






 本文介绍了回调函数的概念,通过Python示例展示了如何在多进程中使用回调函数处理任务结果,例如从网页获取源码大小,并将其保存到文件。此外,还提供了爬取福布斯全球排行榜并进行数据解析的例子,利用回调函数处理爬取结果。
本文介绍了回调函数的概念,通过Python示例展示了如何在多进程中使用回调函数处理任务结果,例如从网页获取源码大小,并将其保存到文件。此外,还提供了爬取福布斯全球排行榜并进行数据解析的例子,利用回调函数处理爬取结果。
十七.回调函数 (callback)
1.什么是回调函数
将第一个函数的指针(也就是内存地址,Python中淡化了指针的概念)作为参数传给另一个函数处理, 这第一个函数就称为回调函数
2.简单示例
def foo(n):
print(f"foo输出{n}")
def Bar(i,func):
func(i)
for i in range(3):
Bar(i,foo)
'''输出
foo输出0
foo输出1
foo输出2
'''
3.回调函数应用场景
当进程池中一个任务处理完之后, 它去通知主进程自己结束了, 让主进程处理自己的结果, 于是主进程去调用另一个函数去处理该结果, 我们可以将耗时间或者阻塞的任务放入进程池, 在主进程中指定回调函数, 并由主进程负责执行, 这样主进程在执行回调函数的时候就省去了I/O的过程, 直接拿到的就是任务的结果
- 举一个简单易于理解的示例
from multiprocessing import Pool
import os
def get(n):
print(f"get--->{os.getpid()}")
return n # 返回任务执行的结果
def set(num): # 拿到回调函数的处理结果--->num
print(f"set--->{os.getpid()} : {num**2}")
if __name__ == '__main__':
p = Pool(3)
nums = [2,3,4,1]
li = []
for i in nums:
# 异步调用,并使用callback指定回调函数
res = p.apply_async(get,args=(i,),callback=set)
li.append(res)
p.close() # 关闭进程池
p.join() # 等待子进程结束
print([ii.get() for ii in li]) # 使用get方法拿到结果
'''输出
get--->8388
get--->8388
set--->8768 : 4
get--->8388
set--->8768 : 9
get--->8388
set--->8768 : 16
set--->8768 : 1
[2, 3, 4, 1]
'''
- 获取网页源码大小示例
from multiprocessing import Pool
import requests,os
def get_htm(url):
print(f"进程:{os.getpid()}开始获取:{url}网页")
response = requests.get(url)
if response.status_code == 200: # 如果是200,则获取成功
return {'url':url,'text':response.text}
else:
return {'url':url,'text':''} # 有些网页获取不到,设置空
def parse_htm(htm_dic):
print(f'进程:{os.getpid()}正在处理:{htm_dic["url"]}的text')
parse_data = f"url:{htm_dic['url']} size:{len(htm_dic['text'])}"
with open("./db.txt","a")as f: # 将URL和对应网页源码大小保存到文件
f.write(f"{parse_data}\n")
if __name__ == '__main__':
urls=[
'https://zhuanlan.zhihu.com',
'https://www.cnblogs.com',
'https://www.python.org',
'https://blog.youkuaiyun.com',
'http://www.china.com.cn',
]
p = Pool(3) # 设置进程池最大进程数为3
li = []
for url in urls:
# 异步调用并指定回调函数
res = p.apply_async(get_htm,args=(url,),callback=parse_htm)
li.append(res)
p.close() # 关闭进程池
p.join() # 等待子进程结束
print([i.get() for i in li]) # 使用get方法获取结果
'''输出
进程:11484开始获取:https://zhuanlan.zhihu.com网页
进程:17344开始获取:https://www.cnblogs.com网页
进程:2688开始获取:https://www.python.org网页
进程:11484开始获取:https://blog.youkuaiyun.com网页
进程:3928正在处理:https://zhuanlan.zhihu.com的text
进程:17344开始获取:http://www.china.com.cn网页
进程:3928正在处理:https://www.cnblogs.com的text
进程:3928正在处理:https://blog.youkuaiyun.com的text
进程:3928正在处理:http://www.china.com.cn的text
进程:3928正在处理:https://www.python.org的text
[{'url': 'https://zhuanlan.zhihu.com', 'text': ''},...一堆网页源码的bytes(省略)]
'''
- 查看一下保存的 “db.txt” 文件
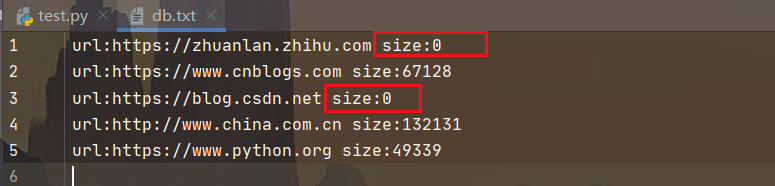
4.爬取福布斯全球排行榜

from multiprocessing import Pool
import re
import requests
def get_htm(url,format1):
response = requests.get(url)
if response.status_code == 200:
return (response.text,format1)
else:
return ('',format1)
def parse_htm(res):
text,format1 = res
data_list = re.findall(format1,text)
for data in data_list:
with open("福布斯排行.txt","a",encoding="utf-8")as f:
f.write(f"排名:{data[0]},名字:{data[1]},身价:{data[2]},公司:{data[3]},国家:{data[4]}\n")
if __name__ == '__main__':
url1 = "https://www.phb123.com/renwu/fuhao/shishi.html"
# 使用正则匹配关键字
format1 = re.compile(r'<td.*?"xh".*?>(\d+)<.*?title="(.*?)".*?alt.*?<td>(.*?)</td>.*?<td>(.*?)<.*?title="(.*?)"', re.S)
url_list = [url1]
for i in range(2, 16): # 总共15页排行,将链接都加进列表里
url_list.append(f"https://www.phb123.com/renwu/fuhao/shishi_{i}.html")
p = Pool()
li = []
for url in url_list:
res = p.apply_async(get_htm,args=(url,format1),callback=parse_htm)
li.append(res)
p.close()
p.join()
print("保存完成")
- 查看一下文件, 看看自己有没有上榜
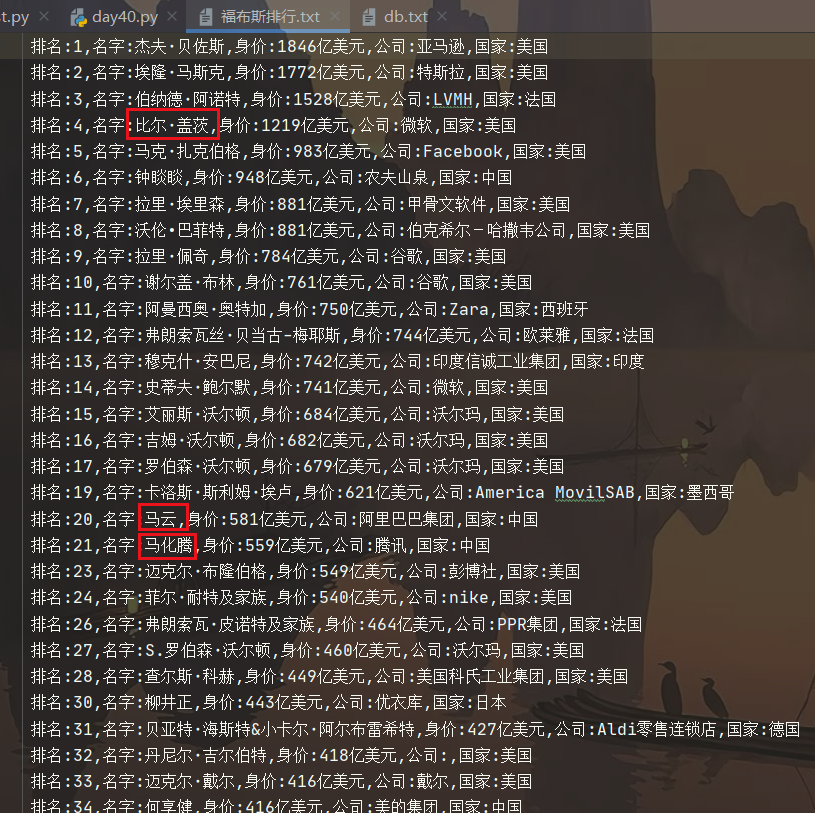

ps : 如果在主进程中等待进程池中所有任务都执行完毕后,再统一处理结果,则无需回调函数




















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











