




|
研究目标和解决的主要问题/背景与意义 | |||
|
研究目标:设计并实现一个基于Python和Spark的电影推荐系统。 背景:随着互联网的飞速发展,人们对于电影的数量需求越来越大。要怎么样依据用户的个人喜好,和历史观看以及搜索偏向,来向用户推荐符合他们要求的电影是当前的热点问题。但是,普通的推荐系统普遍面临着数据的低密度性,复位启动等通病。这类型的通病限制的推荐系统对用户习惯的精准把控,会影响系统的推荐精确度和效果。 意义:可以提高系统推荐的精准度的效率 | |||
|
国内外同类研究 /设计/ 创作的现状 | |||
|
在国内,一些互联网公司如腾讯、阿里巴巴、网易等,都在推荐系统方面进行了深入研究和实践。其中,腾讯的推荐系统在国内处于领先地位,其基于Python和Spark的推荐算法已经得到了广泛应用。此外,国内的一些研究机构和高校也在推荐系统方面进行了一些研究和探索。 在国外,一些大型互联网公司如Netflix、Amazon、YouTube等,都在推荐系统方面进行了大量投入和实践。其中,Netflix的推荐算法在全球范围内处于领先地位,其基于Python和Spark的推荐算法已经得到了广泛应用。此外,一些开源的推荐系统框架和库如TensorFlow、Scikit-Learn等,也为推荐系统的设计和实现提供了便利的工具和算法。 | |||
|
构思与(研究)方法 | |||
|
1.数据采集和处理:首先需要采集和处理电影推荐系统的相关数据,包括用户行为数据、电影元数据等。可以采用爬虫技术、数据交换等方式获取数据,并使用Python和Spark进行数据清洗、预处理和特征提取等操作。 2.模型选择和训练:根据采集到的数据,选择适合的推荐算法进行模型训练。可以采用传统的协同过滤算法、基于内容的推荐算法,也可以采用深度学习算法如神经网络等进行模型训练。同时,需要考虑如何优化模型性能,提高推荐准确度和精度。 3.分布式计算:由于电影推荐系统的数据量通常较大,需要进行分布式计算以提高计算效率和性能。可以使用Spark的分布式计算框架进行数据处理和模型训练,实现高效的并行计算。 4.用户画像和行为分析:通过对用户行为数据的分析,建立用户画像,了解用户兴趣和偏好,为推荐算法提供参考。可以采用聚类分析、关联规则等方法进行用户画像和行为分析。 5.推荐结果展示:将推荐结果以一定的方式展示给用户,包括电影列表、评分预测等。可以考虑采用可视化技术如图表、推荐理由等方式提高用户体验。 6.系统评估和优化:根据实际应用场景和用户反馈,对电影推荐系统进行评估和优化。可以采用准确率、召回率等指标对推荐算法进行评估,并通过调整模型参数、优化数据处理流程等方式对系统进行优化。 模块: 1.用户管理模块:这个模块负责处理用户信息的注册、登陆、退出以及用户权限的管理。 2.电影信息库模块:这个模块负责管理电影的基本信息,例如电影名称、导演、演员、类型等。 3.推荐模块:这是系统的核心模块,根据用户的行为和属性,利用推荐算法生成个性化的电影推荐列表。 4.搜索模块:用户可以通过关键词搜索电影,并查看搜索结果。 5.评论模块:用户可以对电影进行评论和评分。 6.统计模块:这个模块负责收集和分析系统的使用数据,例如用户的活跃度、电影的受欢迎程度等,用于优化推荐算法和提高系统性能。 7.通知模块:根据用户的观影历史和偏好,定期向用户推送个性化的电影推荐通知。 8.界面设计模块:负责系统的界面设计,提供友好和易于使用的用户界面。 | |||
|
技术要求/ 难点、关键及创新点 | |||
|
技术要求: Python语言技能:熟悉Python语言的基本语法和常用库,如NumPy、Pandas等。 Spark使用技能:熟悉Apache Spark的基本操作和API,能够使用Spark进行大规模数据的处理和分析。 机器学习技能:了解并能够应用基本的机器学习算法,如协同过滤、内容过滤等。 数据挖掘技能:能够应用数据挖掘技术,如关联规则、聚类等,对用户行为和电影数据进行深入分析。 数据库和SQL技能:熟悉如何使用关系型数据库和SQL语言进行数据管理。 Web开发技能:了解并能够应用基本的Web开发技术,如HTML、CSS、JavaScript等,进行界面设计。 难点: 大规模数据处理:电影推荐系统需要处理大量的用户行为数据和电影数据,如何在保证性能的前提下处理这些数据是一个挑战。 个性化推荐算法:如何设计一个有效的个性化推荐算法,根据用户的行为和偏好生成个性化的电影推荐列表,是一个难题。 用户行为分析:如何从大量的用户行为数据中提取有用的信息,如用户的兴趣爱好、观影习惯等,需要深入的数据分析和挖掘。 界面设计:如何设计一个友好、易用的界面,让用户能够方便地进行电影搜索、评论和查看推荐列表,也是一个挑战。 关键点: 数据预处理:正确地收集和处理用户行为数据和电影数据是构建电影推荐系统的关键。 算法选择:选择适合的电影推荐算法,如协同过滤、内容过滤等,能够大大提高推荐系统的性能。 参数调优:对于选定的推荐算法,需要进行参数调优,以提高推荐的准确性和多样性。 实时更新:为了提供准确的个性化推荐,系统需要能够实时更新用户行为数据和电影数据。 可扩展性:系统需要能够处理日益增长的用户和数据,因此需要设计可扩展的系统架构。 创新点: 混合推荐模型:结合多种推荐算法,如协同过滤、内容过滤、关联规则等,以提高推荐的准确性和多样性。 深度学习模型的应用:使用深度学习模型,如神经网络或卷积神经网络,对用户行为和电影内容进行更深入的分析,以提高推荐的准确性。 用户反馈机制:根据用户的反馈,不断调整和优化推荐算法,提高用户满意度。 | |||
|
进度安排 / 实施计划、进度、论文大纲 | |||
|
(一)进度安排/实施计划 2023年11月:毕设选题汇总、审核、完成开题报告。 2023年12月:开题答辩。 2024年1月:完成毕业设计作品。 2024年2-4月:完成毕业设计报告并通过知网查重。 2023年5月:完成毕展和毕业设计答辩。 (二) 论文大纲: 1.引言 介绍项目的背景和意义* 描述项目的目标和需求 2.相关工作和文献综述 介绍相关的研究工作和已有的成果* 阐述本项目的创新点和贡献 3.数据收集和处理 描述数据来源和收集过程* 介绍数据清洗和预处理的方法和技术 4.特征提取和选择 描述电影特征和用户特征的提取方法* 介绍特征选择的方法和算法 5.模型设计和实现 描述选择的推荐算法和模型设计思路* 详细介绍模型的实现过程、参数设置和优化方法等 6.系统集成和测试结果分 | |||
|
参考作品与文献 | |||
|
[1]刘念,蔡春花.基于Spark的电影推荐系统的设计与实现[J].软件工程,2023,26(06):59-62+45.DOI:10.19644/j.cnki.issn2096-1472.2023.006.013 [2]黄宏昆,彭明.深度学习和Spark在电影推荐系统上的应用[J].福建电脑,2023,39(02):17-20.DOI:10.16707/j.cnki.fjpc.2023.02.004 [3]张坤.基于Spark机器学习的电影推荐系统的设计与实现[D].南京邮电大学,2022.DOI:10.27251/d.cnki.gnjdc.2022.000686 [4]朱本瑞.基于Spark的离线与实时的电影推荐系统设计与实现[D].南京信息工程大学,2022.DOI:10.27248/d.cnki.gnjqc.2022.000497 [5]赖丽君.基于Spark框架的电影推荐系统的实现[J].鄂州大学学报,2021,28(02):98-101.DOI:10.16732/j.cnki.jeu.2021.02.032 [6]吴猛华.基于协同过滤的影视推荐系统设计与实现[D].华东师范大学,2022.DOI:10.27149/d.cnki.ghdsu.2022.004571 [7]刘亮均,杨柳.电影推荐系统的设计与实现[J].物联网技术,2021,11(03):86-88+92.DOI:10.16667/j.issn.2095-1302.2021.03.026 [8]孟晓哲.基于Spark平台推荐算法的研究与实现[D].大连交通大学,2022.DOI:10.26990/d.cnki.gsltc.2022.000582 [9]徐必成.基于混合方法的电影推荐系统的研究与实现[D].湖南大学,2022.DOI:10.27135/d.cnki.ghudu.2022.003890 [10]孟晓哲.基于Spark平台推荐算法的研究与实现[D].大连交通大学,2022.DOI:10.26990/d.cnki.gsltc.2022.000582 | |||
|
指导教师意见(对本课题深度、广度的意见) | |||
|
是否同意开题答辩 |
ž同意 不同意 | ||
|
指导教师签字 |
日期 | ||
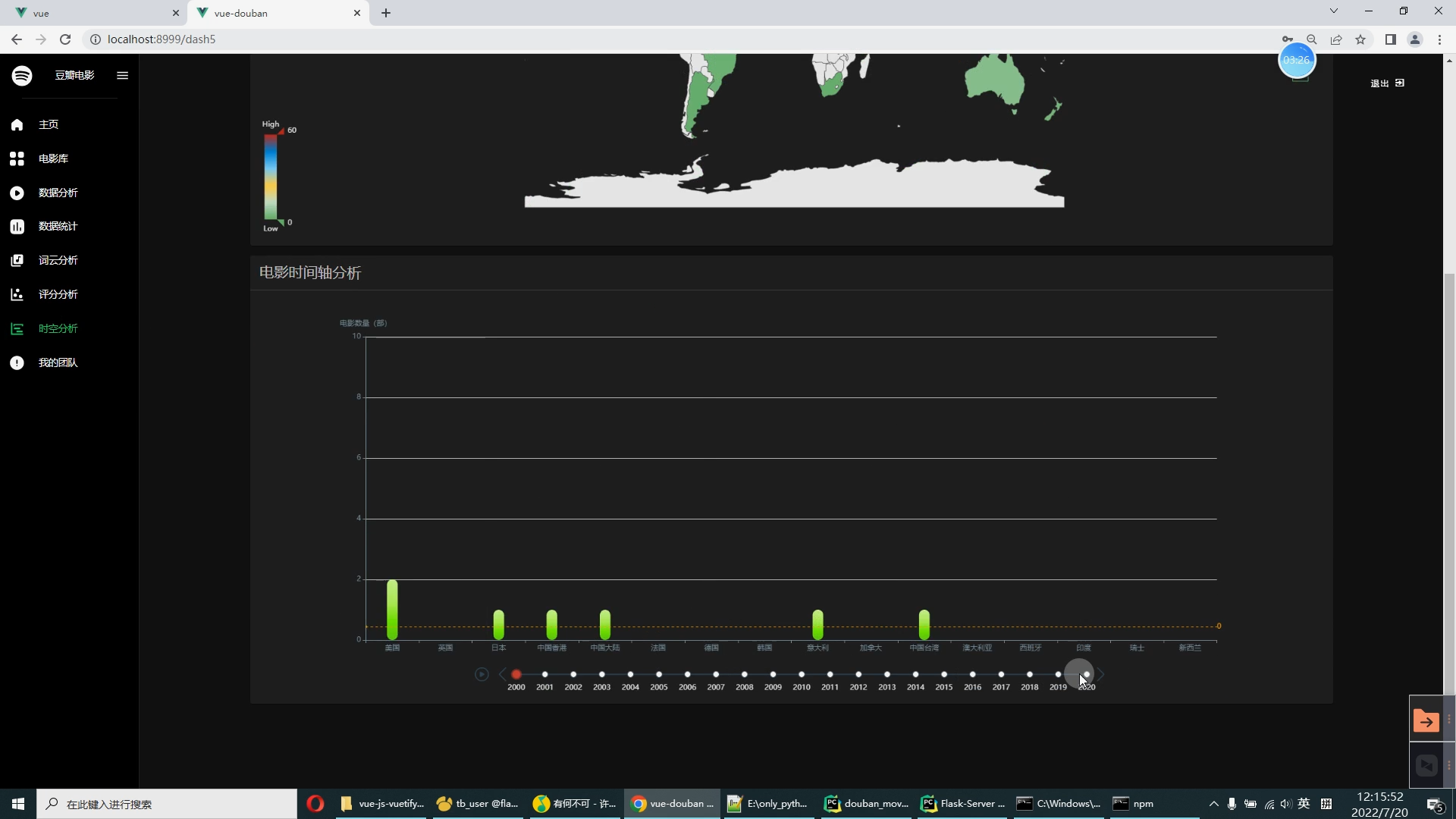
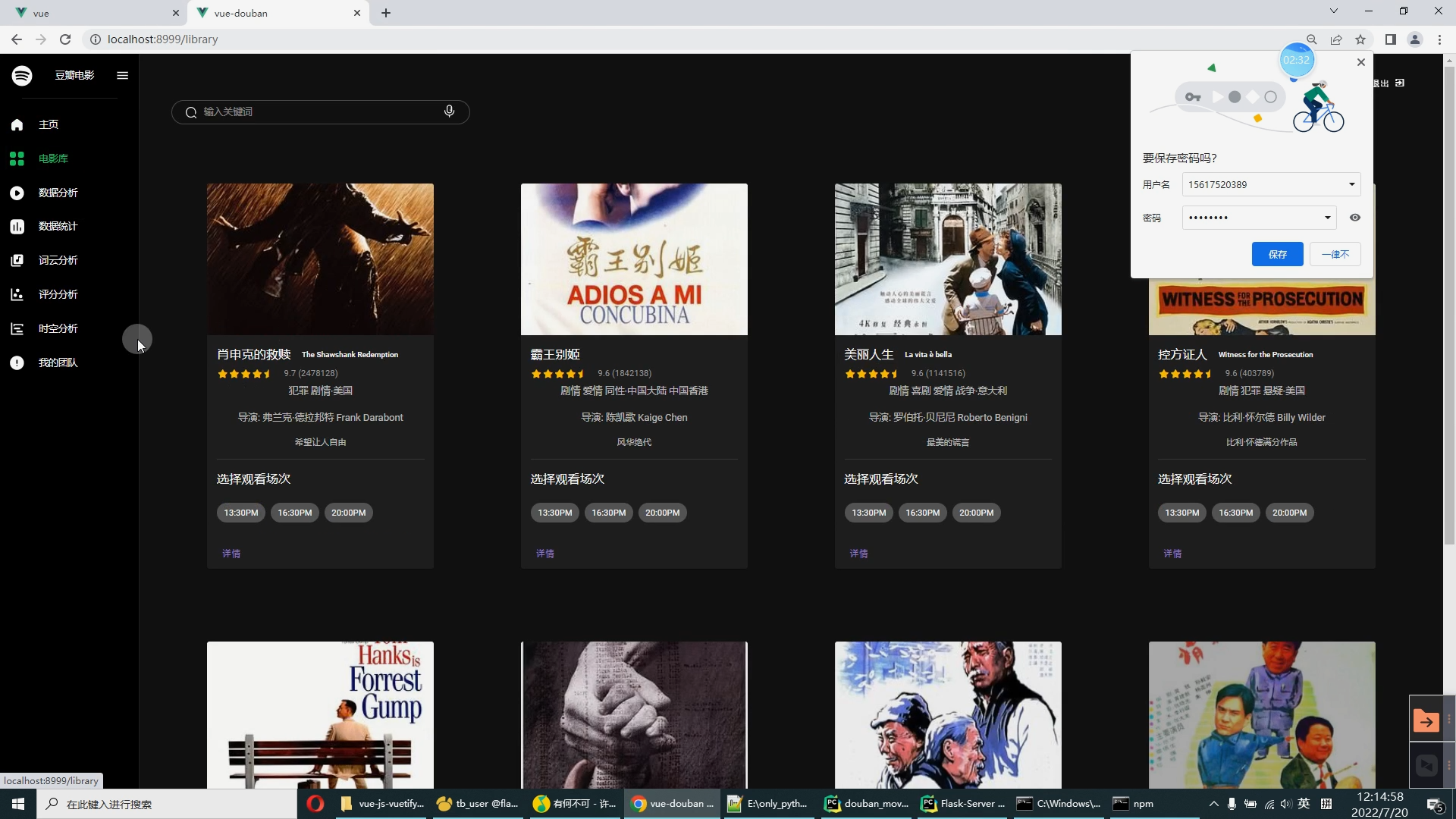
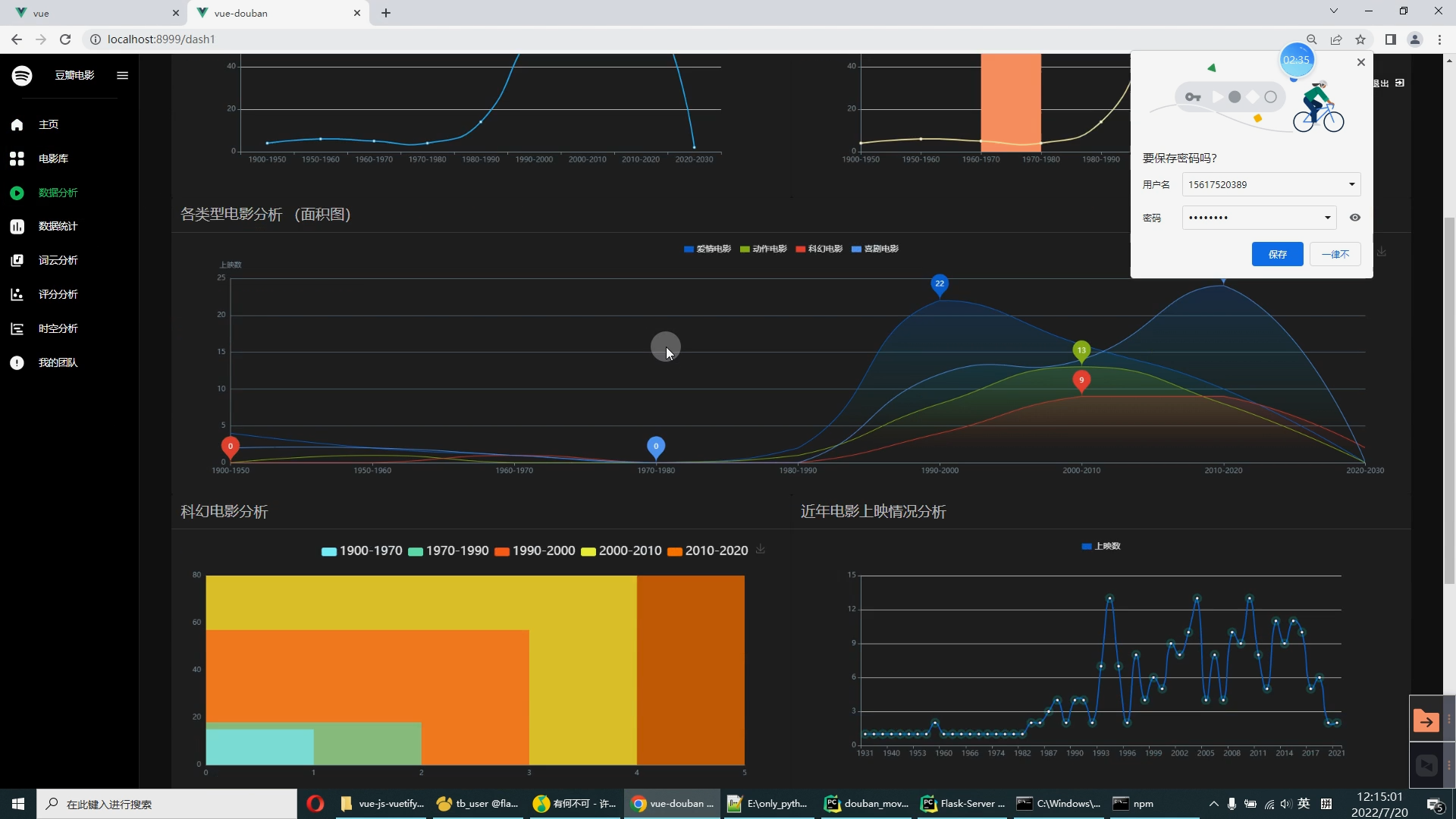
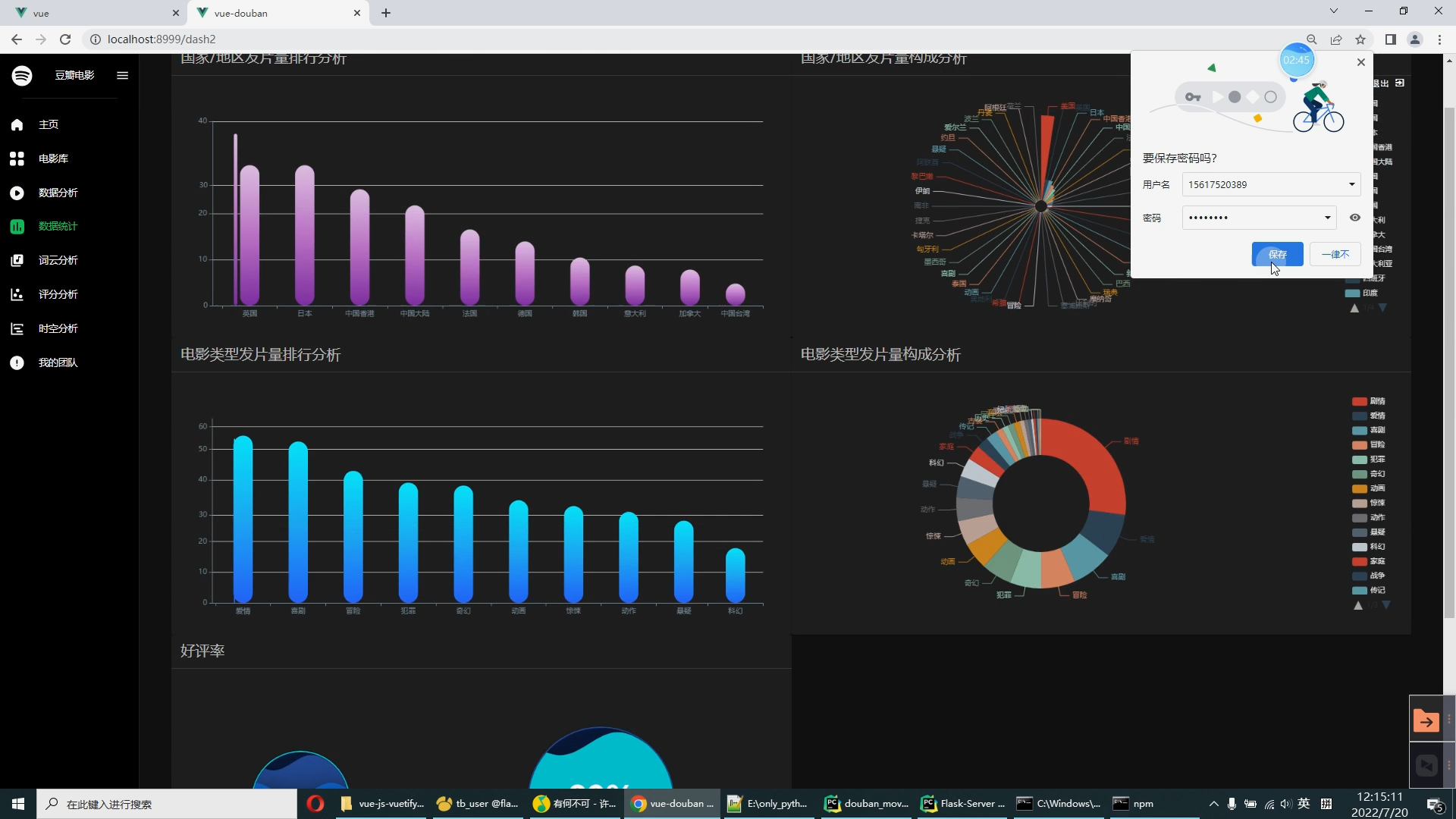
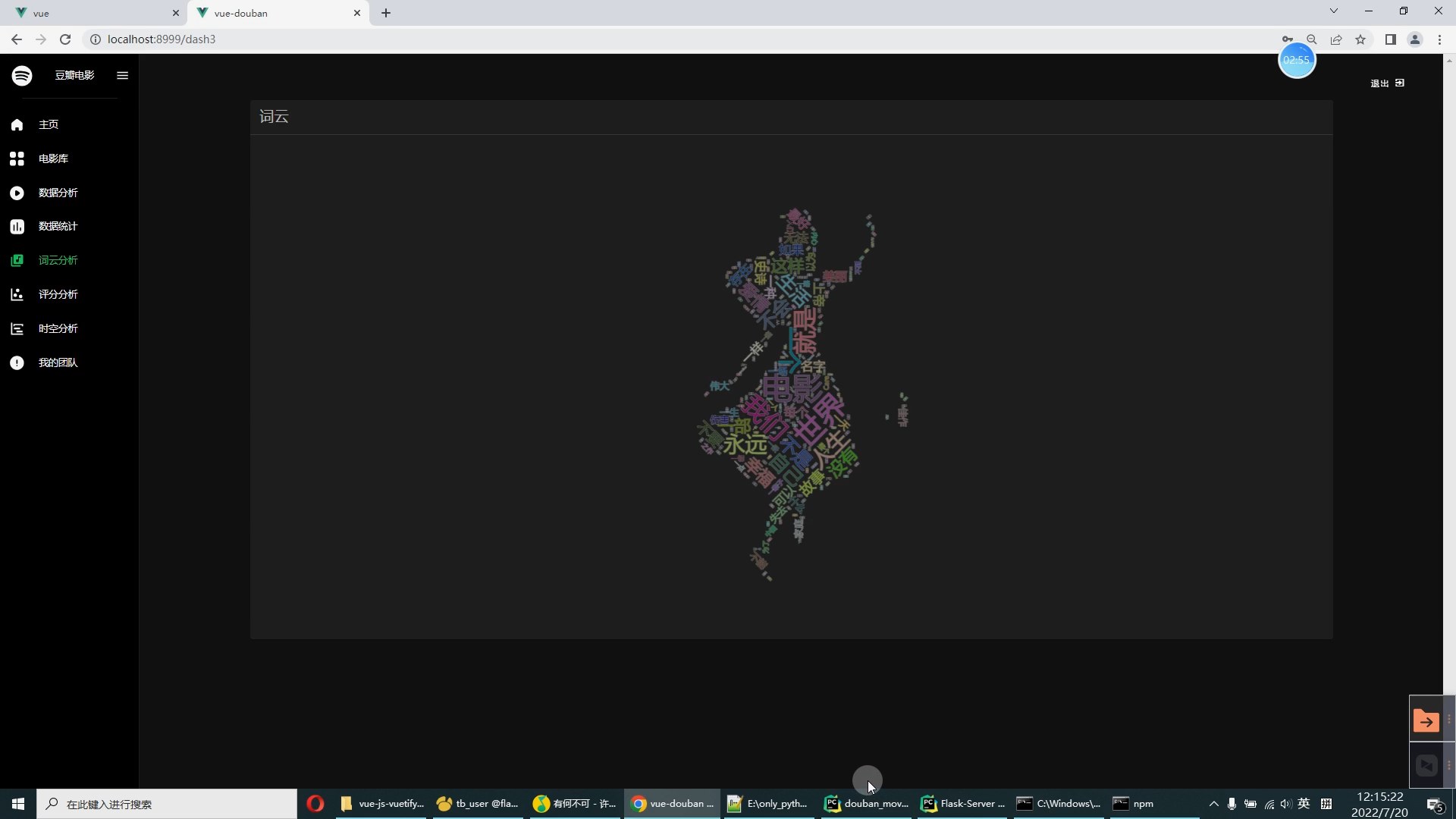

核心算法代码分享如下:
# -*- coding: utf-8 -*-
import scrapy
import numpy as np
from faker import Factory
from douban_movie.dns_cache import _setDNSCache
from douban_movie.items import DoubanMovieItem, DoubanMovieCommentItem, DoubanMovieUser
# import urlparse # python2.x
from urllib import parse as urlparse # python3.x
f = Factory.create()
class DoubanCommentSpider(scrapy.Spider):
def __init__(self, pages = 1000):
"""初始化起始页面
"""
super(DoubanCommentSpider, self).__init__()
self.pages = int(pages) -1 #参数pages由此传入, 表示点击下一页的次数
self.page = 0
self.url_set = [] #话题url的集合
#self.start_urls = ['http://buluo.qq.com/p/barindex.html?bid=%s' % bid]
#self.allowed_domain = 'buluo.qq.com'
#self.driver = webdriver.Firefox()
#self.driver.set_page_load_timeout(5)
#throw a TimeoutException when thepage load time is more than 5 seconds.
name = 'douban-comment20'
allowed_domains = ['accounts.douban.com', 'douban.com','movie.douban.com']
start_urls = [
'xxxxxxxxxxxxxxxxxxxxxxxx'
]
custom_settings = { # 自定义该spider的pipeline输出
'ITEM_PIPELINES': {
'douban_movie.pipelines.MovieCommentPipeline20': 1,
},
'DOWNLOAD_DELAY': 2.0,
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection': 'keep-alive',
'Host': 'accounts.douban.com',
'User-Agent': f.user_agent()
}
formdata = {
'form_email': '15617520389@163.com',
'form_password': 'yl168168...',
# 'captcha-solution': '',
# 'captcha-id': '',
'login': '登录',
'redir': 'xxxxxxxxxxxx',
#'redir': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'source': 'None'
}
def start_requests(self):
return [scrapy.Request(url='xxxxxxxxxxxxxxxxxxxxxxxx',
headers=self.headers,
meta={'cookiejar': 1},
callback=self.parse_login)]
def parse_login(self, response):
# 如果有验证码要人为处理
print('Loging...')
link = response.xpath('.//img[@id="captcha_image"]/@src').extract()
if len(link) > 0:
print("此时有验证码")
#if 'captcha_image' in response.body:
print('Copy the link:')
#link = response.xpath('//img[@id="captcha_image"]/@src').extract()[0]
print(link)
captcha_solution = input('captcha-solution:')
captcha_id = urlparse.parse_qs(urlparse.urlparse(link[0]).query, True)['id']
self.formdata['captcha-solution'] = captcha_solution
self.formdata['captcha-id'] = captcha_id
return [scrapy.FormRequest.from_response(response,
formdata=self.formdata,
headers=self.headers,
meta={'cookiejar': response.meta['cookiejar']},
callback=self.after_login
)]
def after_login(self, response):
print(response.status)
print('after_login!')
_setDNSCache()
print()
self.headers['Host'] = "movie.douban.com"
movie_id = np.loadtxt('movie_id.out', dtype='i').tolist()[:20] # Top250
for mid in movie_id:
yield scrapy.Request(url='xxxxxxxxxxxxxxxxxxxxxxxx%s/comments' % mid,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
callback=self.parse_comment_url)
yield scrapy.Request(url='xxxxxxxxxxxxxxxxxxxxxx/comments' % mid,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
callback=self.parse_next_page,
dont_filter = True)
def parse_next_page(self, response):
#print(response.status)
print('Next_page!')
print()
_setDNSCache()
next_url = response.urljoin(response.xpath('//a[@class="next"]/@href').extract()[0])
self.url_set.append(next_url)
try:
#next_url = response.urljoin(response.xpath('//a[@class="next"]/@href').extract()[0])
if next_url and ( self.page < self.pages):
self.page += 1
## 将 「下一页」的链接传递给自身,并重新分析
yield scrapy.Request(url=next_url,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
callback=self.parse_next_page,
dont_filter = True)
else:
print('No more pages!')
#with open('url_set.txt', mode='w') as f:
# f.write(self.url_set)
print(self.url_set)
for url in self.url_set:
yield scrapy.Request(url=url,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
callback=self.parse_comment_url#,
#dont_filter = True
)
except:
print("Next page Error")
print(response.status)
print(response.urljoin(response.xpath('//a[@class="next"]/@href').extract()))
return
def parse_comment_url(self, response):
#print(response.status)
print('comment_url!')
_setDNSCache()
print()
comment = DoubanMovieCommentItem()
comment['movie_id'] = response.xpath('//div[@class="fright"]/a/@name').extract()
comment['URL'] = response.url
for item in response.xpath('//div[@class="comment-item"]'):
# 短评的唯一id
comment['comment_id'] = int(item.xpath('div[@class="comment"]/h3/span[@class="comment-vote"]/input/@value').extract()[0].strip())
# 多少人评论有用
comment['useful_num'] = item.xpath('div[@class="comment"]/h3/span[@class="comment-vote"]/span/text()').extract()[0].strip()
# 评分
comment['star'] = item.xpath('div[@class="comment"]/h3/span[@class="comment-info"]/span[2]/@class').extract()[0].strip()
# 评论时间
comment['time'] = item.xpath('div[@class="comment"]/h3/span[@class="comment-info"]/span[@class="comment-time "]/@title').extract()
# 评论内容
comment['content'] = item.xpath('div[@class="comment"]/p/text()').extract()
# 评论者名字(唯一)
comment['people'] = item.xpath('div[@class="avatar"]/a/@title').extract()[0]
# 评论者页面
comment['people_url'] = item.xpath('div[@class="avatar"]/a/@href').extract()[0]
# 已摒弃
#url = item.xpath('div[@class="avatar"]/a/@href').extract()[0]
#movie_url = item.xpath('//p[@class="pl2"]/a/@href').extract()[0]
yield comment


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











