



作为数据库工程师,维护 Schema(用户)级别的统计信息是确保数据库整体性能的关键工作。Oracle 的DBMS_STATS.GATHER_SCHEMA_STATS存储过程专门用于批量收集指定 Schema 下所有对象(表、索引、分区表等)的统计信息,相比单表统计工具GATHER_TABLE_STATS,它能更高效地处理批量对象,尤其适合全量更新或定期维护场景。本文将从核心原理、参数详解、场景化示例及最佳实践四个维度,系统讲解如何使用该工具进行 Schema 级数据统计分析。
一、核心作用与原理
DBMS_STATS.GATHER_SCHEMA_STATS的核心功能是批量收集指定 Schema 下所有对象的统计信息,包括:
- 表级统计:各表的总行数、数据块数、平均行长度等;
- 列级统计:各表列的 distinct 值、null 值数量、数据分布(直方图)等;
- 索引统计:所有索引的深度、叶子块数、索引键分布等;
- 分区对象统计:分区表 / 索引的分区级、子分区级统计(需通过
granularity参数控制)。
这些统计信息存储在数据字典(如DBA_TABLES、DBA_TAB_COLUMNS、DBA_INDEXES)中,优化器依赖这些信息判断执行路径成本,生成最优 SQL 计划。对于包含成百上千张表的 Schema,使用该工具可避免逐表手动收集,大幅提升维护效率。
二、基础语法与核心参数
1. 基本语法
plsql
DBMS_STATS.GATHER_SCHEMA_STATS(
ownname => 'Schema名称', -- 目标Schema(必选,区分大小写)
estimate_percent => 采样比例, -- 数据采样比例(默认AUTO_SAMPLE_SIZE)
block_sample => TRUE/FALSE, -- 是否按块采样(默认FALSE,按行采样)
method_opt => '统计收集选项', -- 控制列/索引统计细节(如直方图)
degree => 并行度, -- 并行收集线程数(默认1,串行)
granularity => '粒度', -- 分区对象的统计粒度(如'ALL')
cascade => TRUE/FALSE, -- 是否收集索引统计(默认FALSE)
stattab => '统计信息表名', -- 存储统计的用户表(默认数据字典)
statid => '统计标识', -- 区分多套统计(配合stattab)
options => '收集范围', -- 如'GATHER'(全量)、'GATHER AUTO'(增量)等
objlist => 输出参数(对象列表), -- 存储被处理的对象信息(PL/SQL集合)
statown => '统计信息表所属用户', -- stattab的所有者(默认当前用户)
no_invalidate => TRUE/FALSE, -- 是否使依赖游标失效(默认FALSE)
force => TRUE/FALSE, -- 强制收集(即使统计最新,默认FALSE)
flush_cache => TRUE/FALSE, -- 收集前刷新缓冲区(默认FALSE)
obj_filter_list => 过滤条件, -- 筛选需收集的对象(如排除特定表)
concurrent => TRUE/FALSE -- 是否并发收集(12c+,默认FALSE)
);
2. 核心参数详解(与表级工具的差异与重点)
| 参数 | 关键说明 | 常用取值示例 |
|---|---|---|
ownname | 目标 Schema 名称(必选),需区分大小写(如 'HR'、'SALES'),不可默认当前用户(需显式指定)。 | 'ERP'、'ECOMMERCE' |
options | 最核心参数,控制收集范围,直接影响效率:- 'GATHER':收集 Schema 下所有对象(全量,耗时最长)- 'GATHER AUTO':仅收集 “统计信息过期” 的对象(数据变化率 > 10% 或从未收集,推荐日常维护)- 'GATHER STALE':仅收集 “数据有变更” 的对象(需开启监控,DBMS_STATS.ENABLE_STATISTICS_MONITORING)- 'GATHER EMPTY':仅收集 “从未收集过统计” 的对象(适合新 Schema 初始化) | 'GATHER AUTO'(日常维护)、'GATHER EMPTY'(新库) |
obj_filter_list | 筛选需收集的对象(排除临时表、测试表等),通过DBMS_STATS提供的函数构造:- DBMS_STATS.OBJ_FILTER_LIST('TABLE', 'NOT LIKE ''TEST_%'''):排除表名以 TEST_开头的表- 支持按类型(TABLE/INDEX)、名称过滤 | 见场景示例 5 |
concurrent | 12c + 新增,是否并发收集多对象(利用后台进程,不阻塞当前会话):- TRUE:异步并发(适合大 Schema,不占用当前会话)- FALSE(默认):同步收集(当前会话等待完成) | TRUE(大 Schema 批量收集) |
granularity | 分区对象的统计粒度(同表级,但作用于整个 Schema 的分区对象):- 'ALL'(默认):全量 + 分区 + 子分区- 'AUTO':Oracle 自动判断(推荐,减少冗余) | 'AUTO'(分区表较多时) |
其他参数(如estimate_percent、method_opt、degree等) | 与GATHER_TABLE_STATS含义一致,作用于 Schema 内所有对象(可理解为 “批量应用表级参数”)。 | 同表级工具,如estimate_percent => 5、method_opt => 'FOR ALL COLUMNS SIZE AUTO' |
三、场景化使用示例
1. 基础场景:日常维护(仅收集过期统计)
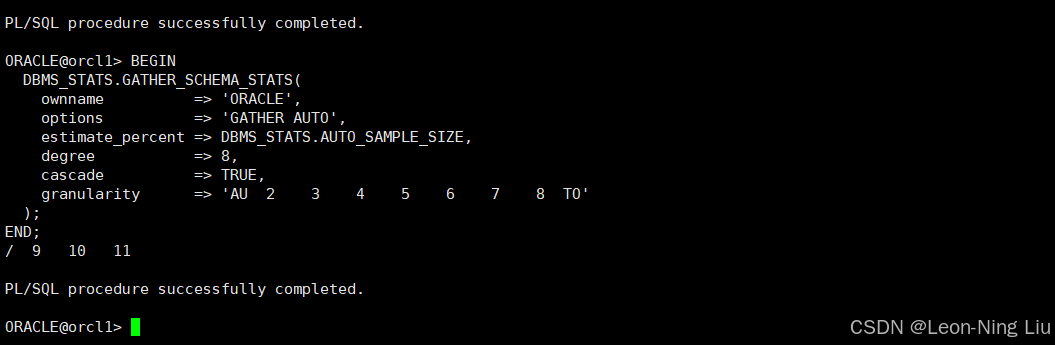
对ORACLE Schema 执行日常维护,仅收集统计信息过期的对象(自动判断),同时收集索引统计,并行加速:
plsql
BEGIN
DBMS_STATS.GATHER_SCHEMA_STATS(
ownname => 'ORACLE',
options => 'GATHER AUTO', -- 仅处理过期对象,效率高
estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE, -- 自动采样
degree => 8, -- 8线程并行
cascade => TRUE, -- 同步收集索引统计
granularity => 'AUTO' -- 分区对象自动粒度
);
END;
/
2. 新 Schema 初始化:收集所有空统计对象
新上线的ORACLE Schema 中,部分表未收集过统计,需初始化:
BEGIN
DBMS_STATS.GATHER_SCHEMA_STATS(
ownname => 'ORACLE',
options => 'GATHER EMPTY', -- 仅处理从未收集过统计的对象
estimate_percent => 100, -- 小表全量扫描,确保准确
cascade => TRUE,
degree => 4
);
END;
/

说明:新表统计为空时,优化器可能生成低效计划(如默认表大小为 1 行),初始化是必要的。
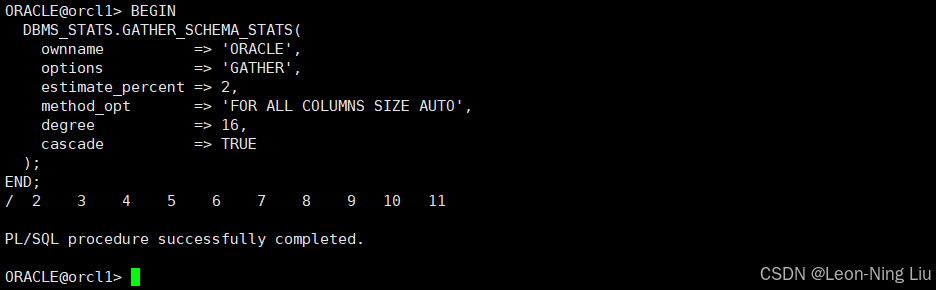
3. 大 Schema 全量更新:低采样 + 并发收集
对包含 1000 + 张表的ORACLE Schema(含大量亿级行大表)执行全量统计更新,优先效率:
BEGIN
DBMS_STATS.GATHER_SCHEMA_STATS(
ownname => 'ORACLE',
options => 'GATHER', -- 全量收集(如批量导入后)
estimate_percent => 2, -- 大表低采样,平衡速度与准确性
method_opt => 'FOR ALL COLUMNS SIZE AUTO', -- 自动直方图
degree => 16, -- 高并行加速
cascade => TRUE,
concurrent => TRUE -- 12c+异步并发,不阻塞当前会话
);
END;
/
适用场景:季度数据归档后、大批量数据导入后,需全量更新统计。
4. 排除特定对象:过滤临时表和测试表
HR Schema 中包含TEMP_前缀的临时表和TEST_前缀的测试表,收集时需排除:
DECLARE
v_filter DBMS_STATS.OBJ_FILTER_LIST_T; -- 定义过滤列表类型
BEGIN
-- 构造过滤条件:排除表名以TEMP_或TEST_开头的表
v_filter := DBMS_STATS.OBJ_FILTER_LIST(
object_type => 'TABLE', -- 仅过滤表(索引不受影响)
name_filter => 'NOT (TABLE_NAME LIKE ''TEMP\_%'' ESCAPE ''\'' OR TABLE_NAME LIKE ''TEST\_%'' ESCAPE ''\'')'
);
DBMS_STATS.GATHER_SCHEMA_STATS(
ownname => 'ORACLE',
options => 'GATHER AUTO',
obj_filter_list => v_filter, -- 应用过滤条件
cascade => TRUE,
degree => 4
);
END;
/
说明:临时表 / 测试表数据频繁变更,统计信息意义不大,排除可减少资源浪费。
5. 备份 Schema 统计信息(用于回滚)
收集ERP Schema 统计后,备份到ERP_STATS表,防止统计异常时回滚:
-- 1. 先创建存储统计的表(仅需一次)
BEGIN
DBMS_STATS.CREATE_STAT_TABLE(
ownname => 'ERP',
stattab => 'ERP_STATS'
);
END;
/
-- 2. 收集并备份统计
BEGIN
DBMS_STATS.GATHER_SCHEMA_STATS(
ownname => 'ERP',
options => 'GATHER AUTO',
stattab => 'ERP_STATS', -- 存储到用户表
statid => 'ERP_STATS_202405', -- 标识此次备份
cascade => TRUE
);
END;
/
四、验证统计信息是否生效
收集完成后,通过以下视图验证 Schema 级统计是否更新:
sql
-- 1. 检查表级统计(随机抽查几张表的最后收集时间)
SELECT TABLE_NAME, NUM_ROWS, LAST_ANALYZED
FROM DBA_TABLES
WHERE OWNER = 'ERP'
ORDER BY LAST_ANALYZED DESC;
-- 2. 检查索引统计(确认cascade参数生效)
SELECT INDEX_NAME, TABLE_NAME, LAST_ANALYZED
FROM DBA_INDEXES
WHERE OWNER = 'ERP'
ORDER BY LAST_ANALYZED DESC;
-- 3. 检查分区表统计(确认granularity参数生效)
SELECT TABLE_NAME, PARTITION_NAME, NUM_ROWS, LAST_ANALYZED
FROM DBA_TAB_PARTITIONS
WHERE TABLE_OWNER = 'ERP'
ORDER BY LAST_ANALYZED DESC;
五、最佳实践与注意事项
- 执行时机:选择业务低峰期(如凌晨)执行,尤其全量收集(
options => 'GATHER')可能消耗大量 CPU 和 I/O。 - options 参数选择:
- 日常维护优先
'GATHER AUTO'(仅处理过期对象,效率最高); - 新 Schema 初始化用
'GATHER EMPTY'; - 批量数据变更后用
'GATHER STALE'(需先开启监控:EXEC DBMS_STATS.ENABLE_STATISTICS_MONITORING;)。
- 日常维护优先
- 采样策略:
- 小表(<100 万行):
estimate_percent => 100(全量,确保准确); - 大表(>1 亿行):
estimate_percent => 1~5(低采样,减少耗时); - 数据倾斜表集中的 Schema:
method_opt => 'FOR ALL COLUMNS SIZE AUTO'(强制自动生成直方图)。
- 小表(<100 万行):
- 并行度控制:并行度(
degree)建议不超过 CPU 核心数的 50%(如 16 核 CPU 设为 8),避免资源竞争导致业务阻塞;RAC 环境可适当提高(利用多节点资源)。 - 排除无关对象:通过
obj_filter_list排除临时表(GLOBAL TEMPORARY TABLE)、日志表、测试表,这些表统计信息对优化器意义不大,且频繁变更会导致统计频繁过期。 - 与自动任务配合:Oracle 默认通过
AutoTask(每天 22:00-2:00)自动执行GATHER_SCHEMA_STATS,但对于高频变更的核心 Schema(如订单库),建议在批量操作后手动补充执行(force => TRUE)。 - 回滚机制:若收集后出现执行计划恶化,用备份的统计信息回滚:
plsql
BEGIN DBMS_STATS.RESTORE_SCHEMA_STATS( ownname => 'ERP', stattab => 'ERP_STATS', statid => 'ERP_STATS_202405' ); END; /
总结
DBMS_STATS.GATHER_SCHEMA_STATS是 Schema 级统计维护的核心工具,其高效性和批量处理能力使其成为数据库工程师的必备技能。实际使用中,需根据 Schema 的对象规模、数据特性及业务场景,灵活调整options、estimate_percent、obj_filter_list等参数,在 “统计准确性” 与 “系统资源消耗” 间找到平衡,最终确保优化器始终基于可靠的统计信息生成最优执行计划,提升数据库整体性能。

















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









