




核心技术以及功能介绍:
1. python编程语言,Django后端框架,Scrapy爬虫框架
2. javascript编程语言,Vue前端框架,Element-plus组件库,axios请求库,windicss样式库,echarts可视化
3. 核心算法:朴素贝叶斯情感分类,当爬虫抓取数据进行入库时,会对文本进行分析,分类出正向/中性/负向三种类别的情感,并给出正向情感的概率
4. 功能模块包括:
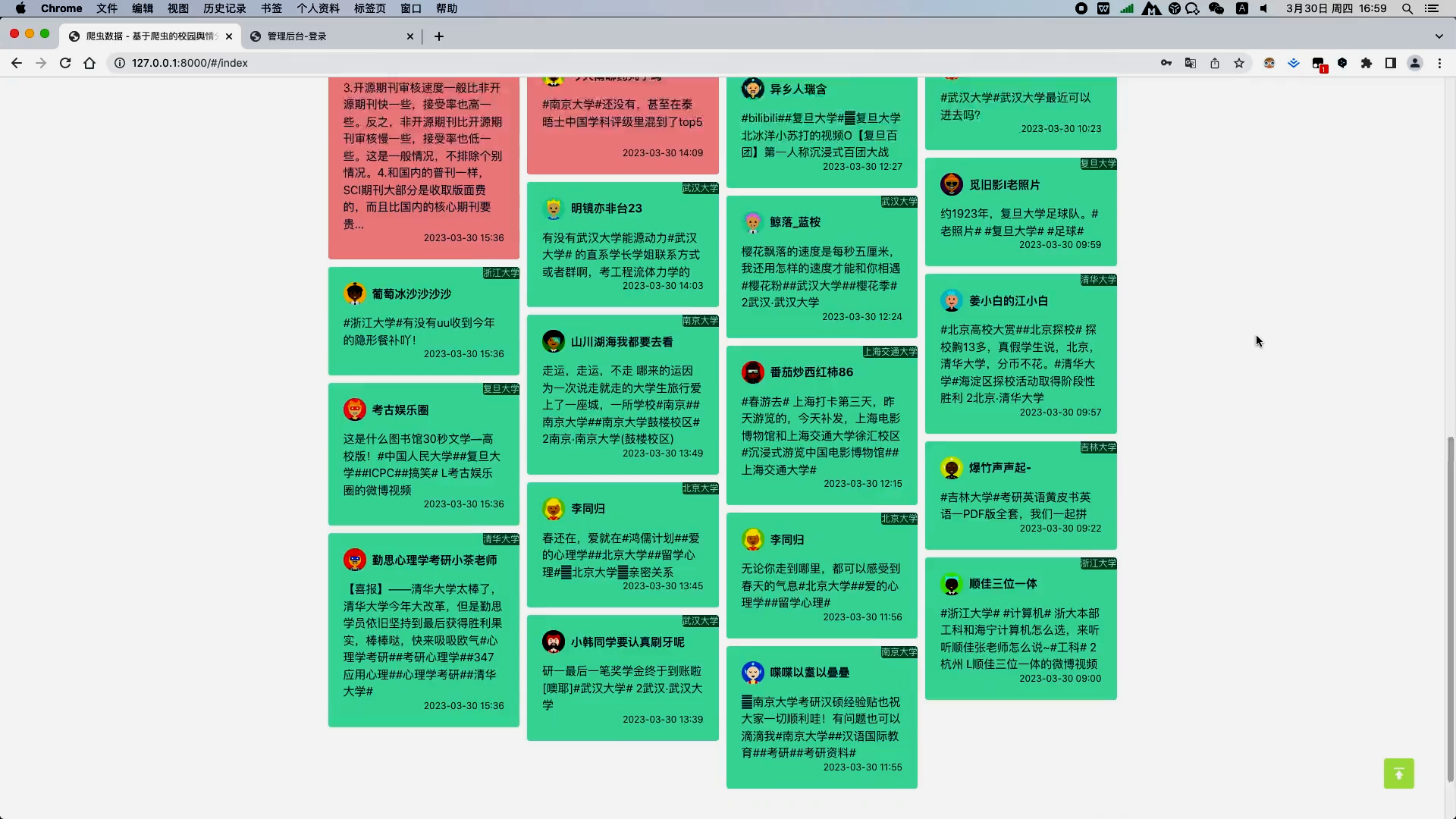
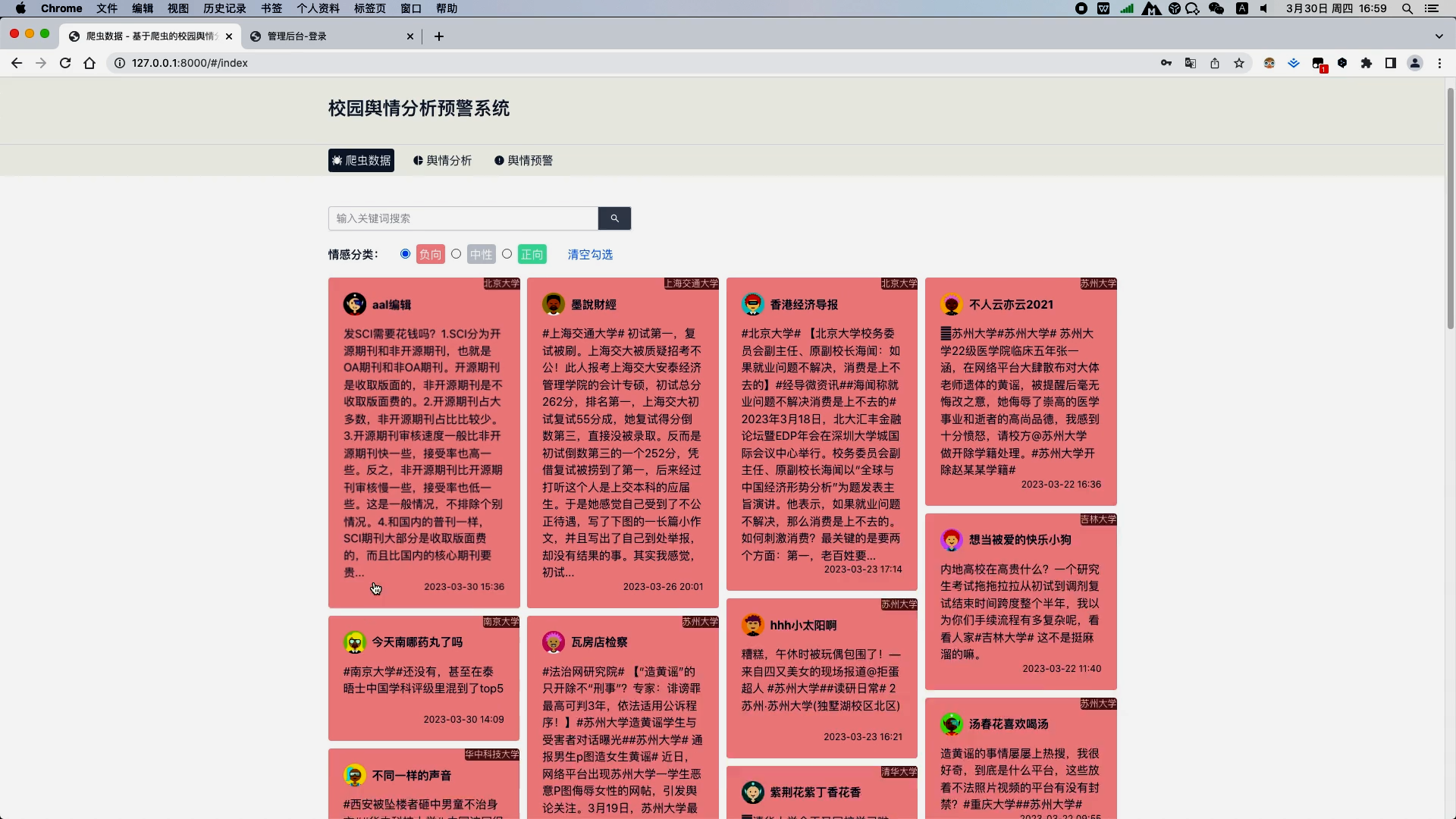
a. 微博各所大学数据的展示与筛选查询,数据以瀑布流卡片形式展现,正向情感的文本用绿色背景,中性用灰色背景,负向以红色背景,方便用户一眼可以识别出该微博数据的情感倾向;
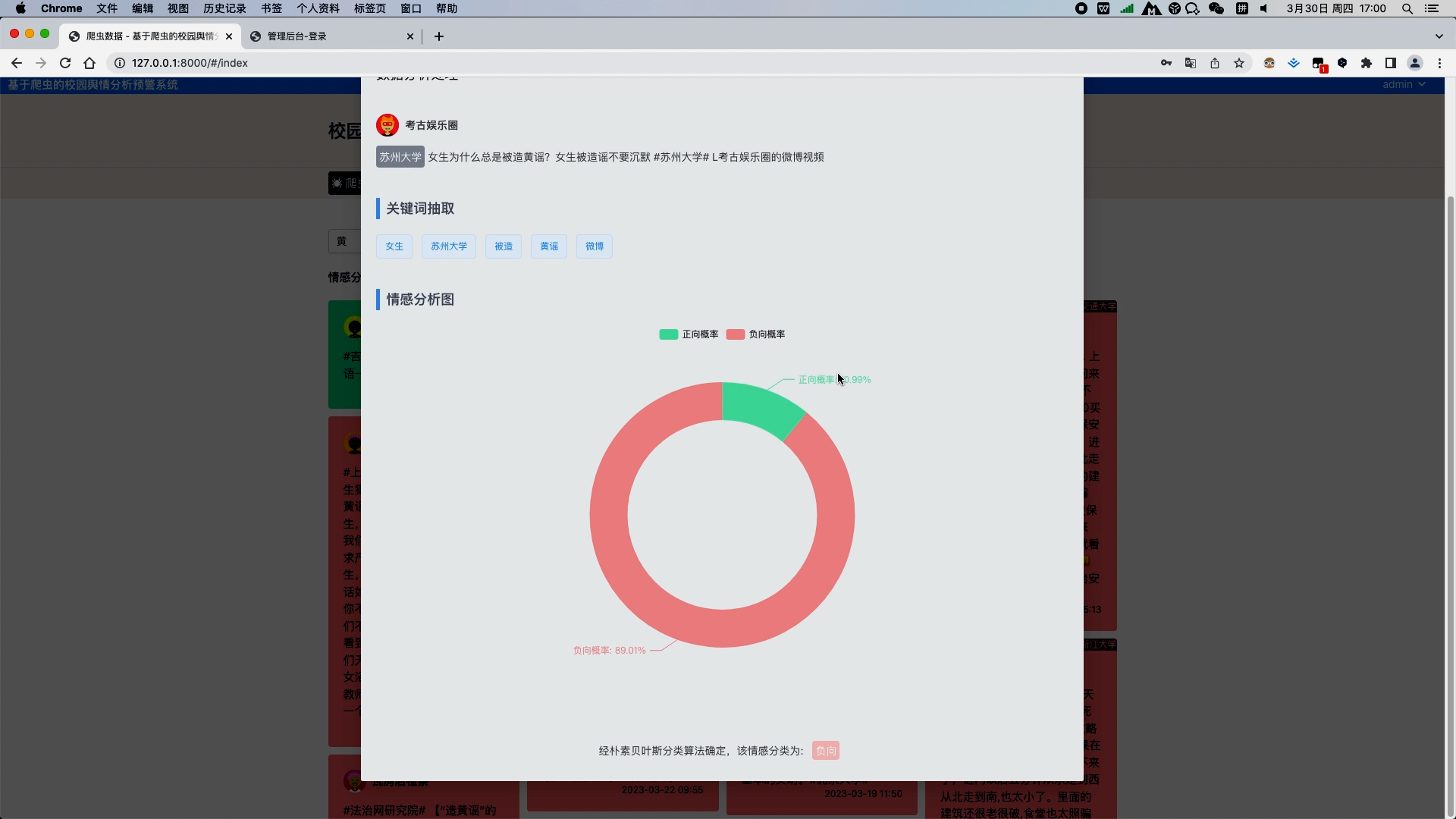
当用户点击卡片时,弹出对话框,显示该微博数据的详细信息,以及信息的关键词,以及饼图分析正负向的情感概率占比
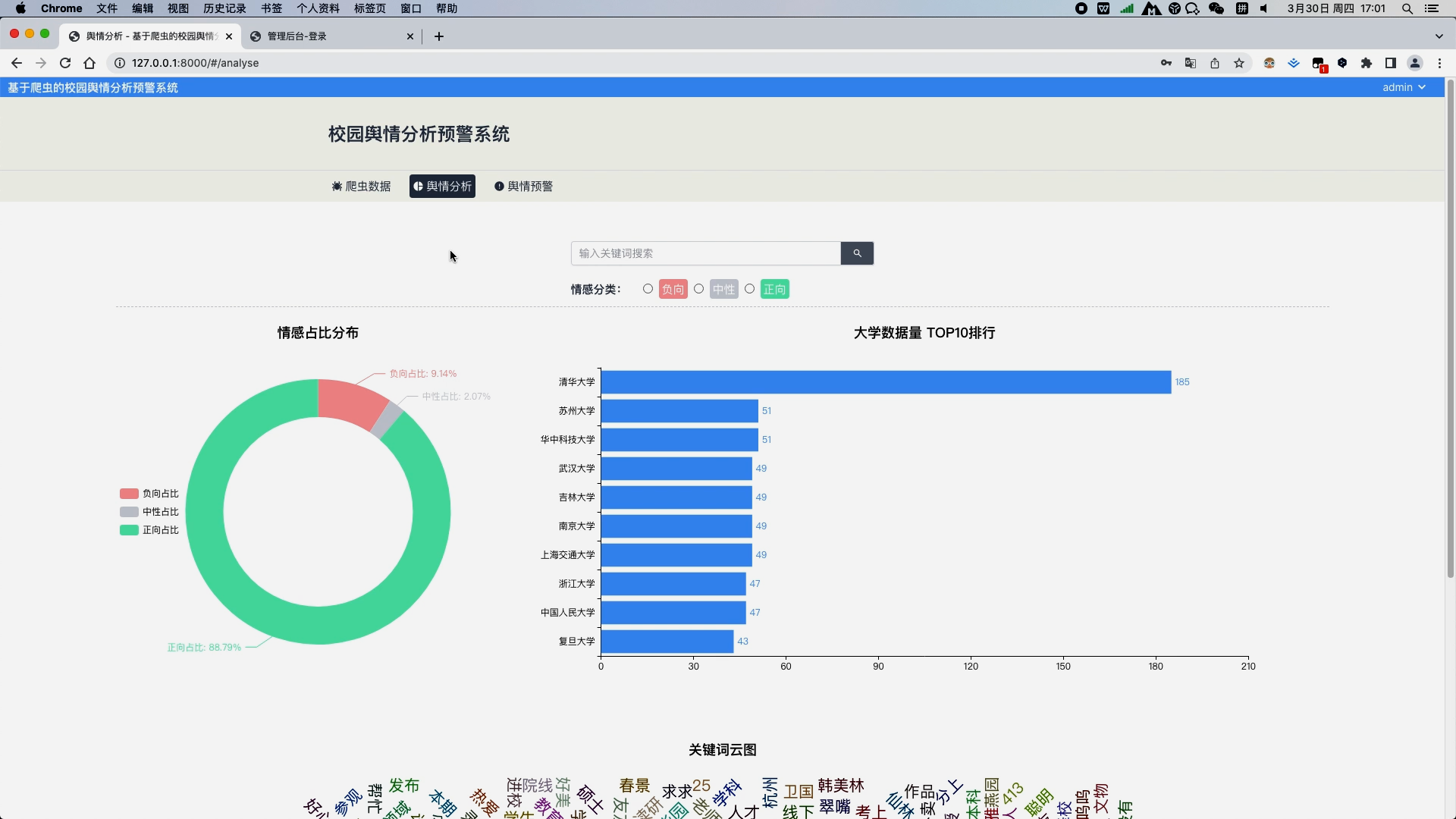
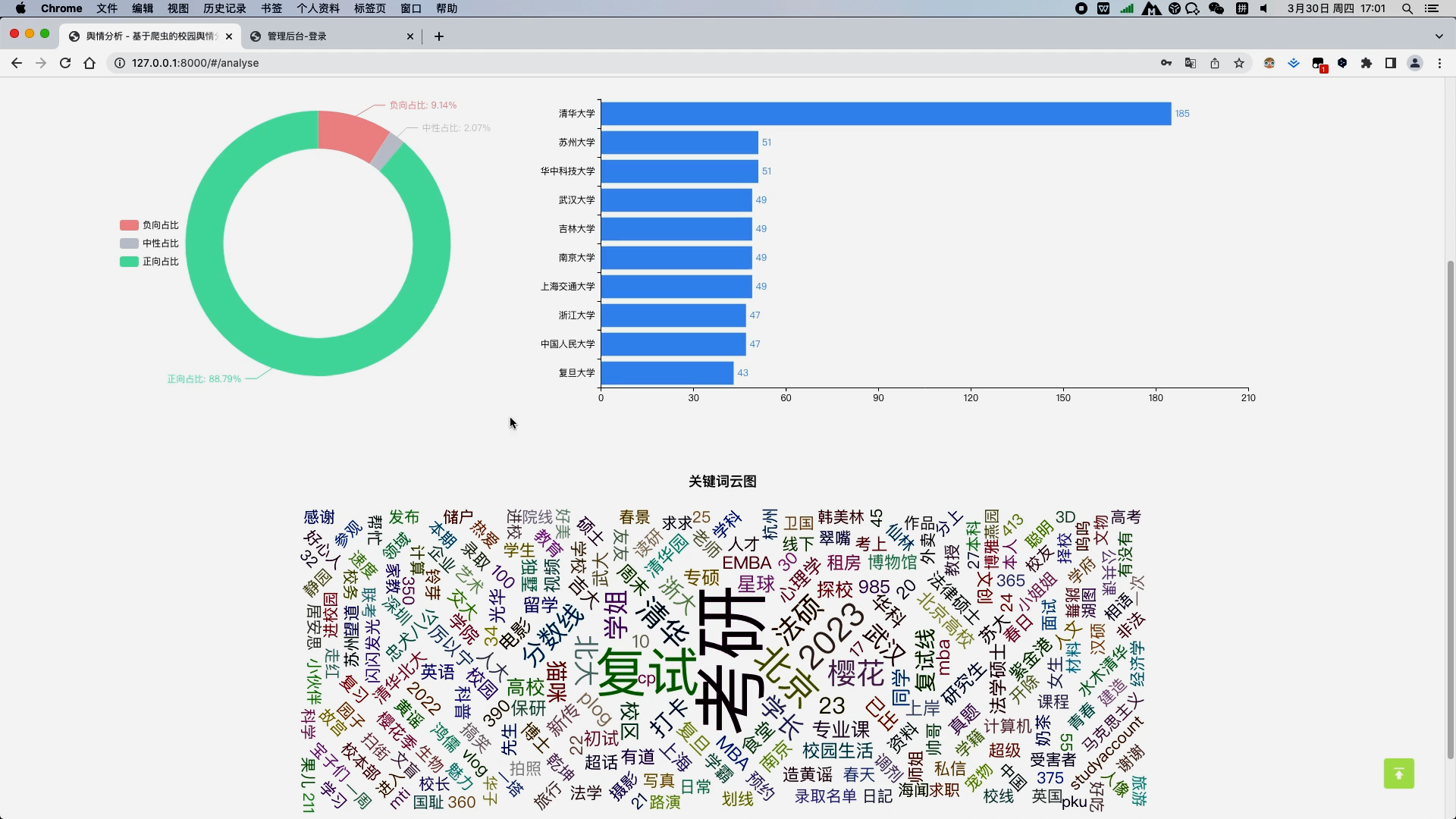
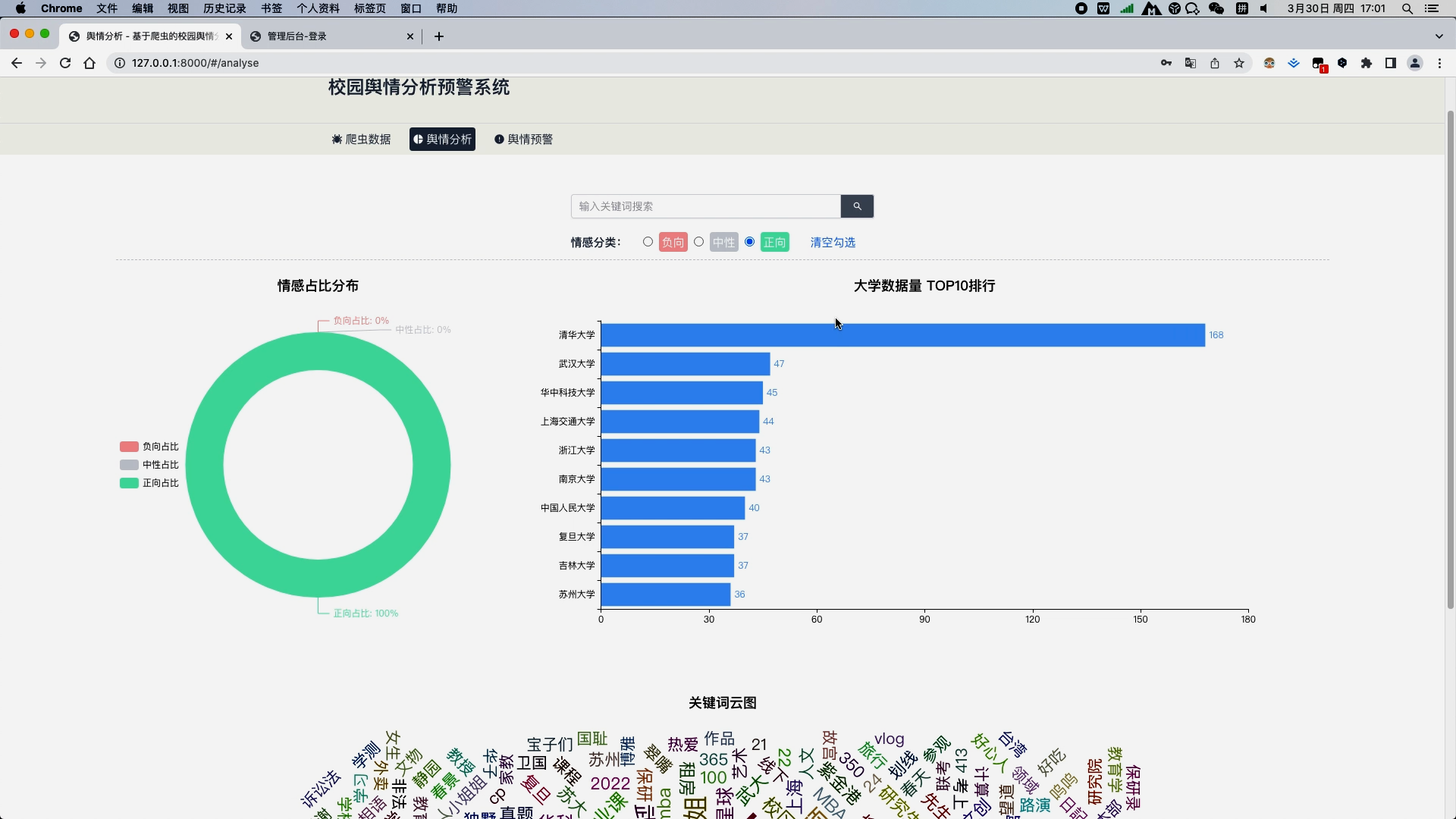
b. 舆情分析模块,用饼图对数据库中所有的微博信息的情感占比进行分析,用柱状图对数据库中所有高校信息量进行top10排序分析,以及用词云图分析所有数据的关键词
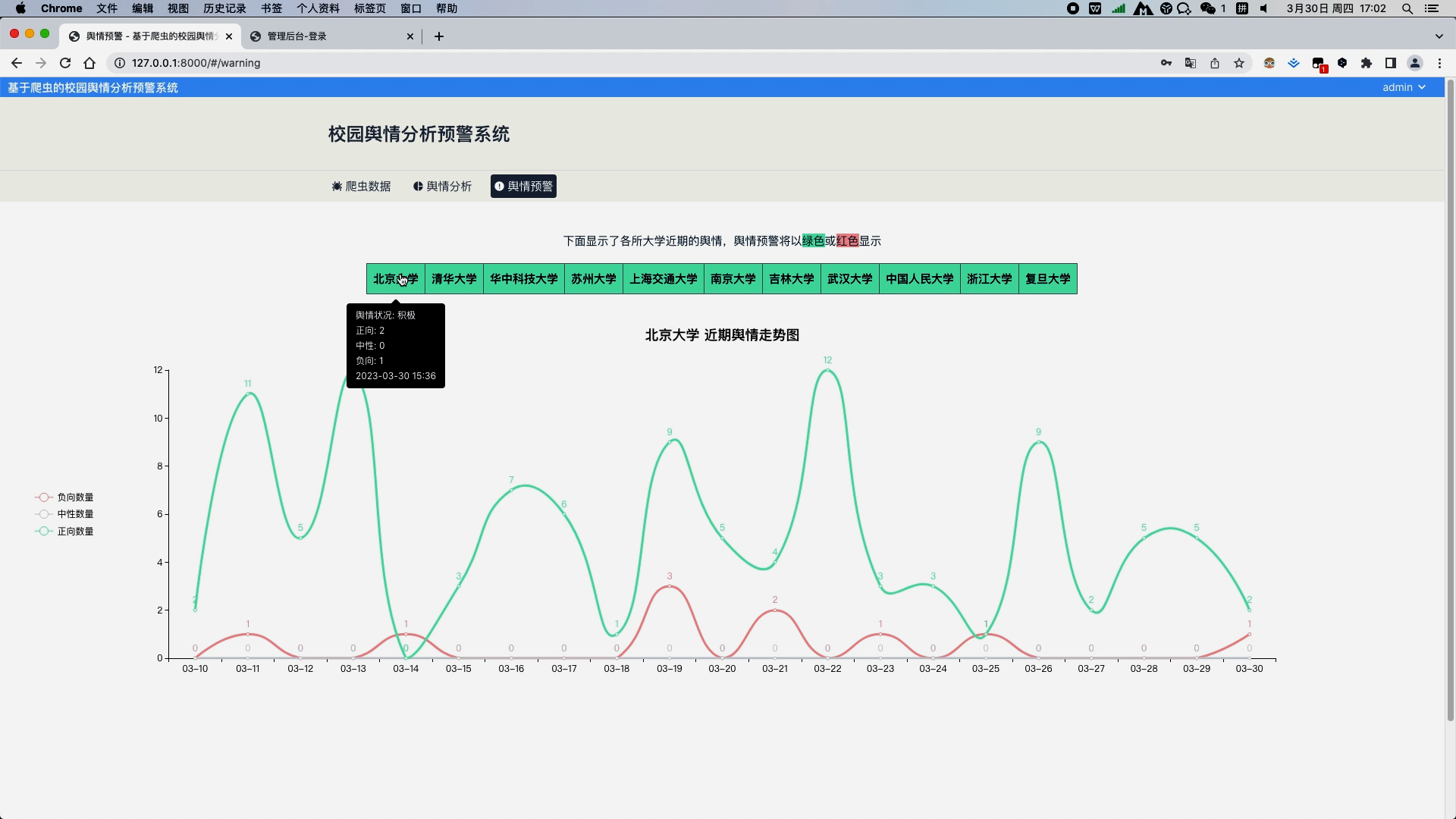
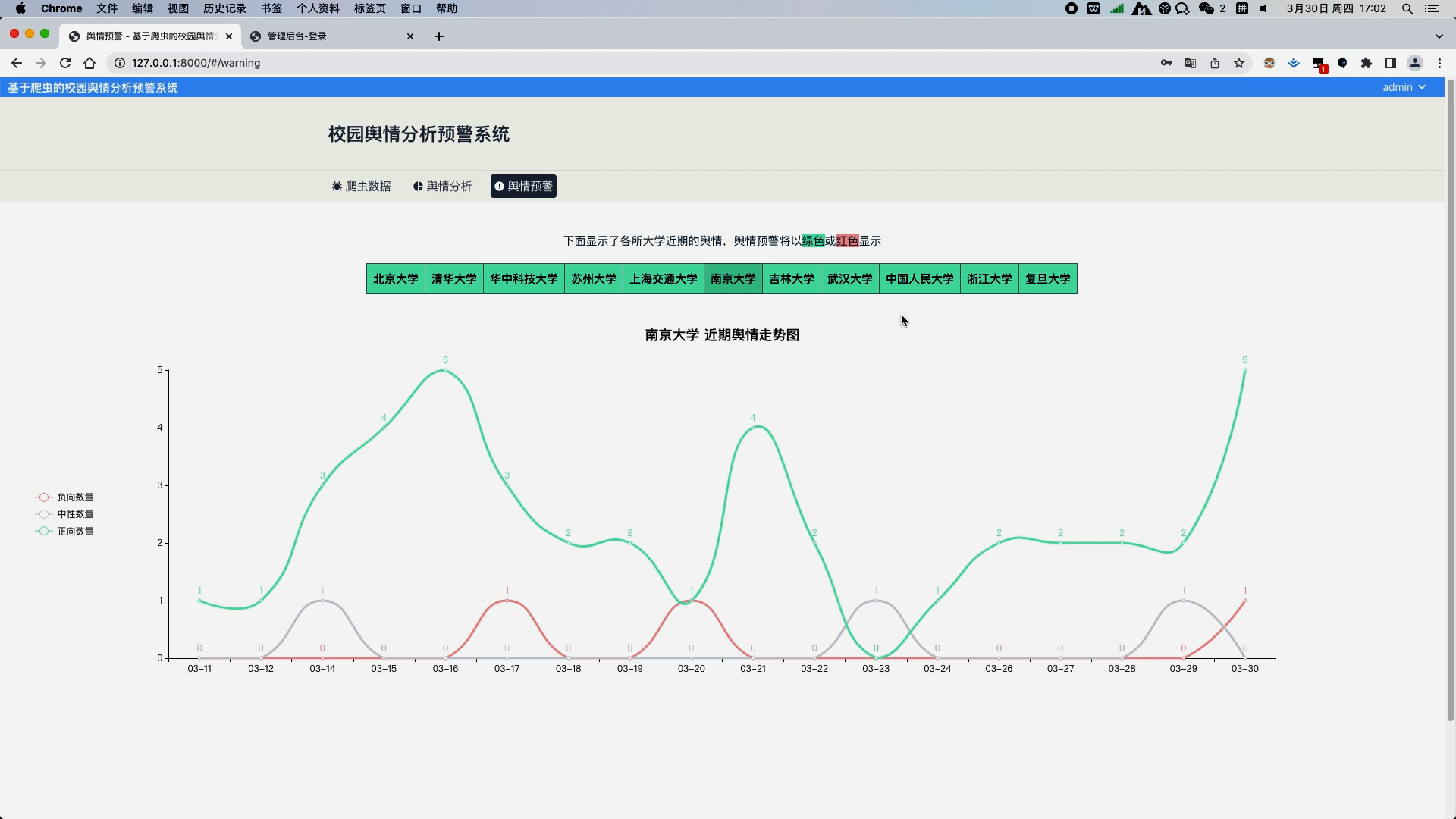
c. 舆情预警模块,列出了各所大学近期的舆情情况,舆情的好坏将以绿色背景或红色背景显示,点击某所大学的时候,可以以线图形式分析出近期该所大学的正负情感的走向,当某天负向情感数量大于正向情感时,将该大学舆情状况标注为坏,用红色背景显示,否则以绿色显示
运行截图

核心算法代码分享如下:
校园舆情分析使用机器学习技术通常涉及文本数据的处理、特征提取、模型训练和预测等步骤。以下是一个简化的Python示例,使用scikit-learn库中的机器学习算法对校园舆情进行情感分析。请注意,由于篇幅和复杂性限制,此示例仅用于展示基本概念和流程,并未涉及复杂的自然语言处理(NLP)步骤或特定于校园舆情的详细特征工程。
准备环境
首先,确保安装了必要的Python库,如scikit-learn、pandas和numpy。可以使用pip安装这些库:
bash复制代码
pip install numpy pandas scikit-learn |
示例代码
以下是一个使用scikit-learn中的逻辑回归(Logistic Regression)模型对校园舆情文本进行情感分类的简单示例。
python复制代码
import pandas as pd | |
from sklearn.model_selection import train_test_split | |
from sklearn.feature_extraction.text import TfidfVectorizer | |
from sklearn.linear_model import LogisticRegression | |
from sklearn.metrics import accuracy_score | |
# 示例数据:这里我们使用虚构的数据来模拟 | |
data = [ | |
("学生对食堂评价很好,饭菜可口。", 1), # 正面情感,标签为1 | |
("图书馆资源太少,难以满足需求。", 0), # 负面情感,标签为0 | |
("老师授课生动有趣,收获颇丰。", 1), # 正面情感,标签为1 | |
("宿舍环境有待改善,噪音大。", 0) # 负面情感,标签为0 | |
] | |
# 将数据转换为DataFrame | |
df = pd.DataFrame(data, columns=['text', 'label']) | |
# 划分训练集和测试集 | |
X_train, X_test, y_train, y_test = train_test_split(df['text'], df['label'], test_size=0.2, random_state=42) | |
# 使用TF-IDF进行文本向量化 | |
vectorizer = TfidfVectorizer() | |
X_train_vec = vectorizer.fit_transform(X_train) | |
X_test_vec = vectorizer.transform(X_test) | |
# 初始化逻辑回归模型 | |
model = LogisticRegression(max_iter=1000) | |
# 训练模型 | |
model.fit(X_train_vec, y_train) | |
# 预测测试集 | |
y_pred = model.predict(X_test_vec) | |
# 评估模型 | |
accuracy = accuracy_score(y_test, y_pred) | |
print(f"Accuracy: {accuracy:.2f}") | |
# 你可以添加更多代码来查看具体预测结果或进行模型调优 |
注意事项
- 数据收集:在实际应用中,你需要从各种来源(如社交媒体、校园论坛、学生反馈等)收集大量的舆情数据。
- 数据预处理:在将文本数据输入到模型之前,需要进行一系列的预处理步骤,如去除停用词、词干提取、拼写校正等。
- 特征工程:除了TF-IDF外,你还可以尝试使用其他特征提取方法,如Word2Vec、BERT等。
- 模型选择:逻辑回归是入门级的分类算法,对于更复杂的任务,你可以考虑使用支持向量机(SVM)、深度学习模型等。
- 模型评估:除了准确率外,你还可以考虑使用精确度、召回率、F1分数等指标来评估模型性能。
- 模型部署:将训练好的模型部署到实际环境中,进行实时或定期的舆情分析。
希望这个示例能帮助你理解如何使用机器学习技术进行校园舆情分析。


















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











