




 本文探讨了在医疗信息化背景下,如何利用Spark等大数据处理技术开发医生推荐系统。研究内容包括医疗数据采集、推荐算法研究(如协同过滤和内容过滤)、系统设计与实现以及性能评估与优化。通过实证方法,旨在提高就医效率和医疗服务质量,提升患者体验。
本文探讨了在医疗信息化背景下,如何利用Spark等大数据处理技术开发医生推荐系统。研究内容包括医疗数据采集、推荐算法研究(如协同过滤和内容过滤)、系统设计与实现以及性能评估与优化。通过实证方法,旨在提高就医效率和医疗服务质量,提升患者体验。
一、选题背景与意义
随着医疗数据的积累和医疗技术的不断发展,医疗信息化已成为医疗行业的重要趋势。在这种背景下,利用大数据技术和人工智能技术,开发智能化的医生推荐系统,能够为患者提供更加个性化、高效的医疗服务。Spark医生推荐系统旨在利用Spark等大数据处理技术,结合医疗数据分析和推荐算法,为患者推荐最适合的医生,提高就医效率和医疗服务质量。
二、研究目标与内容
-
研究目标:建立一套基于Spark平台的医生推荐系统,实现个性化、高效的医生推荐服务,提升医疗服务体验。
-
研究内容:
- 医疗数据采集与处理:从医院信息系统等数据源采集医疗数据,包括医生信息、患者信息、就诊记录等,并进行数据清洗和处理。
- 推荐算法研究:研究医生推荐的算法模型,包括基于协同过滤、内容过滤等推荐算法。
- 系统设计与实现:设计并开发医生推荐系统,包括用户界面设计、推荐算法实现等。
- 系统评估与优化:对推荐系统进行性能评估,并根据用户反馈进行系统优化。
三、研究方法与技术路线
-
研究方法:本研究将采用实证研究方法,结合大数据处理技术和推荐系统算法,通过医疗数据分析和用户行为数据挖掘,建立医生推荐模型,并对模型进行评估和优化。
-
技术路线:
- 医疗数据采集与处理:利用Spark等大数据处理技术,从医院信息系统中获取医疗数据,并进行数据清洗和处理。
- 推荐算法研究:结合协同过滤、内容过滤等算法,构建医生推荐模型。
- 系统设计与实现:基于Spark平台,设计并实现医生推荐系统的用户界面和后台功能。
- 系统评估与优化:通过用户调查、实验评估等方法,对推荐系统的性能进行评估,并针对性能瓶颈进行优化。
四、预期成果与应用价值
-
预期成果:完成基于Spark平台的医生推荐系统,并具有较高的推荐准确度和用户满意度。
-
应用价值:
- 提高就医效率:帮助患者快速找到最适合的医生,减少就医时间。
- 提升医疗服务质量:通过个性化推荐,提供更加精准的医疗服务,提升患者体验和满意度。
- 促进医疗资源优化:合理分配医疗资源,提高医疗服务的整体效率和质量。
五、进度安排与预算
-
进度安排:
- 阶段一(第1-3个月):医疗数据采集与处理,推荐算法研究。
- 阶段二(第4-6个月):系统设计与实现。
- 阶段三(第7-9个月):系统评估与优化,论文撰写。
- 阶段四(第10-12个月):论文修改完善,成果发布。
-
预算:本研究预计需要经费XXX万元,主要用于人员费用、设备购置、数据采集等方面。
六、存在问题与解决方案
-
存在问题:医疗数据的质量和完整性如何保障?推荐算法的准确性和效率如何提升?
-
解决方案:通过数据质量控制和数据清洗技术,保障医疗数据的质量和完整性;利用机器学习和深度学习等技术,不断优化推荐算法,提高推荐的准确性和效率。








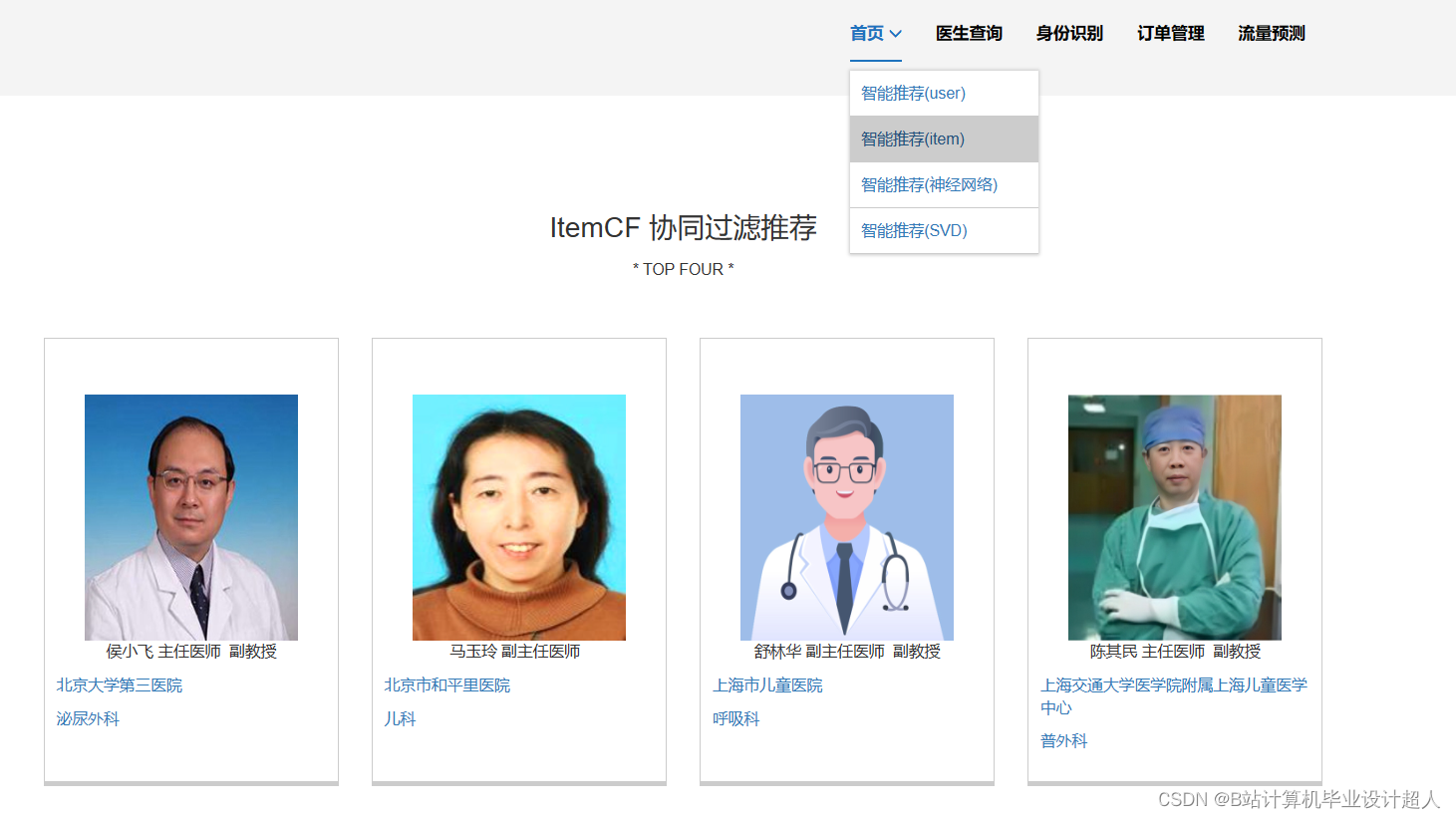
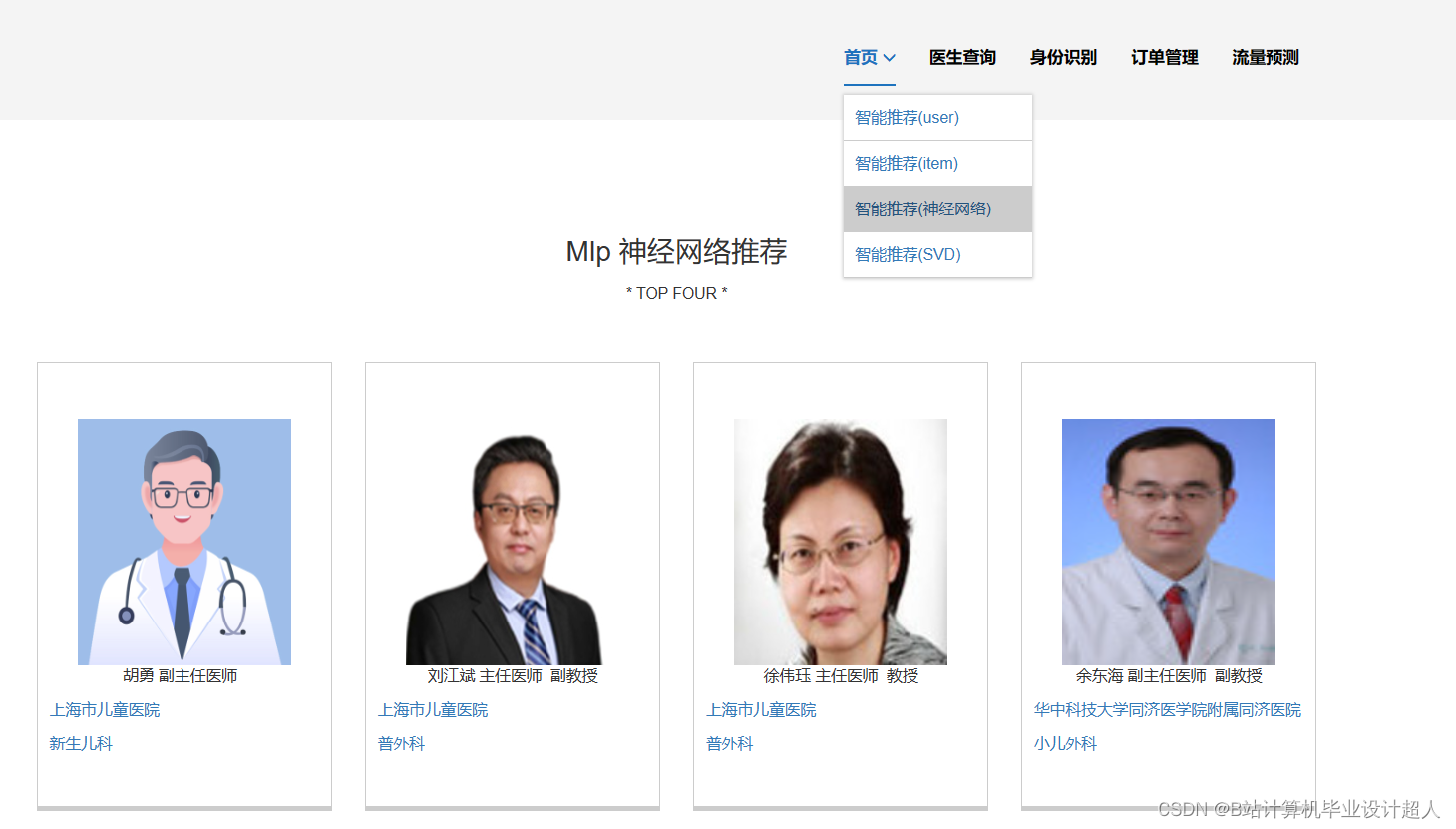
核心算法代码分享如下:
package com.sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.junit.Test
import java.util.Properties
class DoctorSpark2024 {
val spark = SparkSession.builder()
.master("local[12]")
.appName("医生大数据Spark分析2024")
.getOrCreate()
val doctors_schema = StructType(
List(
StructField("name", StringType),
StructField("views", FloatType),
StructField("hospital",StringType),
StructField("department", StringType),
StructField("gaode_province", StringType),
StructField("gaode_city",StringType),
StructField("gaode_district", StringType),
StructField("title", StringType),
StructField("disease", StringType)
)
)
val doctors_df = spark.read.option("header", "false").schema(doctors_schema).csv("hdfs://bigdata:9000/doctor2024/doctors/doctors.csv")
@Test
def init(): Unit = {
doctors_df.show()
}
//指标5 热门医生Top10
@Test
def tables05(): Unit = {
doctors_df.createOrReplaceTempView("ods_doctors")
val df2 = spark.sql(
"""
select hospital,name,max(views) num
from ods_doctors
group by hospital,name
order by num desc
limit 10
""")
df2
// .show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/hive_doctor?useSSL=false",
"tables05",
new Properties()
)
}
//指标6 科室数量Top10
@Test
def tables06(): Unit = {
doctors_df.createOrReplaceTempView("ods_doctors")
val df2 = spark.sql(
"""
select department,count(distinct name) num
from ods_doctors
group by department
order by num desc
limit 10
""")
df2
// .show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/hive_doctor?useSSL=false",
"tables06",
new Properties()
)
}
}


















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











