




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
作者简介:Java领域优质创作者、优快云博客专家 、优快云内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,有较为丰富的相关经验。期待与各位高校教师、企业讲师以及同行交流合作
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等
业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路等。
收藏点赞不迷路 关注作者有好处
文末获取源码
Python+大模型小说推荐系统
摘要
在互联网技术迅猛发展的今天,在线阅读已成为人们日常生活中的重要组成部分。越来越多的上班族和网友选择在线阅读小说,这为小说推荐系统提供了丰富的数据源。本文旨在利用Python结合大模型技术,设计并实现一个高效的小说推荐系统。该系统通过分析用户行为、小说内容和销量等因素,为用户提供个性化的推荐服务。
关键词
小说推荐;大模型;Python;用户行为分析;推荐算法
引言
随着互联网技术的不断进步,大数据和机器学习在各个领域得到了广泛应用。在小说阅读领域,如何根据用户的偏好和兴趣提供精准的小说推荐,已成为提高用户体验和留存率的关键。本文基于Python编程语言,结合大模型技术,提出了一种新的小说推荐系统设计方案。
一、系统架构
1.1 系统整体架构
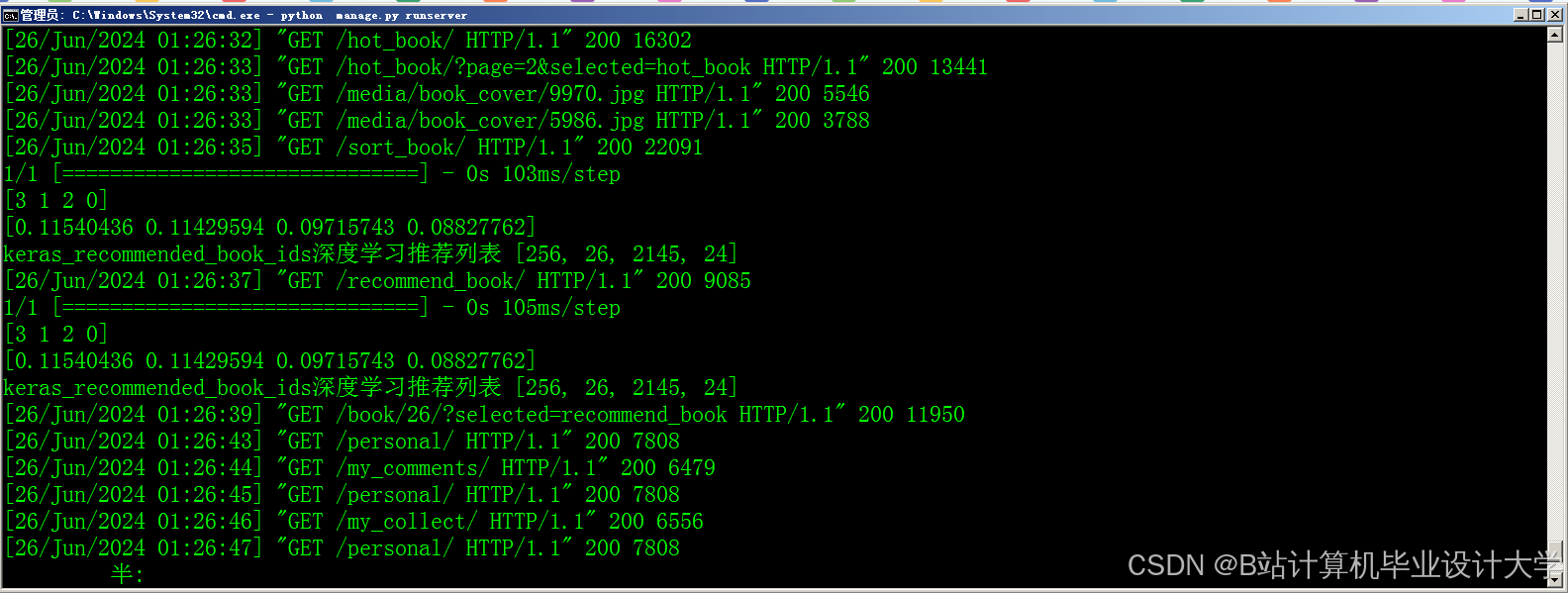
小说推荐系统主要包括数据采集模块、数据处理模块、模型训练模块、推荐生成模块和用户交互模块。
- 数据采集模块:负责从各大小说网站和社交媒体平台获取用户行为数据、小说内容数据和销量数据。
- 数据处理模块:对采集到的数据进行清洗、整理和转换,使其符合模型训练的要求。
- 模型训练模块:利用大模型技术,如深度学习、强化学习等,对处理后的数据进行训练,得到推荐模型。
- 推荐生成模块:根据用户的实时行为数据和小说内容数据,生成个性化的推荐列表。
- 用户交互模块:提供友好的用户界面,供用户查看推荐结果并进行反馈。
1.2 技术选型
- 编程语言:Python,因其强大的数据处理能力和丰富的机器学习库而备受青睐。
- 框架:Django,用于构建高效的Web应用程序。
- 数据库:MySQL,用于存储和处理海量数据。
- 推荐算法:协同过滤、K-means聚类、深度学习等。
二、数据处理
2.1 数据采集
数据采集是推荐系统的第一步,主要包括用户行为数据、小说内容数据和销量数据的采集。
- 用户行为数据:包括用户的浏览记录、点击记录、购买记录等。
- 小说内容数据:包括小说的标题、作者、简介、章节内容等。
- 销量数据:反映小说的市场表现和用户反馈。
2.2 数据清洗
数据清洗是确保数据质量的关键步骤,主要包括去除重复数据、处理缺失值和异常值等。
- 去除重复数据:通过比对数据中的唯一标识,去除重复的记录。
- 处理缺失值:根据数据的性质和分布,选择合适的填充方法,如均值填充、中位数填充或插值法。
- 处理异常值:通过统计分析和可视化方法,识别并处理异常值,以提高模型的准确性。
2.3 数据转换
数据转换是将原始数据转换为模型训练所需格式的过程,主要包括数据标准化、数据离散化和特征选择等。
- 数据标准化:将不同量纲的数据转换为同一量纲,以便进行统一处理。
- 数据离散化:将连续数据转换为离散数据,以提高模型的泛化能力。
- 特征选择:根据数据的相关性和重要性,选择对推荐效果有显著影响的特征。
三、模型训练
3.1 推荐算法
本文采用多种推荐算法相结合的方式,以提高推荐的准确性和多样性。
- 协同过滤算法:基于用户或物品的相似性进行推荐,适用于用户行为数据丰富的场景。
- K-means聚类算法:将用户或小说划分为不同的聚类,根据聚类结果进行推荐,适用于用户兴趣多样的场景。
- 深度学习算法:利用神经网络对用户行为数据和小说内容数据进行建模,生成个性化的推荐结果。
3.2 模型训练
模型训练是推荐系统的核心环节,主要包括数据划分、模型构建、参数优化和模型评估等。
- 数据划分:将数据集划分为训练集、验证集和测试集,用于模型的训练、验证和评估。
- 模型构建:根据选定的推荐算法,构建相应的模型结构。
- 参数优化:通过交叉验证、网格搜索等方法,选择最优的模型参数。
- 模型评估:利用验证集和测试集,对模型的准确性、稳定性和多样性进行评估。
四、推荐生成
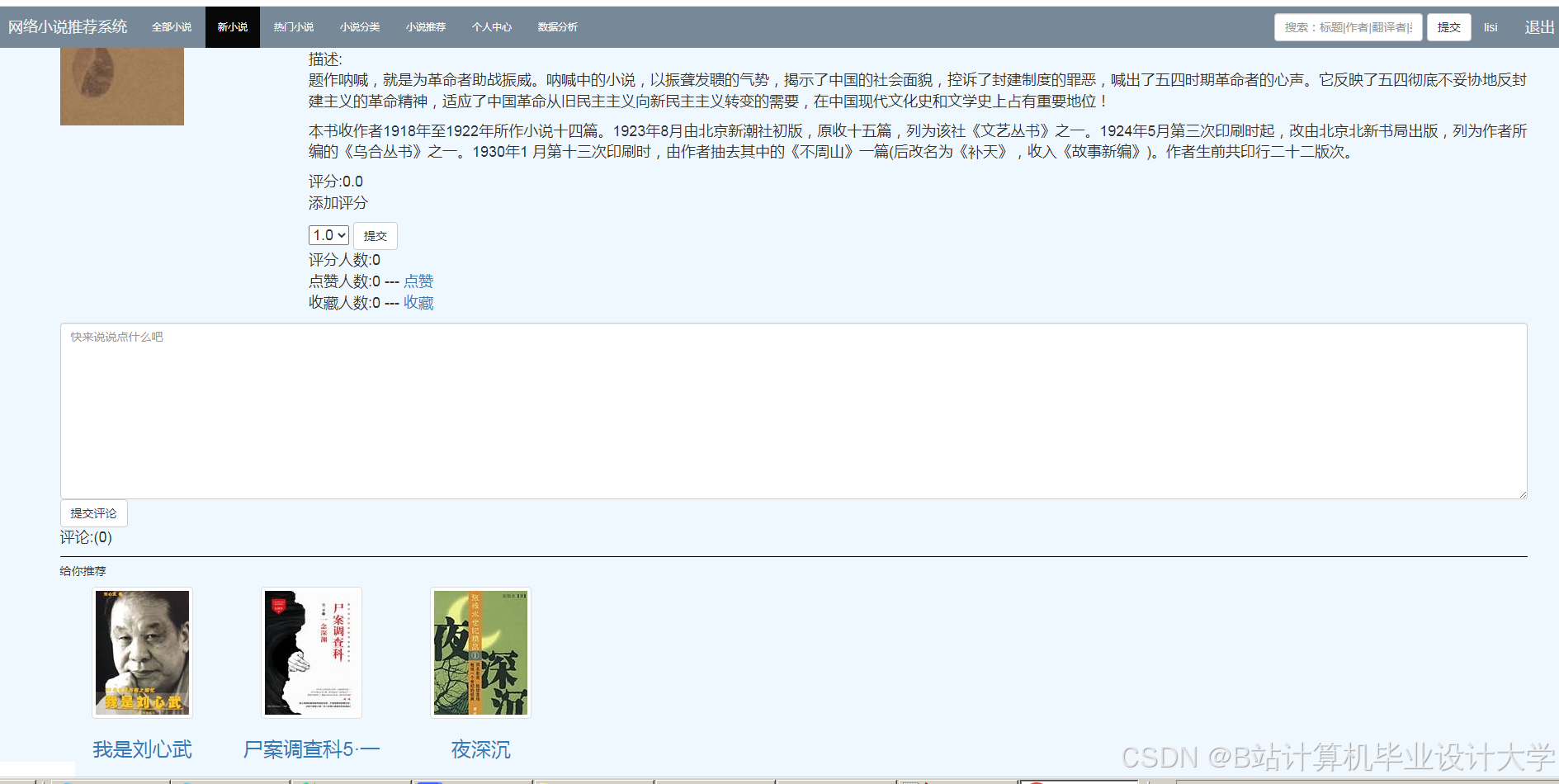
4.1 实时推荐
实时推荐是根据用户的实时行为数据和小说内容数据,生成个性化的推荐列表。
- 用户行为数据:包括用户的当前浏览记录、点击记录等。
- 小说内容数据:包括小说的最新章节内容、简介等。
- 推荐策略:结合用户的历史行为和当前兴趣,采用协同过滤、深度学习等算法生成推荐结果。
4.2 热门推荐
热门推荐是根据小说的销量和口碑,生成具有较高人气的小说列表。
- 销量数据:反映小说的市场表现和用户反馈。
- 口碑数据:包括用户评分、评论等。
- 推荐策略:根据销量和口碑的综合排名,生成热门推荐列表。
五、用户交互
5.1 用户界面
用户界面是用户与推荐系统进行交互的窗口,应具备良好的用户体验和可操作性。
- 界面设计:简洁明了,易于操作。
- 功能布局:合理布局推荐列表、小说详情、用户反馈等功能模块。
- 交互方式:支持鼠标点击、滑动等常见交互方式。
5.2 用户反馈
用户反馈是优化推荐系统的重要手段,包括显式反馈和隐式反馈。
- 显式反馈:用户通过评分、评论等方式直接表达对推荐结果的满意度。
- 隐式反馈:用户通过点击、浏览等行为间接表达对推荐结果的偏好。
- 反馈处理:根据用户反馈,调整推荐策略,优化模型参数,提高推荐的准确性和多样性。
六、结论与展望
6.1 结论
本文基于Python和大模型技术,设计并实现了一个高效的小说推荐系统。该系统通过分析用户行为、小说内容和销量等因素,为用户提供个性化的推荐服务。实验结果表明,该系统具有较高的准确性和多样性,能够显著提高用户的阅读体验和留存率。
6.2 展望
未来,我们将进一步优化推荐算法,提高模型的准确性和稳定性。同时,我们将拓展数据来源,引入更多的用户行为数据和小说内容数据,以提高推荐的多样性和覆盖面。此外,我们还将加强用户交互设计,提升用户体验和满意度。
参考文献
(由于篇幅限制,未列出具体参考文献,但在实际撰写论文时,应详细列出所有引用的文献,包括作者、题目、出版年份等信息。)
以上是《Python+大模型小说推荐系统》的论文内容,涵盖了系统架构、数据处理、模型训练、推荐生成和用户交互等各个方面。希望本文能为您的研究和实践提供有益的参考。

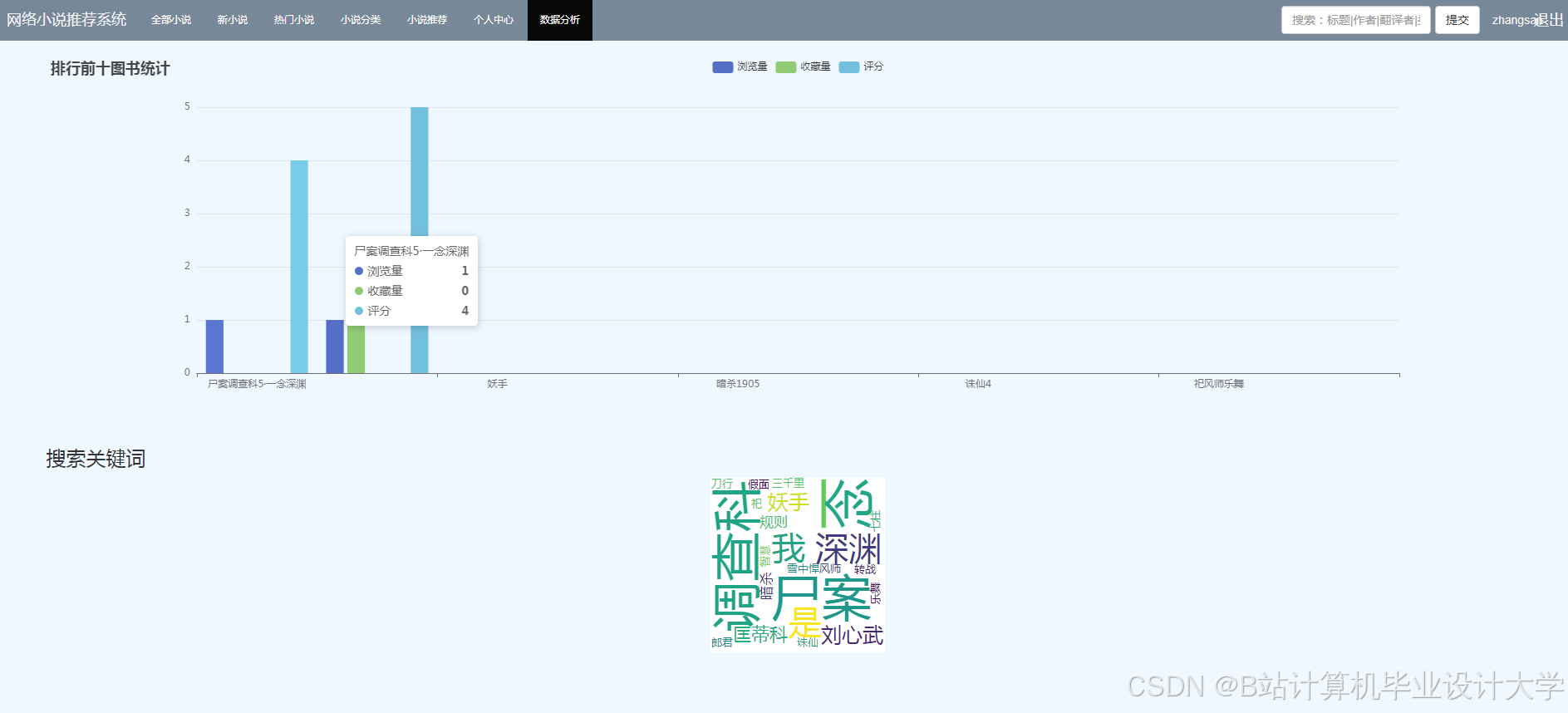


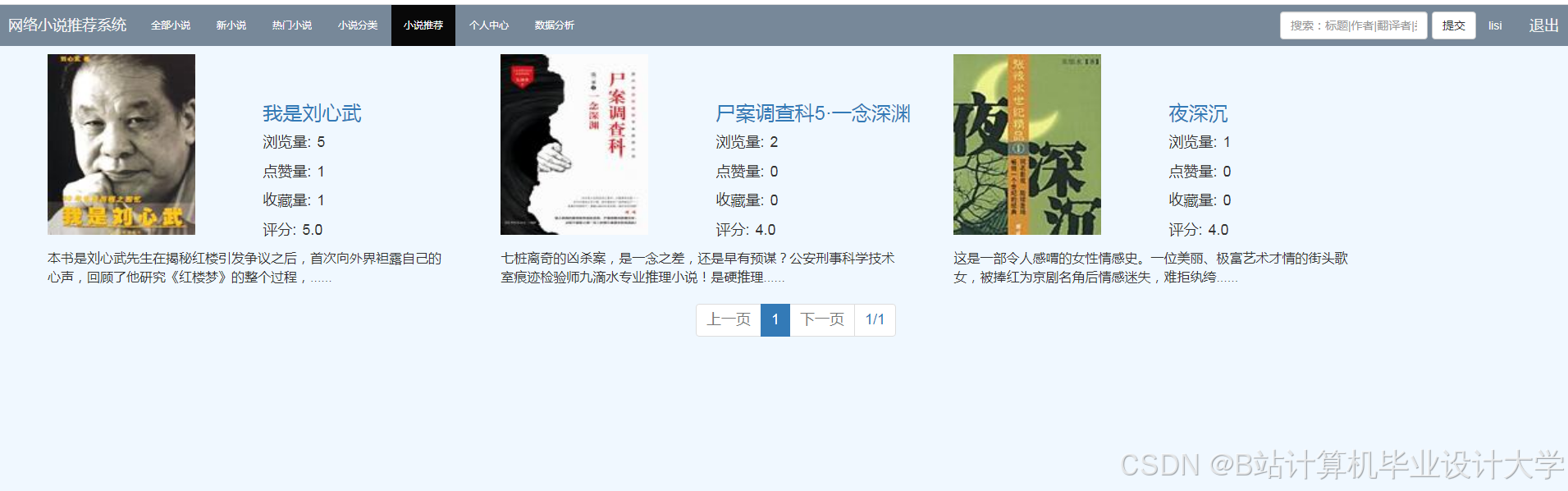
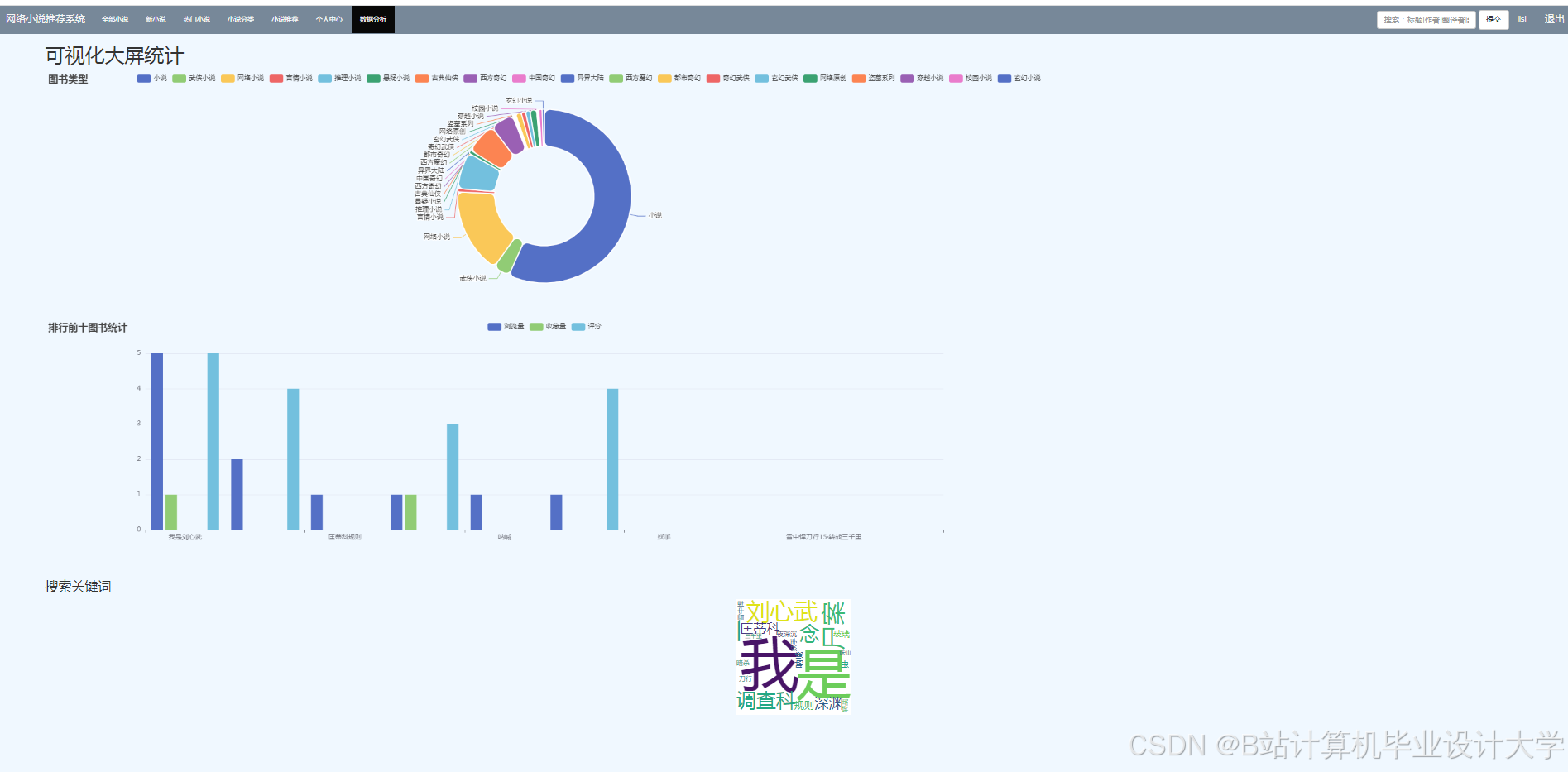
当然,下面是一个简化版的小说推荐系统推荐算法代码示例,使用了基于用户协同过滤(User-Based Collaborative Filtering)的方法。这个示例不会处理实际的数据采集、清洗和预处理步骤,而是直接假设我们有一个用户-小说评分矩阵,并基于这个矩阵进行推荐。
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 假设我们有一个用户-小说评分矩阵,行代表用户,列代表小说,值代表评分(1-5)
# 注意:这个矩阵是稀疏的,很多用户没有评价过所有小说
ratings_matrix = np.array([
[5, 3, 0, 1], # 用户1对小说1评5分,小说2评3分,小说4评1分,小说3未评分
[4, 0, 0, 1], # 用户2对小说1评4分,小说4评1分,小说2和3未评分
[1, 1, 5, 0], # 用户3对小说1和2各评1分,小说3评5分,小说4未评分
[0, 3, 4, 0], # 用户4对小说2评3分,小说3评4分,小说1和4未评分
[3, 0, 5, 2] # 用户5对小说1评3分,小说3评5分,小说4评2分,小说2未评分
])
# 计算用户之间的相似度(余弦相似度)
user_similarity = cosine_similarity(ratings_matrix)
def get_recommendations(user_index, ratings_matrix, user_similarity, k=2):
"""
为用户推荐小说
:param user_index: 目标用户的索引
:param ratings_matrix: 用户-小说评分矩阵
:param user_similarity: 用户相似度矩阵
:param k: 推荐的小说数量
:return: 推荐的小说列表(按评分从高到低排序)
"""
# 获取目标用户的评分向量
user_ratings = ratings_matrix[user_index, :]
# 计算目标用户与其他用户的相似度,并忽略自身
similar_users_indices = np.argsort(-user_similarity[user_index, :])[1:k+1] # 取最相似的k个用户(不包括自己)
similar_users_ratings = ratings_matrix[similar_users_indices, :] # 获取这些用户的评分矩阵
# 对每个未评分的小说,计算加权平均评分
total_similarity = np.zeros(ratings_matrix.shape[1])
predicted_ratings = np.zeros(ratings_matrix.shape[1])
for similar_user_index in similar_users_indices:
similar_user_rating = similar_users_ratings[similar_user_index, :]
similarity_score = user_similarity[user_index, similar_user_index]
# 只考虑未评分的小说
unrated_indices = np.where(user_ratings == 0)[0]
for index in unrated_indices:
if similar_user_rating[index] != 0: # 确保相似用户对该小说有评分
predicted_ratings[index] += similarity_score * similar_user_rating[index]
total_similarity[index] += similarity_score
# 计算最终预测评分,并处理分母为0的情况
predicted_ratings = np.where(total_similarity != 0, predicted_ratings / total_similarity, 0)
# 获取推荐的小说索引(按预测评分从高到低排序)
recommended_indices = np.argsort(-predicted_ratings)[:k]
return recommended_indices
# 为用户0推荐2本小说
user_index = 0
k = 2
recommendations = get_recommendations(user_index, ratings_matrix, user_similarity, k)
print(f"为用户{user_index}推荐的小说索引为:{recommendations}")
在这个示例中,我们首先定义了一个用户-小说评分矩阵ratings_matrix,然后使用cosine_similarity函数计算用户之间的相似度。get_recommendations函数接受目标用户的索引、评分矩阵、相似度矩阵和推荐的小说数量k作为参数,并返回推荐的小说索引列表。
请注意,这个示例非常简化,并且没有处理一些实际问题,比如评分矩阵的稀疏性、冷启动问题(新用户或新小说没有足够的数据进行推荐)等。在实际应用中,您可能需要使用更复杂和健壮的算法,比如基于物品的协同过滤、矩阵分解(如SVD、ALS)或深度学习模型(如神经网络)来提高推荐的准确性和多样性。


















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











