




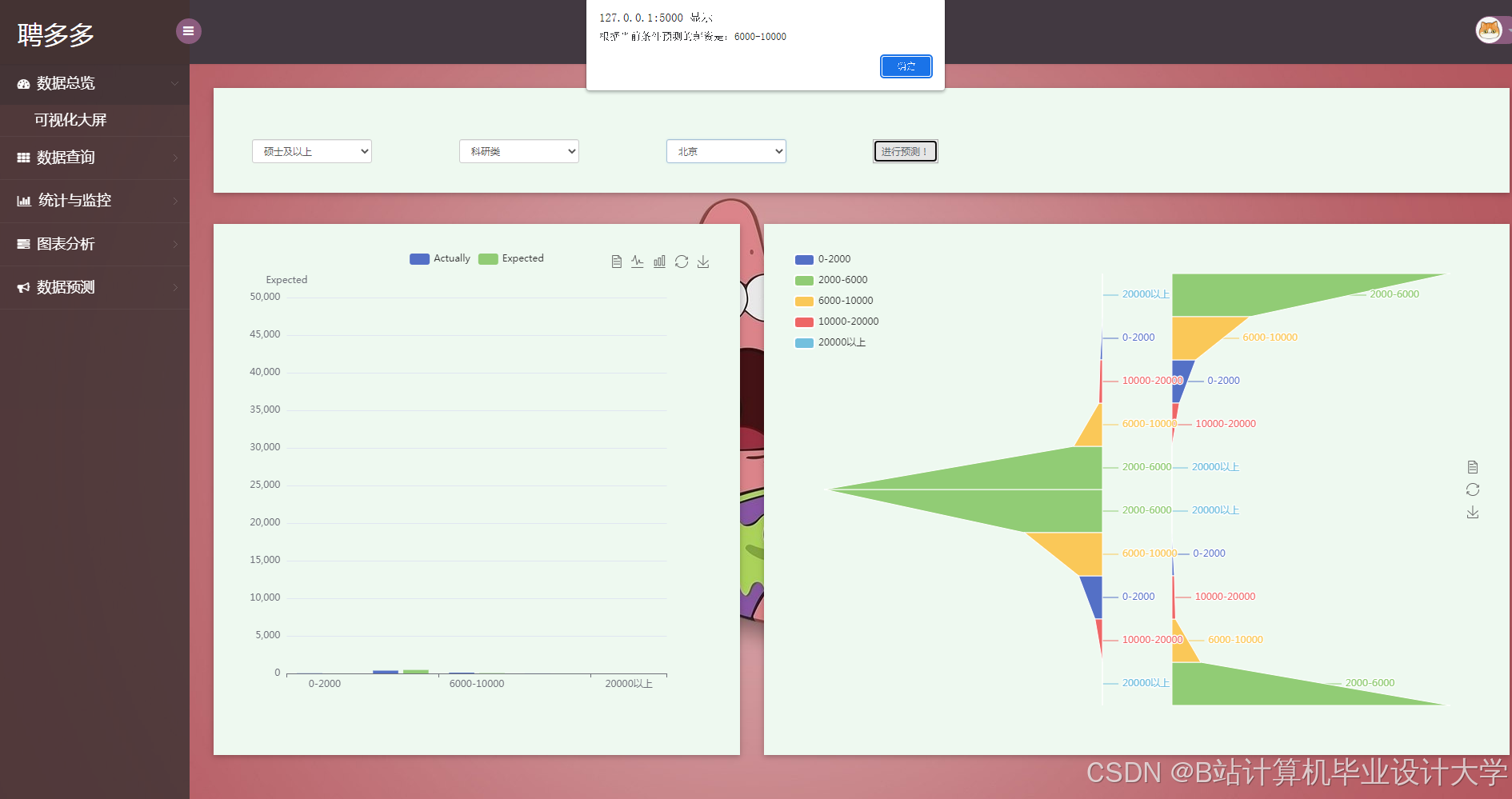
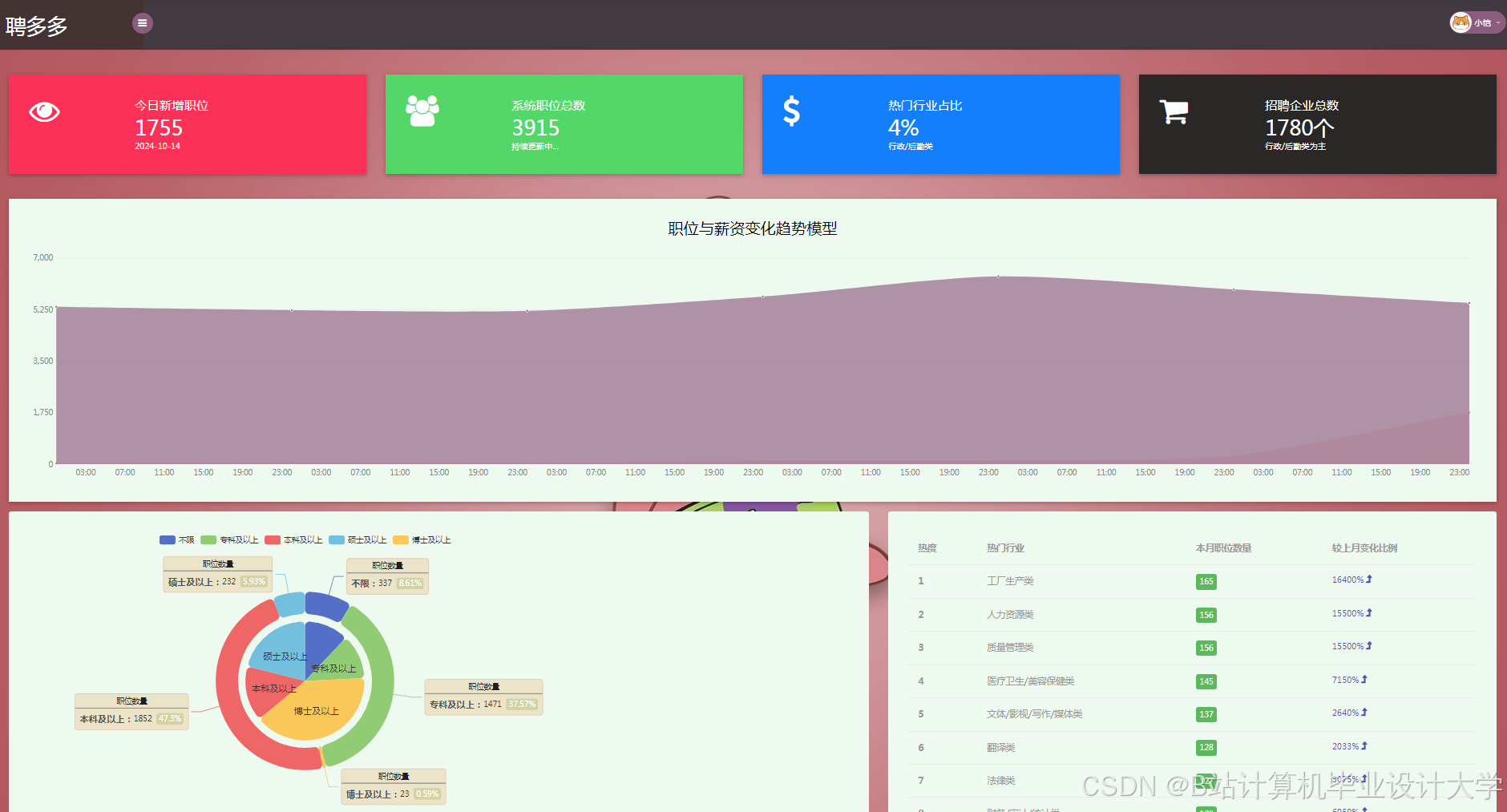
这是一个基于Flask的轻量化招聘信息分析系统,系统基于selenium进行数据爬取并基于pandas进行数据的处理,使用skit-learn的贝叶斯模型预测薪资,前端主要使用html,css,jquery,以echarts作为数据可视化的工具。 注意:所爬取数据来源于大学生招聘信息平台.
核心算法代码分享如下:
import pandas as pd
from sqlalchemy import create_engine
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import CategoricalNB
from sklearn.metrics import accuracy_score
from sklearn.impute import SimpleImputer
con = create_engine('mysql+pymysql://root:123456@localhost:3306/boss')
df = pd.read_sql('select degree,categories,area,company_scale,company_property,salary from jobs_info', con=con)
def native_bayes():
# 数值化处理
# factorize返回的是具有两个数组的元组,第一个是整数编码,第二个是映射
df['degree'] = df['degree'].astype(str).factorize()[0]
df['categories'] = df['categories'].astype(str).factorize()[0]
df['area'] = df['area'].astype(str).factorize()[0]
df['company_scale'] = df['company_scale'].astype(str).factorize()[0]
df['company_property'] = df['company_property'].astype(str).factorize()[0] # 该列中有大量缺失数据,如果预测不理想考虑处理
imp = SimpleImputer(strategy='mean')
df['company_property'] = imp.fit_transform(df[['company_property']])
df['salary'] = df['salary'].astype(str).factorize()[0]
print(df['salary'])
# 数据集
X = df.drop('salary', axis=1) # 指定删除列
y = df['salary']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 构建朴素贝叶斯分类模型
nb = GaussianNB()
# 在训练集上拟合模型
nb.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = nb.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
if __name__ == '__main__':
native_bayes()




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











