





 Spark Standalone模式是一个自带的资源调度框架,由client、master和worker节点构成。driver可以运行在client或master上,master负责资源调度,worker执行任务。运行流程包括:worker节点的心跳机制、SparkContext申请资源、DAG生成、task调度和执行,最后完成任务释放资源。此模式下,job被分解为stage,每个job包含一个或多个stage进行并行计算。
Spark Standalone模式是一个自带的资源调度框架,由client、master和worker节点构成。driver可以运行在client或master上,master负责资源调度,worker执行任务。运行流程包括:worker节点的心跳机制、SparkContext申请资源、DAG生成、task调度和执行,最后完成任务释放资源。此模式下,job被分解为stage,每个job包含一个或多个stage进行并行计算。
简介:
standalone 模式,是 spark 自己实现的,它是一个资源调度框架。这里我们要关注这个框架的三个节点:
1)client
2)master
3)worker
spark 应用程序有一个 Driver 驱动,Driver 可以运行在 Client 上也可以运行在 master 上。如果你使用 spark-shell 去提交 job 的话它会是运行在 master 上的,如果你使用 spark-submit 或者 IDEA 开发工具方式运行,那么它是运行在 Client 上的。这样我们知道了,Client 的主体作用就是运行 Driver。而 master 除了资源调度的作用还可以运行 Driver。
再关注 master 和 worker 节点,standalone 是一个主从模式,master 节点负责资源管理,worker 节点负责任务的执行。
运行流程
了解 standalone 主要节点之后,我们看一下它的运行流程,如图:
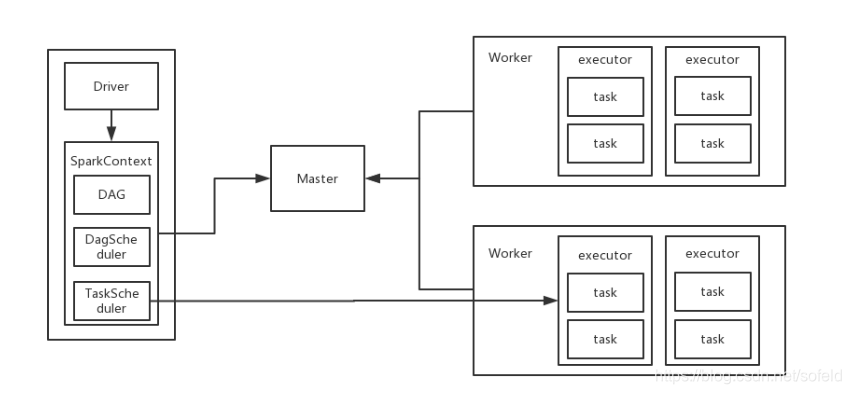
1)当 spark 集群启动以后,worker 节点会有一个心跳机制和 master 保持通信;
2)SparkContext 连接到 master 以后会向 master 申请资源,而 master 会根据 worker 心跳来分配 worker 的资源,并启动 worker 的 executor 进程;
3)SparkContext 将程序代码解析成 dag 结构,并提交给 DagScheduler;
4)dag 会在 DagScheduler 中分解成很多 stage,每个 stage 包含着多个 task;
5)stage 会被提交给 TaskScheduler,而 TaskScheduler 会将 task 分配到 worker,提交给 executor 进程,executor 进程会创建线程池去执行 task,并且向 SparkContext 报告执行情况,直到 task 完成;
6)所有 task 完成以后,SparkContext 向 Master 注销并释放资源;
总结
standalone 的是 spark 默认的运行模式,它的运行流程主要就是把程序代码解析成 dag 结构,并再细分到各个 task 提交给 executor 线程池去并行计算。
在运行流程中我们并没有提到 job 这个概念,只是说 dag 结构会被分解成很多的 stage。其实,分解过程中如果遇到 action 操作(这不暂时不关注 action 操作是什么),那么就会生成一个 job,而 每一个 job 都包含着一个或者多个 stage,所以 job 和 stage 也是一个总分的逻辑关系。

















 2176
2176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









