



|
|
|
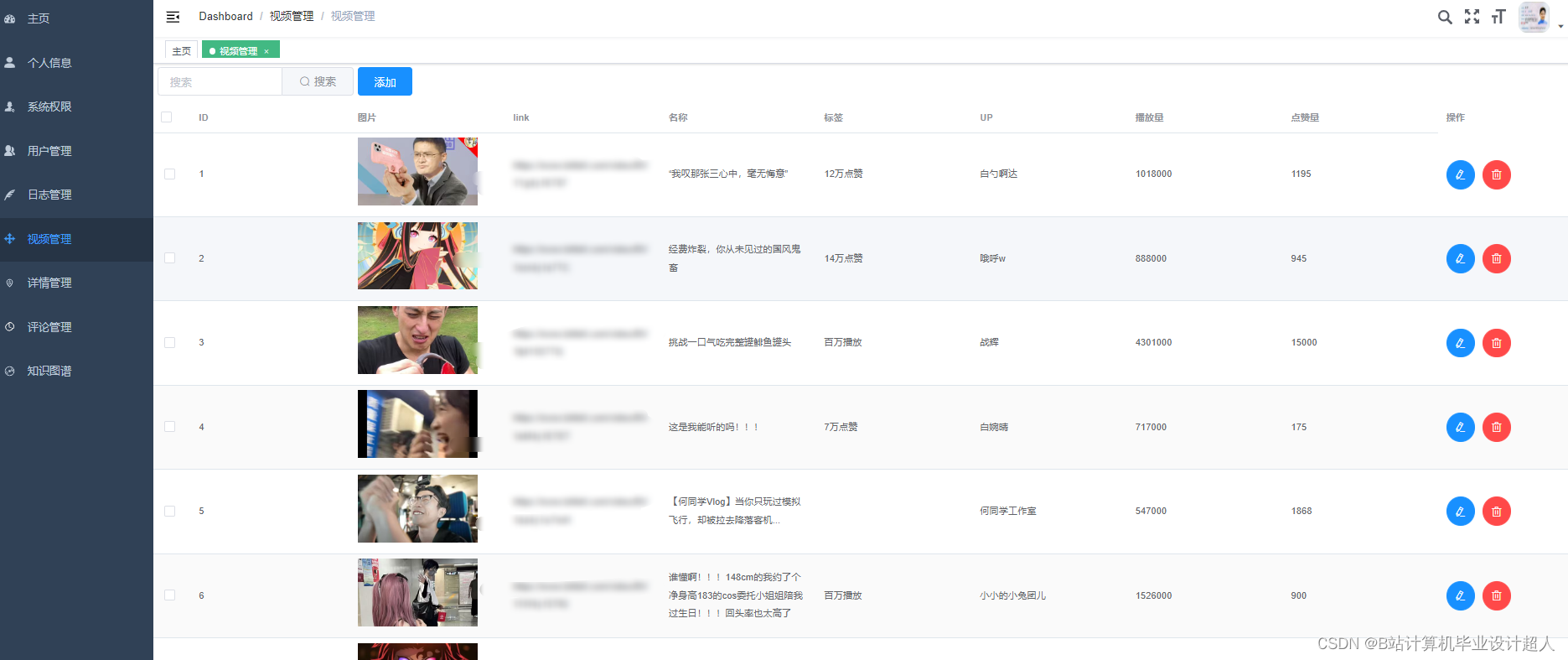
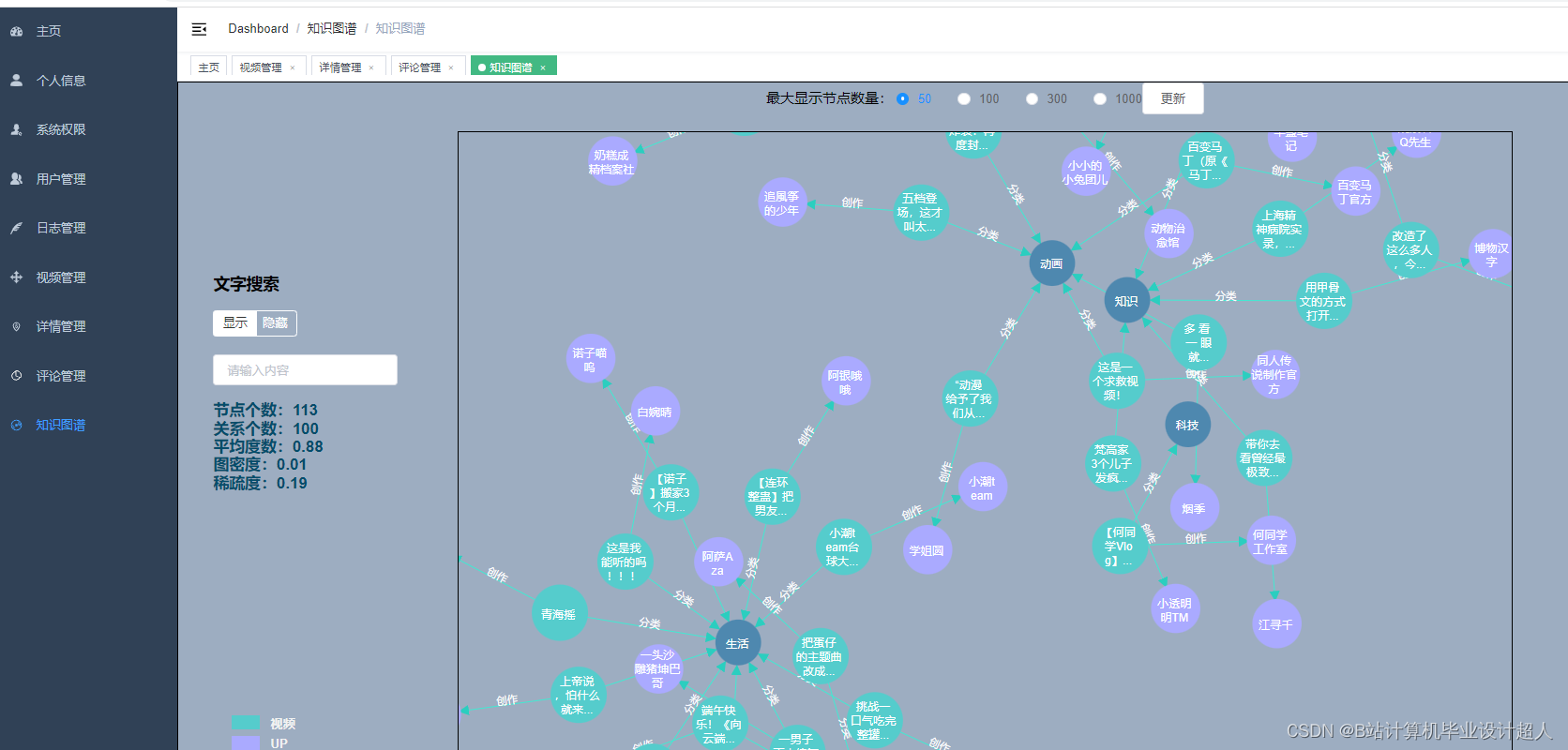
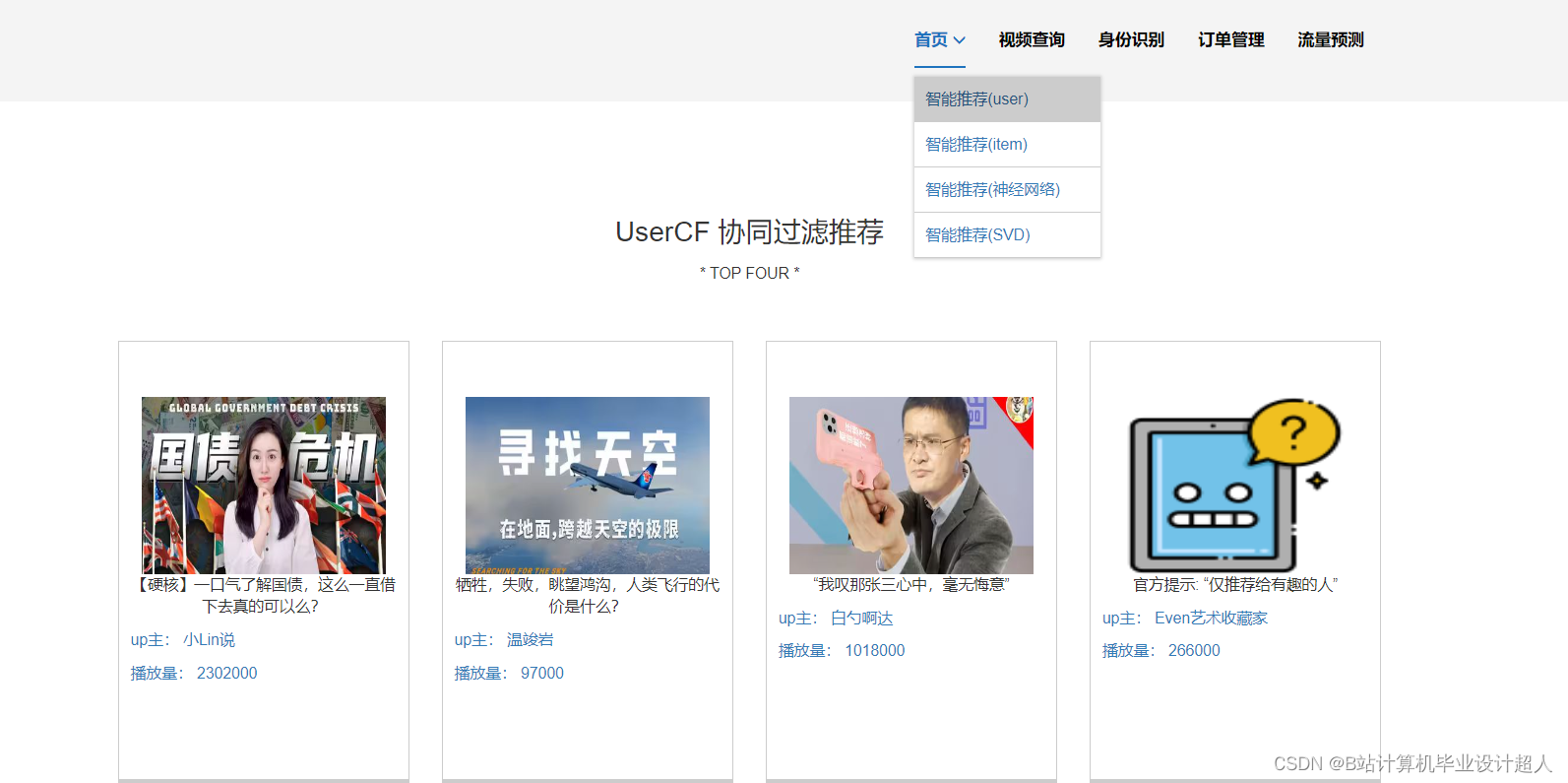
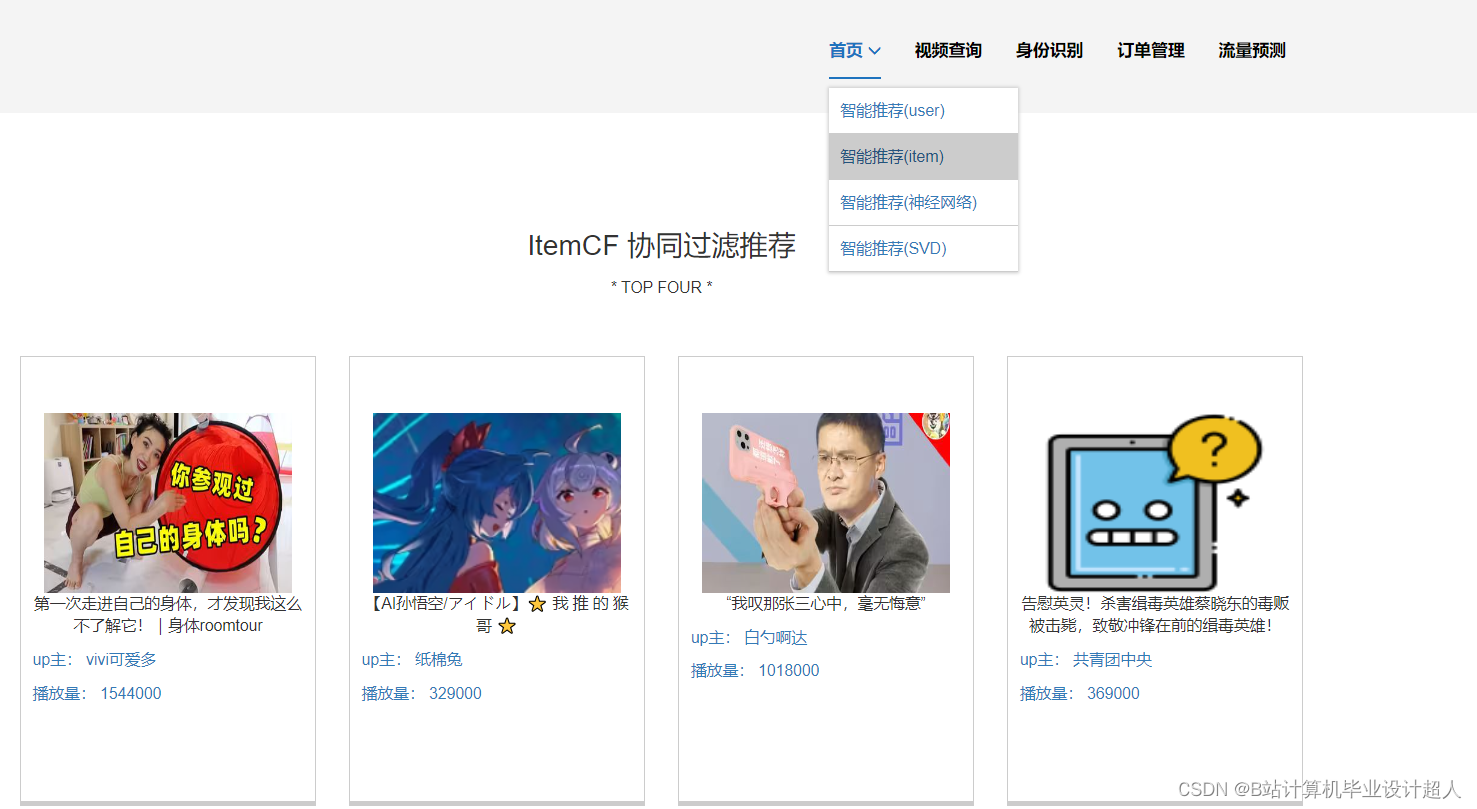
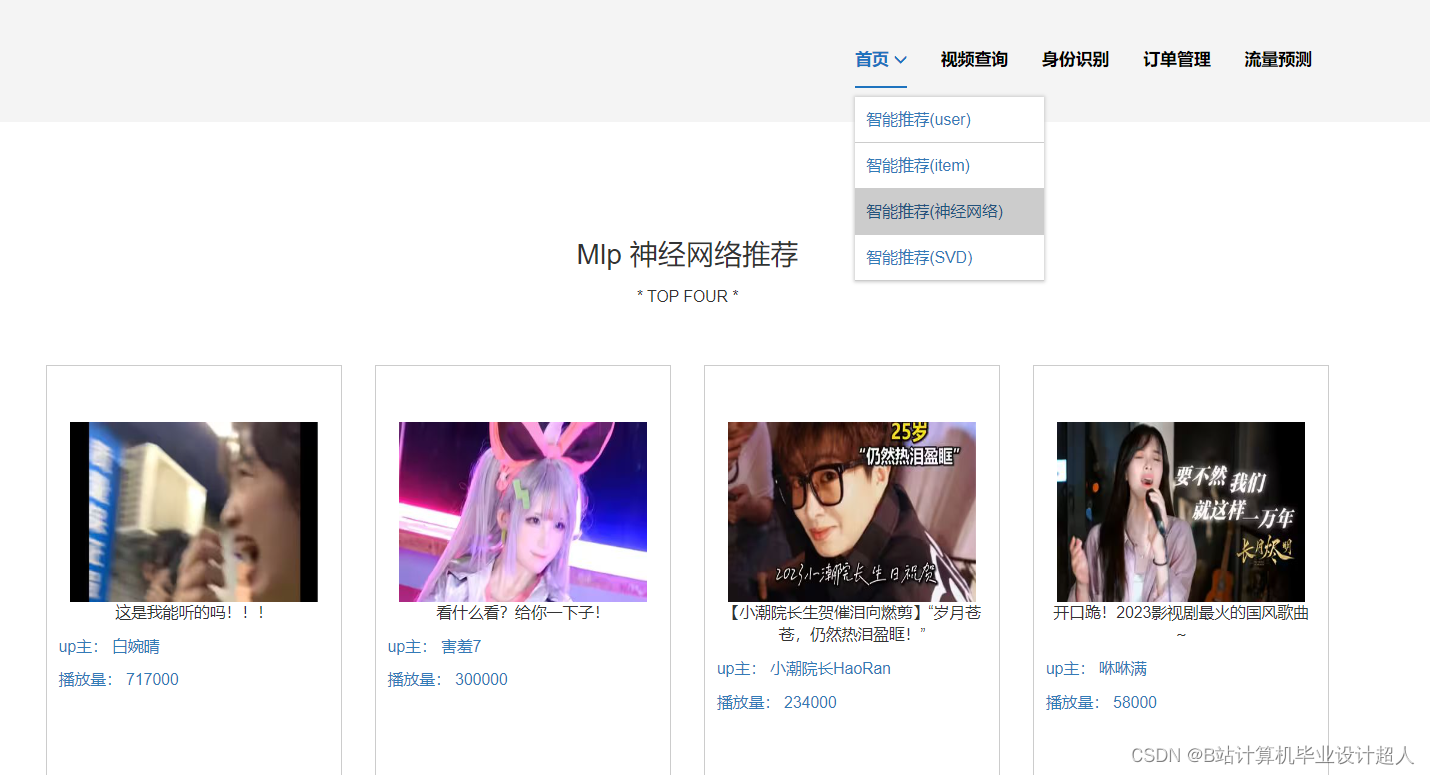
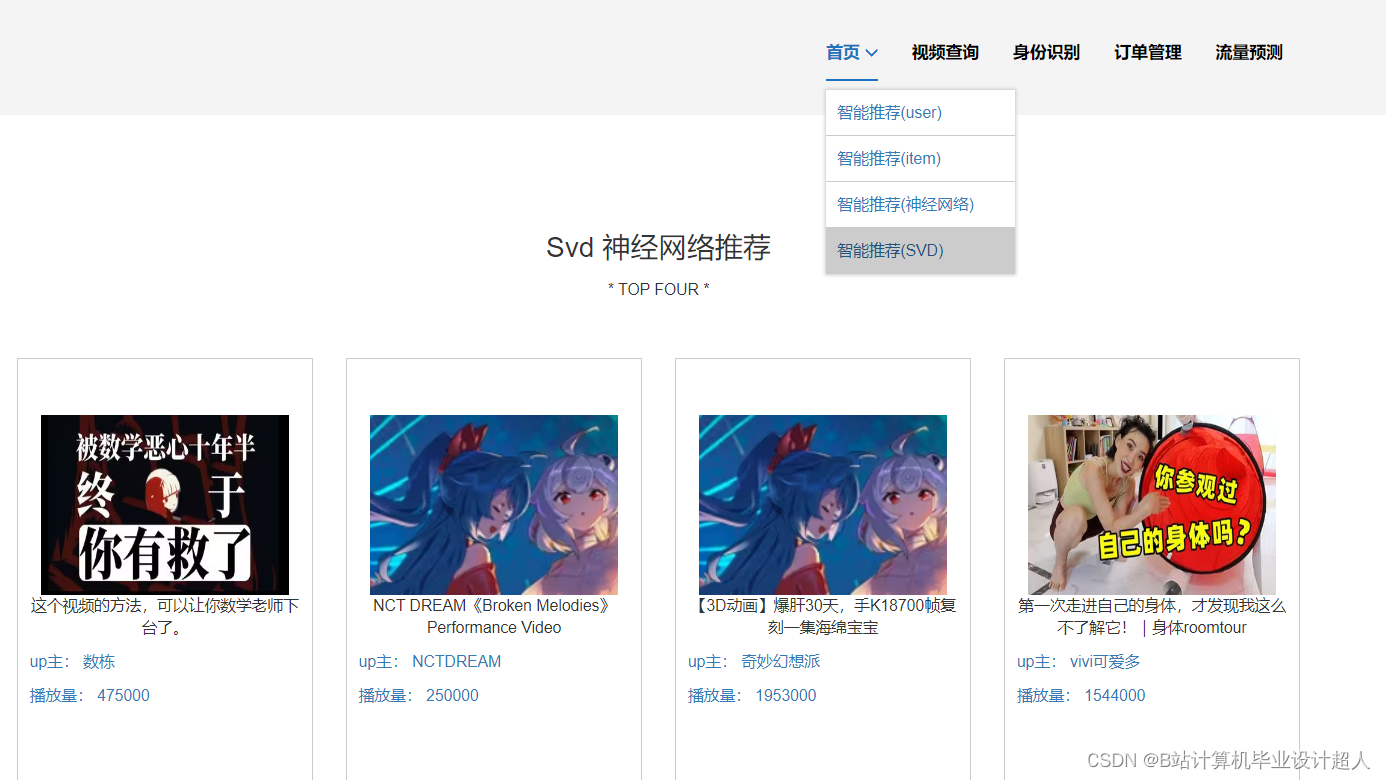
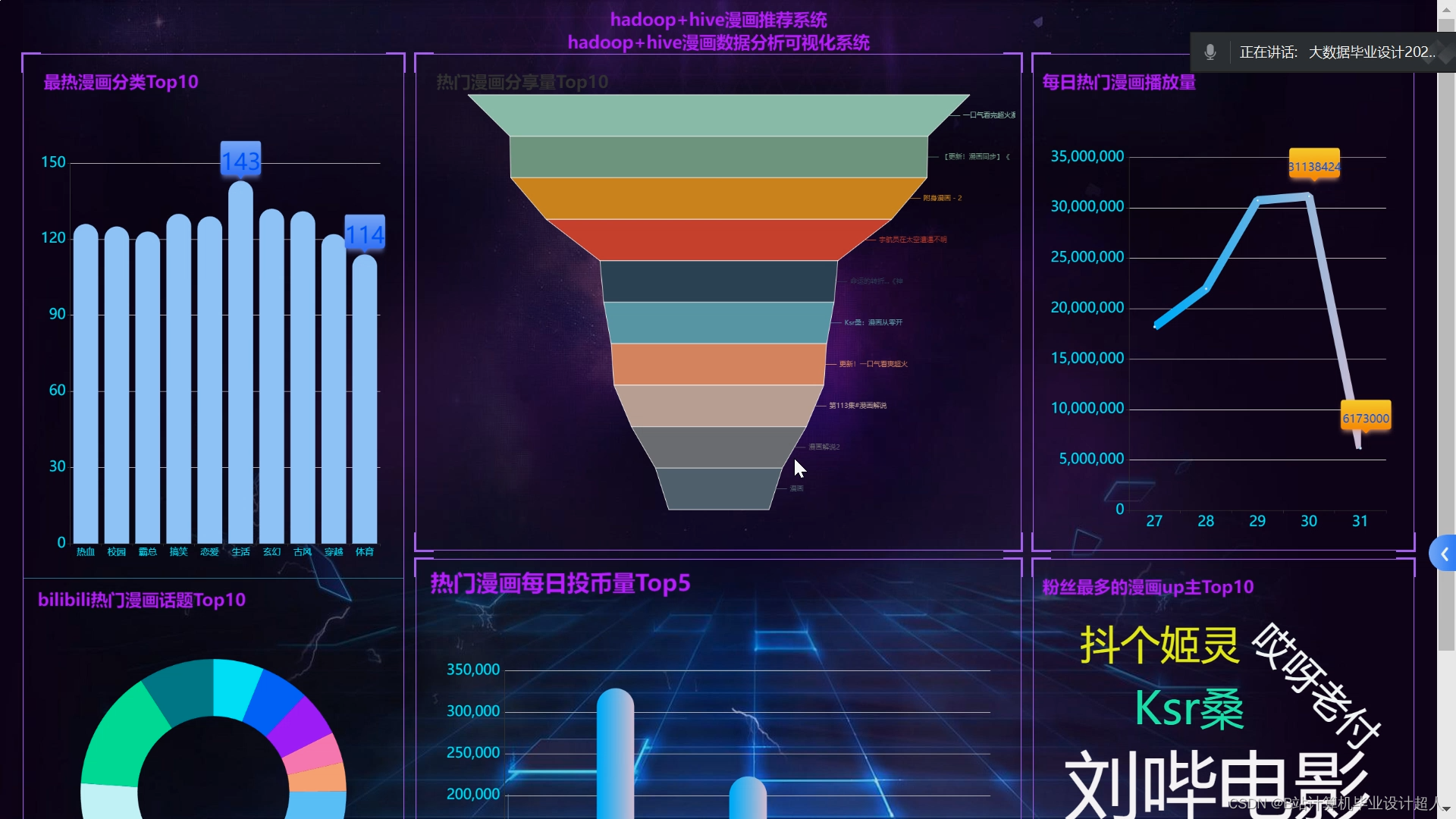
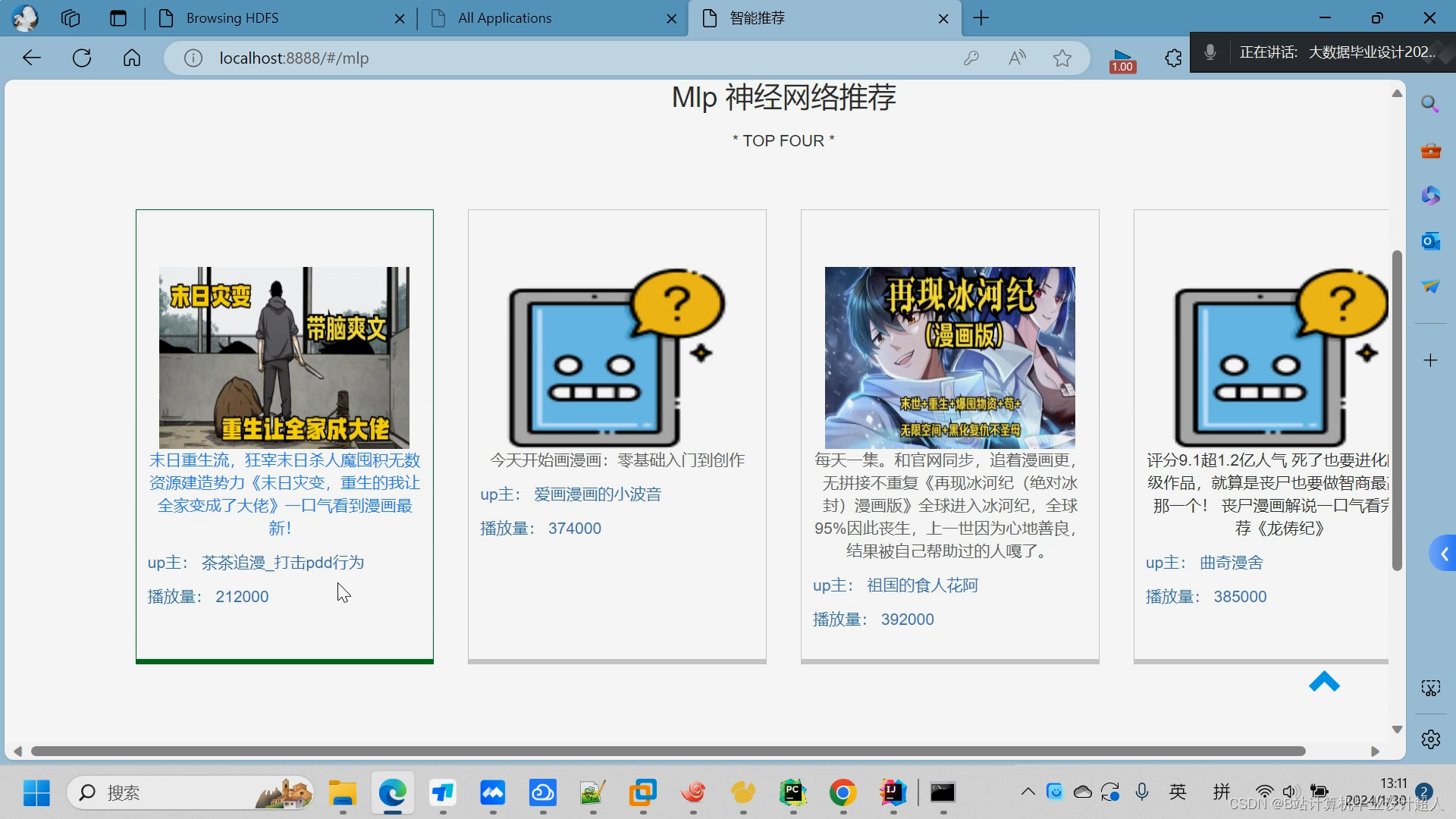
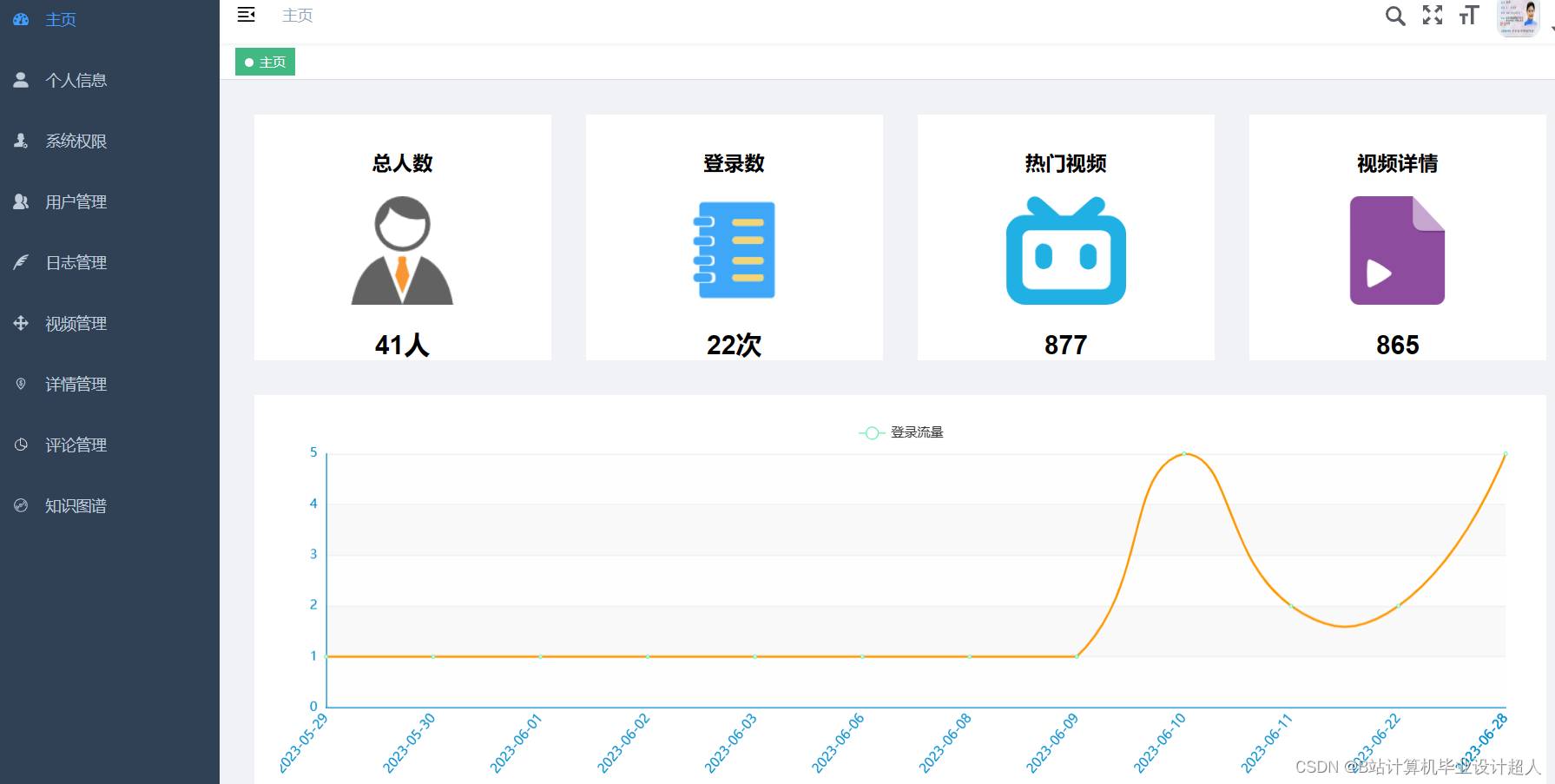
(一)Selenium自动化Python爬虫工具采集漫画视频等约10万条存入.csv文件作为数据集; (二)使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs; (三)使用hive数仓技术建表建库,导入.csv数据集; (四)离线分析采用hive_sql完成,实时分析利用Spark之Scala完成; (五)统计指标使用sqoop导入mysql数据库; (六)使用Flask+echarts进行可视化大屏开发; (七)使用机器学习、深度学习的算法进行个性化漫画视频推荐; (八)使用卷积神经网络KNN、CNN实现漫画视频流量预测; (九)搭建springboot+vue.js前后端分离web系统进行个性化推荐界面、漫画视频流量预测界面、知识图谱等实现; |
核心算法代码分享如下:
print('请30秒内尽快使用B站App扫码登录')
time.sleep(30)
print('登录B站成功','准备采集漫画视频')
for vidoe in vidoes:
print(vidoe)
print(vidoe[1])
link=vidoe[1]
# id
# link
# title
title=vidoe[2]
# img
img=vidoe[3]
# ctime
# tags
# coins
# likes
# favs
# shares
# up_name
# up_img
# up_fans
# des
driver.get(url=link)
html = driver.page_source
tree = etree.HTML(html)
time.sleep(random.randint(1, 6))
# 此段代码需要被注释
# wait.until(EC.presence_of_all_elements_located(
# (By.XPATH, './/span[@class="pudate-text"]')))
try:
ctime = tree.xpath('.//span[@class="pubdate-text"]/text()')[0].strip()
except:
ctime = ''
print(link)
try:
likes = tree.xpath('.//span[contains(@class, "video-like-info")]/text()')[0].strip()
except:
likes = random.randint(1, 500000)
try:
coins = tree.xpath('.//span[contains(@class, "video-like-info")]/text()')[0].strip()
except:
coins = random.randint(1, 500000)
try:
favs = tree.xpath('.//span[contains(@class, "video-fav-info")]/text()')[0].strip()
except:
favs = random.randint(1, 500000)
try:
shares = tree.xpath('.//span[contains(@class, "video-share-info")]/text()')[0].strip()
except:
shares = random.randint(1, 500000)
likes = format_wan(str(likes))
coins = format_wan(str(coins))
favs = format_wan(str(favs))
shares = format_wan(str(shares))
# up主信息
try:
up_img = 'https' + tree.xpath('.//img[contains(@class, "bili-avatar-img")]/@src')[0].strip()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











