







一、安装LMDeploy
pip install lmdeploy直接使用pip install会下载很久,后来在官网发现

租用的机器CUDA版本是11.8,所以下载了这么久的原因可能是CUDA版本冲突了。
export LMDEPLOY_VERSION=0.3.0
export PYTHON_VERSION=38
pip install https://github.com/InternLM/lmdeploy/releases/download/v${LMDEPLOY_VERSION}/lmdeploy-${LMDEPLOY_VERSION}+cu118-cp${PYTHON_VERSION}-cp${PYTHON_VERSION}-manylinux2014_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu118二、模型转换(离线转换)
cd到MedQA文件夹下,执行如下命令。
convert后的internlm2-chat-1_8b指的是模型的名称,merged则是微调后的大模型所在文件夹的名称
lmdeploy convert internlm2-chat-1_8b merged执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。
三、TurboMind 推理+命令行本地对话
执行
lmdeploy chat turbomind ./workspace可以在命令行中进行对话
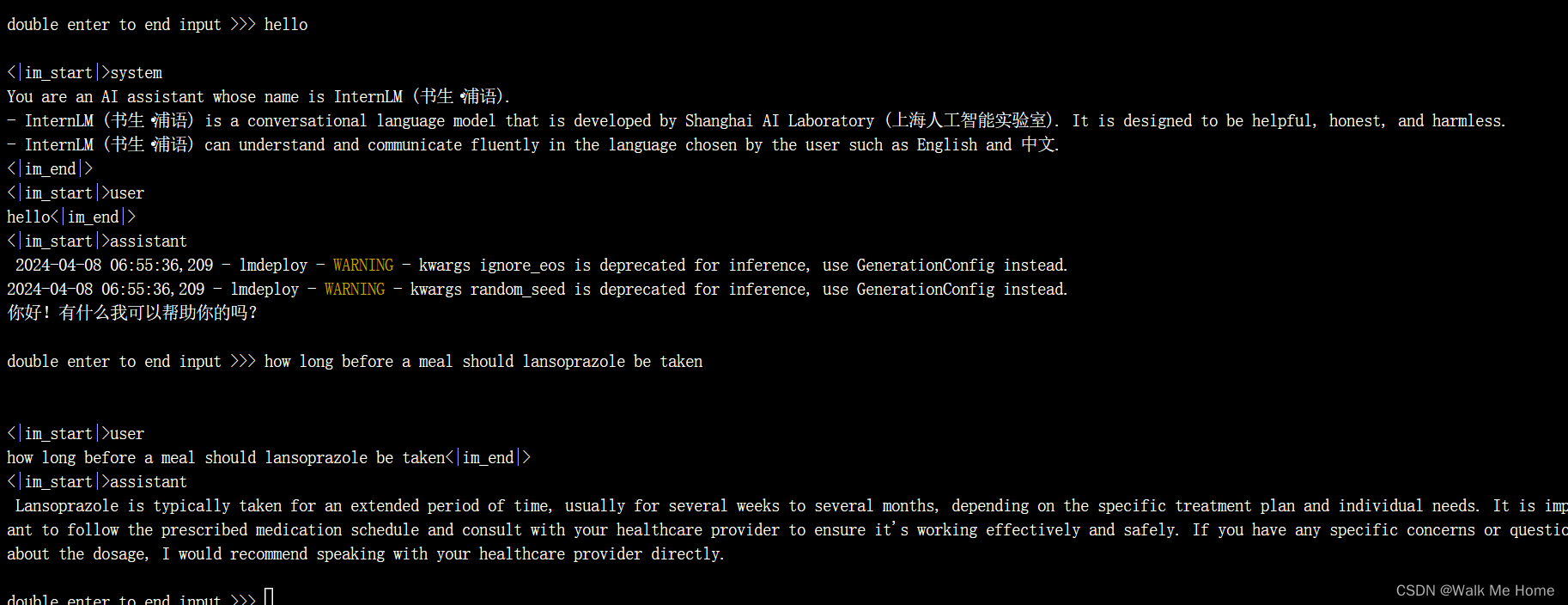
TurboMind 推理+命令行本地对话测试成功
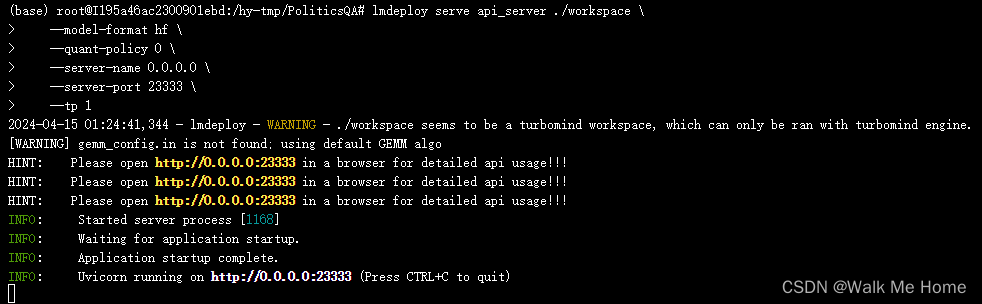
四、TurboMind推理+API服务
执行如下命令
lmdeploy serve api_server ./workspace \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1其中,model-format、quant-policy这些参数是与第三章中量化推理模型一致的;server-name和server-port表示API服务器的服务IP与服务端口;tp参数表示并行数量(GPU数量)。
这里有一个版本问题,如果下载的LMDeploy是最新的3.0版本,参数的下划线都变成了短横线,如果含有效下划线则无法识别参数。
成功运行,这个终端作为server。
另外新建一个终端
# ChatApiClient+ApiServer(注意是http协议,需要加http)
lmdeploy serve api_client http://localhost:23333成功运行,给server发一条信息

作为server的终端收到了一条post请求
五、TurboMind推理+API服务(本地机器访问)
这一步由于 Server 在远程服务器上,所以本地需要做一下 ssh 转发才能直接访问
在恒源云我的实例中查看登录指令。

登录指令如下
ssh -p 29636 root@i-2.gpushare.com29636即为本地需要转发到的端口号,root@i-2.gpushare.com是主机
在你本地打开一个cmd窗口,输入命令如下:(这条命令主机和端口都修改成了我的)
ssh -CNg -L 23333:127.0.0.1:23333 root@i-2.gpushare.com -p 29636 然后复制密码,输入。如果输入的不对,会提示Permission denied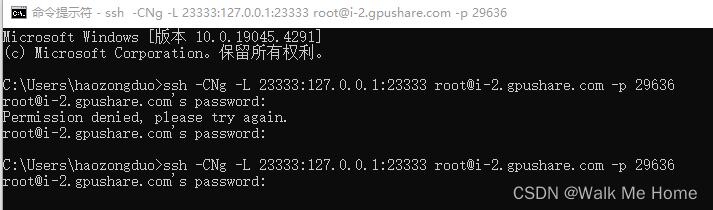
当输入完密码后没有反应,说明已经登录好了
直接在浏览器访问http://127.0.0.1:23333
成功访问到FastAPI
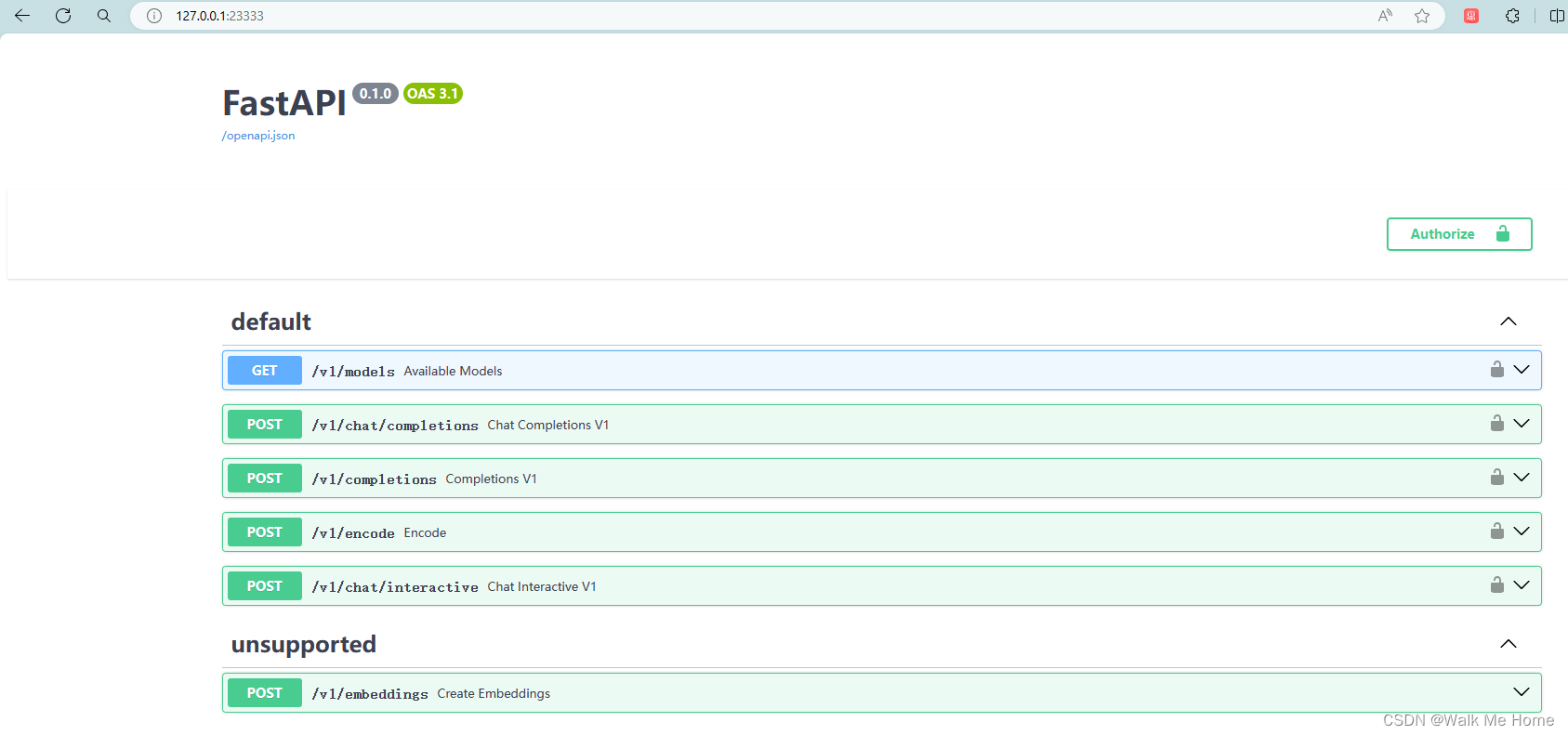
TurboMind推理+API服务测试成功。
六、TurboMind推理+gradio前端
执行以下命令
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006报错ModuleNotFoundError: No module named 'gradio'
这里一定要下小于4.0.0版本的gradio
经过反复下载了多个版本的gradio。发现小于4的版本中过高和过低都会有各种报错。最后发现这个版本的报错少一些。
pip install gradio==3.50.2
如果出现下列报错,则需pip3 install httpx==0.24.1
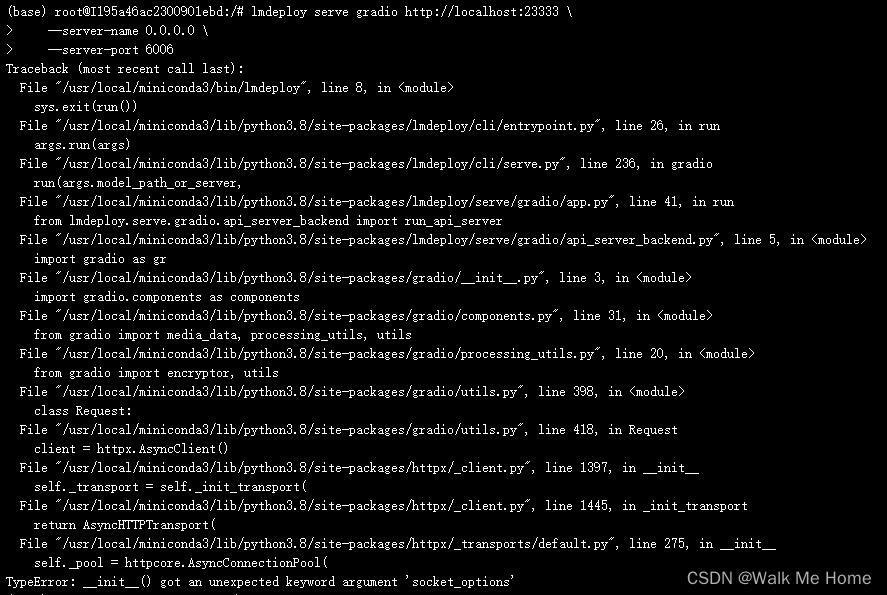
运行成功后,在本地打开命令行,输入
ssh -CNg -L 6006:127.0.0.1:6006 root@i-2.gpushare.com -p 29636然后在浏览器访问。
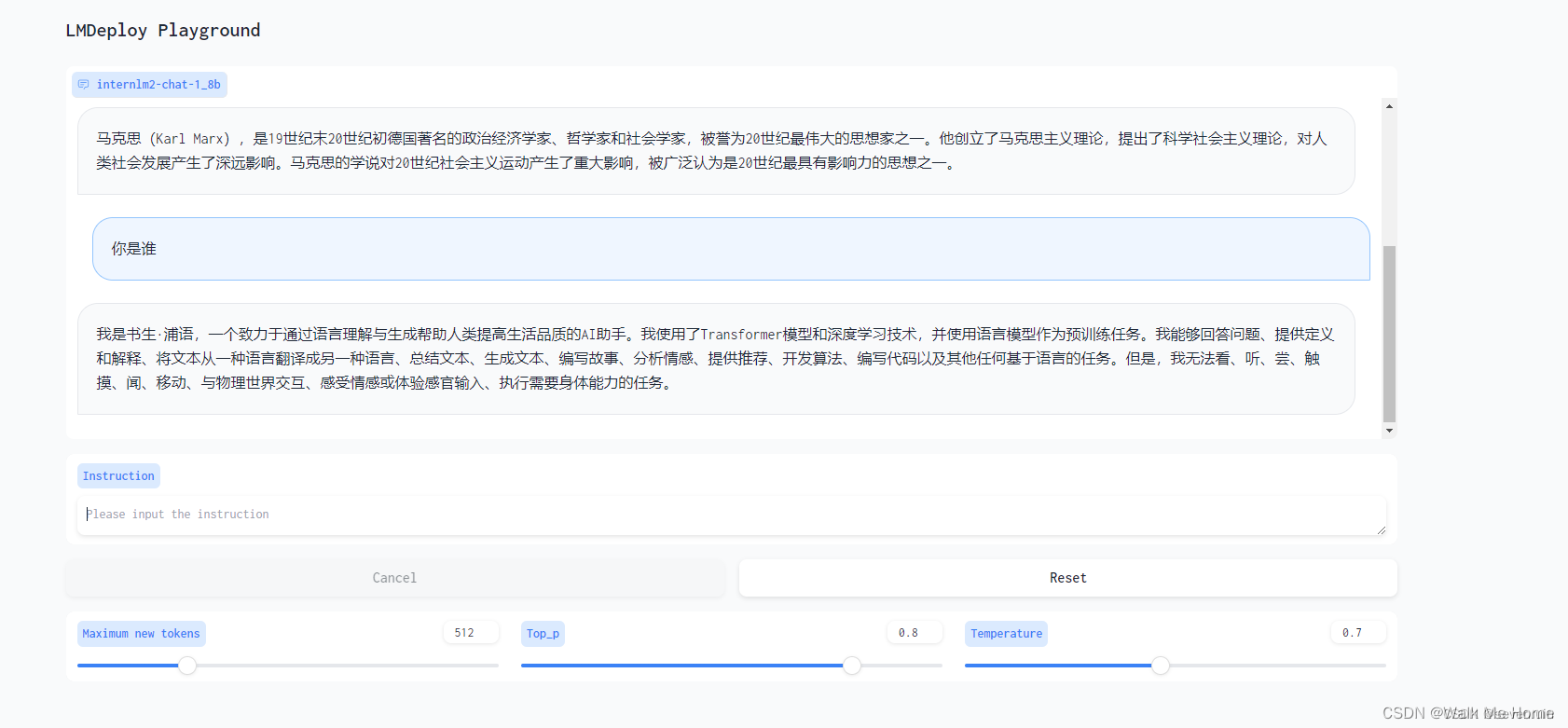
效果如下
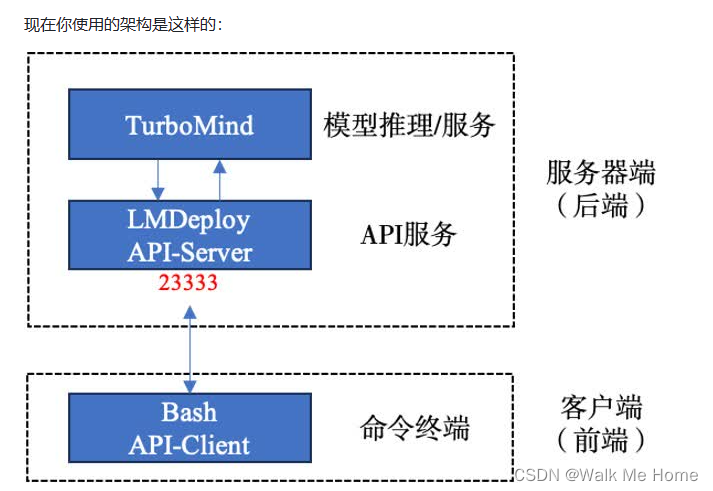
现在你使用的架构是这样的:

自此完成


















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









