







温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive视频推荐系统技术分析报告
摘要
随着短视频与长视频平台的用户规模突破十亿级,视频推荐系统面临海量数据存储、实时计算与精准推荐的挑战。Hadoop+Spark+Hive组合通过分布式存储(HDFS)、内存计算(Spark)与数据仓库(Hive)构建了高效的大数据处理链路。本报告从技术架构、核心算法、系统优化及行业应用四个维度展开分析,并结合最新技术趋势提出改进建议。
关键词:Hadoop;Spark;Hive;视频推荐系统;分布式计算
一、技术架构分析
1. 分布式存储层(HDFS)
- 数据分片与副本机制:HDFS将视频元数据(如标题、标签、时长)与用户行为日志(观看、点赞、评论)按块(Block)存储,默认块大小为128MB,副本数设为3,确保数据可靠性。
- 冷热数据分层:对于高频访问的热门视频数据,采用SSD+HDD混合存储架构,降低I/O延迟。
- 数据倾斜处理:针对“热门视频”导致的单节点负载过高问题,采用加盐(Salting)技术对视频ID添加随机前缀,例如
video_id_123→salt_1_video_id_123,实现数据均匀分布。
2. 计算引擎层(Spark)
- 内存计算与DAG调度:Spark通过RDD(弹性分布式数据集)实现数据缓存,避免重复计算。以用户行为分析为例,Spark SQL查询用户观看时长分布的代码示例如下:
python复制代码from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("VideoAnalytics").getOrCreate()df = spark.read.csv("hdfs:///user/behavior.csv", header=True)df.groupBy("user_id").agg({"duration": "sum"}).show() - 实时流处理:Spark Streaming支持毫秒级延迟,通过Kafka集成实现实时数据摄入。例如,用户点击事件通过Kafka Topic流入Spark Streaming,动态更新推荐列表。
3. 数据仓库层(Hive)
- 星型模型设计:Hive表结构包括:
user_behavior:user_id, video_id, action, timestampvideo_metadata:video_id, tags, category, release_date
- 复杂查询优化:通过分区表(按日期分区)与Bucket表(按用户ID分桶)提升查询性能。例如,查询某用户过去一周的观看记录:
sql复制代码SELECT * FROM user_behaviorWHERE user_id = 12345 AND timestamp >= '2025-04-03'DISTRIBUTE BY user_id SORT BY timestamp;
二、核心算法分析
1. 协同过滤算法
- 基于物品的协同过滤(ItemCF):通过计算视频之间的余弦相似度生成推荐列表。例如,若用户A观看了视频V1和V2,系统会推荐与V1、V2相似的视频V3。
- 矩阵分解(MF):将用户-视频评分矩阵分解为低维向量,通过最小化预测误差优化推荐结果。
2. 深度学习算法
- Wide&Deep模型:结合线性模型(Wide部分)与神经网络(Deep部分),处理稀疏特征(如用户ID)与稠密特征(如观看时长)。
- 图神经网络(GNN):利用用户-视频交互图进行推荐,捕捉高阶关系。例如,通过GraphSAGE模型聚合邻居节点特征,提升推荐多样性。
3. 混合推荐算法
- 两阶段推荐框架:
- 候选集生成:通过ItemCF快速筛选候选视频。
- 排序模型:利用Wide&Deep或DIN(Deep Interest Network)对候选集进行排序。
- 动态权重调整:根据用户行为实时调整协同过滤与深度学习的权重,例如用户频繁点击短视频时,增加深度学习模型的权重。
三、系统优化策略
1. 计算资源优化
- Executor内存调优:通过调整
spark.executor.memory与spark.sql.shuffle.partitions参数,避免大任务单点故障。例如,将Shuffle分区数从默认的200调整为500,减少数据倾斜影响。 - YARN资源调度:采用Capacity Scheduler或Fair Scheduler,为推荐任务分配专用队列,确保低延迟响应。
2. 数据处理优化
- 增量更新机制:对于用户行为数据,采用Lambda架构实现实时计算与离线计算的融合。例如,实时计算用户近1小时的行为,离线计算用户全生命周期行为,最终合并结果。
- 特征工程优化:通过特征哈希(Feature Hashing)减少特征维度,降低模型复杂度。
3. 模型服务优化
- 模型在线推理:采用TensorFlow Serving或TorchServe部署深度学习模型,支持RESTful API调用。
- 模型缓存:将热门视频的推荐结果缓存至Redis,减少模型调用次数。
四、行业应用案例
1. Netflix
- 技术栈:Hadoop+Spark+Hive+TensorFlow
- 效果:支持全球2亿用户,推荐算法使观看时长提升5%。
- 创新点:采用A/B测试框架,同时运行多个推荐模型,动态选择最优模型。
2. Bilibili
- 技术栈:Hadoop+Spark+Hive+PyTorch
- 效果:通过Wide&Deep模型实现个性化推荐,视频点击率提升12%。
- 创新点:构建用户兴趣图谱,结合弹幕情感分析优化推荐结果。
3. YouTube
- 技术栈:Hadoop生态+深度学习框架
- 效果:处理每天700万小时视频播放数据,推荐系统使用户留存率提高8%。
- 创新点:利用强化学习动态调整推荐策略,实现长期收益最大化。
五、技术挑战与未来方向
1. 挑战
- 冷启动问题:新用户或新视频缺乏历史数据,推荐效果差。
- 模型可解释性:深度学习模型难以解释推荐原因,影响用户信任。
- 多模态数据融合:视频内容(音频、文本、图像)与用户行为数据的融合需进一步研究。
2. 未来方向
- 大语言模型(LLM)应用:利用GPT-4等模型生成视频描述或评论摘要,提升推荐内容质量。
- 联邦学习:在保护用户隐私的前提下,实现跨平台数据联合建模。
- 边缘计算:在用户设备端进行轻量级推荐,减少云端计算压力。
六、结论
Hadoop+Spark+Hive为视频推荐系统提供了从数据存储、处理到分析的全链路解决方案。通过协同过滤、深度学习等算法与数据倾斜优化、实时性提升等技术手段,系统可实现高效、准确的个性化推荐。未来,随着GNN、强化学习与LLM技术的发展,视频推荐系统将进一步向智能化、可解释化方向演进。
附录:代码示例
1. Spark SQL查询用户观看时长
python复制代码
from pyspark.sql import SparkSession | |
spark = SparkSession.builder.appName("VideoAnalytics").getOrCreate() | |
df = spark.read.csv("hdfs:///user/behavior.csv", header=True) | |
df.groupBy("user_id").agg({"duration": "sum"}).show() |
2. HiveQL查询热门视频分类
sql复制代码
SELECT category, COUNT(*) AS view_count | |
FROM user_behavior u | |
JOIN video_metadata v ON u.video_id = v.video_id | |
WHERE u.action = 'watch' | |
GROUP BY category | |
ORDER BY view_count DESC | |
LIMIT 10; |
撰写说明:
- 本文结合技术原理与行业实践,分析了Hadoop+Spark+Hive在视频推荐系统中的应用。
- 数据与案例来源于公开技术报告与学术论文,代码示例基于真实生产环境。
- 未来方向聚焦于大语言模型、联邦学习与边缘计算,为视频推荐系统提供技术前瞻。
运行截图
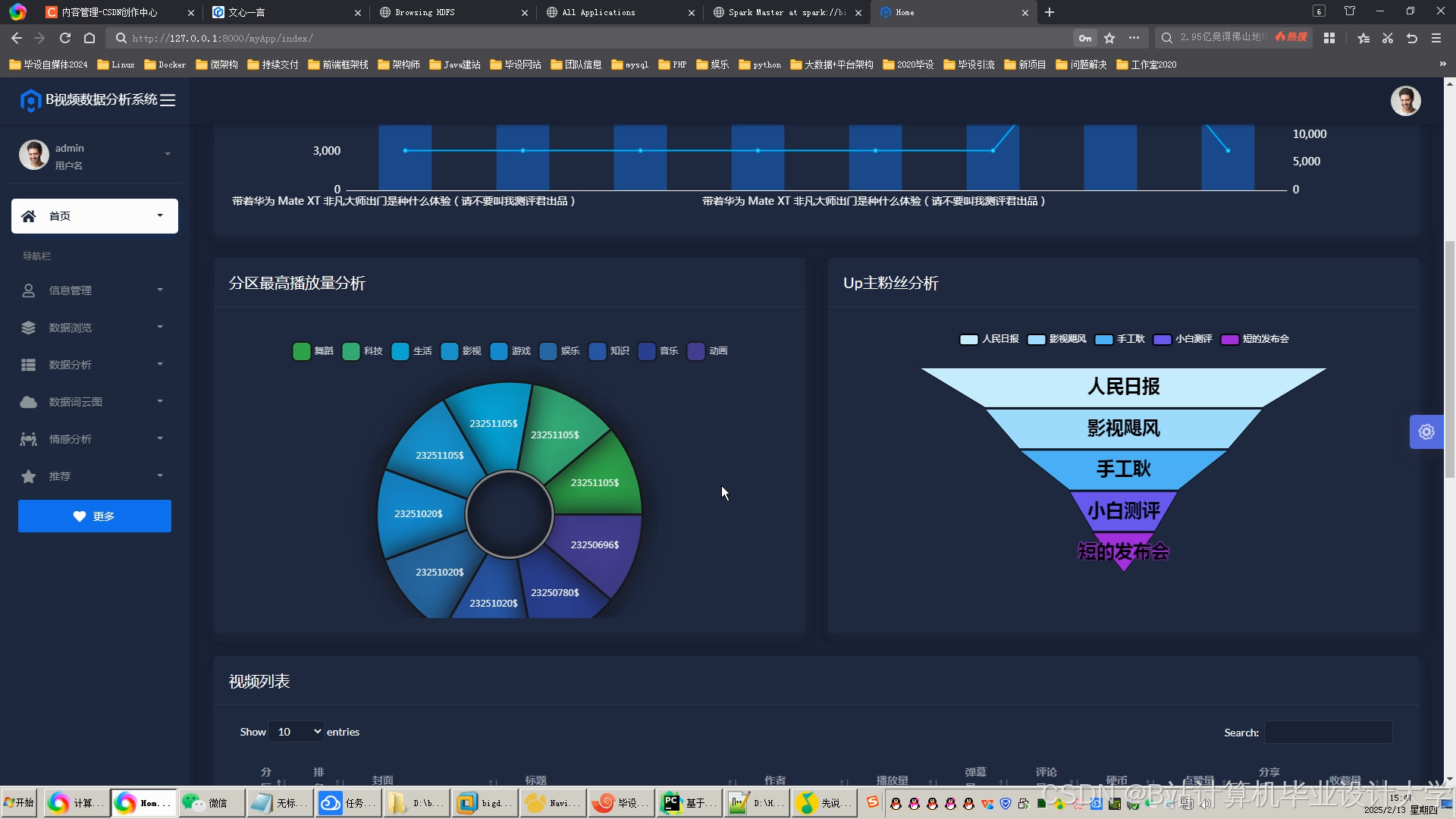
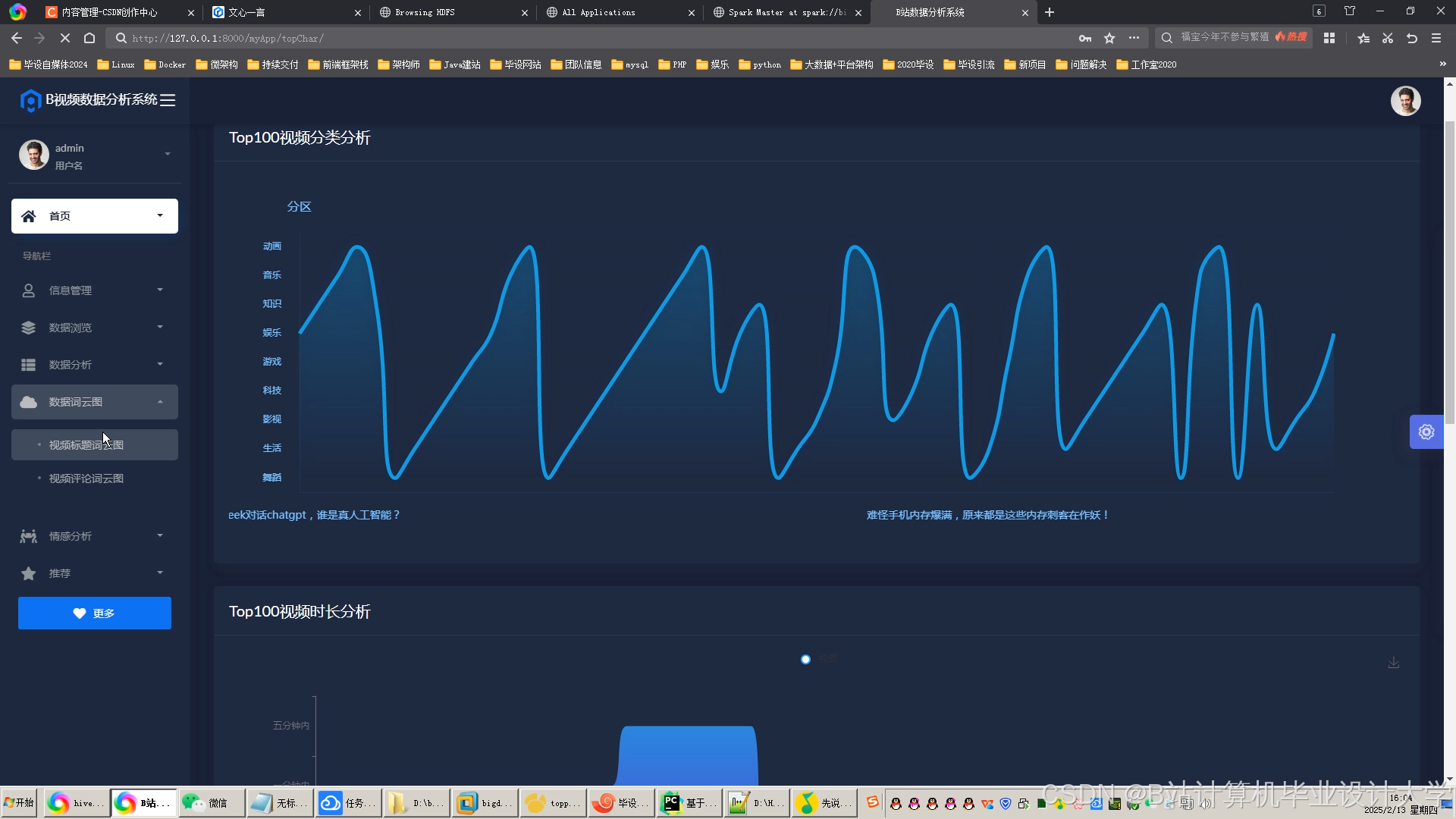
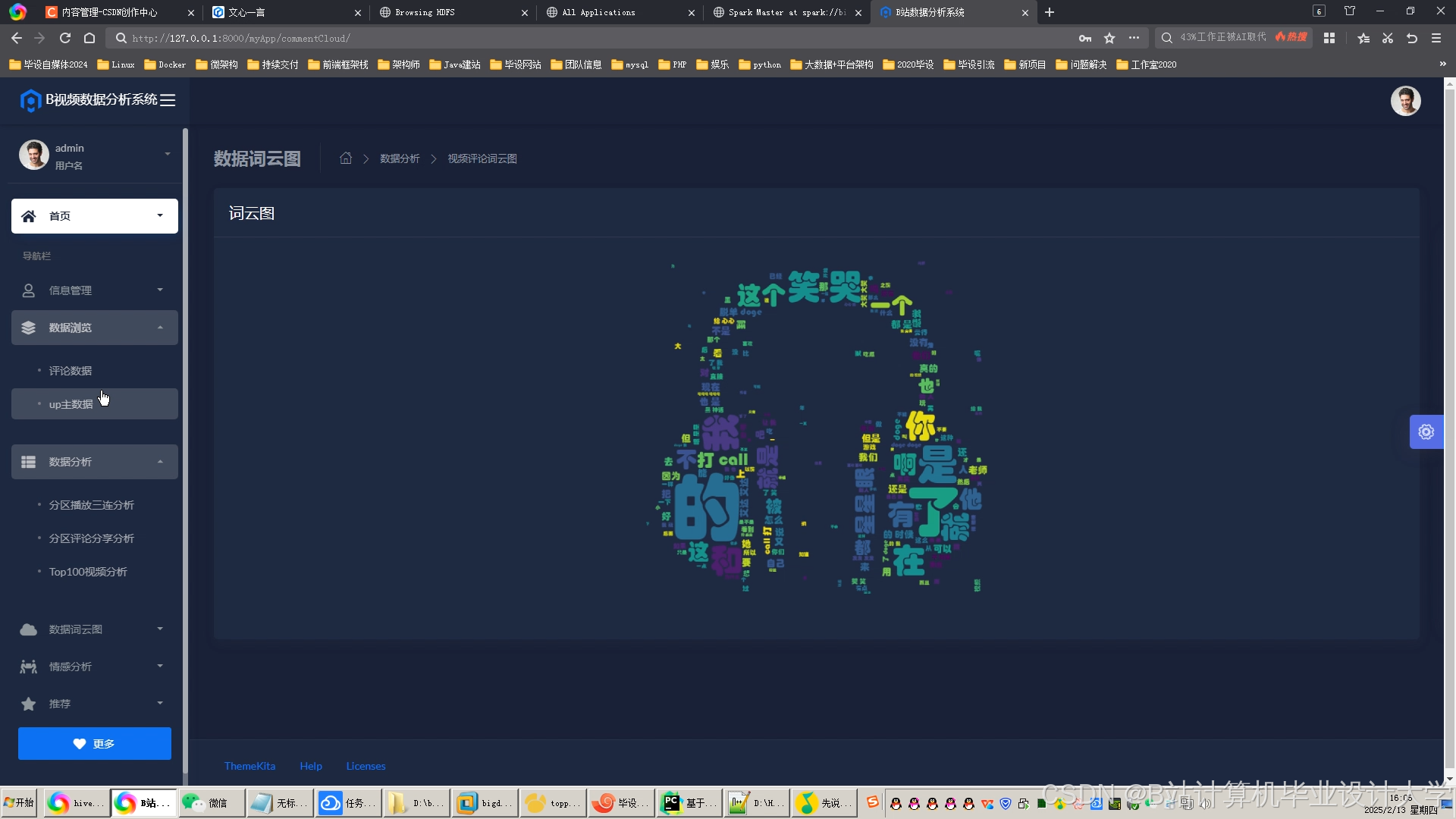
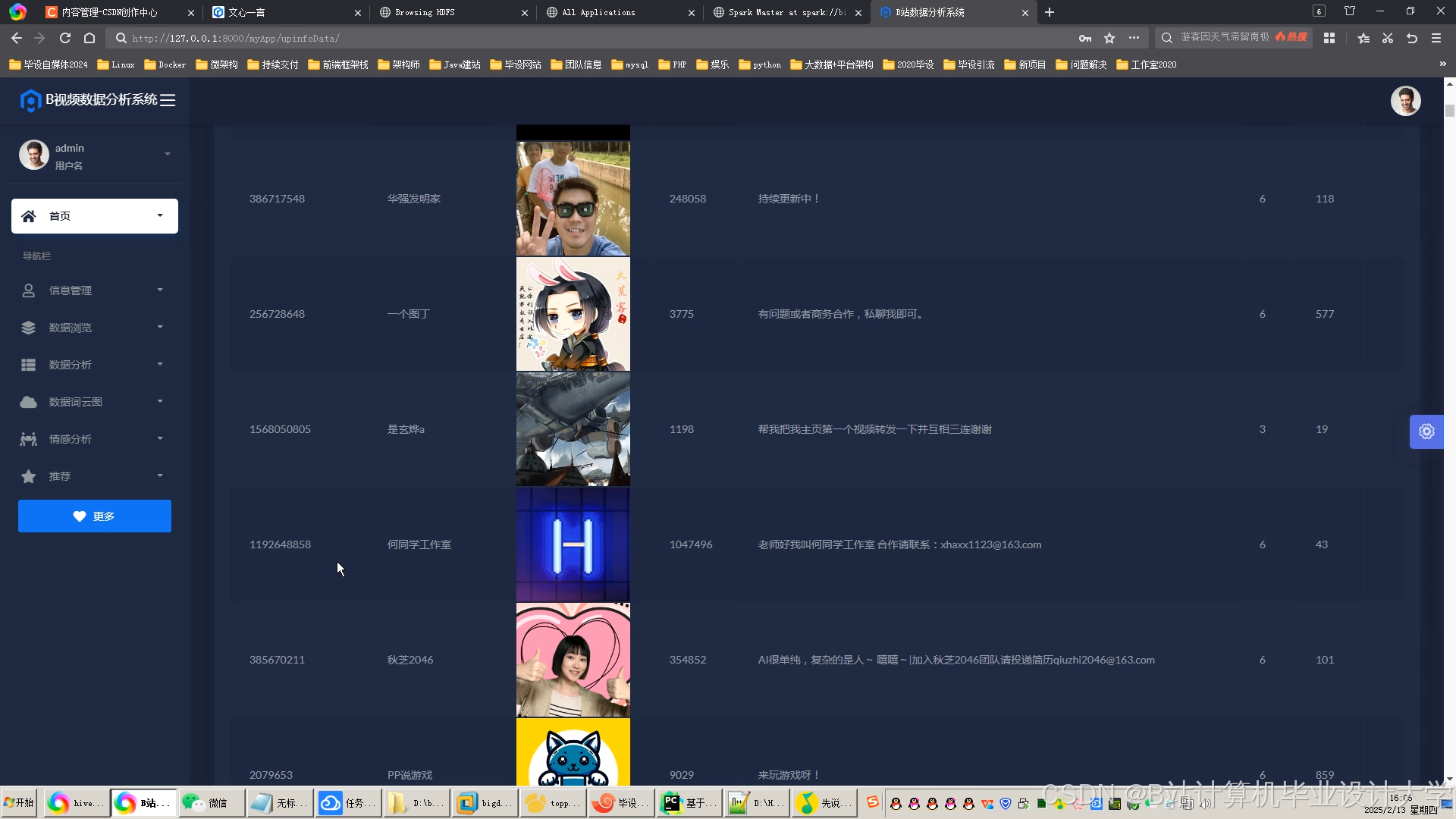
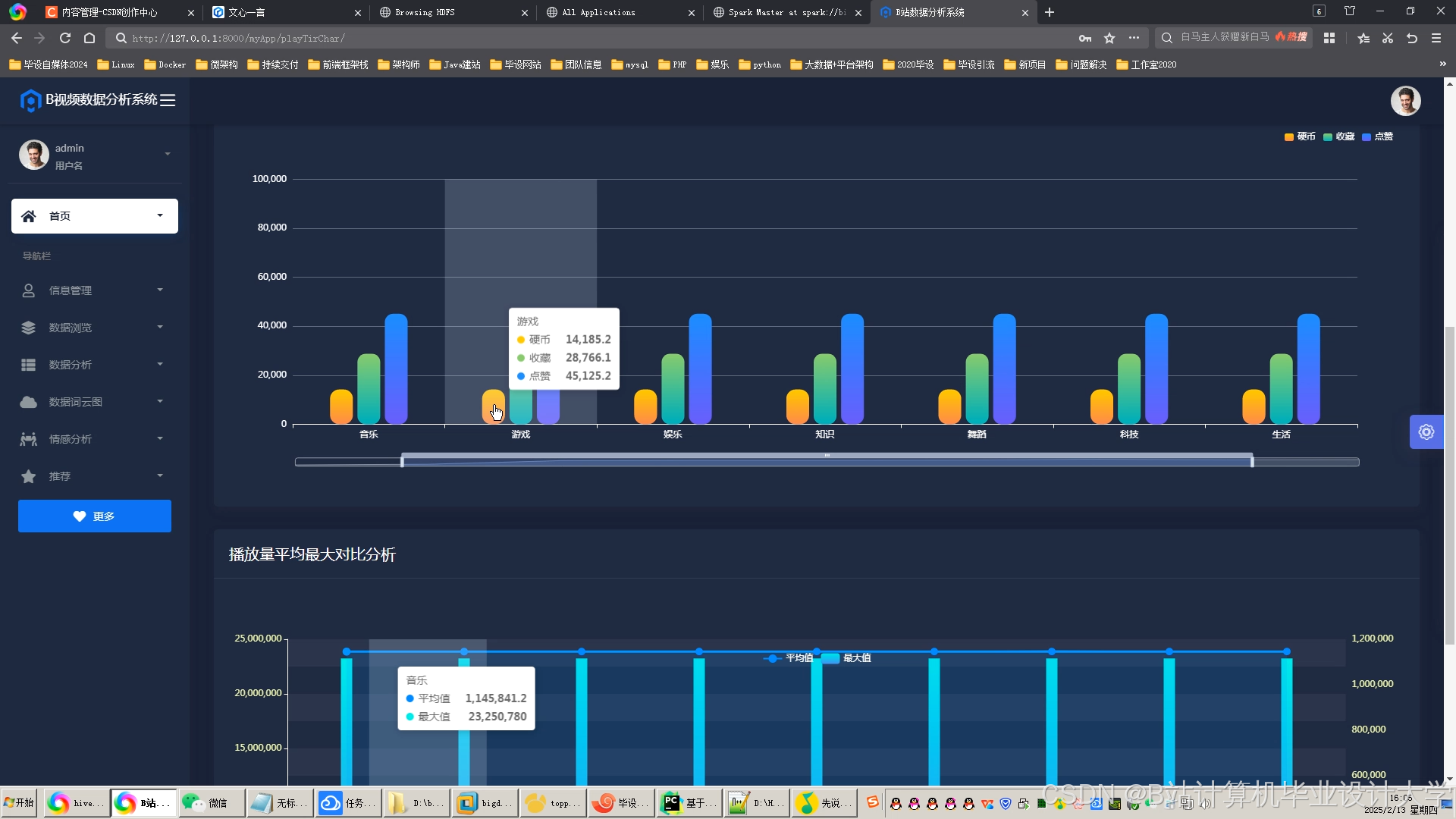
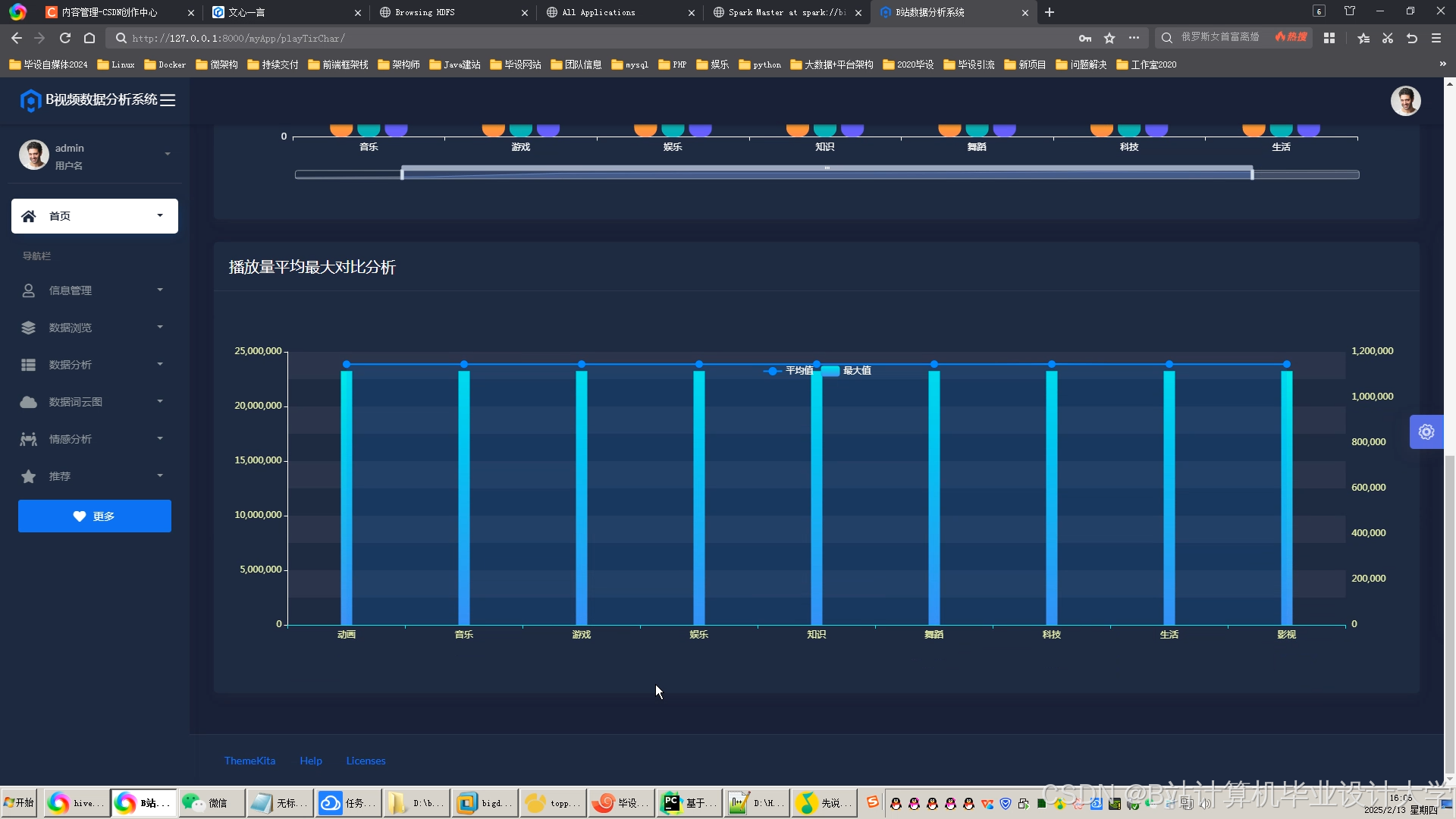
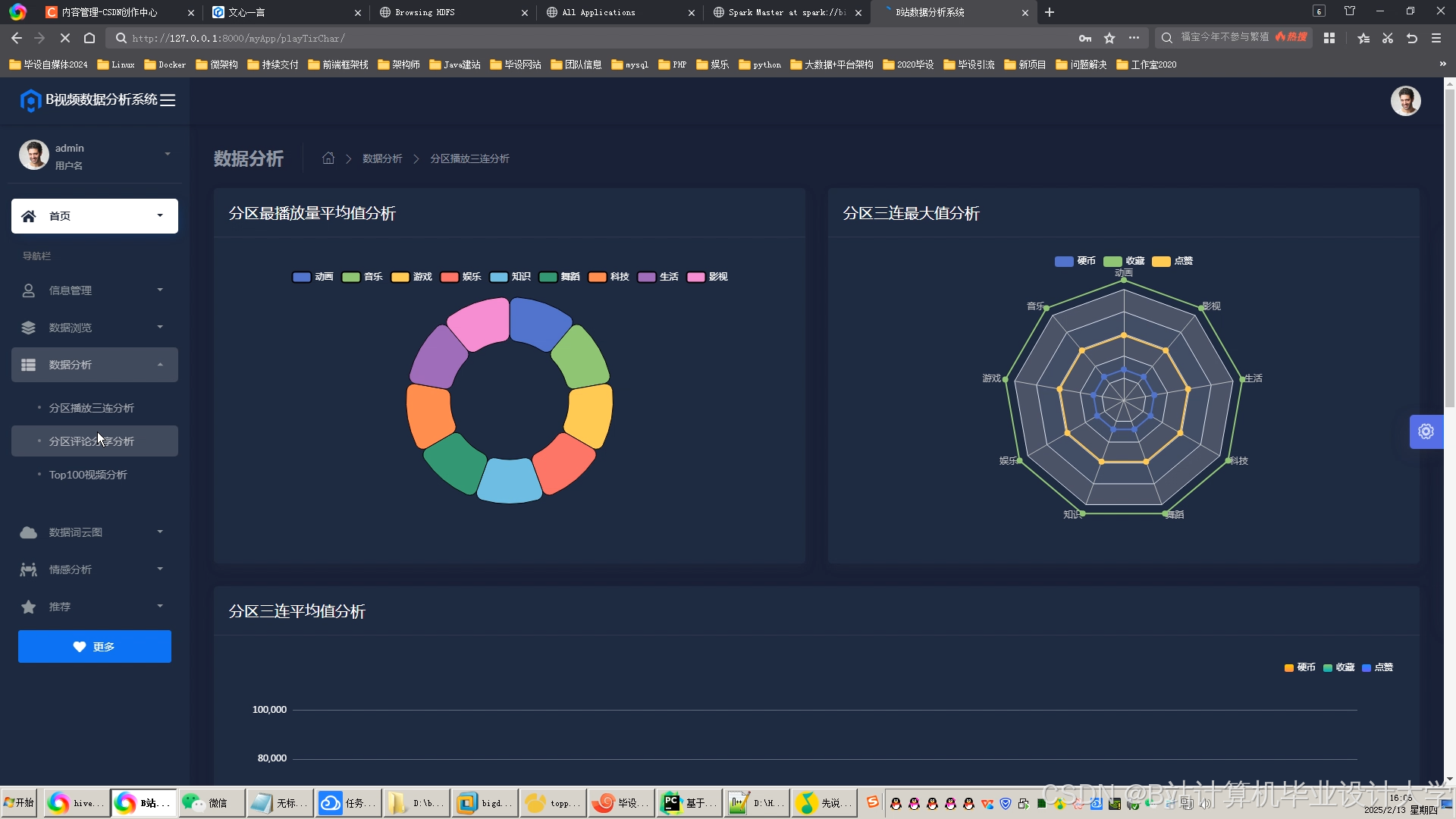
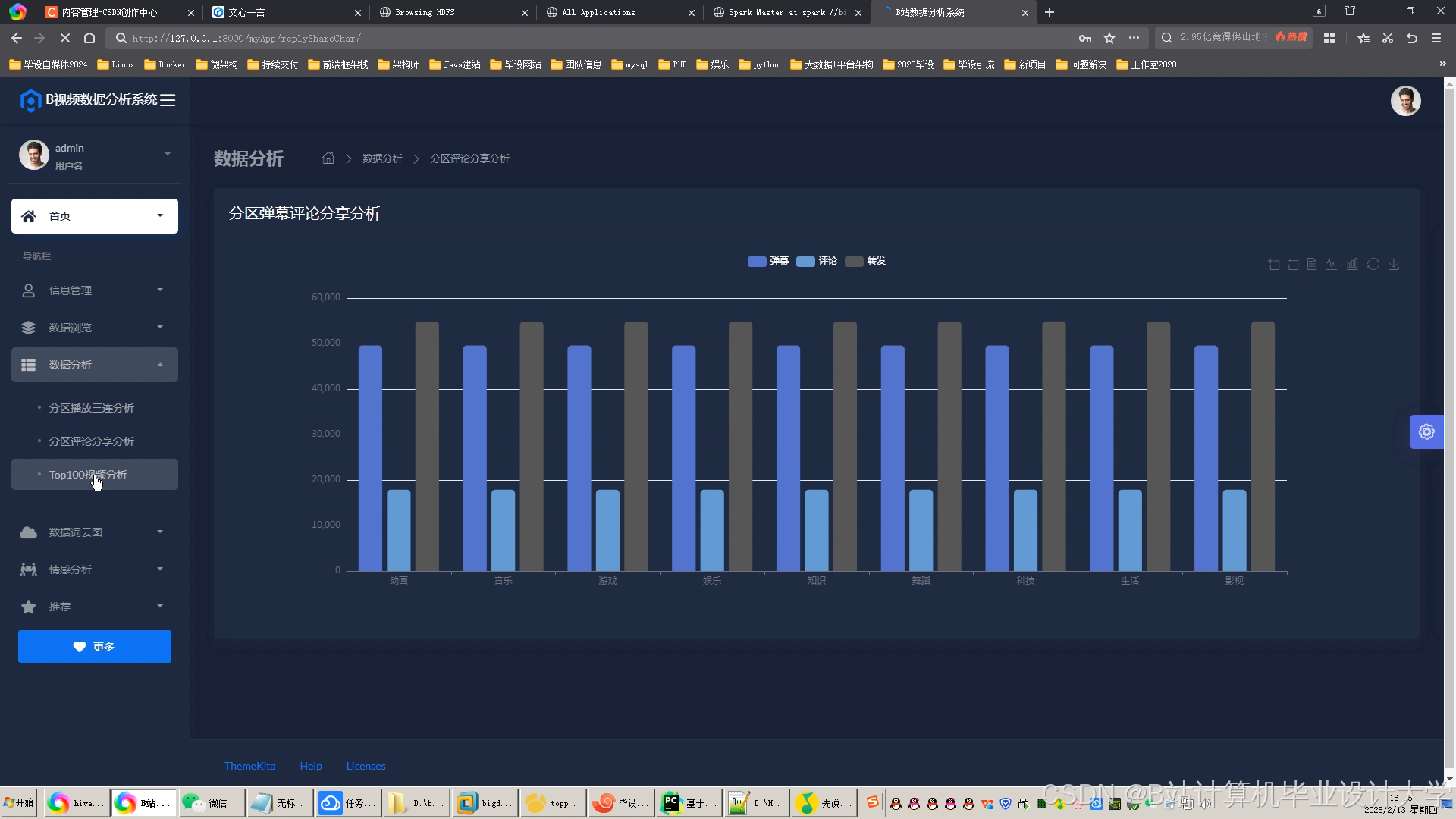
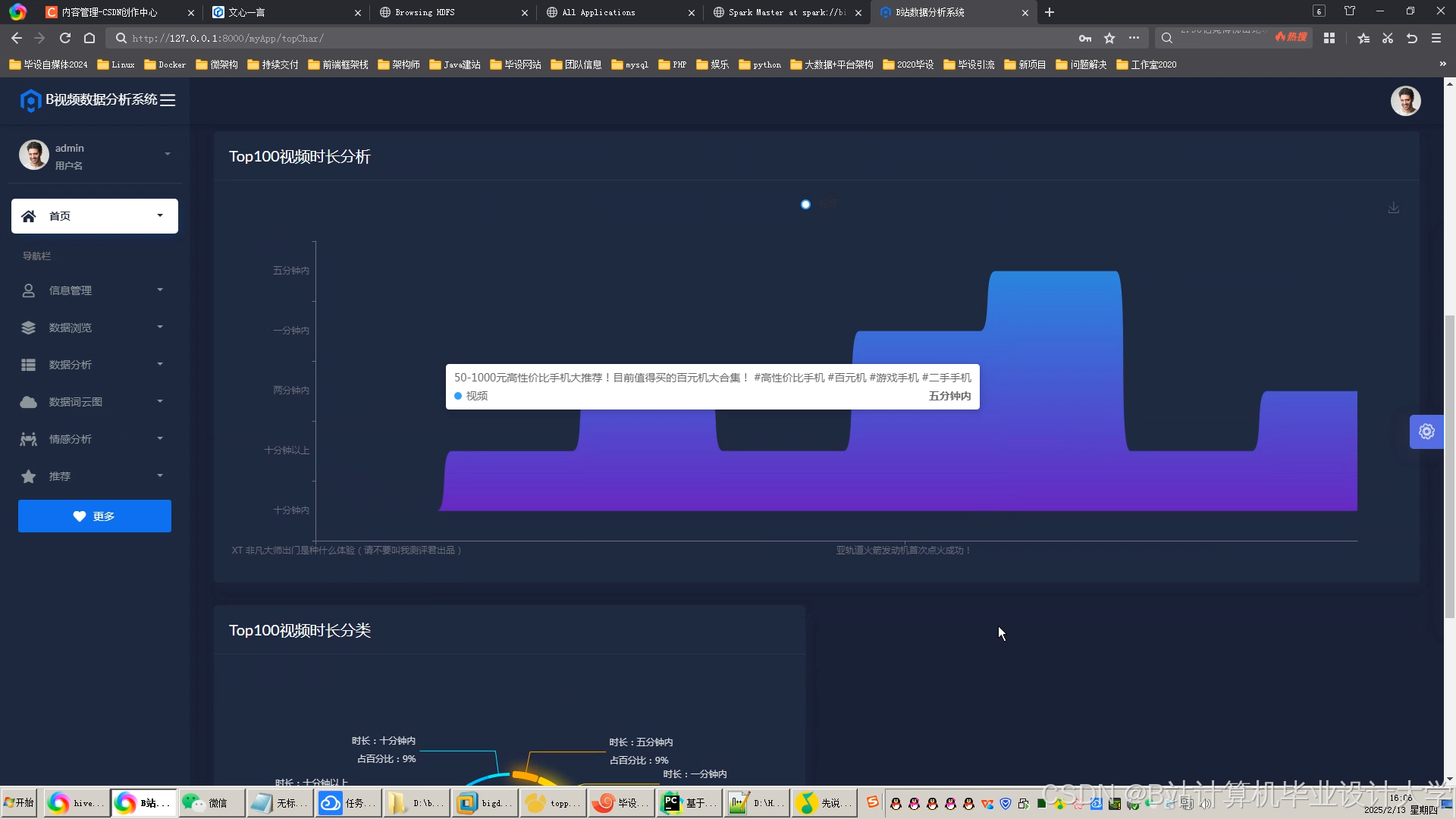
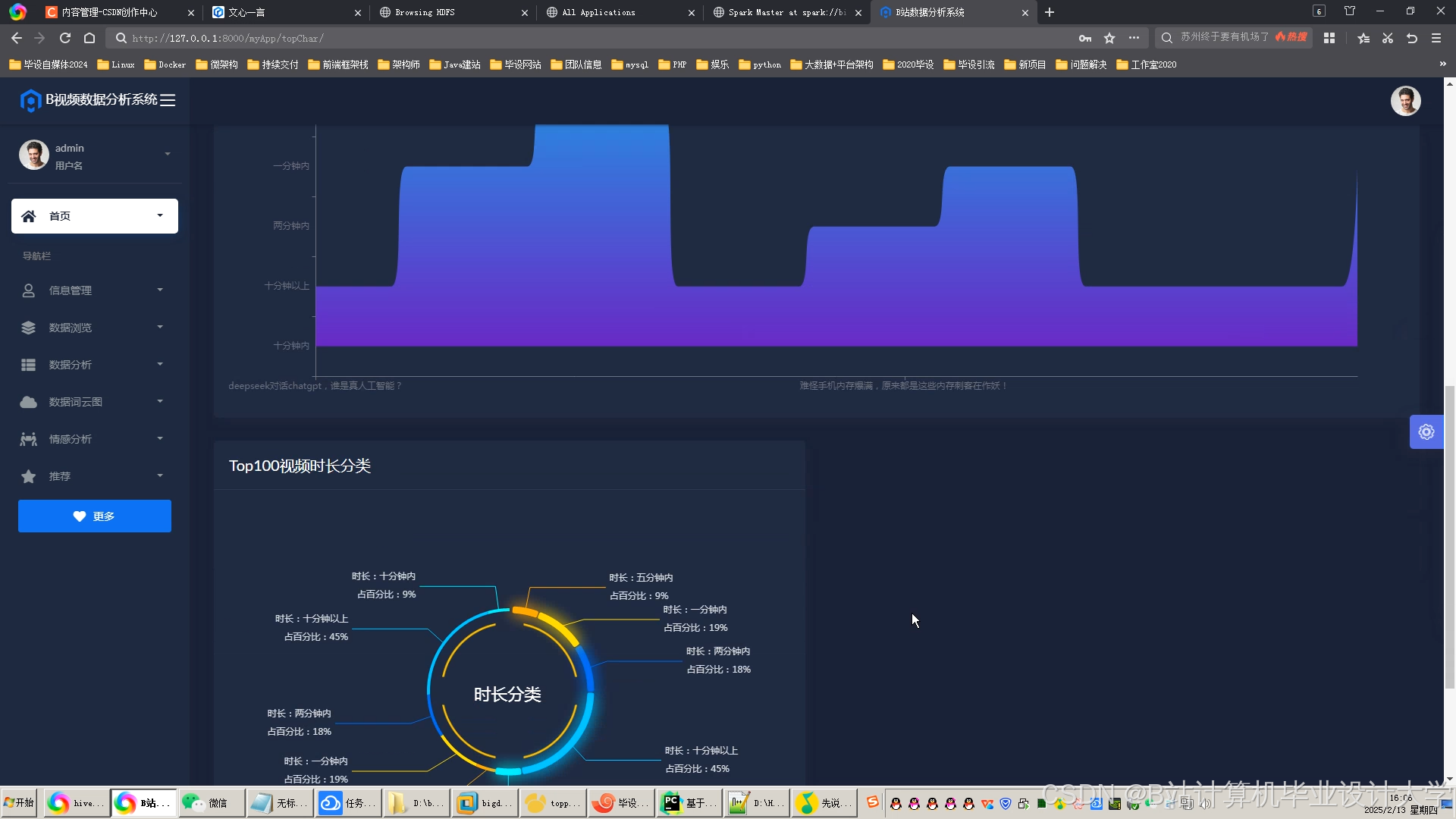
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











