



 文章讨论了一个支付统计项目的代码审查,发现原本的处理流程在一个协程中完成所有操作,导致性能瓶颈。为了解决这个问题,提出了改进建议,包括每个请求使用单独协程处理、控制协程数量和采用Job/Work模式。具体实现中,创建了Dispatcher来分发任务到Worker池,每个Worker有自己的消息队列,从而提高系统性能和并发能力。
文章讨论了一个支付统计项目的代码审查,发现原本的处理流程在一个协程中完成所有操作,导致性能瓶颈。为了解决这个问题,提出了改进建议,包括每个请求使用单独协程处理、控制协程数量和采用Job/Work模式。具体实现中,创建了Dispatcher来分发任务到Worker池,每个Worker有自己的消息队列,从而提高系统性能和并发能力。
前端时间接收一个支付统计类项目,项目使用的技术栈为echo+mysql+redis ,当review完代码后,发现一个问题,整个消息处理是在一个协程里完成的,大概处理流程如下图:
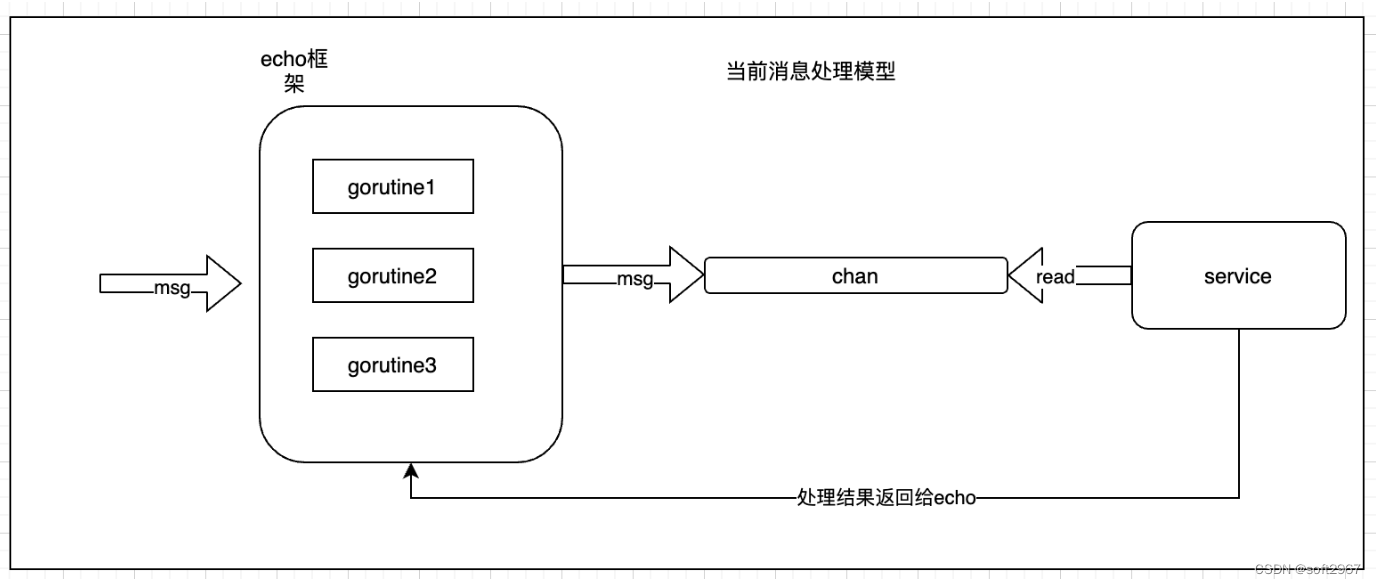
我们来大致分析下当前处理流程问题: http请求到echo框架后,echo会给每个请求创建一个gorutine,然后把接收到的数据push到chan中,service里开启一个协程在for;;无限循环里读取chan里的数据。那么这个处理流程会有什么问题了。我觉得就是慢,没有发挥go语言协程高性能的特性。在service每个处理里有很复杂的逻辑"慢" ,比如读写mysql,调用下游服务,执行复杂的业务计算,如果这里面有一个环节成为短板,服务的整个性能就会下降。知道问题后我们如何改造了?
整体的设计思路如下:
1.每一个请求一个协程单独处理
2.协程数量可控可配置
3.采用Job/Work模式设计
如下图:
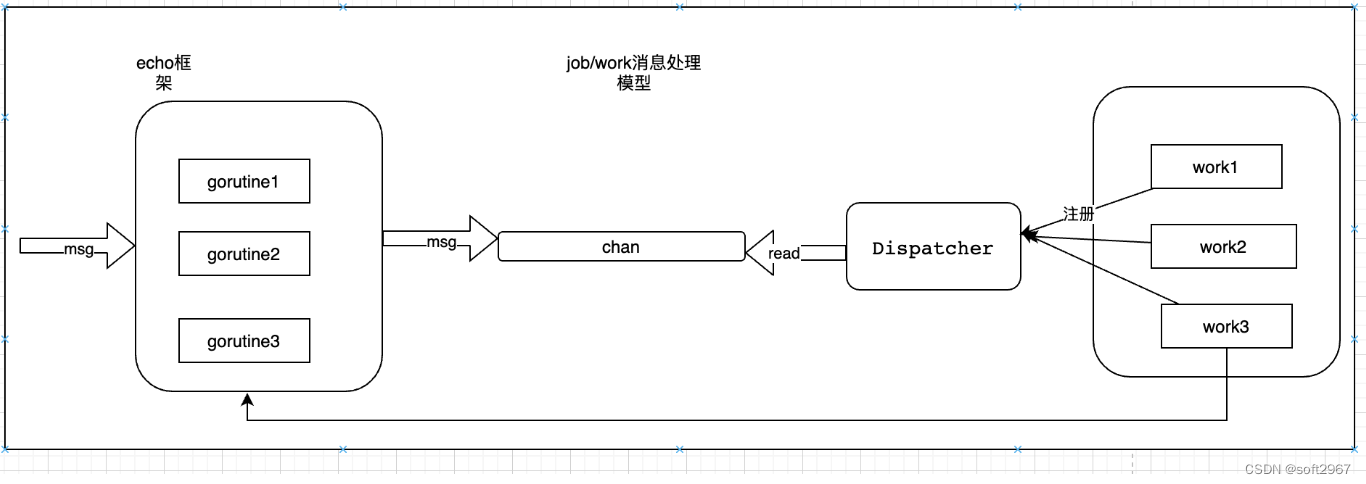
新增一个Dispatcher负责2个事情:
1.work对象在创建的时候需要向Dispatcher注册。
2.分发msg到每个work
下面我们来看看Dispatcher代码
type Dispatcher struct {
p *Service //父对象指针
jobQueue chan *opRequest //echo每个请求都放在这个队列
WorkerPool chan chan *opRequest //work注册过来的队列
maxWorkers int //最大work个数
}
//创建函数
func NewDispatcher(s *Service, maxWorkers int, jobQueue chan *opRequest) *Dispatcher {
pool := make(chan chan *opRequest, maxWorkers)
return &Dispatcher{
p: s,
jobQueue: jobQueue,
WorkerPool: pool,
maxWorkers: maxWorkers,
}
}
//Run函数启动Dispatcher,这个会在Service对象类被调用
func (d *Dispatcher) Run() {
//创建work对象,并调用work的start函数
for i := 0; i < d.maxWorkers; i++ {
//d.WorkerPool 这里注意传入work的是一个chan chan *opRequest
worker := NewWorker(d.p, d.WorkerPool)
worker.Start()
}
//启动分发协程
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
//获取消息队列数据
case job := <-d.jobQueue:
//获取到数据后,创建一个协程
go func(job *opRequest) {
//获取一个空闲的work,这里实质是获取work对象注册的chan
jobChannel := <-d.WorkerPool
//把待处理的消息放入work的chan
jobChannel <- job
}(job)
}
}
}
下面在看看工作者work对象实现
type Worker struct {
p *Service
//Dispatcher传入的chan,work每次处理完msg会重新把自己的JobChannel注册到WorkerPool
WorkerPool chan chan *opRequest
JobChannel chan *opRequest //work的消息队列
quit chan struct{} //用于退出监听的chan
}
//work创建函数,
func NewWorker(s *Service, workerPool chan chan *opRequest) Worker {
return Worker{
p: s,
WorkerPool: workerPool,
JobChannel: make(chan *opRequest),
quit: make(chan struct{})}
}
//工作协程
func (w Worker) Start() {
go func() {
for {
//work注册自己的chan到Dispatcher
w.WorkerPool <- w.JobChannel
//监听自己的chan是否有消息
select {
case job := <-w.JobChannel:
//有消息,处理逻辑
w.p.doRequest(job)
case <-w.quit:
return
}
}
}()
}
func (w Worker) Stop() {
go func() {
w.quit <- struct{}{}
}()
}
最后就是在service里初始化Dispatcher
func NewService() *Service{
s := &Service{}
s.dispatcher = NewDispatcher(s, runtime.NumCPU(), s.opRequestCh)
s.dispatcher.Run()
return s
}
可以来我的知识星球
1、ChatGPT 基础用法、使用教程
2、交流共享 ChatGPT 的各种信息,资源互换,答疑关于 ChatGPT 的问题。
3、分享如何利用 ChatGPT 提升工作效率,分享变现机会。
4、go编程相关知识
5、工作中开发经验分享


















 2369
2369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









