 编程学习:从《深入理解计算机系统》看学习路径
编程学习:从《深入理解计算机系统》看学习路径




 本文作者阿秀分享了自己阅读《深入理解计算机系统》的体验,指出这本书虽被誉为神书,但因其深度和厚度可能不适合初学者。建议学习编程时选择适合自己的资料,逐步积累前置知识。推荐了《编码-隐匿在计算机软硬件背后的语言》、《汇编语言》和《C-语言程序设计》作为辅助学习资源。强调学习过程需耐心,不必急于求成,建议先理解计算机基础,如计算机组成原理和操作系统,再深入学习其他技术。
本文作者阿秀分享了自己阅读《深入理解计算机系统》的体验,指出这本书虽被誉为神书,但因其深度和厚度可能不适合初学者。建议学习编程时选择适合自己的资料,逐步积累前置知识。推荐了《编码-隐匿在计算机软硬件背后的语言》、《汇编语言》和《C-语言程序设计》作为辅助学习资源。强调学习过程需耐心,不必急于求成,建议先理解计算机基础,如计算机组成原理和操作系统,再深入学习其他技术。

作者:阿秀
阿秀的求职笔记:https://interviewguide.cn
你好,我是阿秀。
今天简单聊聊编程学习这个话题,以《深入理解计算机系统》这本书为例简单聊聊,我刚开始看这本书的时候觉得自己像个傻子 。
。
如果你像我一样是个知乎重症玩家,而你关注的一些话题又是计算机、编程、程序员相关,那你估计很容易刷到一些编程书单,很多人都会在社交媒体上分享自己读过的编程类书籍。

1、神书
我相信,有一本书你一定不陌生,那就是《深入理解计算机系统》,也就是《CSAPP》。
知乎上关于这本书的讨论也有很多。
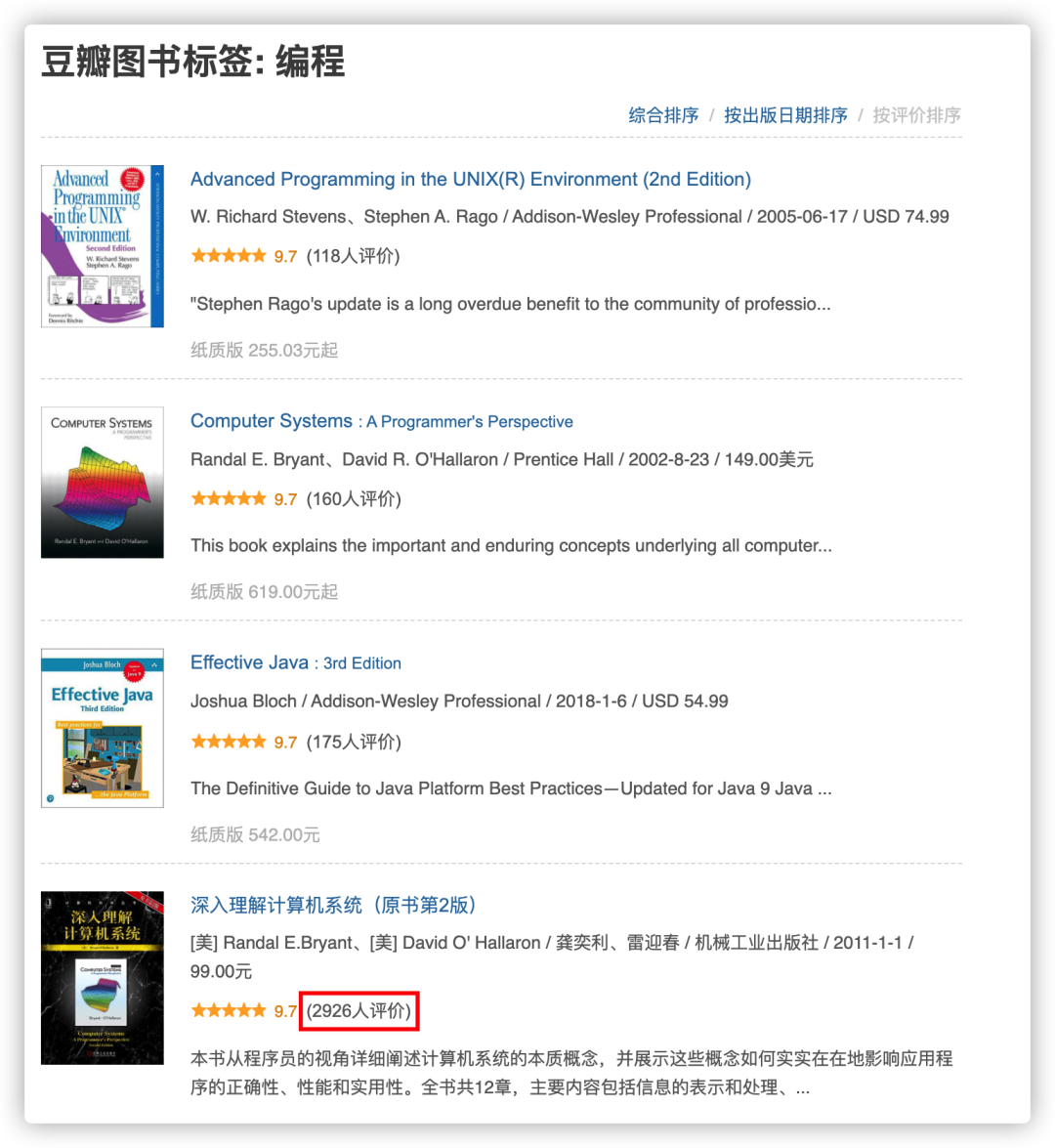
这是本神书,去豆瓣读书上看下它的评分就能知道它确实是本神书。
首先在豆瓣读书上选中编程的标签,然后你就可以发现豆瓣读书编程类最高分就是9.7分。
其中Top5,能够兼顾分值和评论人数的编程类书籍只有这本CSAPP,它不仅有着9.7分的高分,同时也有着高达 2926 人的评论人次。
这本书好吗?
肯定好,有多达3000人给出了自己的评分,最后得到了平均分为9.7.肯定好。
那,请问你看得下去吗?
我想大多数人跟最开始的我一样,根本看不下去。
看不下去的原因应该有很多,但下面两个应该是最高频的:
第一,太厚了,这本书就跟那本800多页的《C++ Primer 5th》 一样,又厚又重,多达700多页。
最适合垫泡面了,大多数人还没开始看就直接被劝退了。

为啥我记得C++ Primer 5th有八百多页呢?因为我看了两三遍...
第二,看不懂。
我想更多人是被第二个原因劝退了。
那为什么会看不懂?
看不懂的原因先放在一边,先来看看这本书的主要内容有哪些?
老实说这本书的覆盖面其实真的很广,它不仅仅只是计算机系统,更准确的说是计算机基础中的《计算机组成原理》和《操作系统》的混合体。
从机器级别的指令、CPU的工作方式、存储结构和优化,到程序I/O、计算机网络、程序性能优化,甚至并行程序设计都有所涉及,其中很多话题都能再次展开,并深入。
毫不客气的说,这一本经典可以继续演变成N本经典。
这本书的主要内容其实可以分为以下六个主题:
计算机信息的表示(如何使用二进制表示数字,比如整型、浮点数等)
C语言和汇编语言的学习(通过汇编语言更深入地理解C语言是什么)
计算机体系结构的基本介绍(比如存储层次结构、局部性原理、处理器体系结构等)
编译链接(可执行文件是怎么来的、静态链接和动态链接的区别)
操作系统的使用(异常控制流、虚拟内存等)
网络及并发编程(并发、并行、系统调用)
2、原因
看到这里,其实你应该已经知道你看不懂这本书的原因了:这是本好书,但很可能不适合现阶段的你。
因为看这本书需要很多前置知识,你至少应该懂最基本的C语言以及一部分的汇编知识再来看这本书。
CSAPP这本书是我在14年,上大二的时候就买的,当时买的还是印影版,后来读研的时候实验室有图书报销机会,我去买了第三版正版。
现在我床头边就放着三本书,一本是余华老师的《活着》,一本是DDIA,也就是《设计数据密集型应用》。
还有一本就是《深入理解计算机系统》,经常会翻一翻。
CASPP这本书一开始我也是看不懂,后来重复地翻开,断断续续的去看,每次看都会有不一样的感受。
所以编程学习也是类似,有时候可能并不是你太笨学不会一些语言或者技术,而是是你学习的方式有误或者你使用的资料暂时不适合你。
等过一段时间你再来看以前被你搁置在一旁的书,你可能会觉得怎么看怎么懂了。
比向上攀登更重要的是选对方向去攀登。
类似的还有《算法导论》就好像知乎上有人问怎么学数据结构与算法一样,很多人一推荐就是那本经典的《算法导论》。

这也是本好书,但推荐它的人十个里可能没有一个完整看完这本书的,更甚者可能有的人自己都没翻过这本书就跑去给别人推荐。
Always learn from the best!
3、多说(水)两句
学习的过程是不能急的,特别是还在上大学的学弟学妹们,你们有大把连续的时间,这就是你们的资本。
资本运用好了叫资本,没运用好就不叫资本了。
如果你真的想学好编程,甚至日后把编程作为自己的主业,依靠编程谋生的话,建议你好好的学一下计算机的前世今生,做到彻头彻尾的理解计算机的原理。
而不是仅仅停留在表面,直接照猫画虎、照葫芦画瓢,这样的基本都会被淘汰,无法从事程序设计工作,最终整天从事重复性工作。
话都说到这里了,如果你打算看CSAPP,给你推荐一些切实可行而非直接劝退学习资源吧。
《编码 - 隐匿在计算机软硬件背后的语言》能帮你了解计算机是如何表示数字的;
《汇编语言》不要被书名吓到了,王爽老师的这本书绝对会让你感到相见恨晚;
《C-语言程序设计》,这个就不介绍了吧。
除此之外,对于操作系统、计算机网络、数据库等知识的学习也是如此,不要在最开始的时候就去看一些大头书,妥妥的劝退自己。
最近在和几个朋友一起写点比较好入手的学习资料&路线,至少学起来不会劝退&打击自己,对一些像我这样自学过来的同学比较友好,已经更新完计算机网络、操作系统、C++和Golang的知识了。

剩下的都会慢慢更新&同步上来:https://github.com/awesome-cs-community/developer-roadmap-zh-CN
剩下的会慢慢更新,今天就先水到这里吧,溜了溜了 。
。
参考文献:https://zhuanlan.zhihu.com/p/38584767
我是阿秀,一个平凡的互联网打工仔,我们下期再见。

推荐👍:求职硬实力(操作系统、计算机网络、数据库MySQL、Redis等)
推荐👍:求职软实力(面试、话术、简历)
你好,我是阿秀,本硕均于普通双非学校就读,现于抖音旗下担任全栈研发工程师,前后端全能。一路走来,很累也很不容易,希望能帮助到更多像我一样的普通学校的学生。我踩的坑不希望你再踩,我走过的路希望你照着走下来。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











