



 本文探讨了在音乐库规模庞大的情况下,如何利用机器学习和协同过滤算法设计一个音乐推荐系统,该系统能根据用户兴趣提供精准的个性化推荐,帮助用户发现新的音乐。核心算法包括用户行为分析、物品映射和基于用户/物品的推荐模型实现。
本文探讨了在音乐库规模庞大的情况下,如何利用机器学习和协同过滤算法设计一个音乐推荐系统,该系统能根据用户兴趣提供精准的个性化推荐,帮助用户发现新的音乐。核心算法包括用户行为分析、物品映射和基于用户/物品的推荐模型实现。
- 目的
随着计算机技术的快速发展,音乐数字化极大的丰富了人们对音乐的获取。现在大家使用的大部分软件例如QQ音乐、网易云音乐、酷狗音乐。在这些音乐软件的音乐库收录着许许多多的音乐项目。但现在的音乐库中的歌曲数据非常的多,出现了百万级甚至千万级的音乐库,大家寻找自己喜欢的歌曲一般使用的还是依赖关键字的搜索引擎,通过输入歌曲名或者歌手名来发现自己喜欢的歌曲,搜索出来的还是自己常听的,对于忘记歌曲信息的人们来说要在这么多的数据中选择自己喜欢的歌曲是非常困难的。并且对于无法准确描述自己需求的用户,这种方式无异于大海捞针。所以本课题主要设计一个基于机器学习的音乐推荐,目的是在音乐数据巨大的音乐库中通过过滤大量的音乐项目,给用户推荐比较符合用户兴趣爱好的歌曲列表。
- 意义
本课题设计的音乐推荐系统,可以帮助用户在百万级的音乐数据库中发现许许多多自己没有听过的歌曲,并且这些歌曲还有可能比较符合自己的兴趣爱好。推荐系统本质上是在用户需求不明确的情况下,从海量的信息中为用户寻找其感兴趣的信息的技术手段。推荐系统结合用户信息、内容信息和用户的历史行为数据,利用机器学习技术构建用户兴趣模型,为用户提供精确的个性化推荐。可以快速的将多样化的内容推送到用户的面前,有效的提高了信息的配置效率。大大节省用户的时间,提高了用户的体验,做到资源的优化配置。

|
课 题 简 介 |
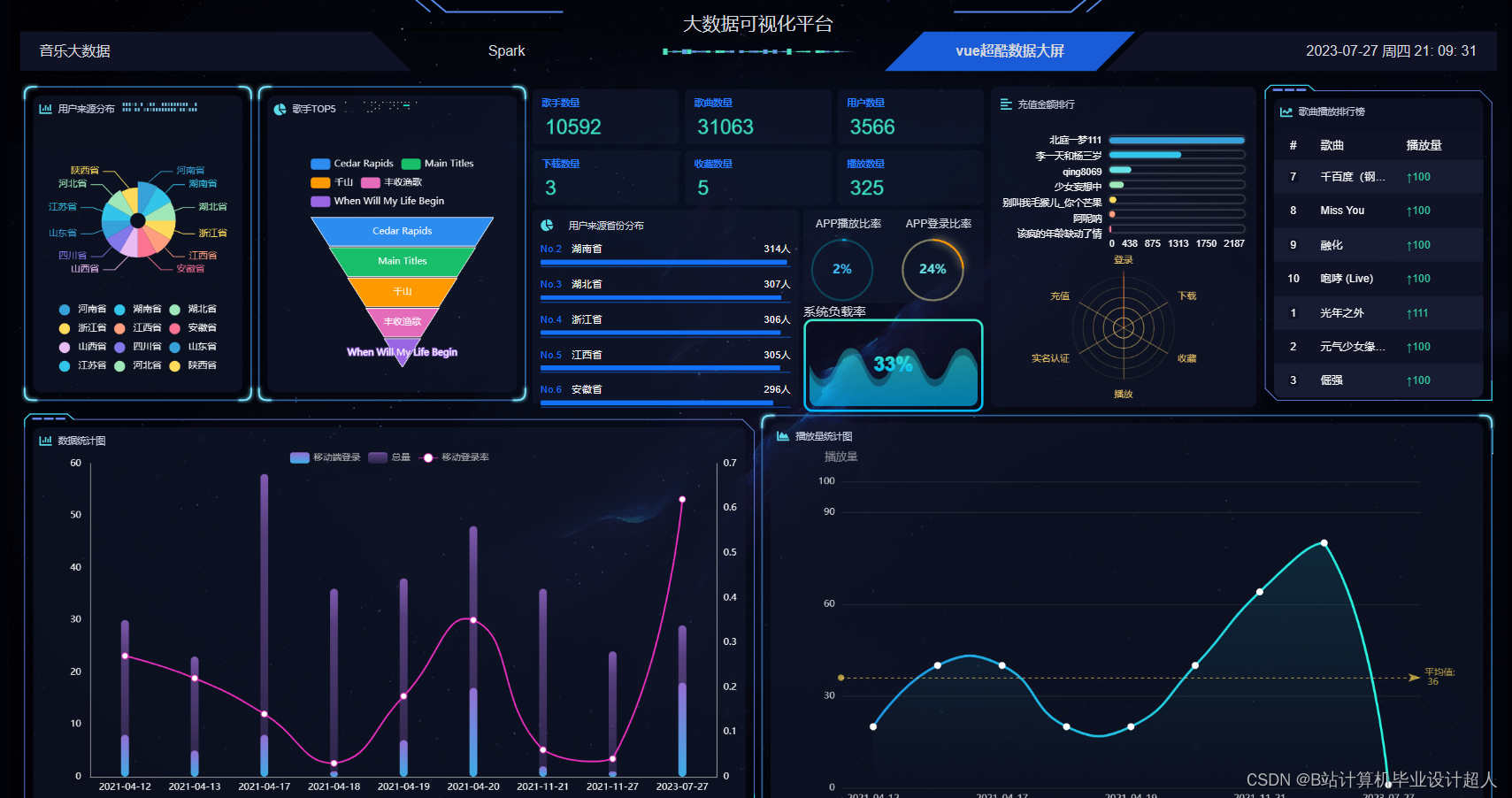
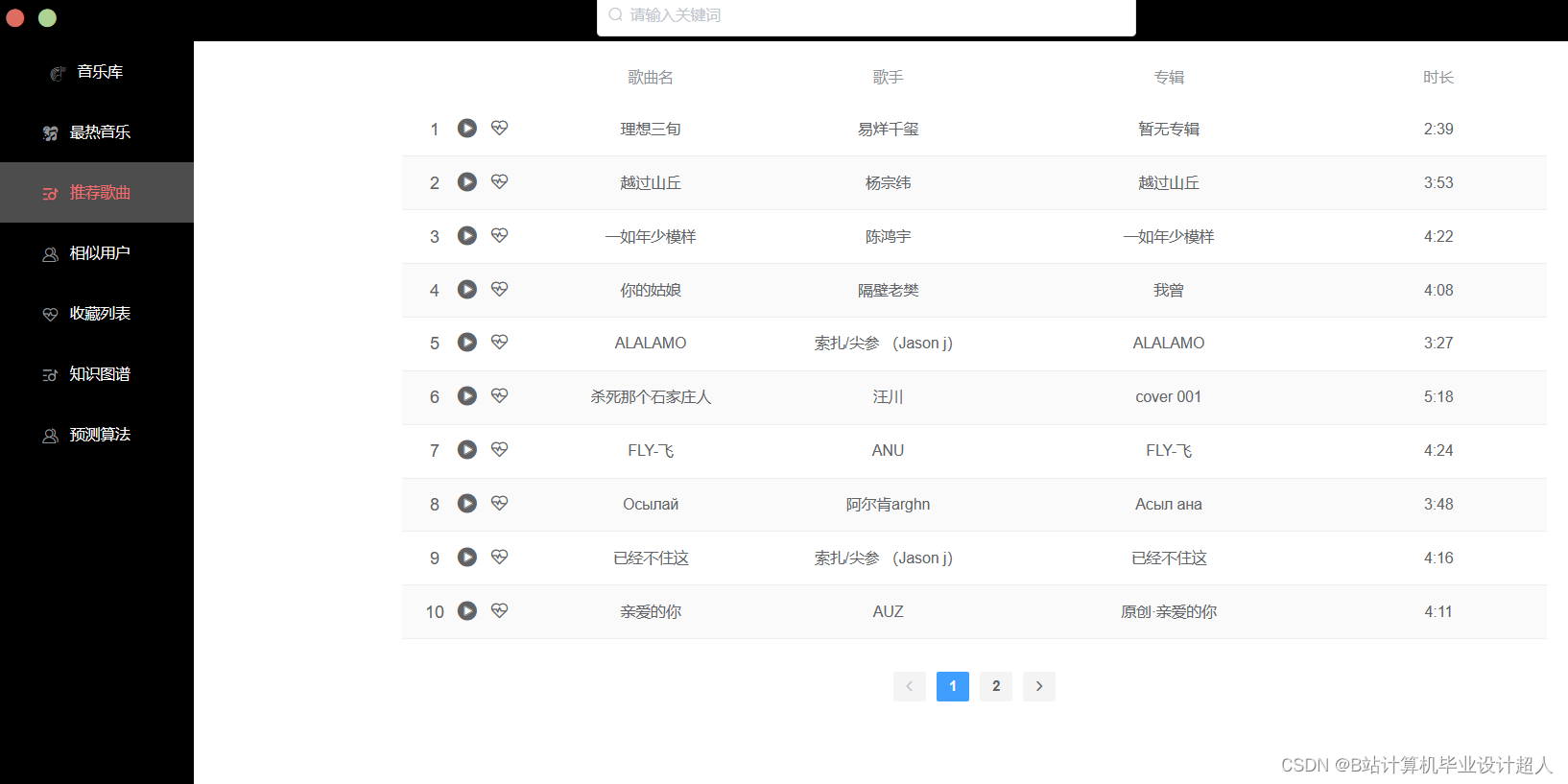
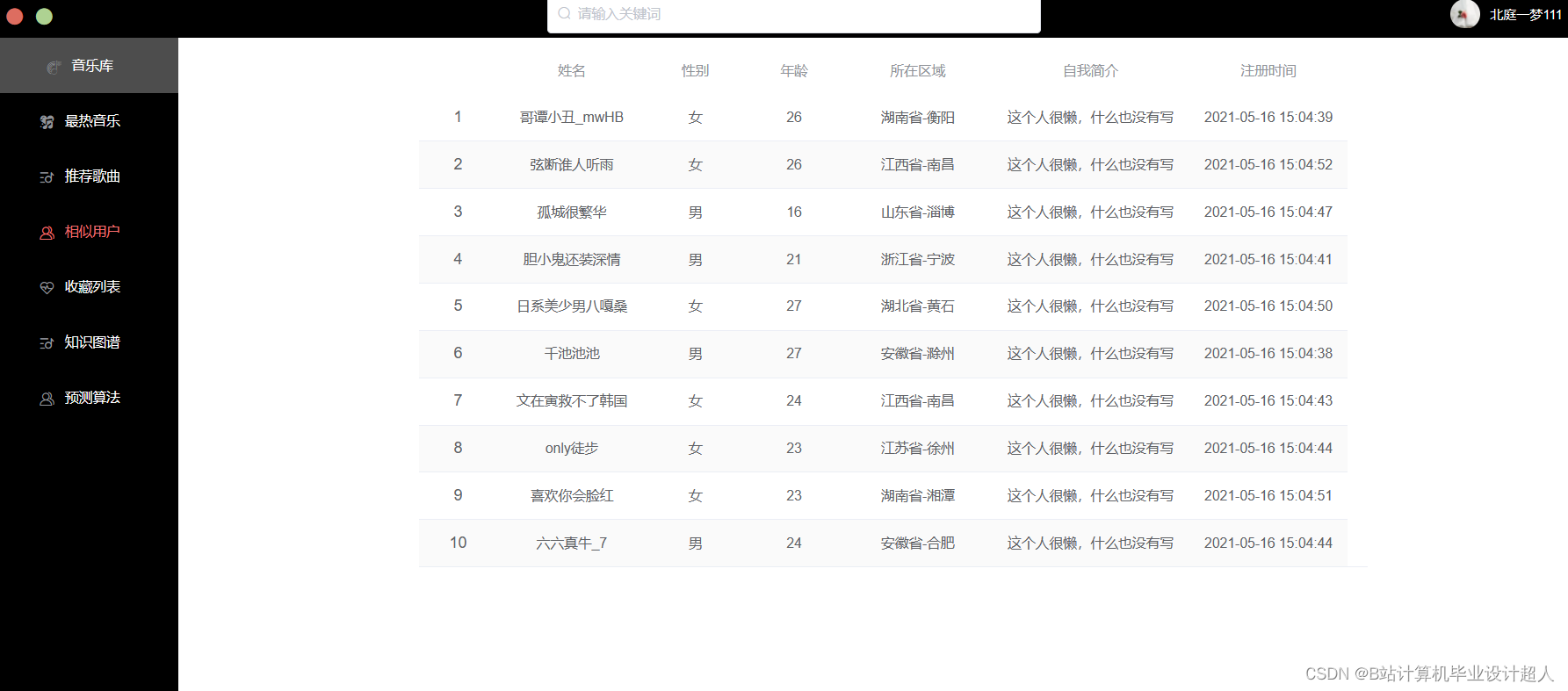
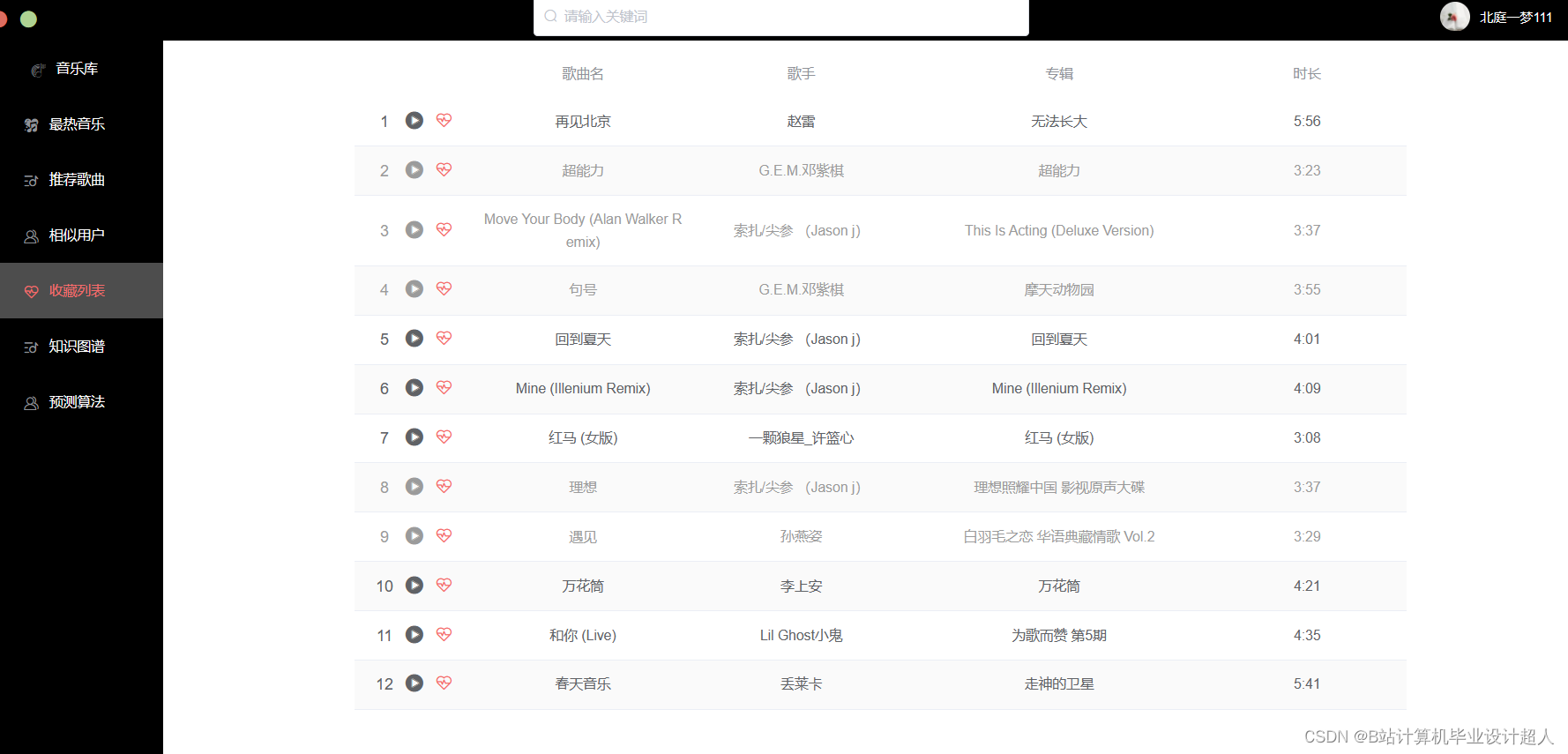
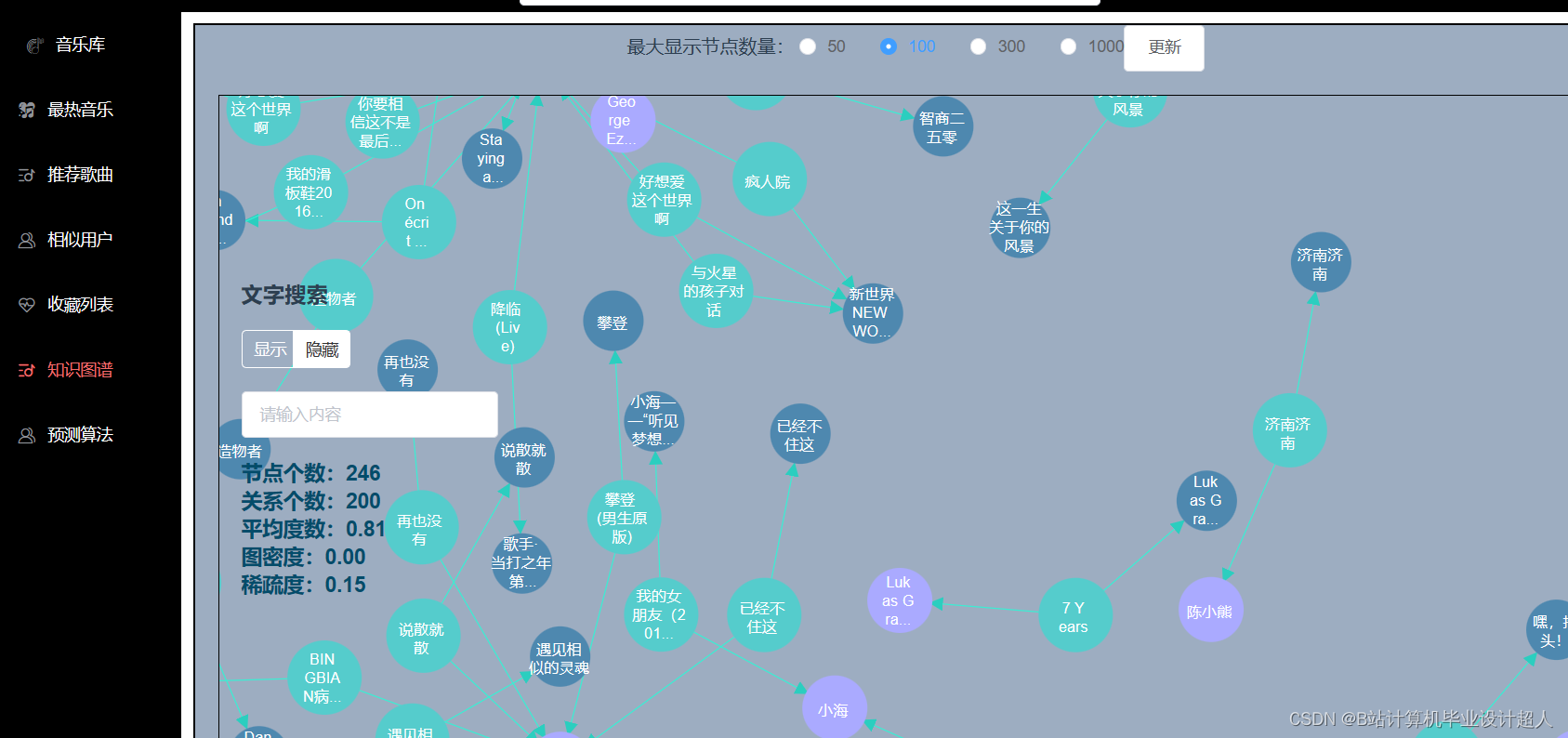
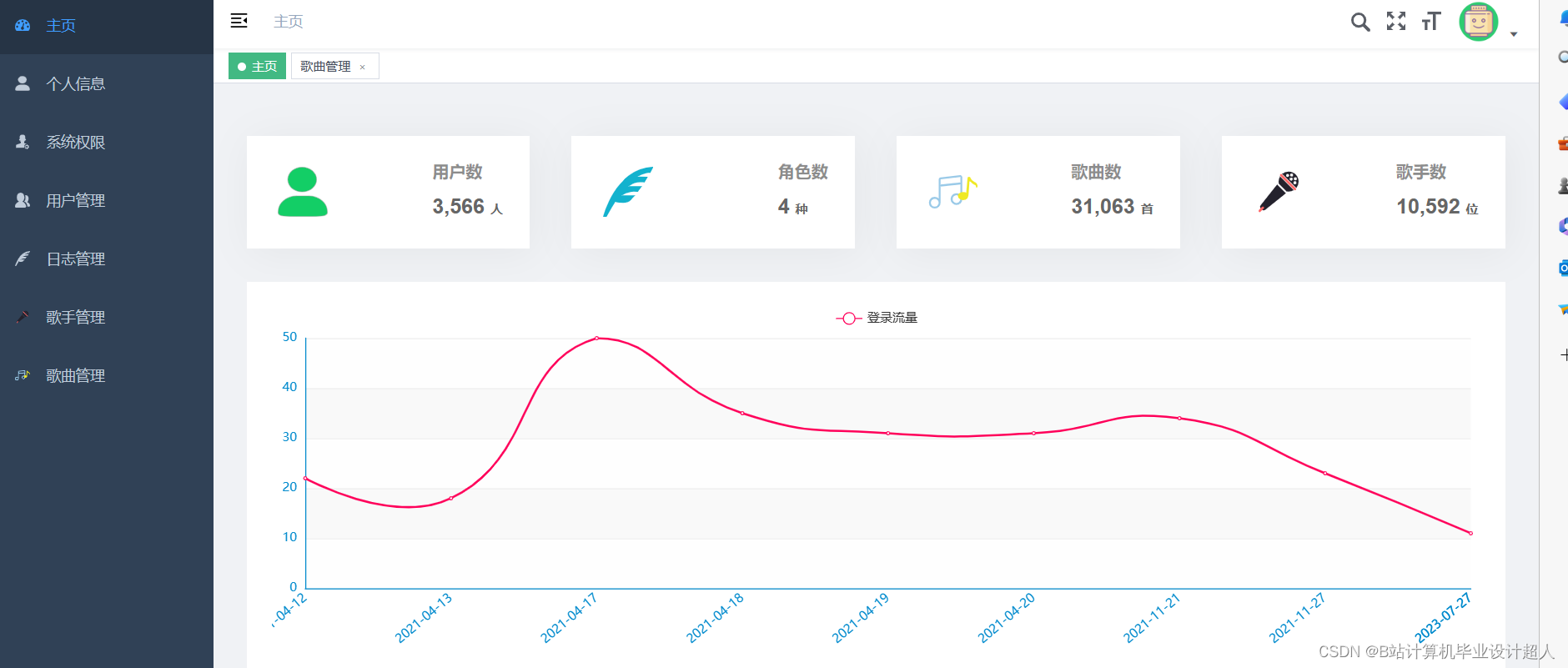
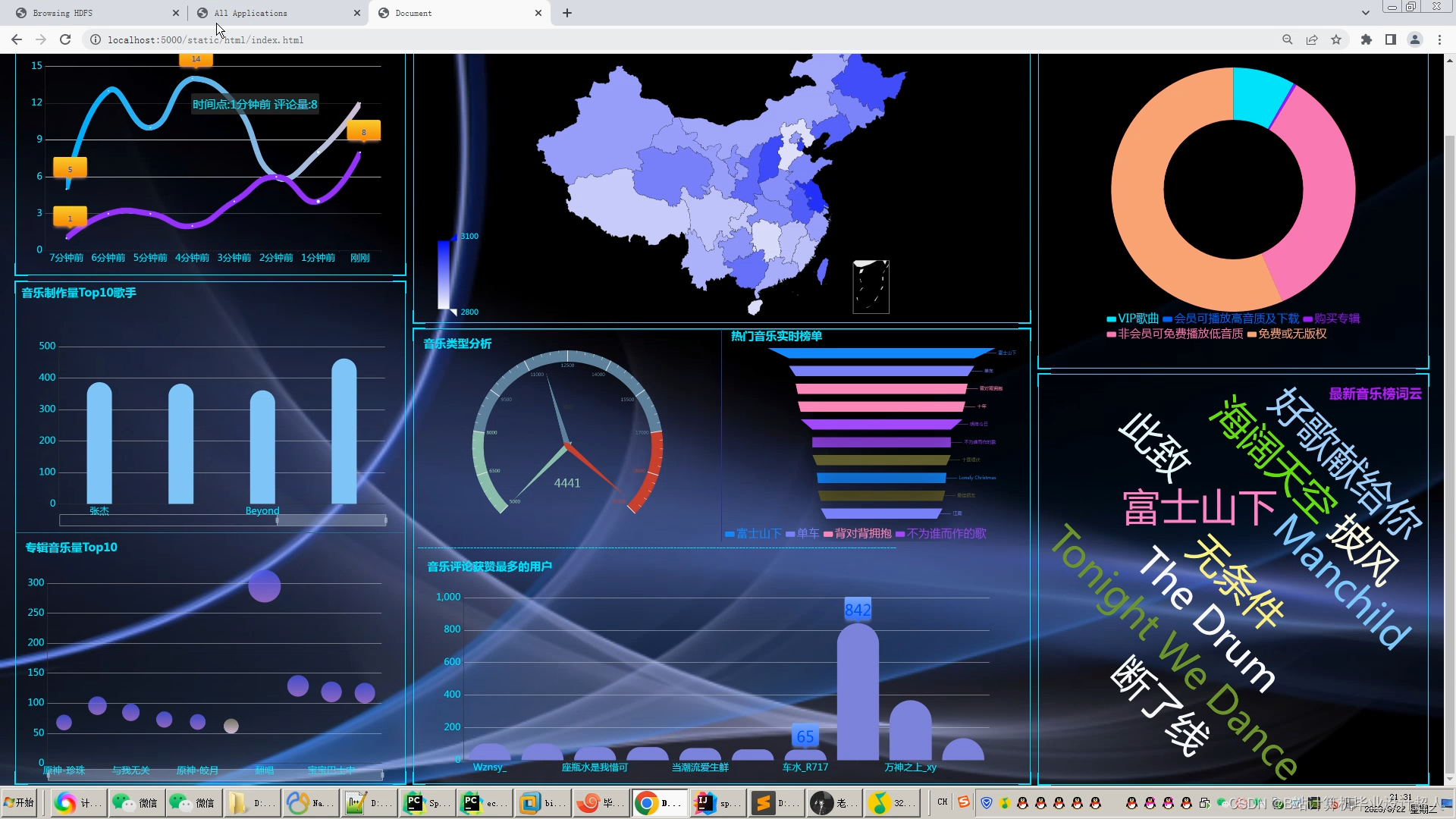
本课题主要设计一个基于机器学习的音乐推荐系统,目的是为每一个用户推荐与其兴趣爱好契合度较高的音乐。本系统包含音乐前端展示界面、音乐评分板块、推荐算法的实现以及后端数据库的设计。其中实现推荐算法是整个音乐推荐系统的核心。 |
|
设 计 内 容 |
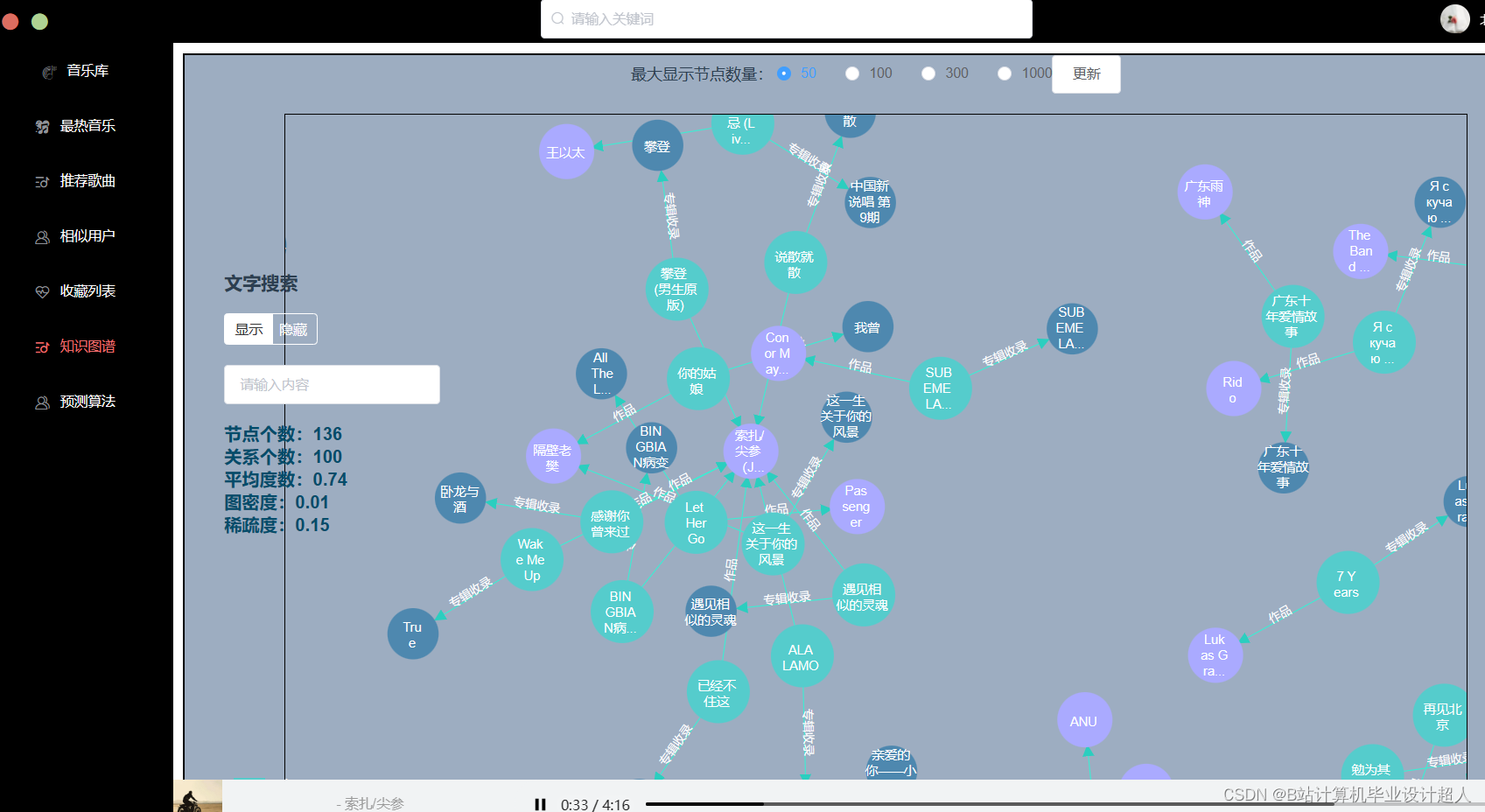
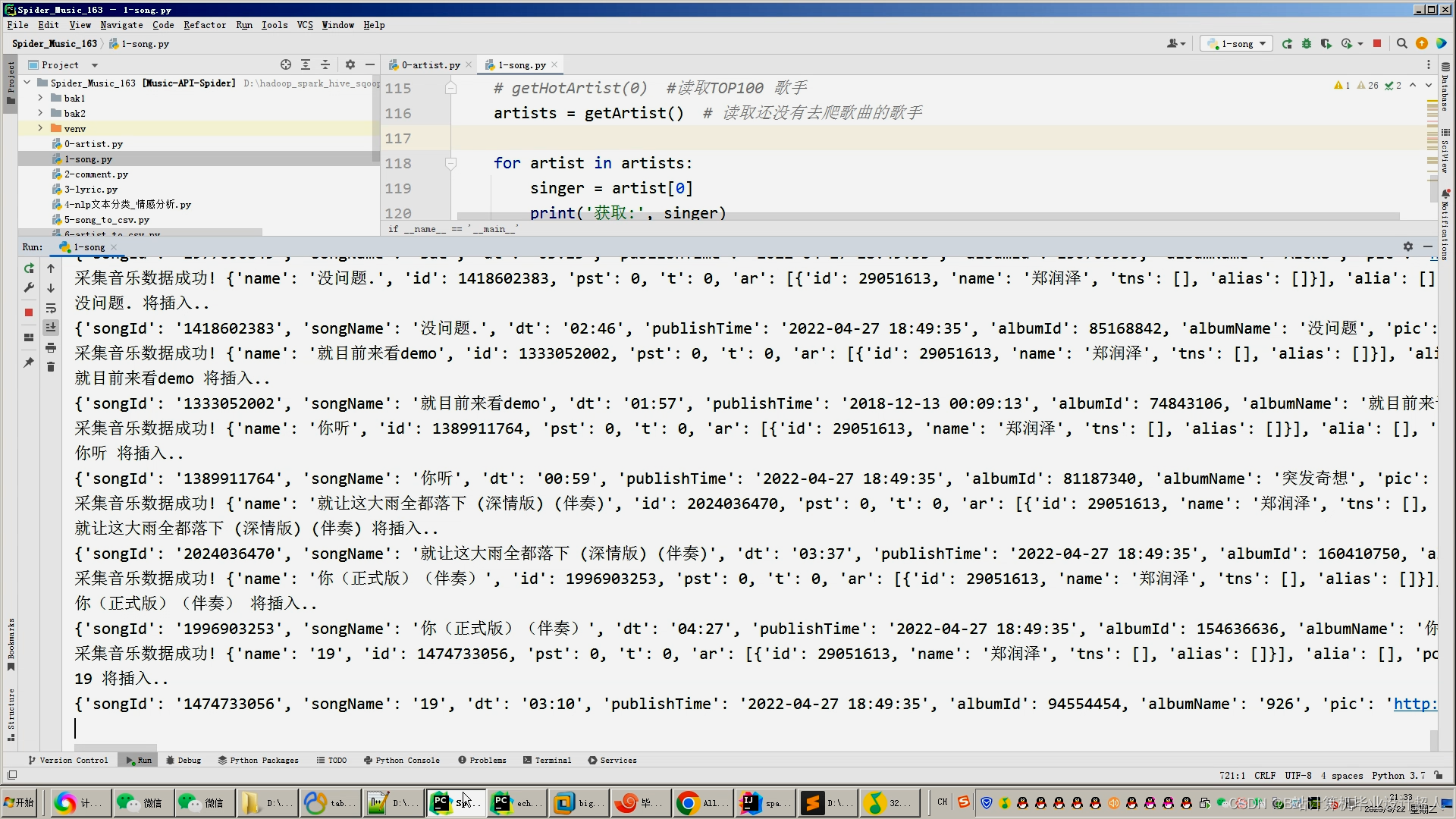
本课题设计的音乐推荐系统主要包括以下内容: 1、前端界面模块:利用html、JavaScript和JQuery等技术实现系统界面展示 2、后端服务器模块:利用Java+SpringBoot等技术实现数据的传输交互 3、数据存储模块:使用MYSQL数据库进行数据的存储处理 4、网络爬虫模块:利用python中的requests模块进行请求,pandas库进行数据处理, matplotlib库进行可视化分析 5、机器学习模块:使用pandas, libFM, sklearn完整的数据处理和模型构建、训练、预测。 |
|
设 计 要 求 |
|
核心算法代码分享如下:
# 基于皮尔逊相似的的物品推荐
from __future__ import (absolute_import, division, print_function
, unicode_literals)
import os
import io
from surprise import KNNBaseline
from surprise import KNNBasic
from surprise import SVD
from surprise import Dataset
from surprise import Reader
# def read_item_names():
# """
# 获取歌曲名称到歌曲id 和 歌曲id到歌曲名的映射
# :return: 两个字典
# rid_to_name:键为rid,值为name,只有一个键值对
# name_to_rid = {}键为name,值为rid,只有一个键值对
# """
# file_name = ('./dataset/song_info.txt')
# rid_to_name = {}
# name_to_rid = {}
# # 打开文件,并指定编码格式(这里是该数据要求的指定格式)
# with io.open(file_name, 'r', encoding='utf-8') as f:
# next(f) # 跳过第一行的列名称,从第二行开始读
# # 每次读取一行,并且每一行中的各个元素使用制表符 ”\t“ 隔开
# for line in f:
# # 将每个元素转存到数组中
# line = line.split('\t')
# # 第一个元素为歌曲id,第二个元素为歌曲名称
# rid_to_name[line[0]] = line[1]
# name_to_rid[line[1]] = line[0]
# return rid_to_name, name_to_rid
def get_rid2name(file_name):
"""
获得名称到id 和 id到名称的映射,包括歌曲或用户等的映射
:param file_name: 需要解析的文件路径名,且文件中每行的第一列为id,第二列为名称,使用制表符隔开
:return: 两个字典
rid_to_name:键为rid,值为name,只有一个键值对
name_to_rid = {}键为name,值为rid,只有一个键值对
"""
rid_to_name = {}
name_to_rid = {}
# 打开文件,并指定编码格式(这里是该数据要求的指定格式)
with io.open(file_name, 'r', encoding='utf-8') as f:
# next(f) # 跳过第一行的列名称,从第二行开始读
# 每次读取一行,并且每一行中的各个元素使用制表符 ”\t“ 隔开
for line in f:
# 将每个元素转存到数组中
line = line.split('\t')
# 第一个元素为id,第二个元素为名称
rid_to_name[line[0]] = line[1]
name_to_rid[line[1]] = line[0]
return rid_to_name, name_to_rid
# 获取歌曲名称到歌曲id 和 歌曲id到歌曲名的映射
item_rid_to_name, item_name_to_rid = get_rid2name('dataset/min_song_info.txt')
# 得到用户名称到id 和 用户id到名称的映射
user_rid_to_name, user_name_to_rid = get_rid2name('./dataset/user_info.txt')
# print(rid_to_name.values())
# 映射结果如下
# print(rid_to_name["1"])
# print(name_to_rid.values())
def get_trainset_algo():
"""
算法使用训练集进行训练
:return: 训练之后的结果
"""
# 指定数据格式
reader = Reader(line_format='user item rating timestamp', sep='\t', skip_lines=0, rating_scale=(0, 100))
# 文件路径
file_path = os.path.expanduser('./dataset/min_user_record.txt')
# 加载数据集
data = Dataset.load_from_file(file_path, reader=reader)
# 将数据集转换成矩阵形式
trainset = data.build_full_trainset()
print(trainset.all_items())
print(trainset.all_users())
# 基于物品的协同过滤算法,相似度衡量方法:皮尔逊相似度
# 这是一个用户数量N,矩阵大小为 N*N 的稀疏矩阵,然后get_neighbors得到的是topK个相似用户。如果想要得到相似歌曲,则需要使用基于项目的协同过滤算法,
# 或者从得到的相似用户中,提取他们的播放记录(这是基于用户的协同过滤算法)
sim_options = {'name': 'pearson_baseline', 'user_based': True}
# 选择算法
algo = KNNBaseline(sim_options=sim_options)
# algo = KNNBasic(sim_options=sim_options)
# 训练数据集
print('开始训练······')
algo.fit(trainset)
print('训练结束')
return algo
# 得到训练之后的结果
algo = get_trainset_algo()
def get_topN_items(current_item_raw_id, topK):
"""
得到指定物品的top-N个相似物品
:param current_item_raw_id: 物品的原始id,必须为字符串类型
:param topK: 相似度高的前topK首歌曲
:return: 当前歌曲的相似歌曲id列表
"""
# 得到训练之后的结果
# algo = get_trainset_algo()
print("歌曲原始id:")
print(current_item_raw_id)
# 得到矩阵中的歌曲id(内部id),参数为字符串格式
current_song_inner_id = algo.trainset.to_inner_iid(current_item_raw_id)
print("歌曲内部id:")
print(current_song_inner_id)
# 相似歌曲推荐,得到的是相似歌曲的内部id,得到topK个
current_song_neighbors = algo.get_neighbors(current_song_inner_id, k=topK)
# 推荐歌手的内部id如下
print("推荐歌曲的内部id:")
print(current_song_neighbors)
# 从相似歌曲的内部id得到原始id
current_song_neighbors = (algo.trainset.to_raw_iid(inner_id)
for inner_id in current_song_neighbors)
# 从相似歌曲的原始id得到相似歌曲的名称
current_song_neighbors = (item_rid_to_name[rid]
for rid in current_song_neighbors)
# 存储topN首歌曲的id
topN_items_id = []
print("推荐歌曲如下:")
for song in current_song_neighbors:
topN_items_id.append(item_name_to_rid[song])
print(item_name_to_rid[song], song)
return topN_items_id
# 32835565对应的歌曲名为:国王与乞丐,返回相似的前30首歌曲
get_topN_items('448317748', 30)
def get_topN_users(current_user_raw_id, topK):
"""
获得相似音乐好友推荐
:param current_user_raw_id: 当前用户id
:param topK: 相似度高的前topK个相似音乐好友
:return: 当前用户的相似音乐好友id数组
"""
# 得到训练之后的结果
# algo = get_trainset_algo()
# 给定一个歌曲名称,并得到它的歌曲id(原始id)
# current_user_raw_id = user_name_to_rid['北庭一梦']
print("用户原始id:")
print(current_user_raw_id)
# 得到矩阵中的用户id(内部id),方法是algo.trainset.to_inner_uid(uid),参数为字符串格式
current_user_inner_id = algo.trainset.to_inner_uid(current_user_raw_id)
print("用户内部id:")
print(current_user_inner_id)
# 相似音乐好友推荐,得到的是相似音乐好友的内部id,得到topK个
current_user_neighbors = algo.get_neighbors(current_user_inner_id, k=topK)
# 推荐相似好友的内部id如下
print("推荐用户的内部id:")
print(current_user_neighbors)
# 从相似音乐好友的内部id转化为原始id
current_user_neighbors = (algo.trainset.to_raw_uid(inner_id)
for inner_id in current_user_neighbors)
# 从相似音乐好友的原始id得到名字
current_user_neighbors = (user_rid_to_name[rid]
for rid in current_user_neighbors)
# 存储topN个用户的id
topN_users_id = []
print("推荐相似好友如下:")
for user in current_user_neighbors:
topN_users_id.append(user_name_to_rid[user])
print(user_name_to_rid[user], user)
return topN_users_id
# 338663754对应的用户名为:北庭一梦,返回前十个最相似的用户
# users_id_list = get_topN_users('338663754', 10)
# init_id = '338663754' + '\t'
# for id in users_id_list:
# init_id = init_id + id + ','
# print(init_id.strip(','))
# 获得每首歌曲的相似歌曲推荐
def get_all_topN_songs():
"""
从文件中读取歌曲信息,然后根据基于用户的协同过滤推荐算法,推荐出每一首歌曲的相似歌曲,并将相似歌曲对应的id存到文件汇总,形成倒排链表
格式为:当前歌曲id 相似歌曲id1,相似歌曲id2···
:return:
"""
song_info_file_name = 'dataset/min_song_info.txt'
all_topN_songs_file_name = 'resultset/topN_songs_baseline.txt'
with open(song_info_file_name, 'r', encoding='utf-8') as input_f, open(all_topN_songs_file_name, 'a',
encoding='utf-8') as output_f:
for line in input_f:
# 获得歌曲id
song_id = line.split('\t')[0]
print('获得' + item_rid_to_name[song_id] + '的推荐结果:')
line = song_id + '\t'
# 将得到的结果拼接成字符串
for id in get_topN_items(song_id, 20):
line = line + id + ','
# 写入到文件中
output_f.write(line.strip(',') + '\n')
output_f.flush()
# 关闭文件输入输出流
input_f.close()
output_f.close()
# get_all_topN_songs()
# 获得每个用户的相似音乐好友推荐
def get_all_topN_users():
"""
从文件中读取用户信息,然后根据基于用户的协同过滤推荐算法,推荐出每一个用户的相似音乐好友,并将音乐好友对应的id存到文件汇总,形成倒排链表
:return:
"""
# 输入文件路径和结果文件路径
user_info_file_name = './dataset/user_info.txt'
all_topN_users_file_name = 'resultset/topN_users_baseline.txt'
with open(user_info_file_name, 'r', encoding='utf-8') as input_f, open(all_topN_users_file_name, 'a',
encoding='utf-8') as output_f:
for line in input_f:
# 获得用户id
user_id = line.split('\t')[0]
line = user_id + '\t'
# 将结果拼接成字符串
for id in get_topN_users(user_id, 10):
line = line + id + ','
# 写入到文件中
output_f.write(line.strip(',') + '\n')
output_f.flush()
# 关闭文件输入输出流
input_f.close()
output_f.close()
# 获取所有用户的相似好友
get_all_topN_users()


















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











