




一、 操作系统
什么是内存泄漏?什么是内存溢出?二者有什么区别?
内存溢出(OutOfMemory-OOM):指你的应用的内存已经不能满足正常使用了,堆栈已经达到系统设置的最大值,进而导致崩溃,这是一种结果描述。
内存泄漏(Memory Leak):指你的应用使用资源之后没有及时释放,导致应用内存中持有了不需要的资源,这是一种状态描述。
了解的操作系统有哪些?
Windows,Unix,Linux,Mac
二、 计算机网络
局域网
局域网(Local Area Network),简称 LAN,是指在某一区域内由多台计算机互联成的计算机组。“某一区域”指的是同一办公室、同一建筑物、同一公司和同一学校等,一般是方圆几千米以内。局域网可以实现文件管理、应用软件共享、打印机共享、扫描仪共享、工作组内的日程安排、电子邮件和传真通信服务等功能。
局域网是封闭型的,可以由办公室内的两台计算机组成,也可以由一个公司内的上千台计算机组成。
二、广域网
广域网(Wide Area Network),简称 WAN,是一种跨越大的、地域性的计算机网络的集合。通常跨越省、市,甚至一个国家。广域网包括大大小小不同的子网,子网可以是局域网,也可以是小型的广域网。
10M 兆宽带是什么意思?理论下载速度是多少?
首先我们要搞懂其中的区别,运营商说的 10M,完整的单位应该是 10Mbps(bps:比特率),而我们讲的下载速度单位是 MB,虽然都念兆,但是不一样的。
它们之间的换算关系是:1MB=8×1Mbps,换个方式看:1Mbps÷8=128KB,也就是说,运营商称的 10M宽带,实际速度是 10Mbps÷8=1280KB,约 1.25MB。
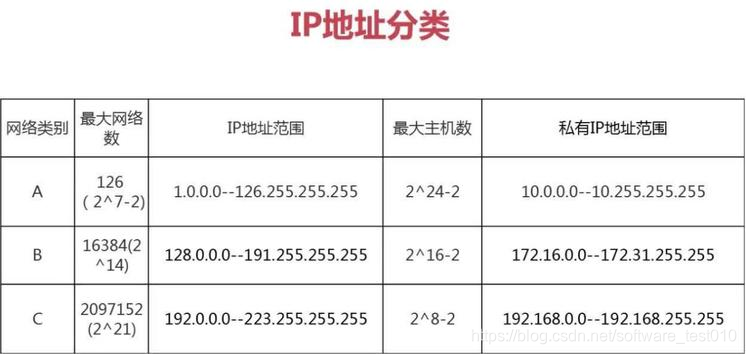
什么是IP 地址?
IP 地址是指互联网协议地址(英语:Internet Protocol Address,又译为网际协议地址),是 IP Address的缩写。IP 地址是 IP 协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
IP地址的分类
如果对软件测试有兴趣,想了解更多的测试知识,解决测试问题,以及入门指导,帮你解决测试中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,又或者已经工作但是经常觉得难点很多,觉得自己测试方面学的不够精想要继续学习的,想转行怕学不会的, 都可以加入我们1079636098,群内可领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!
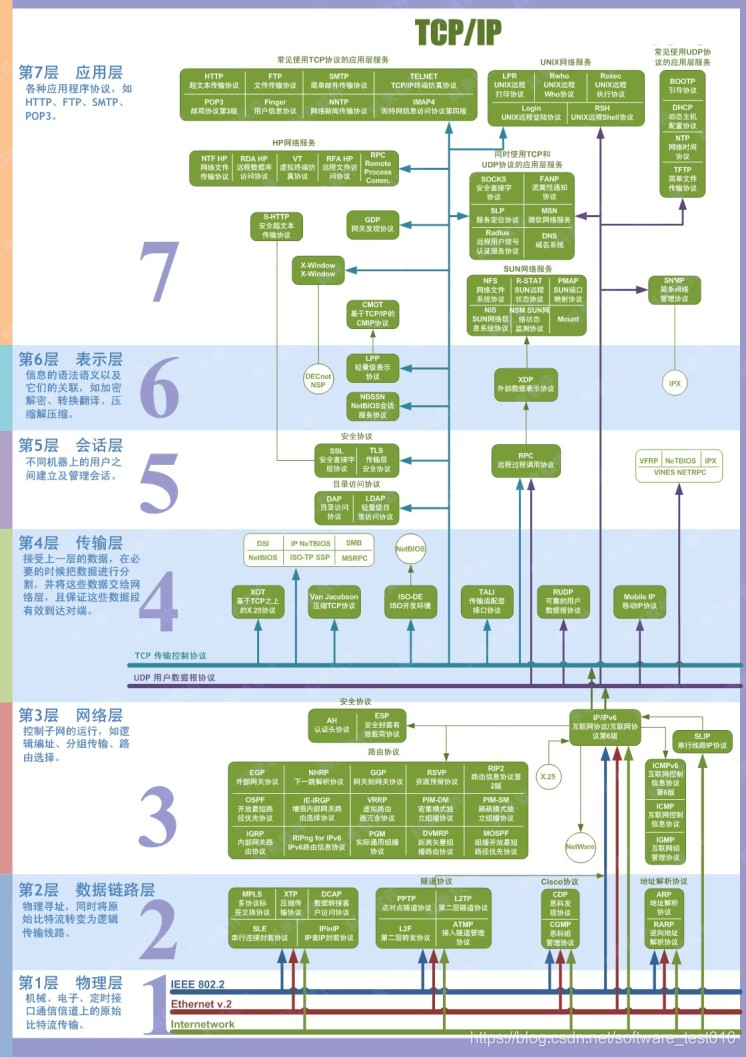
OSI 七层网络模型的划分?

如果对软件测试有兴趣,想了解更多的测试知识,解决测试问题,以及入门指导,帮你解决测试中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,又或者已经工作但是经常觉得难点很多,觉得自己测试方面学的不够精想要继续学习的,想转行怕学不会的, 都可以加入我们1079636098,群内可领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!
TCP 和 UDP 有什么不同?
TCP:
优点:可靠 稳定
• TCP 的可靠体现在TCP 在传输数据之前,会有三次握手来建立连接,而且在数据传递时,有确认. 窗口. 重传. 拥塞控制机制,在数据传完之后,还会断开来连接用来节约系统资源。
缺点:慢,效率低,占用系统资源高,易被攻击
• 在传递数据之前要先建立连接,这会消耗时间,而且在数据传递时,确认机制. 重传机制. 拥塞机制等都会消耗大量时间,而且要在每台设备上维护所有的传输连接。然而,每个连接都会占用系统的CPU,内存等硬件资源。因为 TCP 有确认机制. 三次握手机制,这些也导致 TCP 容易被利用,实现 DOS. DDOS. CC 等攻击。
UDP:
优点:快,比TCP 稍安全
• UDP 没有TCP 拥有的各种机制,是一种无状态的传输协议,所以传输数据非常快,没有 TCP 的这些机制,被攻击利用的机会就少一些,但是也无法避免被攻击。
缺点:不可靠,不稳定
• 因为没有 TCP 的这些机制,UDP 在传输数据时,如果网络质量不好,就会很容易丢包,造成数据的缺失。
适用场景:
• TCP:当对网络质量有要求时,比如HTTP,HTTPS,FTP 等传输文件的协议;POP,SMTP 等邮件传输的协议
• UDP:对网络通讯质量要求不高时,要求网络通讯速度要快的场景
HTTP 属于哪一层的协议?
HTTP 协议属于应用层协议
HTTP 和 HTTPS 的区别?
安全性上的区别:HTTPS:HTTP 协议的安全加强版,通过在 HTTP 上建立加密层,对传输数据进行加密。主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
表现形式:HTTPS 站点会在地址栏上显示一把绿色小锁,表明这是加密过的安全网站,如果采用了全球认证的顶级 EV SSL 证书的话,其地址栏会以绿色高亮显示,方便用户辨认。
SEO:在 2015 年之前百度是无法收录 HTTPS 页面的,不过自从 2015 年 5 月份百度搜索全站 HTTPS 加密后,就已经可以收录 HTTPS 了。谷歌则是从 2014 年起便开始收录 HTTPS 页面,并且 HTTPS 页面权重比HTTP 页面更高。从SEO 的角度来说,HTTPS 和HTTP 区别不大,甚至HTTPS 效果更好。
技术层面:如果要说HTTPS 和HTTP 的区别,最关键的还是在技术层面。比如 HTTP 标准端口是 80, 而 HTTPS 标准端口是 443;HTTP 无需证书,HTTPS 需要 CA 机构颁发的 SSL 证书;HTTP 工作于应用层, HTTPS 工作于传输层。
cookies 和session 的区别?
cookies:是针对每一个网站的信息,每一个网站只对应一个,其它网站不能访问,这个文件是保存在客户端的,每次你打相应网站,浏览器会查找这个网站的 cookies,如果有就会将这个文件起发送出去。cookies 文件的内容大致包函这些信息如用户名,密码,设置等。
session: 是针对每一个用户的,只有客户机访问,程序就会为这个客户新增一个 session。session 里
主要保存的是用户的登录信息,操作信息等。这个 session 在用户访问结束后会被自动消失(如果超时也会)。
HTTP 的get 请求和post 请求的区别?
- 在客户端,Get 方式在通过 URL 提交数据,数据在 URL 中可以看到;POST 方式,数据放置在HTML HEADER 内提交。
- GET 方式提交的数据最多只能有 1024 字节,而POST 则没有此限制。
- 安全性问题。正如在(1)中提到,使用 Get 的时候,参数会显示在地址栏上,而 Post 不会。所以,如果这些数据是中文数据而且是非敏感数据,那么使用 get;如果用户输入的数据不是中文字符而且包含敏感数据,那么还是使用 post 为好。
- 安全的和幂等的。所谓安全的意味着该操作用于获取信息而非修改信息。幂等的意味着对同一 URL 的多个请求应该返回同样的结果。
HTTP1.0 和 HTTP1.1 有什么区别
HTTP 协议老的标准是HTTP/1.0,目前最通用的标准是 HTTP/1.1。在同一个 tcp 的连接中可以传送多个 HTTP 请求和响应.
多个请求和响应可以重叠,多个请求和响应可以同时进行. 更加多的请求头和响应头(比如HTTP1.0 没有host 的字段).
它们最大的区别:
在 HTTP/1.0 中,大多实现为每个请求/响应交换使用新的连接。HTTP 1.0 规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个 TCP 连接,服务器完成请求处理后立即断开 TCP 连接,服务器不跟踪每个客户也不记录过去的请求。
在 HTTP/1.1 中,一个连接可用于一次或多次请求/响应交换,尽管连接可能由于各种原因被关闭。HTTP
1.1 支持持久连接,在一个 TCP 连接上可以传送多个 HTTP 请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。HTTP 1.1 还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。
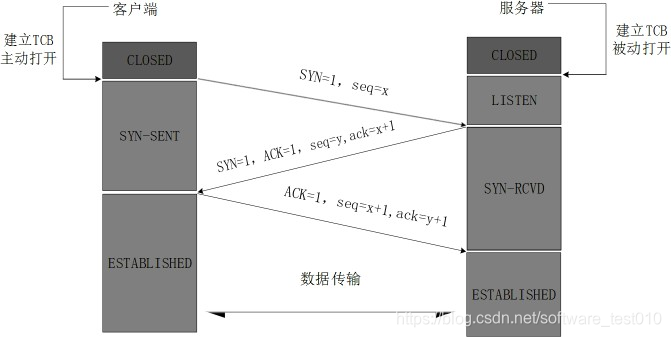
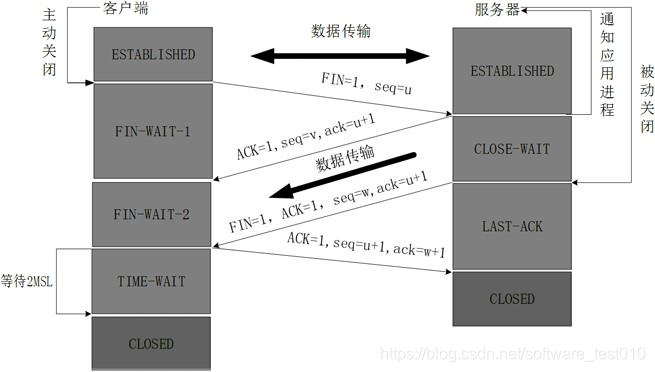
TCP 的连接建立过程,以及断开过程?
如果对软件测试有兴趣,想了解更多的测试知识,解决测试问题,以及入门指导,帮你解决测试中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,又或者已经工作但是经常觉得难点很多,觉得自己测试方面学的不够精想要继续学习的,想转行怕学不会的, 都可以加入我们1079636098,群内可领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!
常用协议端口号 SSH、DHCP、HTTP、FTP、SMTP、DNS 等
客户端使用 DHCP 获取IP 的过程?
发现阶段:即DHCP 客户端寻找 DHCP 服务器的阶段。提供阶段:即DHCP 服务器提供 IP 地址的阶段。
选择阶段:即DHCP 客户端选择某台 DHCP 服务器提供的 IP 地址的阶段。确认阶段:即DHCP 服务器确认所提供的 IP 地址的阶段。
写出某个网段的网络地址和广播地址?
算法:
子网掩码与 IP 地址进行位与运算,得处网络地址
网络地址 | (~子网掩码),得出广播地址 (|:位或运算; ~:按位取反) 例如:
IP 地址 10.145.129.20,掩码 255.255.248.0,网络地址和广播地址怎么计算?
网络地址 10.145.128.0 广播地址 10.145.135.255
解答:
IP 转换成二进制:00001010 10010001 10000001 00010010
掩码转换成二进制:11111111 11111111 11111000 00000000
IP 与掩码相与得网络地址(全 1 为 1,见 0 为 0):00001010 10010001 10000000 00000000 网络地址转换成十进制为:10,145,128,0
看你的掩码把后 24 位的前 13 为划成了子网,后 11 为划成了主机,故:
广播地址则要把网络地址的主机位全换成 1,得:00001010,10010001,10000111,1111111 广播地址转换成十进制为:10,145,135,255
首先由 ip 地址结合子网掩码可以看出的是这是一个由 A 类地址,“借用”13 位的主机位而得到的子网,所以很轻易地得到 网络地址是:10.145.128.0,也即:00001010.10010001.10000 000.00000000(前 21(8+13)
位是网络位,后 11 位是主机位)。至于广播地址,网络位+全为 1 的主机位,即得:00001010.10010001.10000
111.11111111,10 进制表达方式就是 10.145.135.255
什么是 VPN 都有什么类型?
VPN 的隧道协议主要有三种,PPTP、L2TP 和 IPSec,其中 PPTP 和 L2TP 协议工作在 OSI 模型的第二层,又称为二层隧道协议;IPSec 是第三层隧道协议。
B/S 和 C/S 的区别
b/s 代表浏览器和服务器架构;c/s 代表客户端和服务器架构
网络环境不同(c/s 建立在专用的局域网上,b/s 建立在广域网上) 安全要求不同(c/s 必须安装客户端,安全度较高;b/s 安全度较低)
系统维护不同(c/s 升级困难,需要重新安装最新客户端;b/s 无缝升级) 对系统要求不同(c/s 对系统要求较高;b/s 对系统要求较低)
线程和进程的区别
进程——资源分配的最小单位,线程——程序执行的最小单位。线程进程的区别体现在几个方面:
第一:因为进程拥有独立的堆栈空间和数据段,所以每当启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这对于多进程来说十分“奢侈”,系统开销比较大,而线程不一样,线程拥有独立的堆栈空间,但是共享数据段,它们彼此之间使用相同的地址空间,共享大部分数据,比进程更节俭,开销比较小,切换速度也比进程快,效率高,但是正由于进程之间独立的特点,使得进程安全性比较高,也因为进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。一个线程死掉就等于整个进程死掉。
第二:体现在通信机制上面,正因为进程之间互不干扰,相互独立,进程的通信机制相对很复杂,譬如管道,信号,消息队列,共享内存,套接字等通信机制,而线程由于共享数据段所以通信机制很方便。。
- 属于同一个进程的所有线程共享该进程的所有资源,包括文件描述符。而不同过的进程相互独立。
- 线程又称为轻量级进程,进程有进程控制块,线程有线程控制块;
- 线程必定也只能属于一个进程,而进程可以拥有多个线程而且至少拥有一个线程;
第四:体现在程序结构上,举一个简明易懂的列子:当我们使用进程的时候,我们不自主的使用 if else 嵌套来判断 pid,使得程序结构繁琐,但是当我们使用线程的时候,基本上可以甩掉它,当然程序内部执行功能单元需要使用的时候还是要使用,所以线程对程序结构的改善有很大帮助。
常用的响应码
HTTP 响应码,也称 http 状态码(HTTP Status Code),反映了 web 服务器处理 HTTP 请求状态,每一个响应码都代表了一种服务端反馈的响应状态,标识了本次请求是否成功。我们应该了解常见的响应码代表的
状态,通过响应码能够对错误进行排查和定位,这是一个测试的必备技能~ HTTP 响应码通常分为五大类:
1XX——信息类(Information),表示收到 http 请求,正在进行下一步处理,通常是一种瞬间的响应状
态
2XX——成功类(Successful),表示用户请求被正确接收、理解和处理
200(OK):请求成功。一般用于 GET 与POST 请求
201(Created):已创建。成功请求并创建了新的资源 202(Accepted):
3XX——重定向类(Redirection),表示没有请求成功,必须采取进一步的动作
301(Moved Permanently):资源被永久移动。请求的资源已被永久的移动到新 URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的 URI
302(Found):资源临时移动。资源只是临时被移动,客户端应继续使用原有 URI
304:用其他策略获取资源
4XX——客户端错误(Client Error),表示客户端提交的请求包含语法错误或不能正确执行
400(Bad Requests):客户端请求的地址不存在或者包含不支持的参数
401(Unauthorized):未授权,或认证失败。对于需要登录的网页,服务器可能返回此响应
403(Forbidden):没权限。服务器收到请求,但拒绝提供服务
404(Not Found):请求的资源不存在。遇到 404 首先检查请求 url 是否正确
5XX——服务端错误(Server Error),表示服务器不能正确执行一个正确的请求(客户端请求的方法及参数是正确的,服务端不能正确执行,如网络超时、服务僵死,可以查看服务端日志再进一步解决)
500(Internal Server Error):服务器内部错误,无法完成请求
503(Service Unavailable):由于超载或系统维护(一般是访问人数过多),服务器无法处理客户端的请求 ,通常这只是暂时状态
三、 组成原理
计算机基本组成
a. 冯·诺依曼计算机的特点(机器以运算器为中心)
ⅰ. 计算机由运算器、存储器、控制器、输入设备和输出设备五大部件组成
ⅰ. 指令(程序)和数据以二进制不加区别地存储在存储器中
ⅰ. 程序自动运行
a. 现代计算机由三大部分组成(已经转化为以存储器为中心)
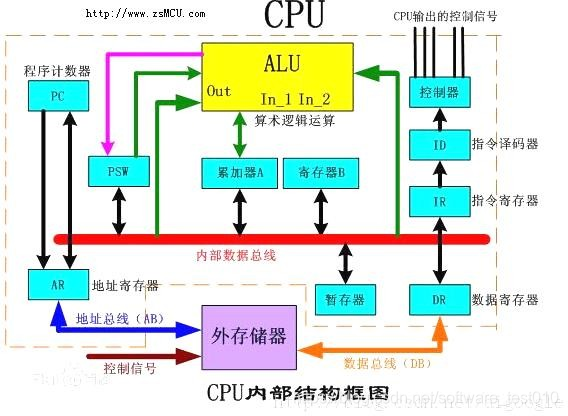
ⅰ. CPU(Central Processing Unit) 中央处理器,核心部件为 ALU(Arithmetic Logic Unit,算术逻辑单元)和CU(Control Unit,控制单元)
ⅱ. I/O 设备(受 CU 控制)
ⅰ. 主存储器(Main Memory,MM),分为 RAM(随机存储器)和ROM(只读存储器)
一条指令在CPU 的执行过程
a. Ad(Address) 形式地址
a. DR(Data Register) 数据寄存器
a. AR(Address Register) 地址寄存器(MAR)
a. IR(Instruction Register) 指令寄存器
a. BR(Buffer Register) 缓冲寄存器(MBR)
- ID(Instruction Decoder) 指令译码器
- PC(ProgramCounter) 程序计数器
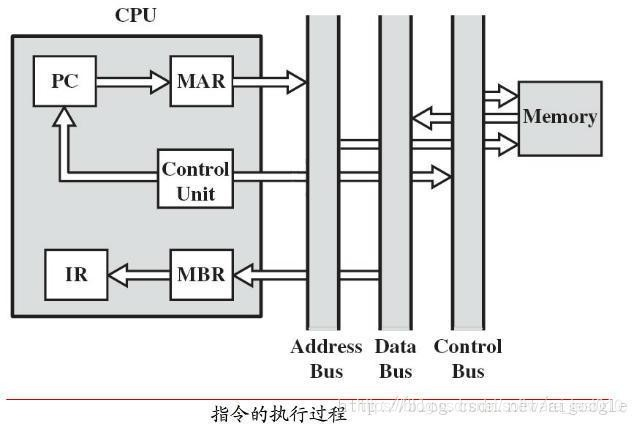
过程详述:
几乎所有的冯·诺伊曼型计算机的 CPU,其工作都可以分为 5 个阶段: 取指令
指令译码执行指令访存取数结果写回
1.取指令阶段
取指令(Instruction Fetch,IF)阶段是将一条指令从主存中取到指令寄存器的过程。
程序计数器 PC 中的数值,用来指示当前指令在主存中的位置。当一条指令被取出后,PC 中的数值将根据指令字长度而自动递增:若为单字长指令,则(PC)+1àPC;若为双字长指令,则(PC)+2àPC,依此类推。
//PC -> AR -> Memory
//Memory -> IR 2.指令译码阶段
取出指令后,计算机立即进入指令译码(Instruction Decode,ID)阶段。
在指令译码阶段,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法。
在组合逻辑控制的计算机中,指令译码器对不同的指令操作码产生不同的控制电位,以形成不同的微操作序列;在微程序控制的计算机中,指令译码器用指令操作码来找到执行该指令的微程序的入口, 并从此入口开始执行。
// { 1.Ad
//Memory -> IR -> ID -> { 2.PC 变化
// { 3.CU(Control Unit)
3.访存取数阶段
根据指令需要,有可能要访问主存,读取操作数,这样就进入了访存取数(Memory,MEM)阶段。 此阶段的任务是:根据指令地址码,得到操作数在主存中的地址,并从主存中读取该操作数用于运
算。
//Ad -> AR -> AD -> Memory 4.执行指令阶段
在取指令和指令译码阶段之后,接着进入执行指令(Execute,EX)阶段。
此阶段的任务是完成指令所规定的各种操作,具体实现指令的功能。为此,CPU 的不同部分被连接起来,以执行所需的操作。
例如,如果要求完成一个加法运算,算术逻辑单元ALU 将被连接到一组输入和一组输出,输入端提
供需要相加的数值,输出端将含有最后的运算结果。
//Memory -> DR -> ALU 5.结果写回阶段
作为最后一个阶段,结果写回(Writeback,WB)阶段把执行指令阶段的运行结果数据“写回”到某种存储形式:结果数据经常被写到 CPU 的内部寄存器中,以便被后续的指令快速地存取;在有些情况下, 结果数据也可被写入相对较慢、但较廉价且容量较大的主存。许多指令还会改变程序状态字寄存器中标志位的状态,这些标志位标识着不同的操作结果,可被用来影响程序的动作。
//DR -> Memory 6.循环阶段
在指令执行完毕、结果数据写回之后,若无意外事件(如结果溢出等)发生,计算机就接着从程序计数器 PC 中取得下一条指令地址,开始新一轮的循环,下一个指令周期将顺序取出下一条指令。
//重复 1~5
//遇 hlt(holt on)停止
计算机的逻辑部件
a. 若逻辑电路的输出状态仅和当时的输入状态有关,而与过去的输入状态无关,则称这种逻辑电路为组合逻辑电路
常见的组合逻辑电路有三态门、异或门、加法器、算术逻辑单元、译码器
a. 若逻辑电路的输出状态不但与当时的输入状态有关,而且还与电路在此前的输入状态有关,则称这种逻辑电路为时序逻辑电路。时序电路内必须有能存储信息的记忆元件即触发器。触发器是构成时序电路的基础。
b. “阵列”是逻辑元件在硅芯片上以阵列形式排列。常见阵列逻辑电路有:只读存储器 ROM、可编程序逻辑阵列PLA、可编程序阵列逻辑 PAL、通用阵列逻辑 GAL 等
四、 数据结构与算法
冒泡排序

冒泡思想:通过无序区中相邻记录的关键字间的比较和位置的交换,使关键字最小的记录像气泡一样逐渐向上漂至水面。整个算法是从最下面的记录开始,对每两个相邻的关键字进行比较,把关键字较小的记录放到关键字较大的记录的上面,经过一趟排序后,关键字最小的记录到达最上面,接着再在剩下的记录中找关键字次小的记录,把它放在第二个位置上,依次类推,一直到所有记录有序为止
插入排序
插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为 O(n^2)。是稳定的排序方法。插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。
def insert_sort(lists): # 插入排序count = len(lists)
for i in range(1, count): key = lists[i]
j = i - 1 while j >= 0:
if lists[j] > key:
lists[j + 1] = lists[j] lists[j] = key
j -= 1
return lists
希尔排序
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因 DL.Shell 于 1959 年提出而得名。 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。
def shell_sort(lists):
# 希尔排序
count = len(lists) step = 2
group = count / step
while group > 0:
for i in range(0, group): j = i + group
while j < count: k = j - group
key = lists[j]
while k >= 0:
if lists[k] > key:
lists[k + group] = lists[k] lists[k] = key
k -= group j += group
group /= step
return lists
快速排序
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据
都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
def quick_sort(lists, left, right):
# 快速排序
if left >= right:
return lists key = lists[left] low = left
high = right
while left < right:
while left < right and lists[right] >= key: right -= 1
lists[left] = lists[right]
while left < right and lists[left] <= key: left += 1
lists[right] = lists[left] lists[right] = key quick_sort(lists, low, left - 1) quick_sort(lists, left + 1, high)
return lists
直接选择排序
基本思想:第 1 趟,在待排序记录 r1 ~ r[n]中选出最小的记录,将它与 r1 交换;第 2 趟,在待排序记录r2 ~ r[n]中选出最小的记录,将它与 r2 交换;以此类推,第i 趟在待排序记录r[i] ~ r[n]中选出最小的记录,将它与 r[i]交换,使有序序列不断增长直到全部排序完毕。
def select_sort(lists):
# 选择排序
count = len(lists)
for i in range(0, count): min = i
for j in range(i + 1, count):
if lists[min] > lists[j]: min = j
lists[min], lists[i] = lists[i], lists[min]
return lists
堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即 A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。
def adjust_heap(lists, i, size): lchild = 2 * i + 1
rchild = 2 * i + 2 max = i
if i < size / 2:
if lchild < size and lists[lchild] > lists[max]: max = lchild
if rchild < size and lists[rchild] > lists[max]: max = rchild
if max != i:
lists[max], lists[i] = lists[i], lists[max] adjust_heap(lists, max, size)
def build_heap(lists, size):
for i in range(0, (size/2))[::-1]: adjust_heap(lists, i, size)
def heap_sort(lists): size = len(lists)
build_heap(lists, size)
for i in range(0, size)[::-1]:
lists[0], lists[i] = lists[i], lists[0] adjust_heap(lists, 0, i)

归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并过程为:比较 a[i]和 a[j]的大小,若 a[i]≤a[j],则将第一个有序表中的元素 a[i]复制到 r[k]中,并令 i和 k 分别加上 1;否则将第二个有序表中的元素 a[j]复制到 r[k]中,并令 j 和k 分别加上 1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到 r 中从下标 k 到下标 t 的单元。
归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序, 最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
def merge(left, right): i, j = 0, 0
result = []
while i < len(left) and j < len(right):
if left[i] <= right[j]: result.append(left[i]) i += 1
else:
result.append(right[j]) j += 1
result += left[i:] result += right[j:] return result
def merge_sort(lists):
# 归并排序
if len(lists) <= 1:
return lists
num = len(lists) / 2
left = merge_sort(lists[:num]) right = merge_sort(lists[num:]) return merge(left, right)
基数排序
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或 bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序,其时间复杂度为 O (nlog®m),其中 r 为所采取的基数,而 m 为堆数,在某些时候,基数排序法的效率高于其它的稳定性排序法。
import math
def radix_sort(lists, radix=10):
k = int(math.ceil(math.log(max(lists), radix))) bucket = [[] for i in range(radix)]
for i in range(1, k+1):
for j in lists:
bucket[j/(radix**(i-1)) % (radix**i)].append(j)
del lists[:]
for z in bucket: lists += z del z[:]
return lists
测试新手
如果你立志成为一名测试工程师,但却没有任何的知识储备。这时候,你应该抓紧时间学习计算机基础知识,同时,还需要了解编程体验、产品设计、用户体验和研发流程等知识。
测试工程师
从知识体系上看,你需要有更全面的计算机基础知识,还需要了解互联网的基础架构、安全攻击、软件性能、用户体验和常见缺陷等知识。从测试技术上看,你需要能够使用常见的测试框架或者工具,需要具有一定的自动化测试脚本的开发能力,
高级测试工程师
合格的测试工程师关注的是纯粹的测试,而优秀的测试工程师关注更多的是软件整体的质量,需要根据业务风险以及影响来制定测试策略。另外,优秀的测试工程师不仅可以娴熟地运用各类测试工具,还非常清楚这些测试工具背后的实现原理。
测试架构
测试架构师不仅仅应该有技术的深度,还应该有全局观。比如,面对大量测试用例的执行,无论是 GUI 还是 API,都需要一套高效的能够支持高并发的测试执行基础架构;再比如,面对测试过程中的大量差异性数据要求,需要统一的测试数据准备平台。同时,测试架构师还必须对一些前沿的测试方法和技术有自己的理解。

















 1565
1565




 到【灌水乐园】发言
到【灌水乐园】发言







