




《Python+Django企业征信预测与分析可视化》开题报告
一、选题背景与意义
随着互联网技术的快速发展,企业征信数据已成为评估企业信用状况、控制金融风险、促进经济健康发展的重要依据。然而,面对海量的企业征信数据,如何高效地提取有价值的信息、进行精准预测和分析,并以直观、可视化的方式呈现给用户,是当前企业和研究机构面临的重要挑战。
Python作为一种高效、灵活的编程语言,结合Django框架,能够构建出稳定、可扩展的企业征信预测与分析系统。同时,数据可视化技术能够将复杂的分析结果以图表、图形等形式直观展现,帮助用户快速理解数据背后的规律和趋势。因此,开发基于Python+Django的企业征信预测与分析可视化系统具有重要的现实意义和应用价值。
二、国内外研究现状
国内研究现状
在国内,随着大数据和人工智能技术的快速发展,企业征信数据的挖掘和分析逐渐成为研究热点。一些大型金融科技公司和研究机构已经推出了自己的企业征信数据分析平台,通过数据爬取、清洗、建模和可视化展示,为金融机构和企业提供全面的信用评估服务。此外,一些学者还结合Python和Django框架,在企业征信数据的爬取、处理和可视化方面进行了深入研究,取得了显著成果。
国外研究现状
在国外,企业征信预测与分析可视化也是一个热门的研究领域。许多知名的科技公司和研究机构都在这一领域进行了深入研究和实践。例如,Google、Facebook等科技公司利用自身强大的技术实力,开发了先进的企业征信数据分析平台,为全球用户提供高效、精准的服务。此外,国外的研究者还提出了许多创新的技术和方法,如基于自然语言处理的文本分析、基于机器学习的预测模型等,进一步推动了企业征信预测与分析可视化技术的发展。
三、研究内容
本研究旨在开发一款基于Python+Django的企业征信预测与分析可视化系统,具体研究内容包括:
-
数据采集与预处理:利用Python的爬虫技术,从各大征信平台、政府网站等渠道获取企业征信数据,并进行数据清洗、转换和存储。
-
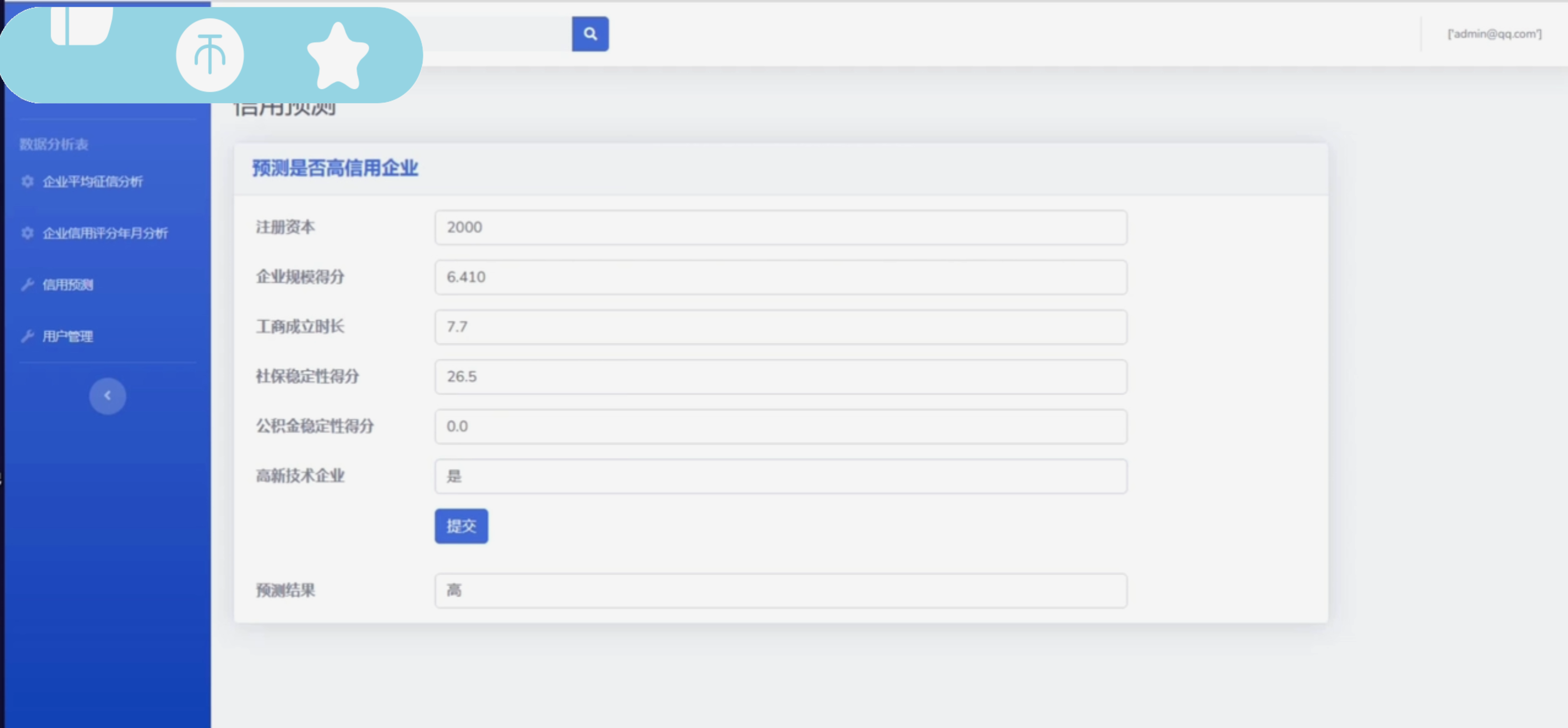
数据分析与建模:运用统计学和机器学习算法,对企业征信数据进行深入分析,建立信用评估模型和预测模型,实现对企业信用状况的精准评估和未来趋势的预测。
-
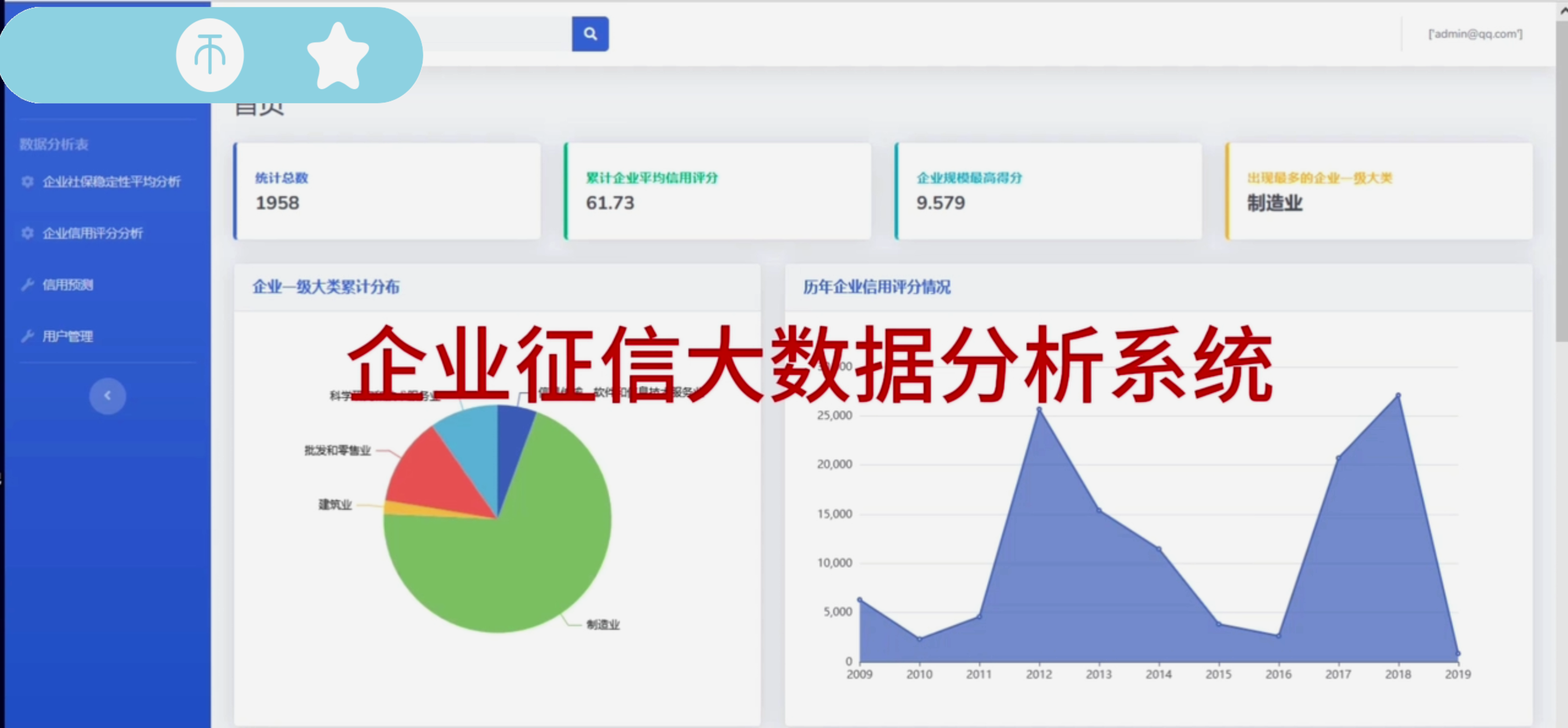
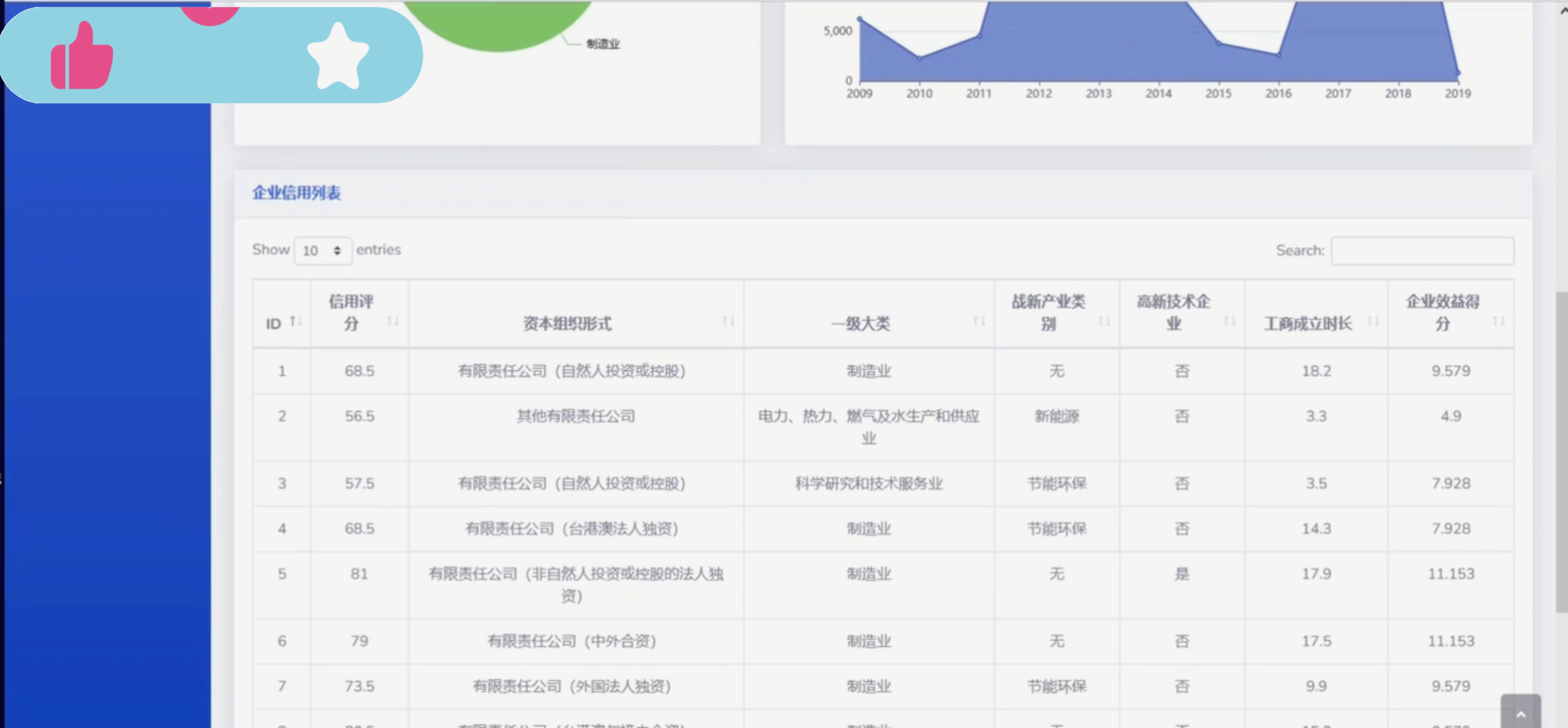
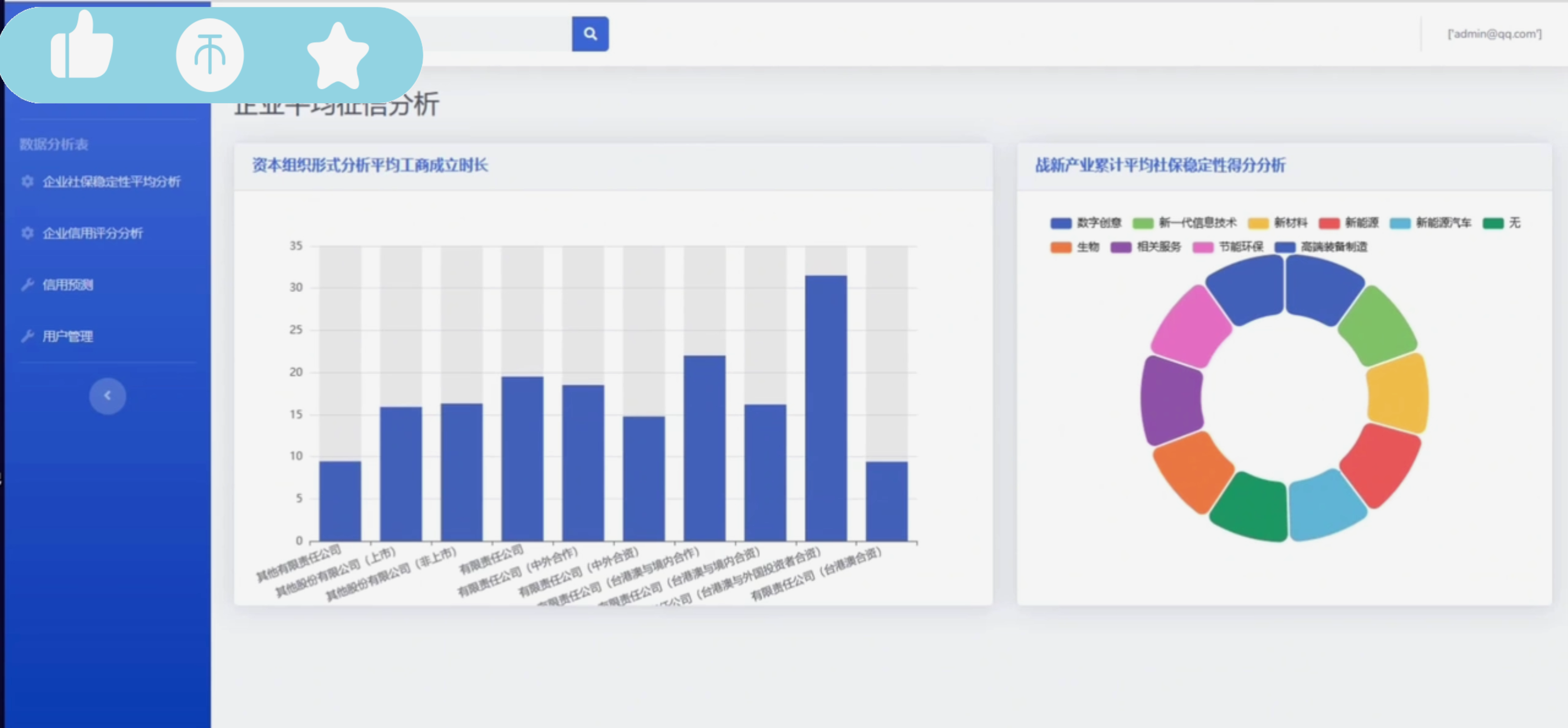
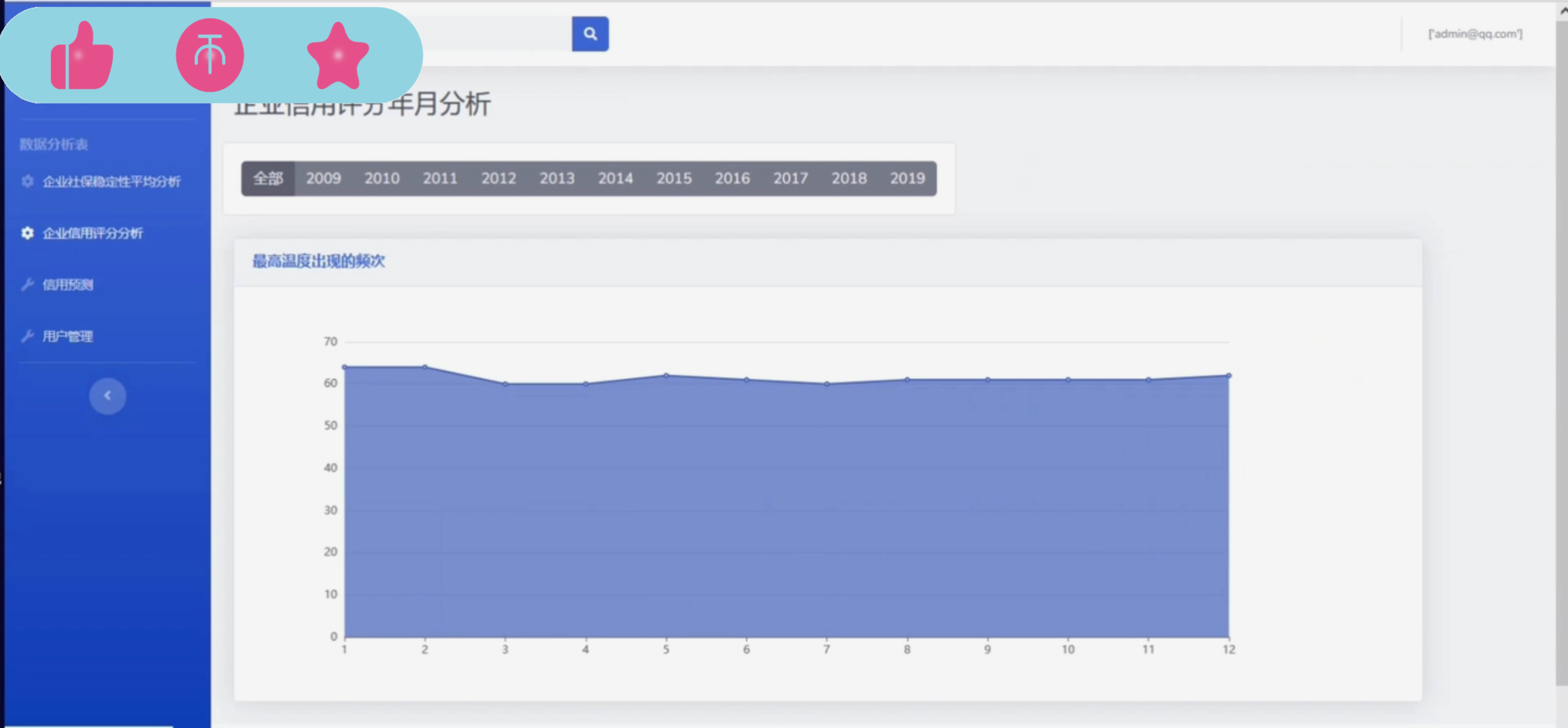
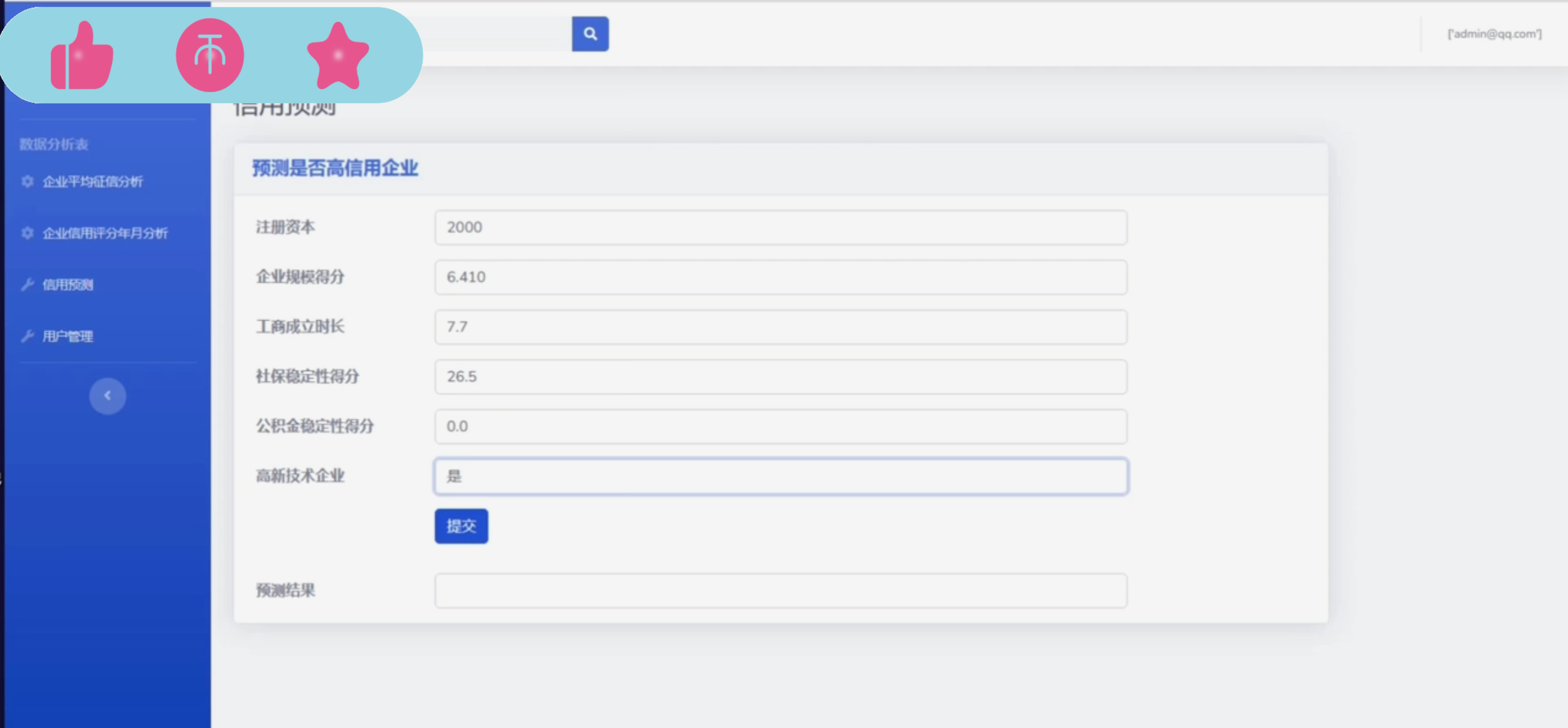
数据可视化:利用Django框架和前端技术(如HTML、CSS、JavaScript、ECharts等),将分析结果以图表、图形等形式直观展现给用户,提高数据的可读性和可理解性。
-
系统设计与实现:根据需求分析,设计系统架构、功能模块和数据库结构,并完成系统的编码、测试和部署工作。
四、研究方法
为了完成本研究,将采用以下研究方法:
-
文献阅读法:通过查阅国内外相关文献和资料,了解企业征信预测与分析可视化的研究现状和发展趋势,为系统设计提供理论依据和技术支持。
-
比较分析法:对国内外现有的企业征信数据分析平台进行功能、性能等方面的比较分析,找出存在的问题和不足,为系统设计提供改进方向。
-
模拟法:在本地开发环境中模拟系统的运行过程,通过测试验证系统的功能、性能和稳定性。
-
实践法:将系统设计方案付诸实践,通过编码、测试和部署等环节,完成系统的开发工作。
五、预期成果
通过本研究,预期将取得以下成果:
-
开发一款基于Python+Django的企业征信预测与分析可视化系统,实现对企业征信数据的全面挖掘和分析。
-
建立一套科学、有效的企业信用评估模型和预测模型,提高信用评估的准确性和预测能力。
-
提供直观、便捷的数据可视化展示功能,帮助用户快速理解数据背后的规律和趋势。
-
为企业征信领域的研究和应用提供新的思路和方法,推动该领域的发展和进步。
六、结论与展望
本研究将为企业征信预测与分析可视化领域提供新的解决方案和技术支持,具有重要的实际应用价值和研究意义。未来,随着技术的不断进步和应用场景的不断扩展,该系统将进一步完善和优化,为企业征信领域的发展注入新的活力和动力。同时,也期待更多的研究者和企业能够关注这一领域的研究和应用,共同推动该领域的繁荣和发展。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











