




 本文描述了西安工程大学计算机科学学院一名学生针对海量视频数据的毕业设计,将构建一个基于Hadoop和Spark的视频推荐系统,通过Python爬虫抓取和处理数据,实现个性化推荐、视频分析等功能。项目将探索大数据处理技术在视频推荐中的应用和优化算法。
本文描述了西安工程大学计算机科学学院一名学生针对海量视频数据的毕业设计,将构建一个基于Hadoop和Spark的视频推荐系统,通过Python爬虫抓取和处理数据,实现个性化推荐、视频分析等功能。项目将探索大数据处理技术在视频推荐中的应用和优化算法。
西安工程大学本科毕业设计(论文)开题报告
学院:计算机科学学院 专业: 填表时间:2023年3月28日
|
姓 名 |
班级 |
学号 | |||
|
题 目 |
基于hadoop+spark的动漫视频推荐系统 | ||||
|
选题的意义: 随着互联网的快速发展,人们面临着海量的视频内容,如何从这些繁杂的视频中找到自己感兴趣的内容成为一个重要的问题。推荐系统作为一种解决信息过载问题的重要工具,能够根据用户的历史行为和偏好,预测用户可能感兴趣的内容,并对其进行推荐。在视频推荐领域,基于Hadoop和Spark的大数据框架的应用越来越广泛,它们能够处理大规模的视频数据,并对其进行深入的分析和挖掘。 本文旨在研究并设计一个基于Hadoop+Spark的视频推荐系统,该系统能够有效地利用大数据技术,对海量的视频数据进行处理和分析,并根据用户的行为和偏好进行视频推荐。与传统的推荐系统相比,基于Hadoop+Spark的视频推荐系统具有更高的处理能力和准确性,能够提供更加个性化的视频推荐服务。 | |||||
|
研究综述: 在基于Hadoop和Spark的视频推荐系统方面,一些国内外的研究机构和企业在大数据处理和分析方面进行了深入研究,并取得了一定的成果。例如,国外的Netflix利用Hadoop和Spark构建了一个大规模的推荐系统,能够处理海量的用户行为数据和视频数据,并为其用户推荐相关的视频内容。在国内,一些企业如阿里巴巴、腾讯等也在大数据处理和分析方面进行了深入研究,并推出了一些基于Hadoop和Spark的大数据产品和服务。 综上所述,推荐系统在国内外得到了广泛应用,不仅在视频领域,还在其他领域得到应用。在基于Hadoop和Spark的视频推荐系统方面,一些国内外的研究机构和企业已经取得了一定的成果,但是随着大数据技术的不断发展,还需要进一步研究和探索更加准确、高效的视频推荐算法和系统。 | |||||
|
论文(设计)写作提纲:
| |||||
|
研究工作进度安排: (根据学校安排自行修改) 1、查阅资料,拟定写作大纲,完成研究内容、现状、方法的研究等,提交开题报告; 2、基本完成毕业设计及毕业论文草稿的撰写; 3、提交中期检查相关资料,参加中期检查; 4、修改完善毕业设计,完成毕业设计和论文定稿的撰写; 5、提交答辩申请,参加答辩; 6、提交论文最终稿,打印装订论文,整理并上交全套毕业论文(设计)资料。 |
|
参考文献目录: [1] 基于短视频内容理解的用户偏好预测模型研究[D]. Muhammad Irbaz Siddique.北京交通大学,2023 [2] 基于人像聚类的短视频推荐系统的研究与实现[D]. 郝艳峰.辽宁大学,2022 [3] 基于前景理论的视频推荐方法研究[D]. 李天鹏.河南财经政法大学,2021 [4] 高校视频公开课点播平台智能推荐系统的设计与实现[D]. 陈汉福.华南理工大学,2022 [5] 基于物品协同过滤的个性化视频推荐算法改进研究[D]. 卜旭松.宁夏大学,2021 [6] 基于图论的个性化视频推荐算法研究[D]. 陈壁生.华南理工大学,2023 [7] 基于深度观看兴趣网络的视频推荐系统设计与实现[D]. 刘端阳.北京邮电大学,2021 |
|
指导教师意见: 签名: 2023年3月 29日 |
|
教研室主任意见: 签名: 2023年3 月29日 |
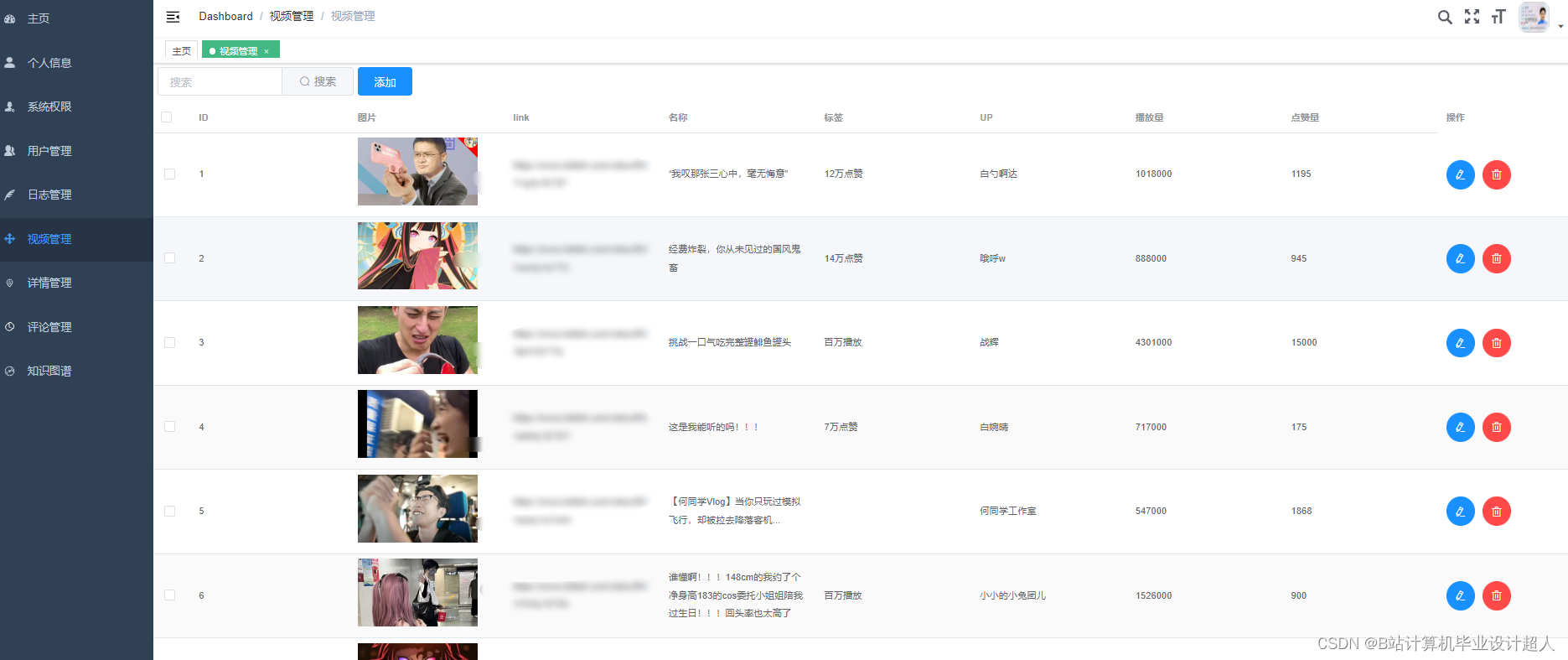
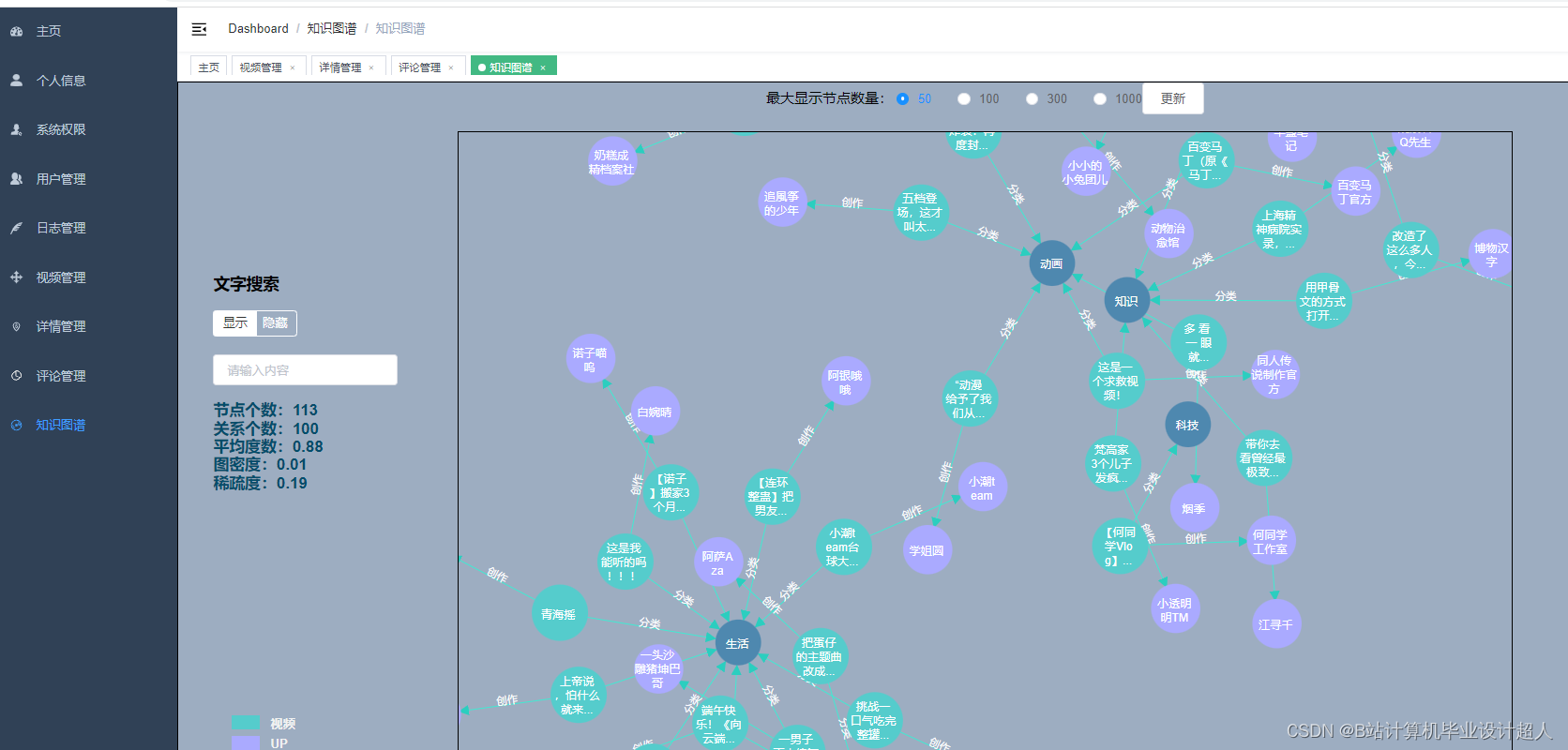
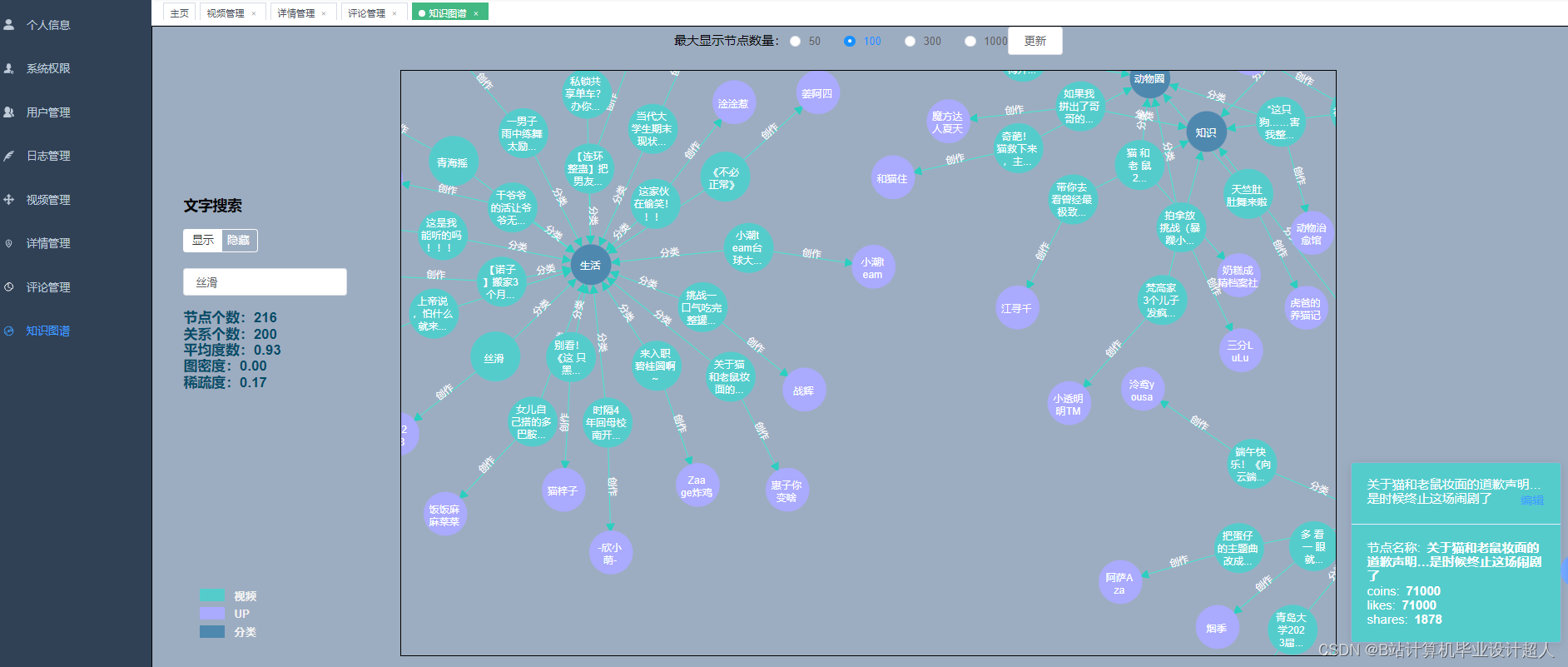
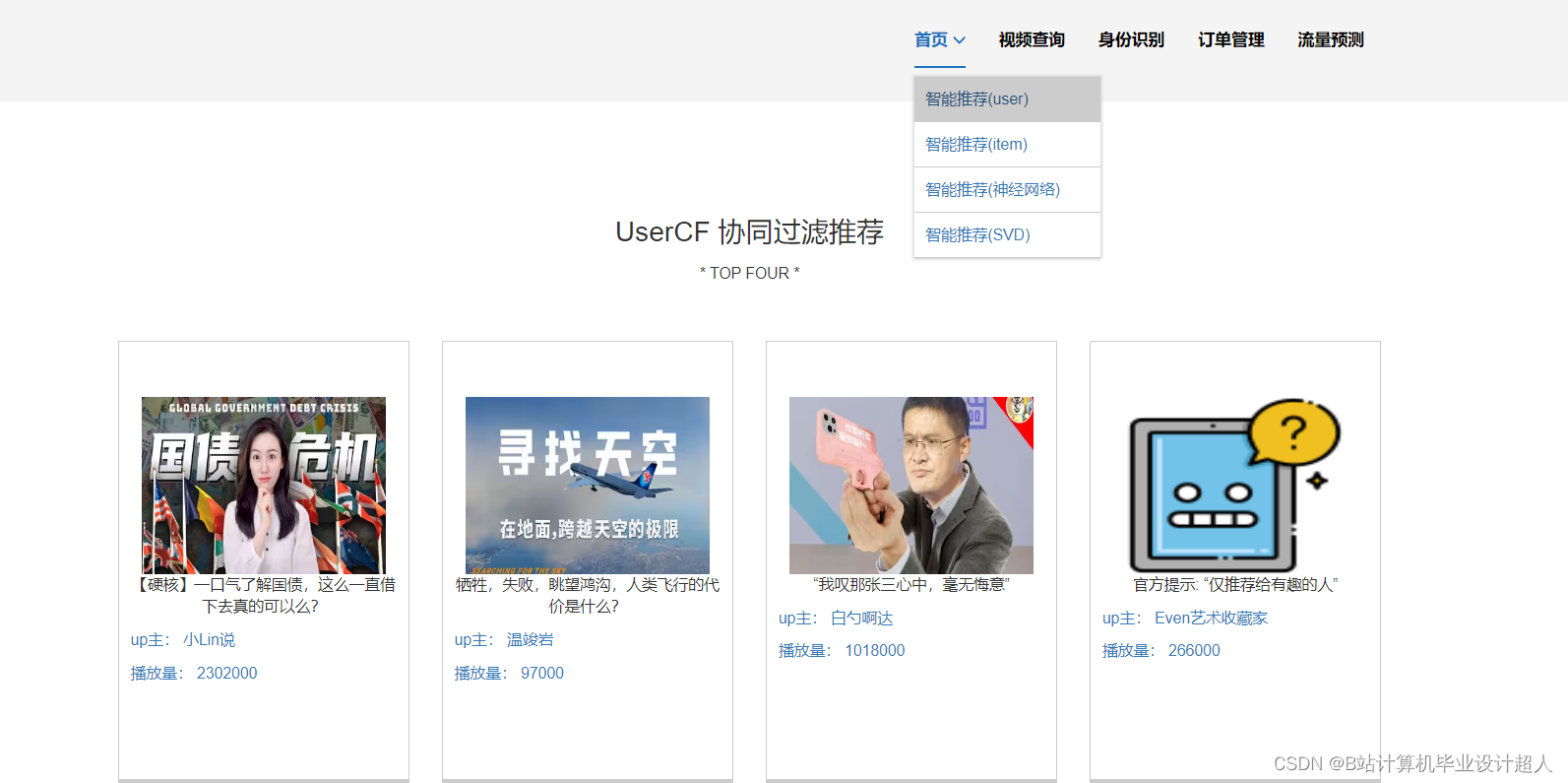
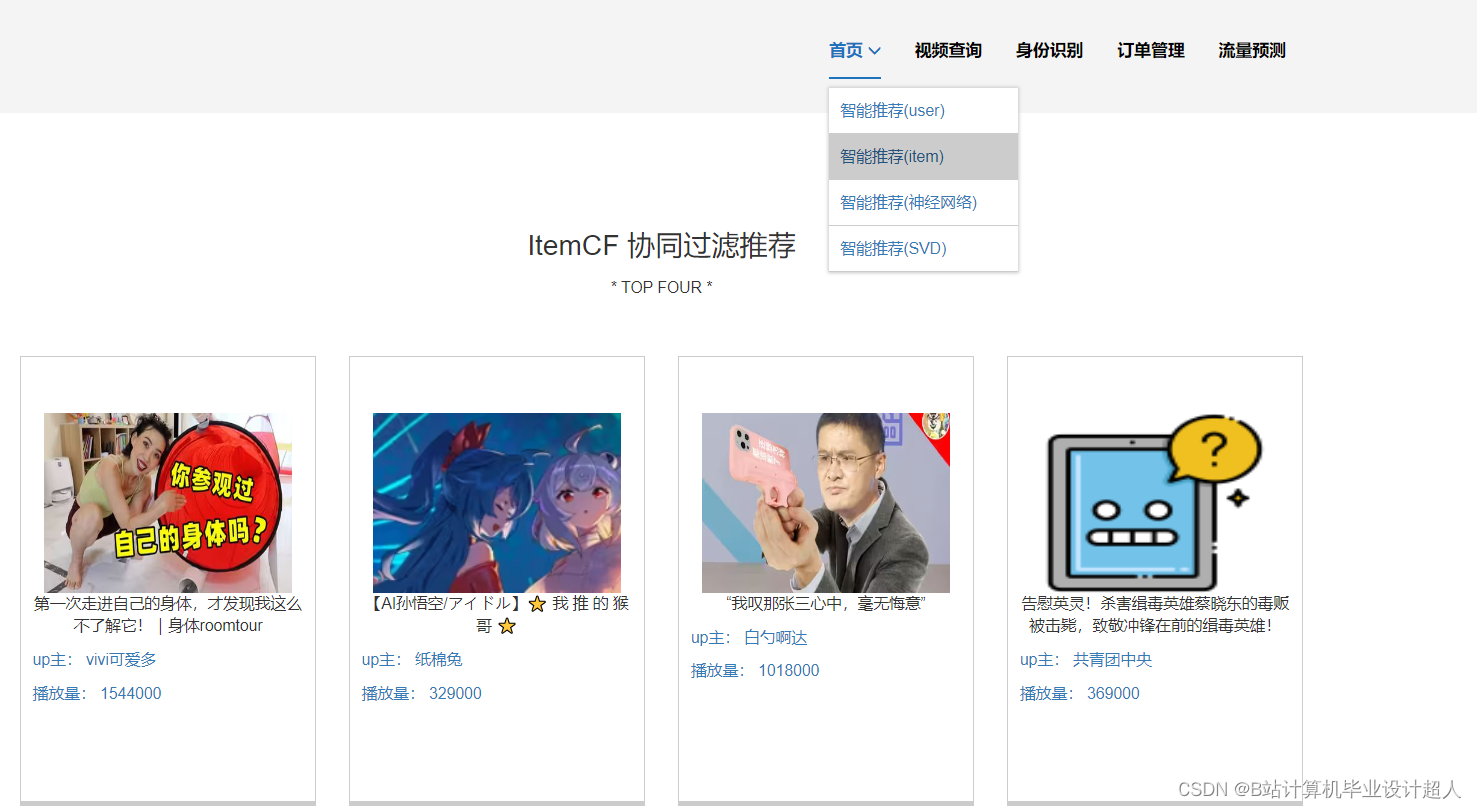
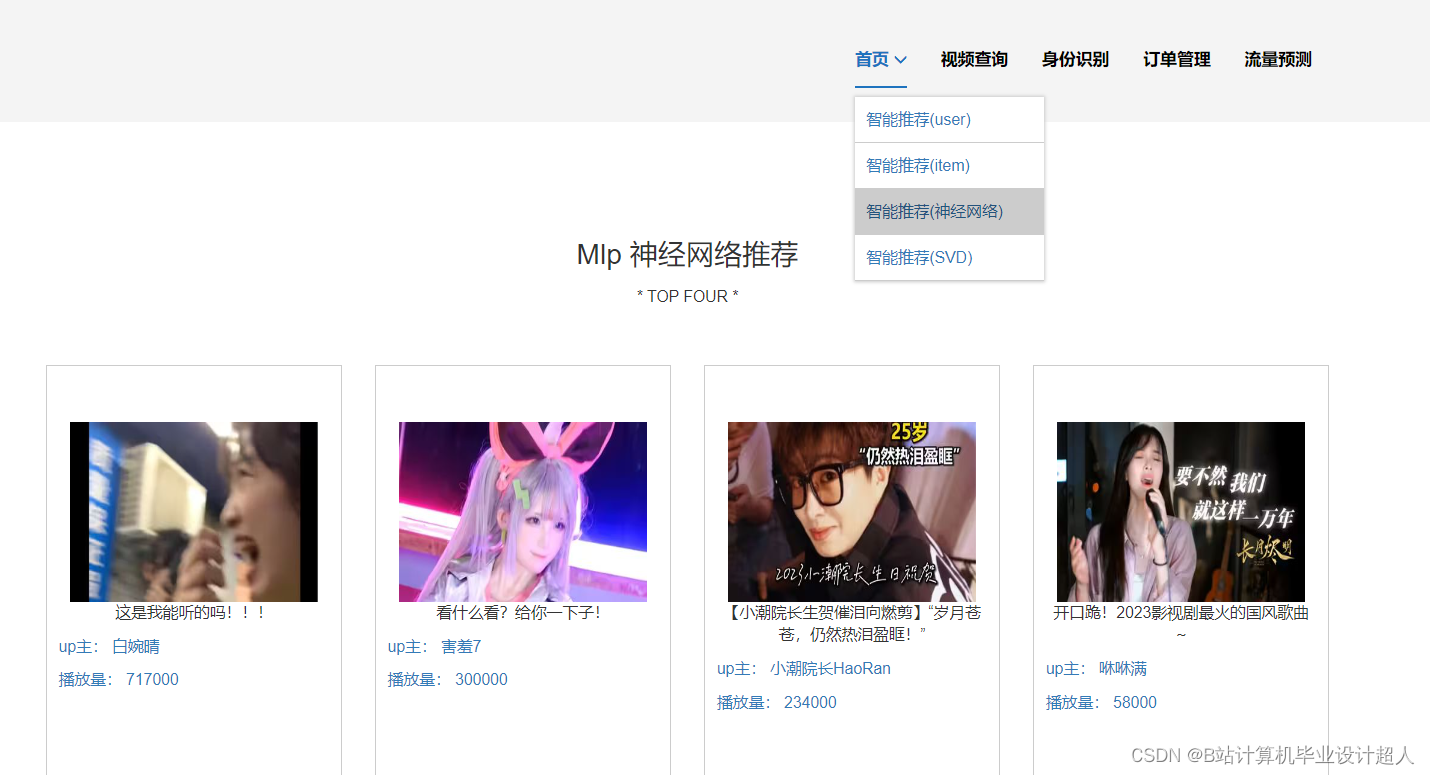
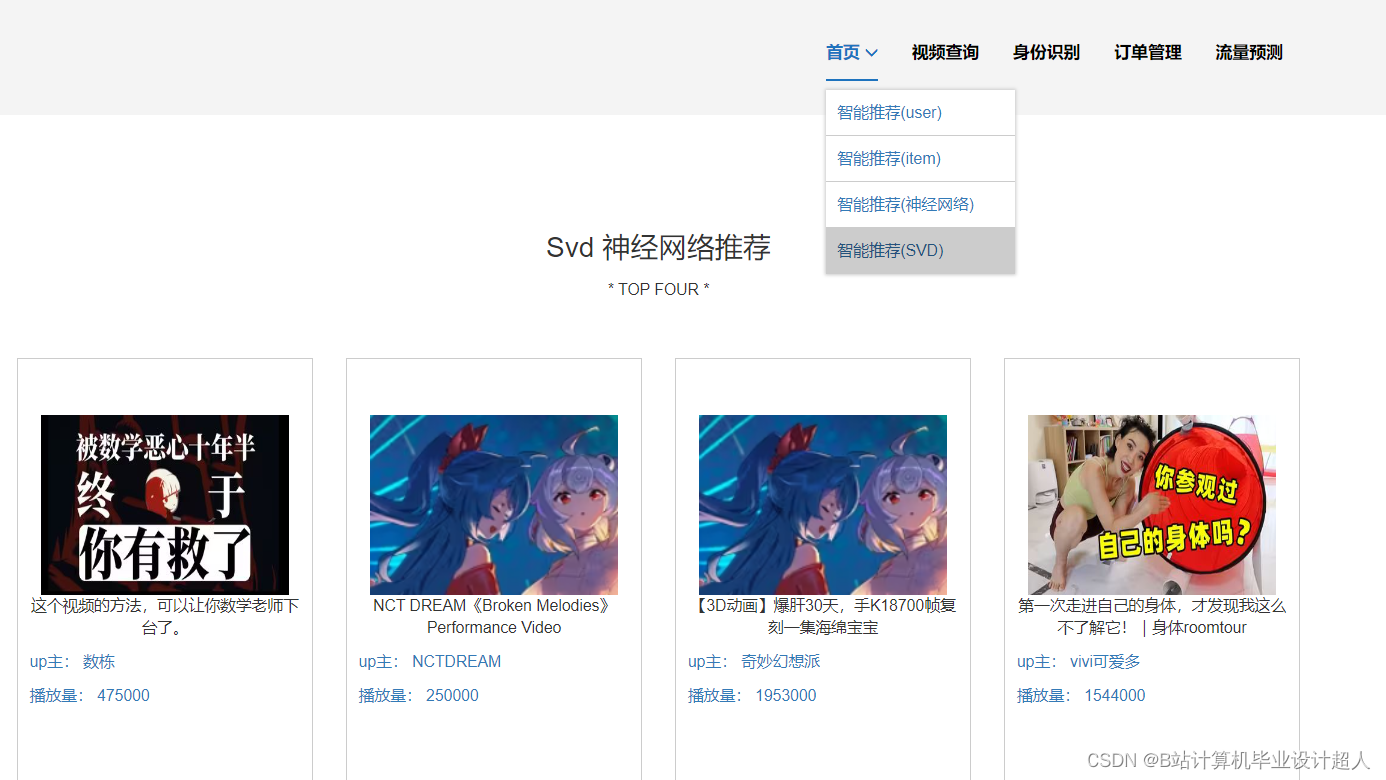
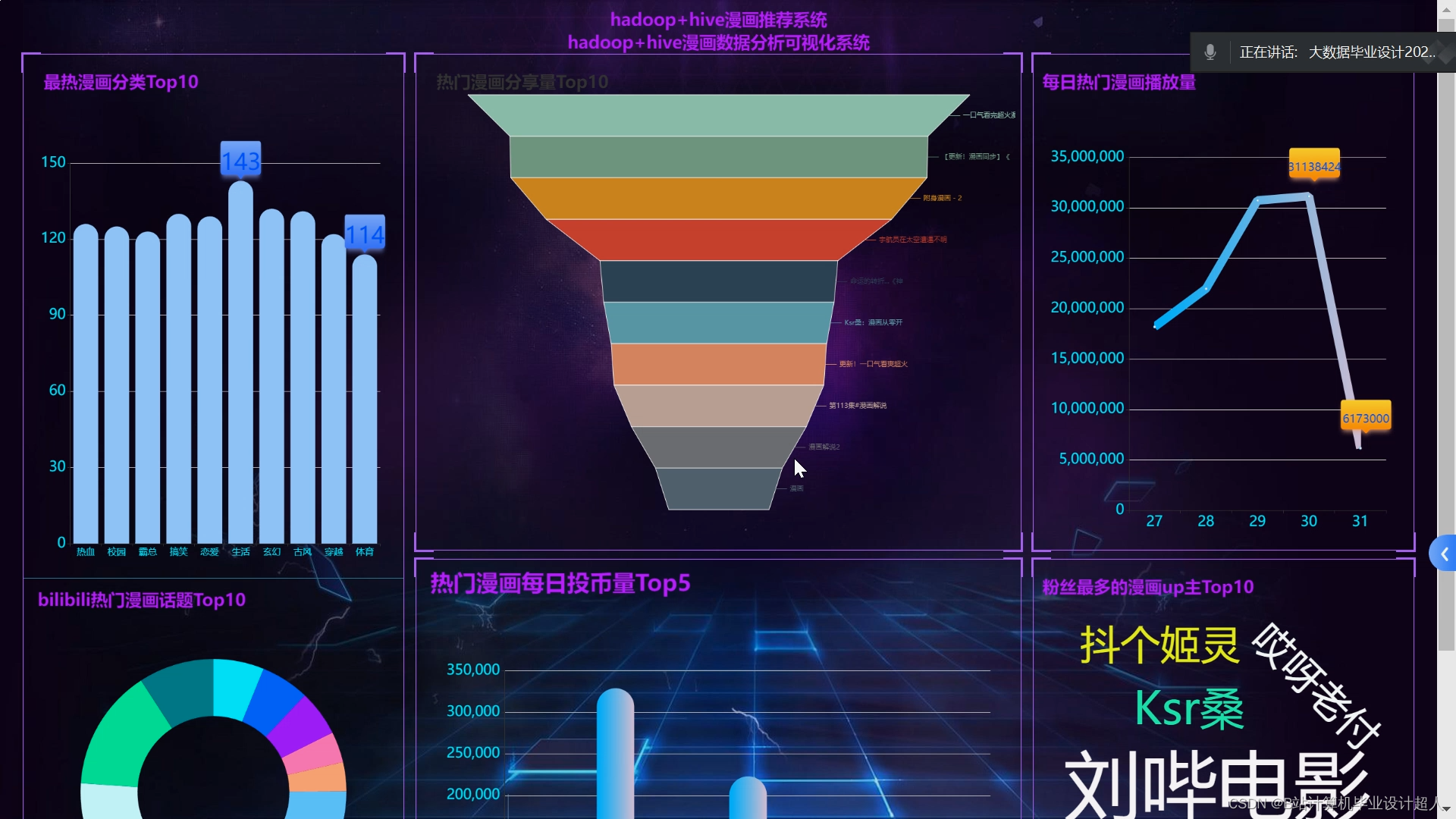
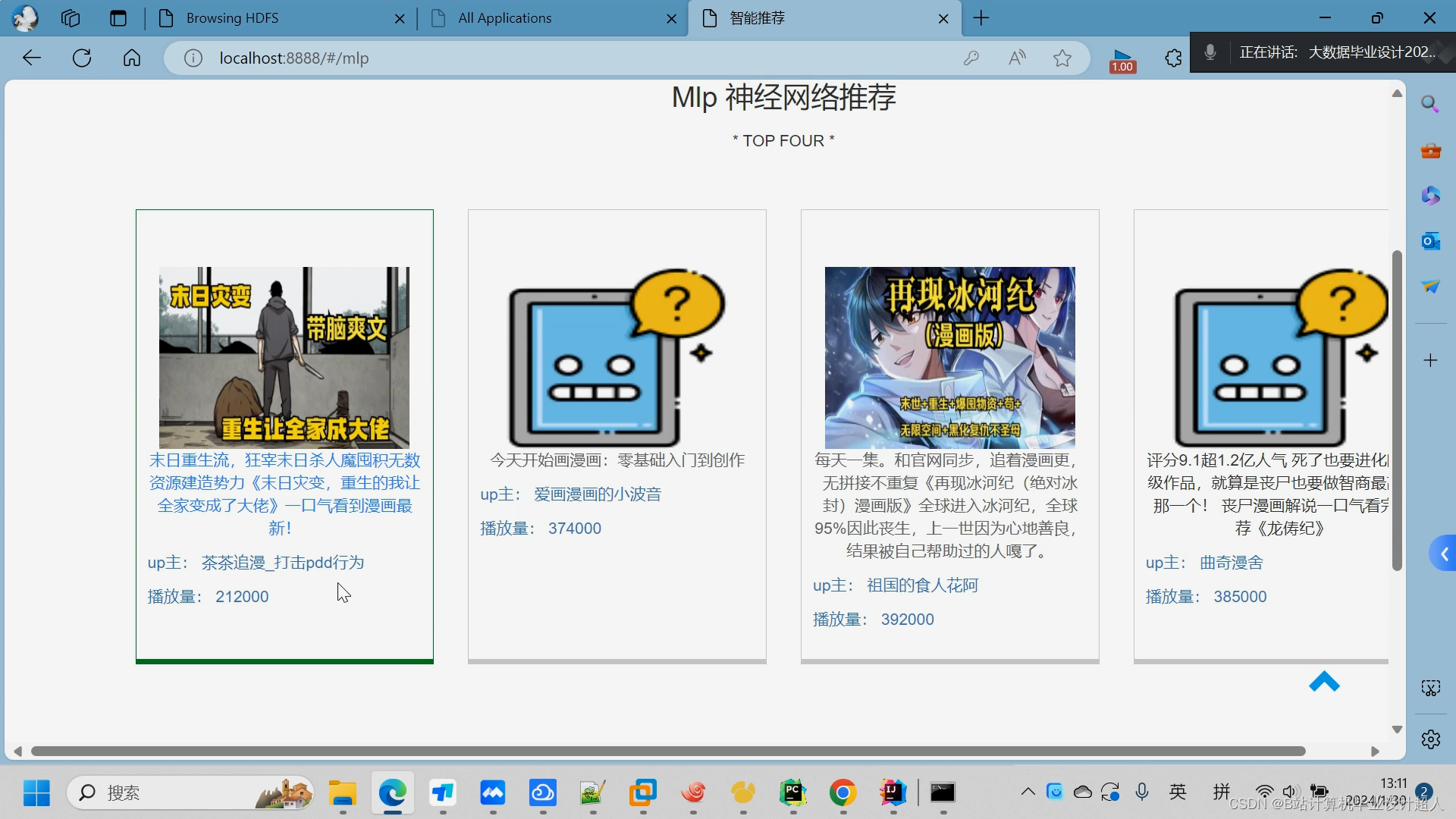
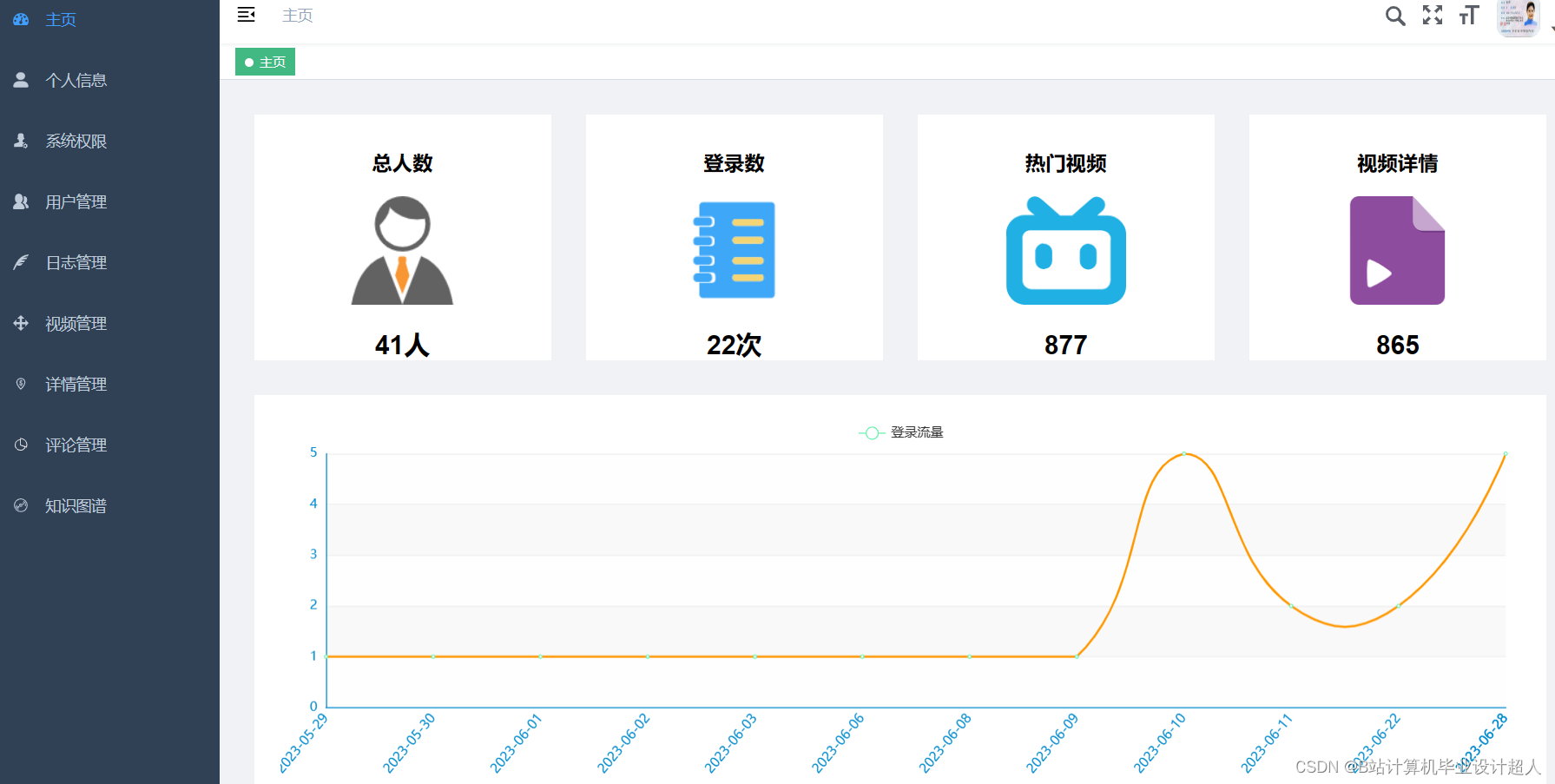
核心算法代码分享如下:
from flask import Flask, request
import json
from flask_mysqldb import MySQL
import io, sys
# 创建应用对象
app = Flask(__name__)
app.config['MYSQL_HOST'] = 'bigdata'
app.config['MYSQL_USER'] = 'root'
app.config['MYSQL_PASSWORD'] = '123456'
app.config['MYSQL_DB'] = 'hive_zymk'
mysql = MySQL(app) # this is the instantiation
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
@app.route('/tables01')
def tables01():
cur = mysql.connection.cursor()
cur.execute('''select * from (SELECT * FROM tables01 order by ctime desc limit 7) tt order by tt.ctime asc ''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables05')
def tables05():
cur = mysql.connection.cursor()
cur.execute('''select * from tables05 limit 5''')
#cur.execute('''SELECT * FROM tables05 ''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables06')
def tables06():
cur = mysql.connection.cursor()
cur.execute('''select * from tables06 limit 5''')
#cur.execute('''SELECT * FROM tables05 ''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables03')
def tables03():
cur = mysql.connection.cursor()
cur.execute('''select * from tables03 ''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables02')
def tables02():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM tables02''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables04')
def tables04():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM tables04''')
#row_headers = [x[1] for x in cur.description] # this will extract row headers
row_headers = ['title', 'book_reads']
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
if __name__ == "__main__":
#app.run(debug=True)
app.run(host="0.0.0.0", port=8080, debug=False)


















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











