




 本文深入探讨逻辑回归作为线性回归的一种变形,如何通过sigmoid函数将预测值映射到(0,1)区间,解释为何这能提高分类效果。文章详细介绍了逻辑回归的数学模型,包括似然函数和梯度上升法的使用,并提供了Python代码实现。
本文深入探讨逻辑回归作为线性回归的一种变形,如何通过sigmoid函数将预测值映射到(0,1)区间,解释为何这能提高分类效果。文章详细介绍了逻辑回归的数学模型,包括似然函数和梯度上升法的使用,并提供了Python代码实现。
逻辑回归可以用于解决二分类问题,之前写的感知机也是用于二分类问题的,不过感知机将特征的线性组合映射到了(-1,+1)两个离散值,logistic regression则将这个线性组合的输出映射到了(0,1)区间之内,并且一般认为输出≥0.5\geq0.5≥0.5就取为1,反之则取为0(其实也就是正例和反例的分类)。
逻辑回归
逻辑回归的本质其实是线性回归,不过是把线性回归的值映射到了(0,1)区间之内,这个映射函数称之为sigmoid函数,也称为Logistic函数,这个函数的公式如下:
g(z)=11+e−zg(z)=\frac{1}{1+e^{-z}}g(z)=1+e−z1
sigmod函数当zzz趋近于无穷大时,g(z)g(z)g(z)趋近于1;当zzz趋近于无穷小时,g(z)g(z)g(z)趋近于0。函数的图像如下所示:
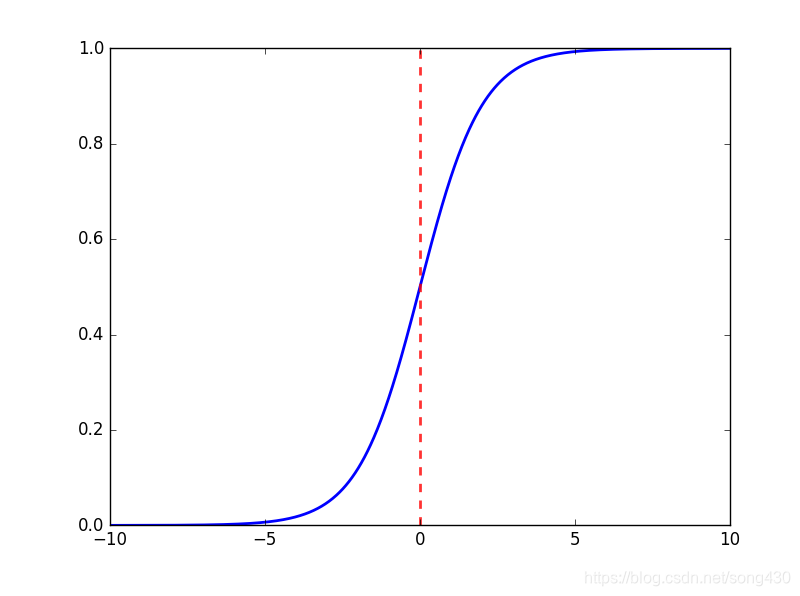
可能这时候会有点好奇,为什么要把线性回归的值给映射到(0,1)之间呢?这样做有什么好处?我们可以联想之前的感知机模型,其损失函数是为了让误分类的个数最小,但是个数这种离散值不容易计算梯度,所以才会有一个相同功能的函数的替换。sigmoid函数也是类似,当特征线性求和之后,我们要把正例和反例的结果相差特别远,才会对新的实例产生一个较好的分类结果,换句话说,也就是使得属于某一类的概率非常高,这就弥补了之前感知机分类的可能存在多个超平面的情形。
一个特征线性求和函数如下,如果令b=w0,x0=1b = w_0,x_0=1b=w0,x0=1,则:
wTx+b=w0+∑i=1nwixi=∑i=0nwixi=θTxw^Tx+b = w_0+\sum\limits_{i=1}^nw_ix_i=\sum\limits_{i=0}^nw_ix_i=\theta^TxwTx+b=w0+i=1∑nwixi=i=0∑nwixi=θTx
(w,b)(w,b)(w,b)就可以写成一个参数θ\thetaθ,将上面这个线性特征和带入到sigmoid函数,就能得到逻辑回归的表达式:
hθ(x)=g(θTx)=11+e−θTxh_\theta(x)=g(\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}}hθ(x)=g(θTx)=1+e−θTx1
现在我们就可以将y的取值hθ(x)h_\theta(x)hθ(x)通过sigmoid函数归一化到(0,1)之间,y的取值表示取1的概率:
P(y=1∣x;θ)=hθ(x)P(y=0∣x;θ)=1−hθ(x)\begin{array}{lr}
P(y=1|x;\theta) = h_\theta(x) & \\
P(y=0|x;\theta) = 1-h_\theta(x)
\end{array}P(y=1∣x;θ)=hθ(x)P(y=0∣x;θ)=1−hθ(x)
对上面的表达式合并就是
P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−yP(y|x;\theta) = (h_\theta(x))^y(1-h_\theta(x))^{1-y}P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−y
梯度上升
得到了逻辑回归的表达式,我们就可以来进行求解θ\thetaθ了,回想一下概率论,如果我们想在模型参数未知,但数据已知的情形下,怎么才能找到最有可能产生这些数据的参数呢?
答案就是采用极大似然法。采用梯度上升使得概率最大。
我们可以写出这里的似然函数:
L(θ)=∏i=1mp(y(i)∣x(i);θ)=∏i=1m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i)L(\theta) = \prod_{i=1}^mp(y^{(i)}|x^{(i)};\theta)=\prod_{i=1}^m(h_\theta(x^{(i)}))^{y^{(i)}}(1-h_\theta(x^{(i)}))^{1-y^{(i)}}L(θ)=i=1∏mp(y(i)∣x(i);θ)=i=1∏m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i)
对似然函数取对数:
l(θ)=logL(θ)=∑i=1my(i)logh(x(i))+(1−y(i))log(1−h(x(i)))l(\theta) = \log L(\theta) = \sum_{i=1}^my^{(i)}\log h(x^{(i)})+(1-y^{(i)})\log (1-h(x^{(i)}))l(θ)=logL(θ)=i=1∑my(i)logh(x(i))+(1−y(i))log(1−h(x(i)))
转换后的似然函数对θ\thetaθ取偏导,在这里以一个训练样本为例:
∂∂θjl(θ)=(y1g(θTx)−(1−y)11−g(θTx))∂∂θjg(θTx)=(y1g(θTx)−(1−y)11−g(θTx))g(θTx)(1−g(θTx))∂∂θjθTx=(y(1−g(θTx))−(1−y)g(θTx))xj=(y−hθ(x))xj\begin{aligned} \frac{\partial}{\partial\theta_j}l(\theta)&= (y\frac{1}{g(\theta^Tx)}-(1-y)\frac{1}{1-g(\theta^Tx)})\frac{\partial}{\partial\theta_j}g(\theta^Tx) \\
&=(y\frac{1}{g(\theta^Tx)}-(1-y)\frac{1}{1-g(\theta^Tx)})g(\theta^Tx)(1-g(\theta^Tx))\frac{\partial}{\partial\theta_j}\theta^Tx \\
&=(y(1-g(\theta^Tx))-(1-y)g(\theta^Tx))x_j \\
&=(y-h_\theta(x))x_j
\end{aligned}∂θj∂l(θ)=(yg(θTx)1−(1−y)1−g(θTx)1)∂θj∂g(θTx)=(yg(θTx)1−(1−y)1−g(θTx)1)g(θTx)(1−g(θTx))∂θj∂θTx=(y(1−g(θTx))−(1−y)g(θTx))xj=(y−hθ(x))xj
求出偏导之后,我们就可以通过迭代来更新θ\thetaθ了,更新公式如下:
θj:=θj+α(y(i)−hθ(x(i)))xji\theta_j :=\theta_j+\alpha(y^{(i)}-h_\theta(x^{(i)}))x_j^{i}θj:=θj+α(y(i)−hθ(x(i)))xji
如果有细心的同学注意的话,这个函数的梯度其实跟最小二乘函数的梯度是一致的。
Python实现
import numpy as np
import random
import math
import matplotlib.pyplot as plt
#sigmoid function
def sigmoid(z):
return 1/(1+math.e**(-z))
# train function to get weight and bias
def training():
train_data1 = [[1,3,1], [2,5,1], [3,8,1], [2,6,1]] #positive sample
train_data2 = [[3,1,0], [4,1,0], [6,2,0], [7,3,0]] #negative sample
train_data = train_data1 + train_data2;
theta = [0,0,0]
learning_rate = 0.1
train_num = int(input("train num:"))
for i in range(train_num):
train = random.choice(train_data)
x1,x2,y = train;
y_predict = sigmoid(theta[0]*1 + theta[1]*x1 + theta[2]*x2 )
print("train data:x:(%d, %d) y:%d ==>y_predict:%d" %(x1,x2,y,y_predict))
theta[0] = theta[0] + learning_rate*(y-y_predict)*1
theta[1] = theta[1] + learning_rate*(y-y_predict)*x1
theta[2] = theta[2] + learning_rate*(y-y_predict)*x2
print("update theta:")
print(theta[0], theta[1], theta[2])
print("stop training :")
print(theta[0], theta[1], theta[2])
#plot the train data and the hyper curve
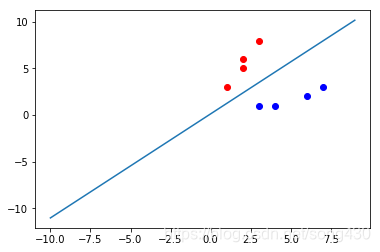
plt.plot(np.array(train_data1)[:,0], np.array(train_data1)[:,1],'ro')
plt.plot(np.array(train_data2)[:,0], np.array(train_data2)[:,1],'bo')
x_1 = []
x_2 = []
for i in range(-10,10):
x_1.append(i)
x_2.append((-theta[1]*i-theta[0])/theta[2])
plt.plot(x_1,x_2)
plt.show()
return theta
#test function to predict
def test():
theta = training()
while True:
test_data = []
data = input("enter q to quit,enter test data (x1, x2):")
if data == 'q':
break
test_data += [int(n) for n in data.split(',')]
predict = sigmoid(theta[1]*test_data[0] + theta[2]*test_data[1] + theta[0])
if(predict>0.5):
print("predict==>1,probability==>%.3f" %predict)
else:
print("predict==>0,probability==>%.3f" %predict)
if __name__ == "__main__":
test()
输出结果如下:

















 2448
2448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









