




 一位拥有100万粉丝的博主介绍其团队专注于计算机专业毕业设计项目实战,提供源码获取和代做服务,同时分享项目选题和展示图片,解答毕设相关问题。
一位拥有100万粉丝的博主介绍其团队专注于计算机专业毕业设计项目实战,提供源码获取和代做服务,同时分享项目选题和展示图片,解答毕设相关问题。
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
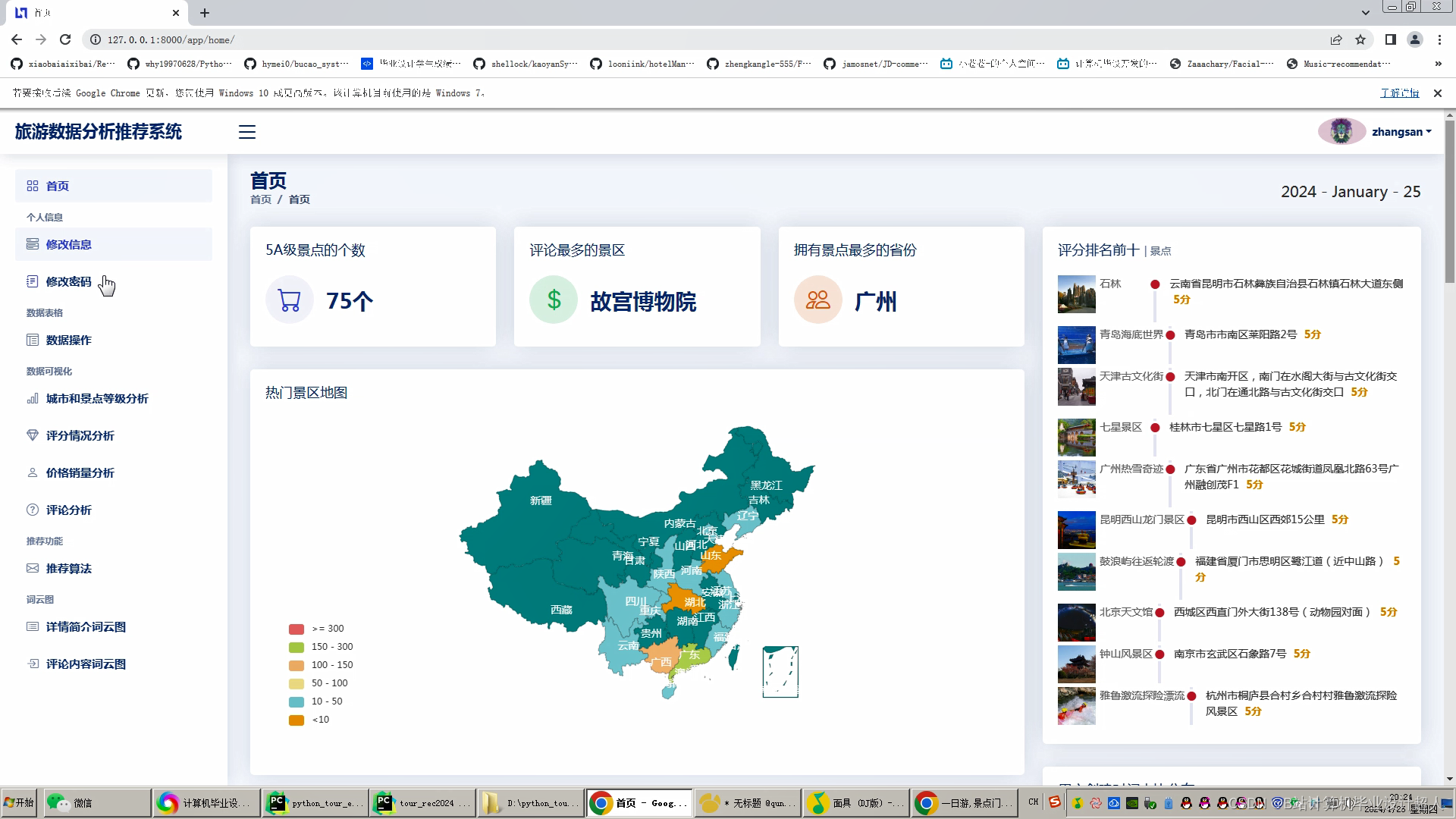
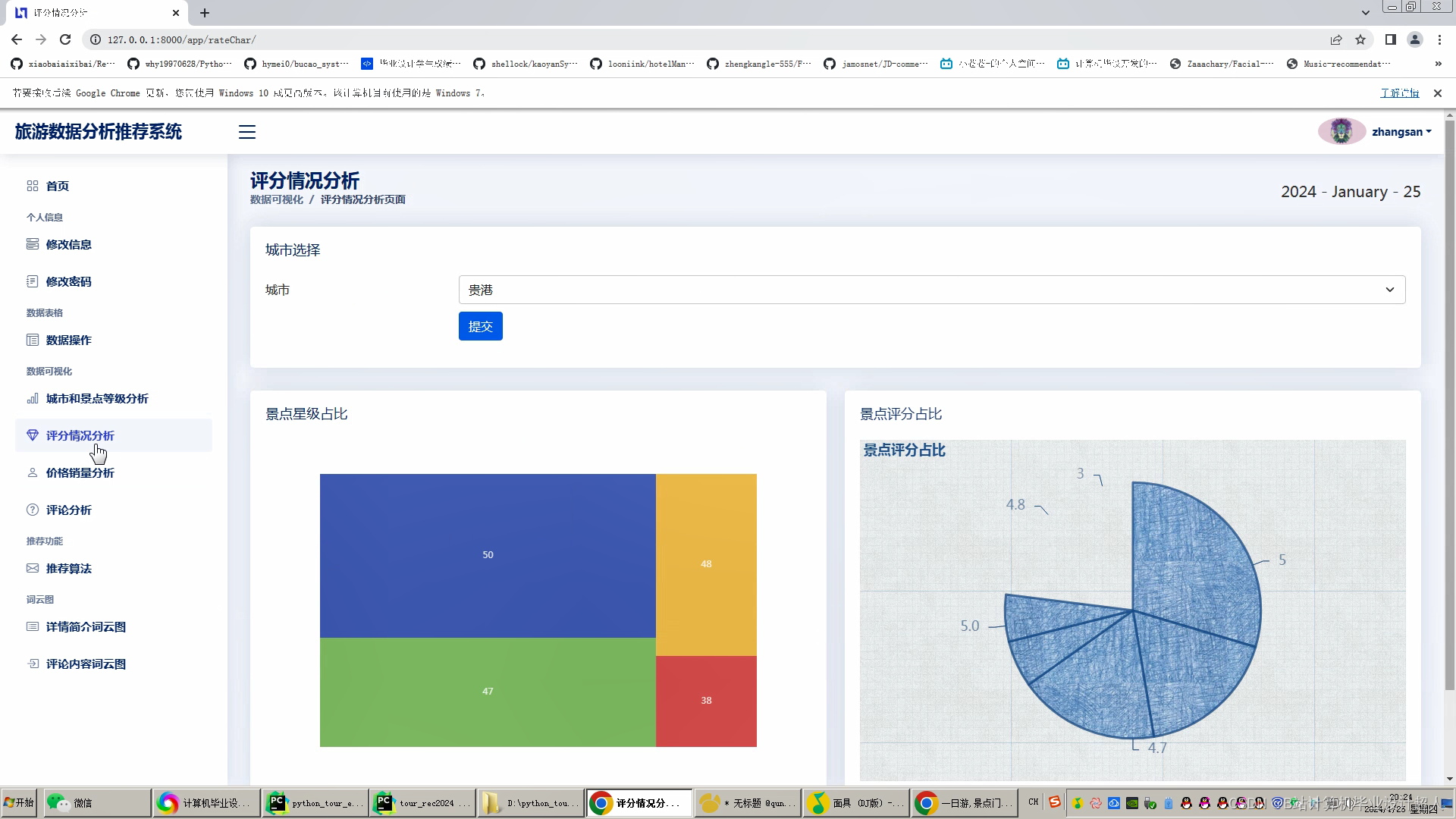
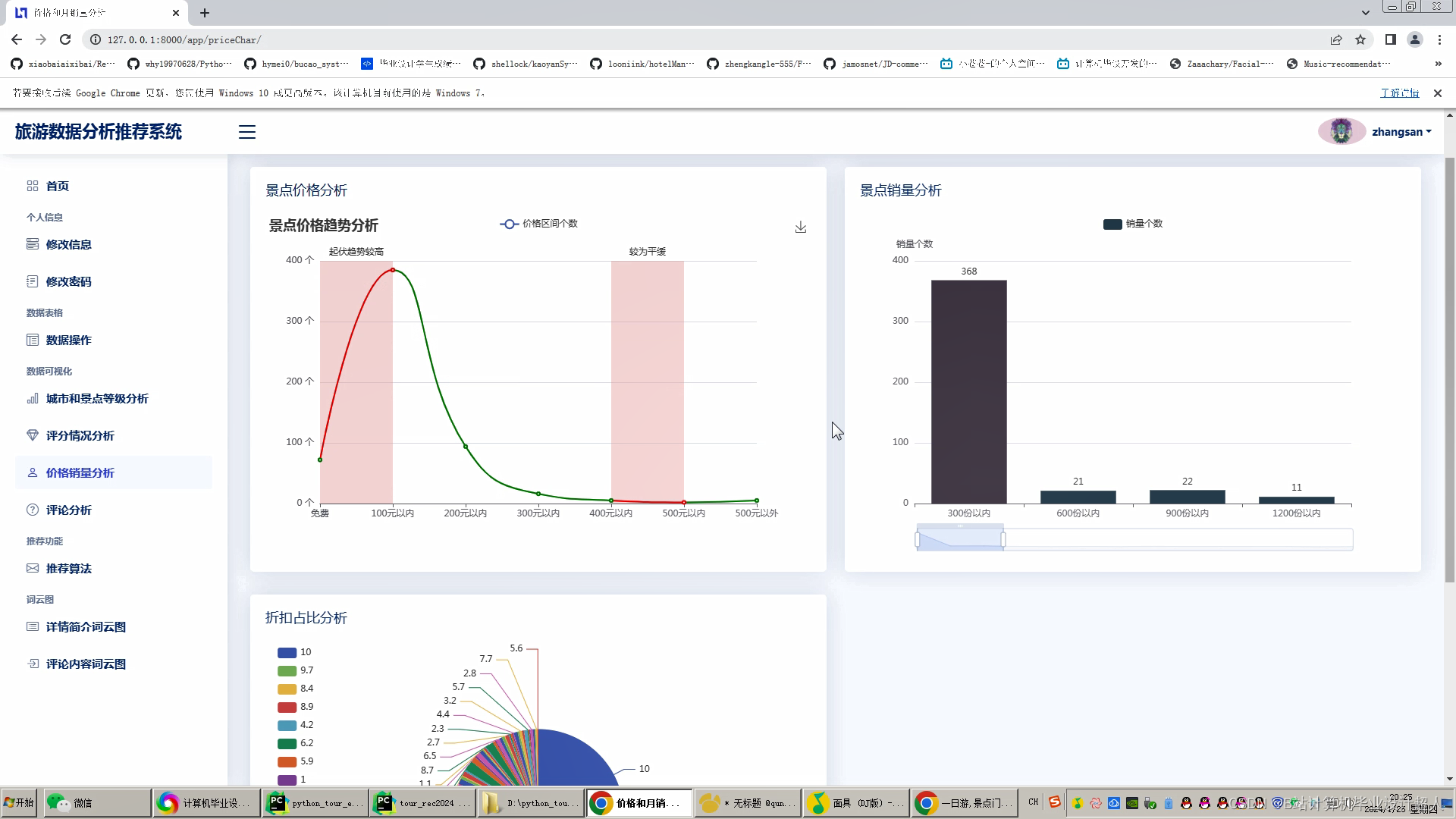
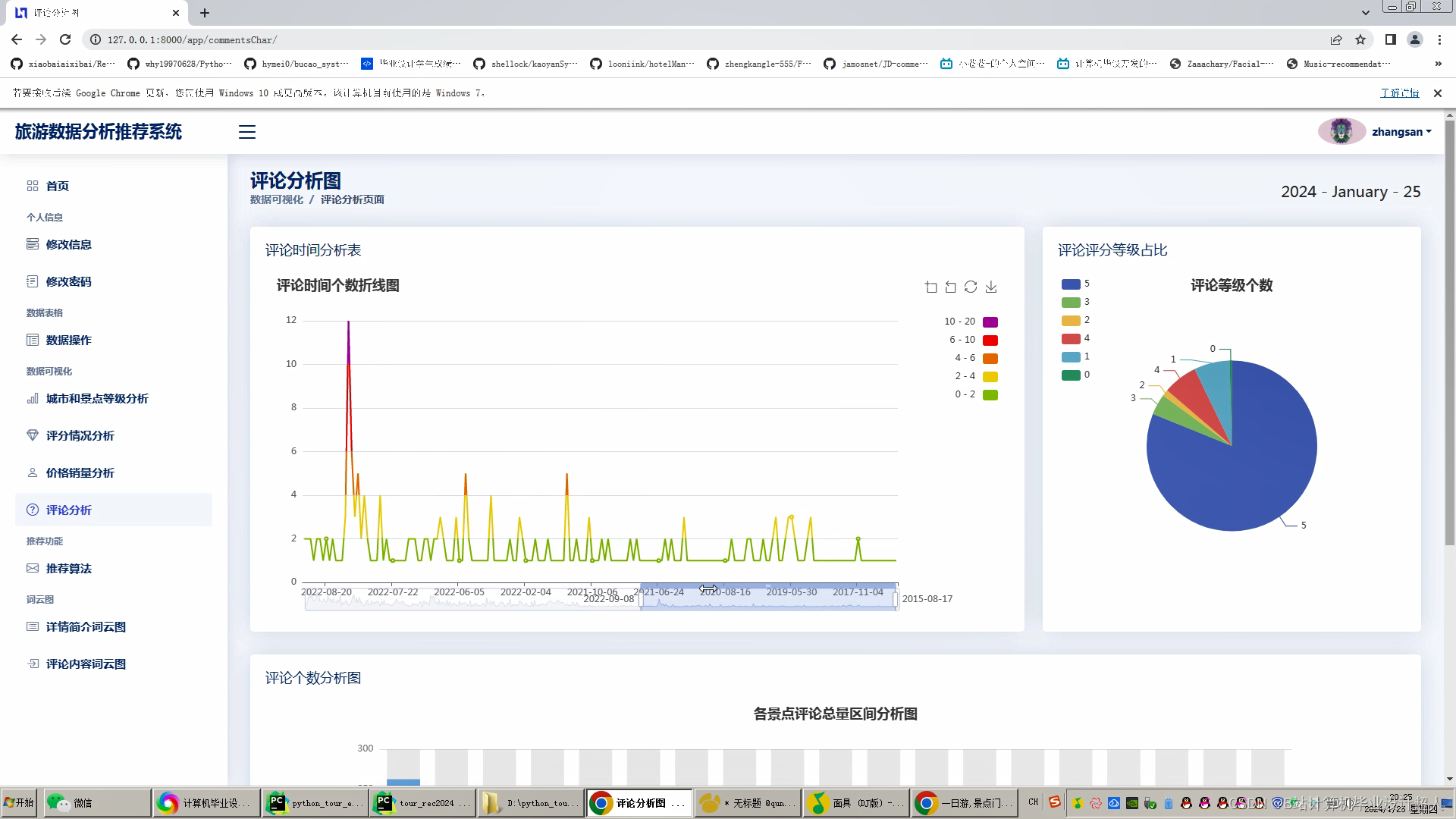
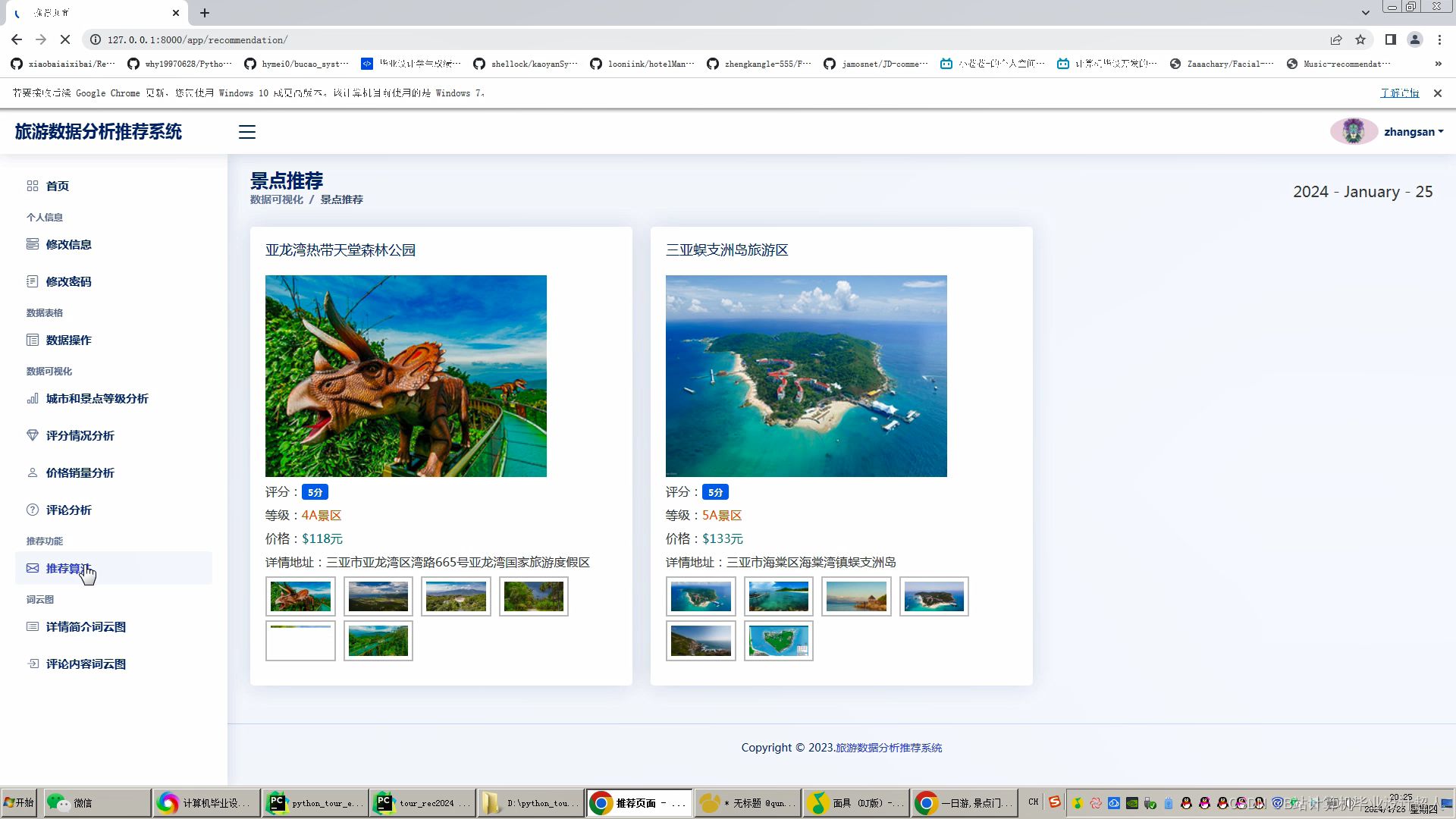
文章包含:项目选题 + 项目展示图片 (必看)
pip install requests beautifulsoup4
import requests
from bs4 import BeautifulSoup
def get_travel_destinations(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # 检查请求是否成功
soup = BeautifulSoup(response.text, 'html.parser')
# 假设旅游目的地列表在一个具有特定类的div中
destinations = soup.find_all('div', class_='destination-item')
travel_dests = []
for dest in destinations:
# 提取目的地名称
name = dest.find('h3').text.strip()
# 提取目的地描述或简介
description = dest.find('p', class_='description').text.strip() if dest.find('p', class_='description') else ''
# 提取目的地链接
link = dest.find('a')['href'] if dest.find('a') else ''
travel_dests.append({
'name': name,
'description': description,
'link': link
})
return travel_dests
except requests.RequestException as e:
print(f"An error occurred while fetching the webpage: {e}")
return []
# 示例:爬取某个旅游网站的旅游目的地信息
travel_website_url = 'https://example.com/travel-destinations' # 替换为实际的旅游网站URL
destinations = get_travel_destinations(travel_website_url)
if destinations:
for dest in destinations:
print(f"Name: {dest['name']}")
print(f"Description: {dest['description']}")
print(f"Link: {dest['link']}\n")


















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











