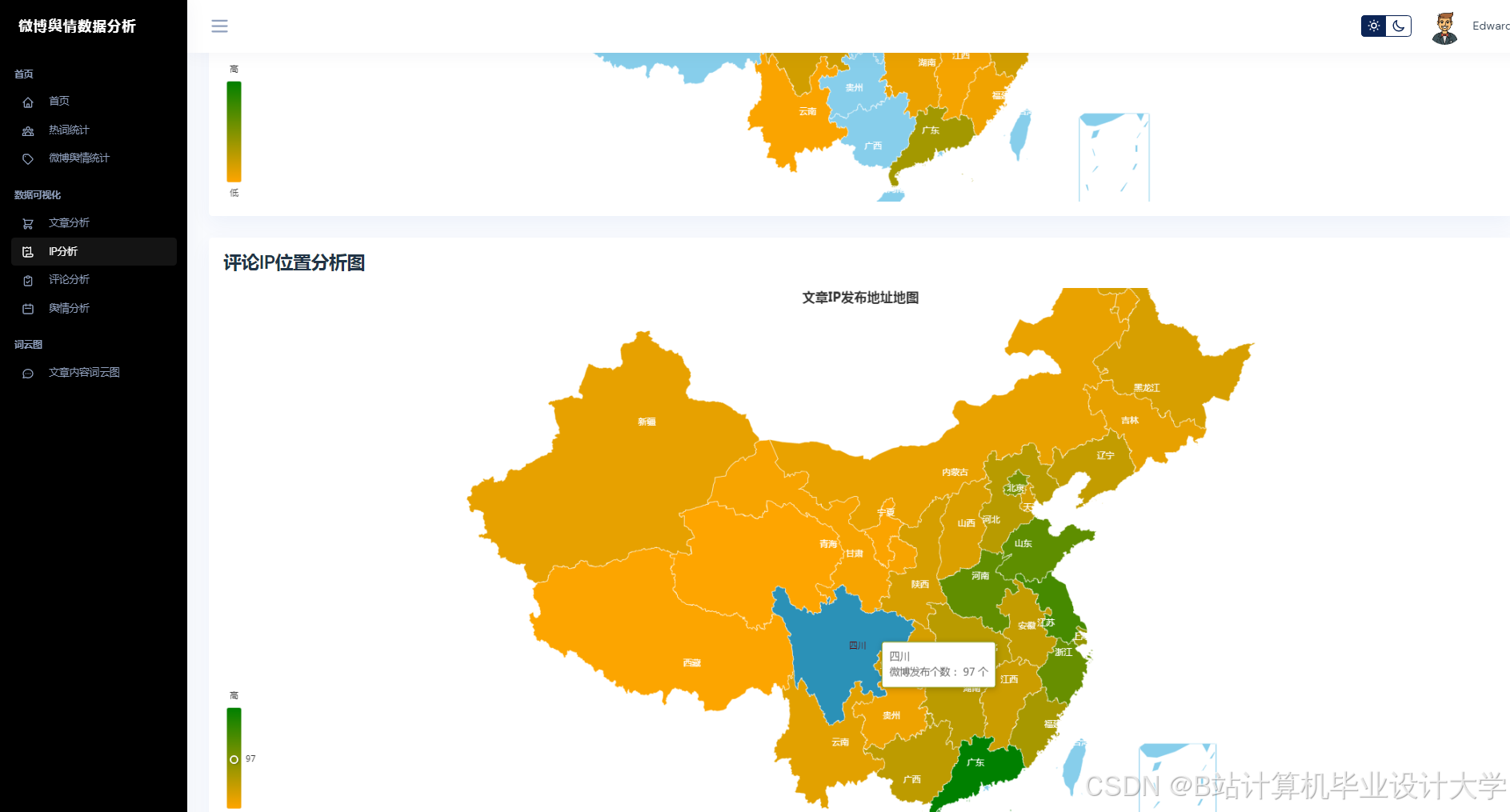
使用Three.js构建三维节点图,节点表示用户/话题,边表示互动关系。 - 地理热力图:
结合高德地图API,展示不同地区的话题热度分布。
4. 系统优化与扩展
4.1 性能优化
- 数据库优化:
- 使用索引加速查询,分表存储历史数据。
- 定期清理冗余数据,释放存储空间。
- 模型推理优化:
- 将BERT模型部署为TensorFlow Serving服务,通过gRPC实现高效推理。
- 使用ONNX格式转换模型,提升跨平台兼容性。
4.2 功能扩展
- 多模态分析:
整合微博图片与视频数据,通过图像识别(如YOLOv5)与视频摘要技术(如VGGish)提取多模态特征。 - 知识图谱:
构建舆情知识图谱,实现事件关联分析与因果推理。 - 实时预警:
通过WebSocket推送负面舆情预警,支持邮件/短信通知。
5. 部署与运维
- 容器化部署:
使用Docker打包Django后端与Vue.js前端,通过Kubernetes实现弹性扩展。 - 日志监控:
集成ELK Stack(Elasticsearch+Logstash+Kibana),实时监控系统运行状态。 - 安全加固:
- 使用JWT进行用户认证,防止CSRF攻击。
- 对敏感数据(如用户信息)进行加密存储。
6. 总结
本系统通过Django+Vue.js技术栈,实现了微博舆情数据的全流程分析,具备高扩展性与可视化交互能力。未来可进一步融合多模态数据与知识图谱技术,提升舆情分析的智能化水平。
技术文档版本:1.0
作者:XXX
日期:2025年4月19日
运行截图





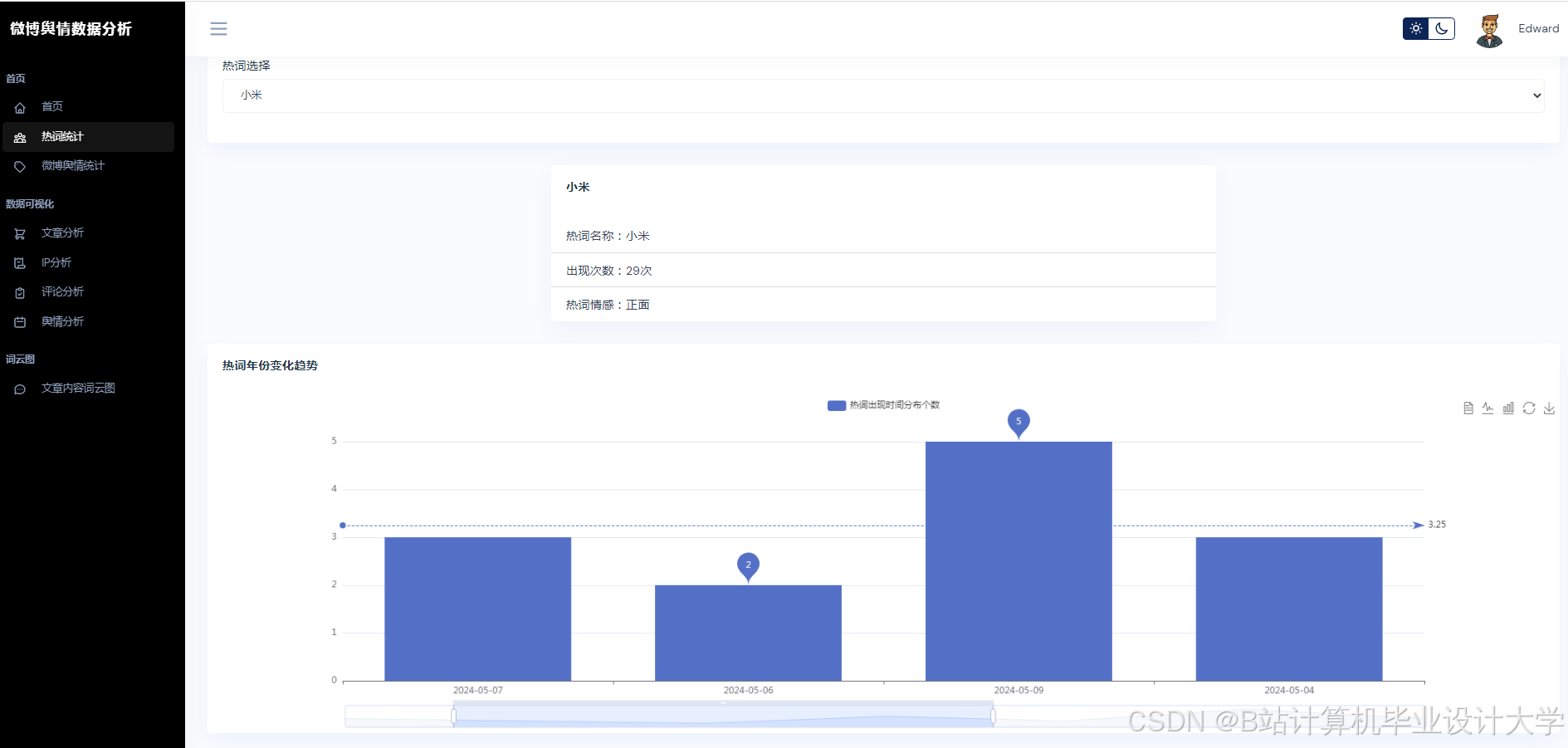
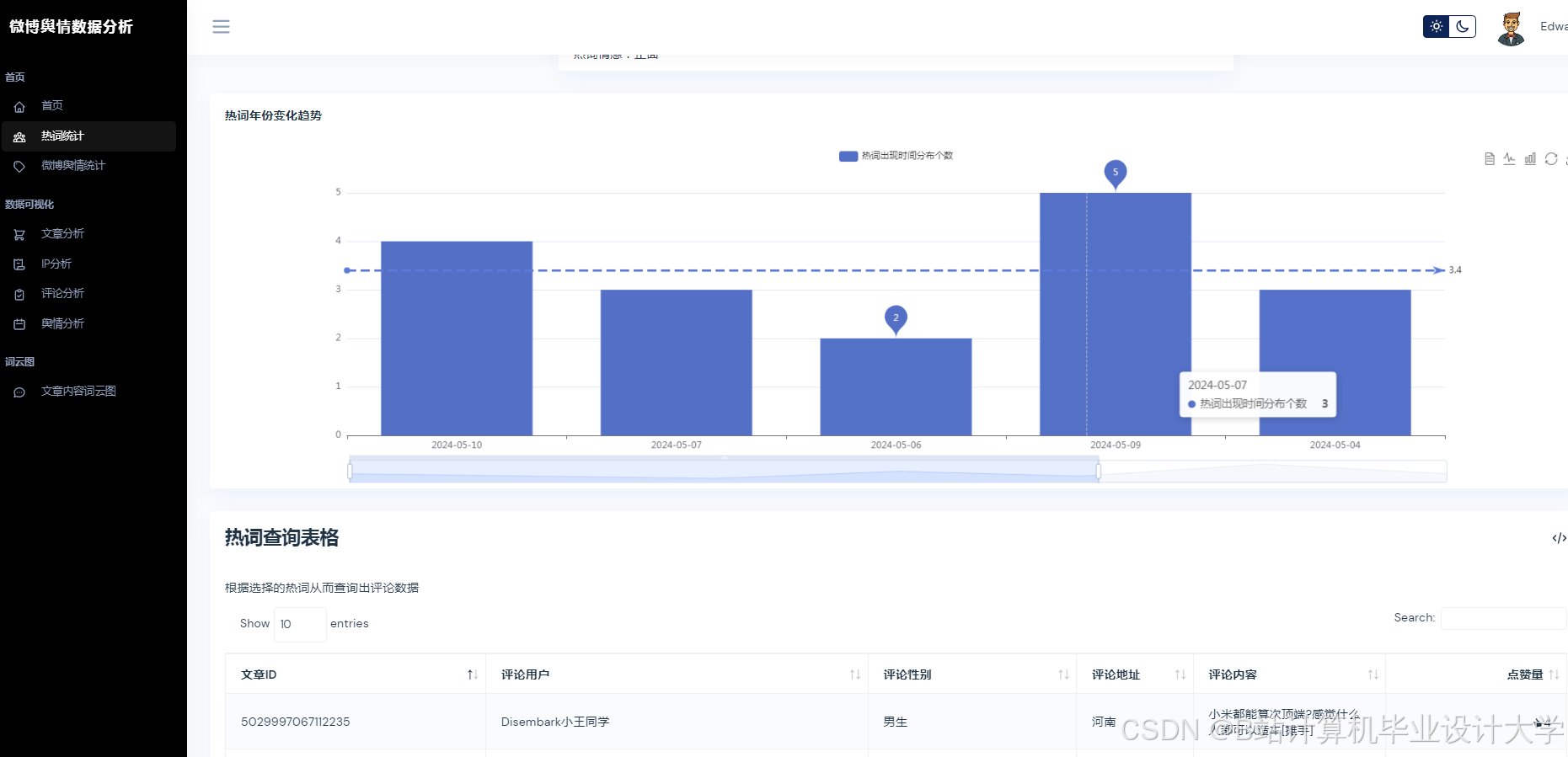




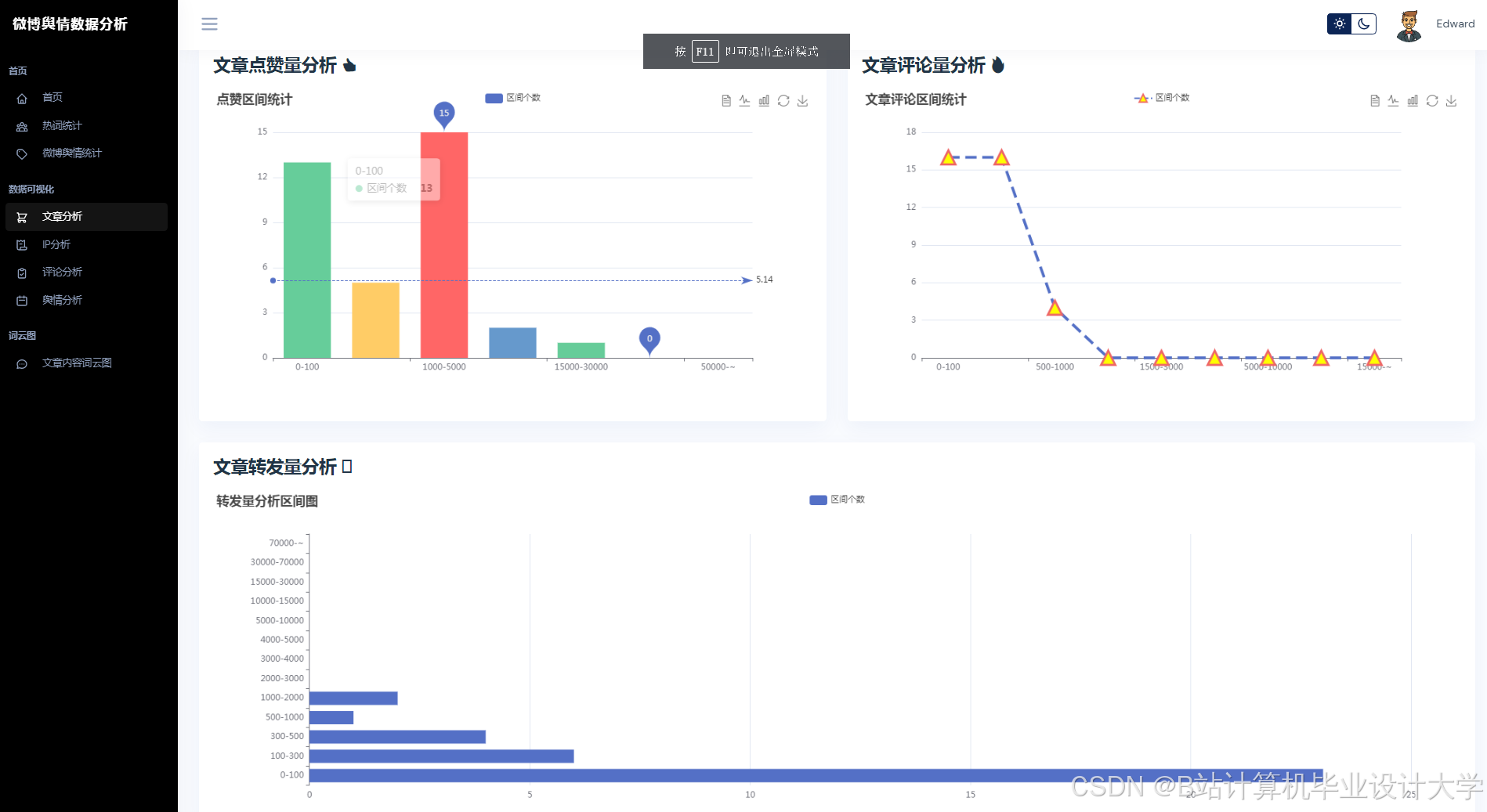
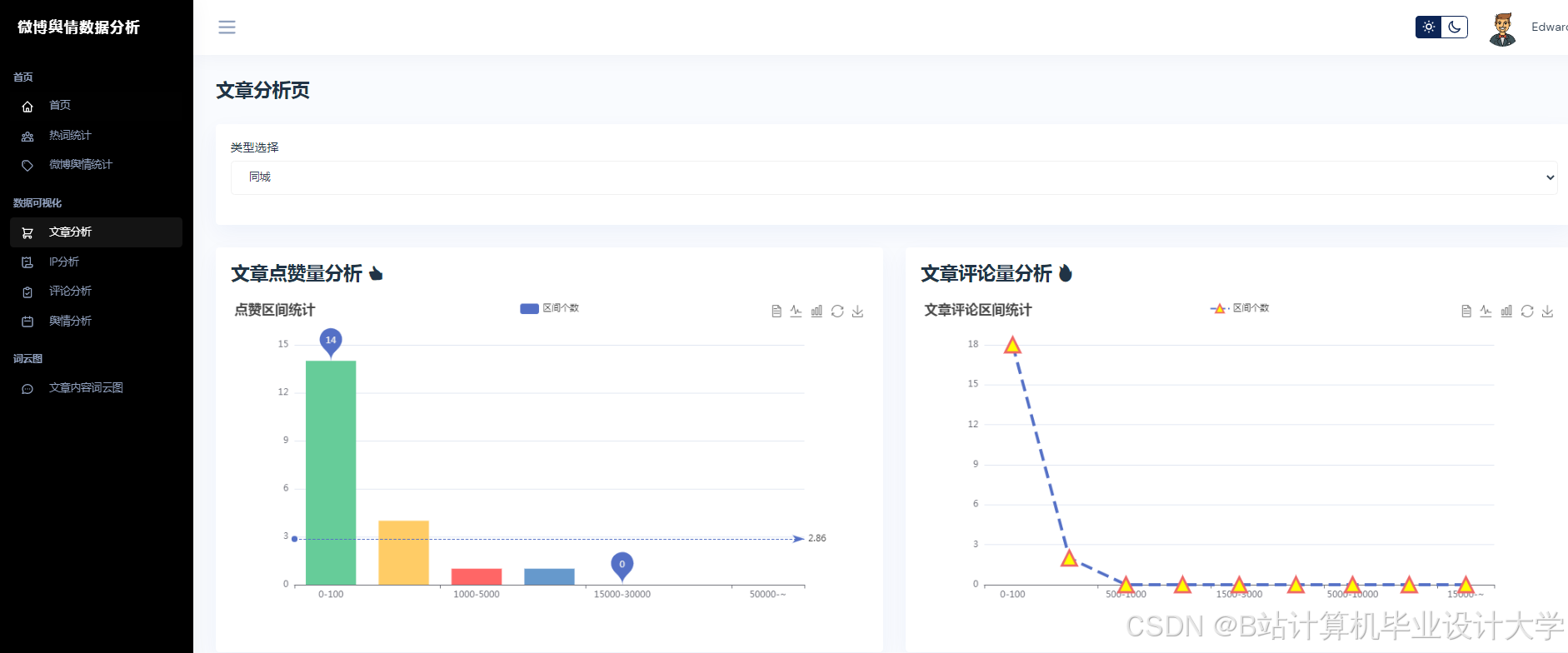

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











