



摘要
在机器人学习领域,扩散模型因其稳定的训练特性和对复杂多模态行为的强大建模能力,正逐渐成为策略学习的重要工具。然而,传统基于模仿学习的扩散策略在面对分布偏移和未知场景时往往表现不佳,强化学习虽能通过试错弥补这些不足,但在真实机器人上进行海量交互不仅成本高昂,还存在安全风险。来自弗莱堡大学与纽伦堡工业大学的研究团队提出了 DiWA 框架,一种结合世界模型(World Model)与扩散策略的全离线微调方法。
不同于依赖真实或仿真环境反复交互的在线微调,DiWA 将强化学习过程完全迁移到由世界模型构建的“想象空间”中,在压缩的潜在状态里进行长时序滚动推演和奖励评估,从而实现无需额外交互的数据高效策略优化。在 CALVIN 基准和真实 Franka Panda 机械臂实验中,DiWA 在八个任务上均显著提升成功率,且物理交互次数为零,首次验证了扩散策略可通过纯离线的世界模型适配到真实技能的可行性,为安全、高效的机器人技能迁移开辟了新路径。
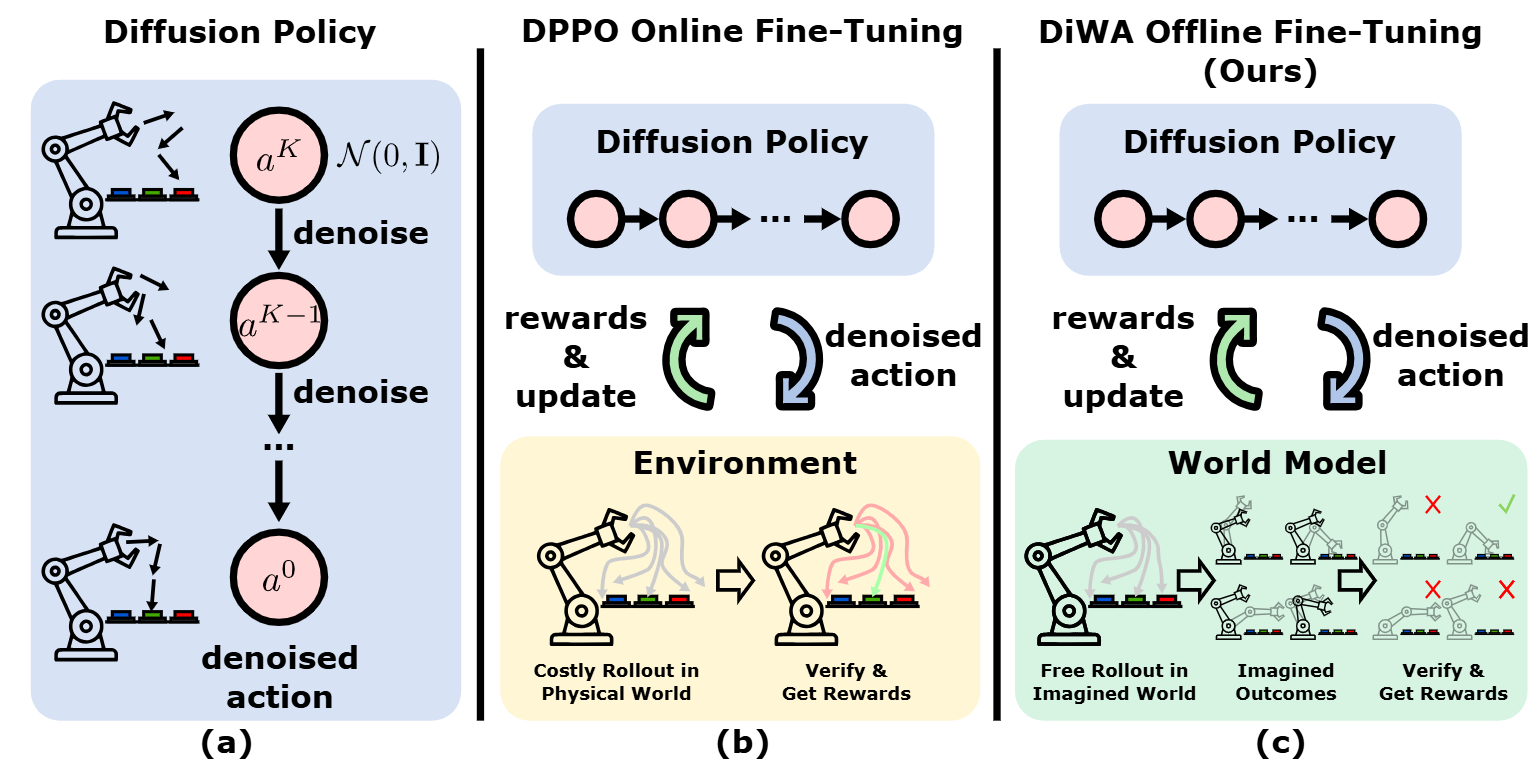
图1|(a) 通过模仿学习训练的标准扩散策略受限于离线数据。(b) DPPO使用在线交互来微调扩散策略,这种方式代价高昂,并且需要访问真实或模拟环境。(c) DiWA 完全在离线环境中,通过在学习得到的世界模型中进行想象的回合(imagined rollouts)来微调扩散策略,从而在无需额外物理交互的情况下,实现安全且高效的策略改进
论文出处:CoRL2025
论文标题:DiWA: Diffusion Policy Adaptation with World Models
论文作者:Akshay L Chandra, Iman Nematollahi, Chenguang Huang, Tim Welschehold, Wolfram Burgard, Abhinav Valada

扩散模型已经成为机器人策略学习中的一种强大工具,它通过条件去噪的方式表示动作,能够捕捉复杂的多模态行为。它们的优势在于训练过程稳定,并且可以建模高维分布。然而,当仅依赖离线示范数据、采用纯模仿学习进行训练时,扩散策略会继承模仿学习的固有缺陷:在遇到分布偏移时容易失效,并且在未见过的场景中表现不佳。这主要源于专家轨迹的覆盖范围有限或质量不足。
强化学习(RL)为克服模仿学习的不足提供了一条自然途径:通过与环境交互,利用奖励信号引导策略改进,使其能够超越示范数据的限制。RL 能够纠正策略错误、适应新情境并探索更优解。这种先预训练、再微调的范式在语言和视觉领域的大模型中已被广泛采用,并逐渐在机器人领域受到关注。然而,与这些领域不同,机器人微调需要与真实环境交互,这带来了样本效率低和安全风险高的挑战,使得 RL 在真实机器人上的应用更加困难。
近期的 Diffusion Policy Policy Optimization(DPPO)方法展示了利用近端策略优化(PPO)在在线环境中微调扩散策略的可行性,且在仿真中取得了优异结果。然而,它的样本效率较低,往往需要数百万次环境交互,这在真实场景中是昂贵且不切实际的。此外,DPPO 依赖高保真模拟器提供的真实状态信息,这种条件在现实部署中难以满足,且仿真到现实的差距会影响迁移效果。
相比之下,人类能够借助内部的世界模型和物理直觉,通过极少的实际试错快速适应新情况。受此启发,研究者们提出了利用数据驱动学习的世界模型替代人工构建的模拟器,从而在“想象”中进行长时序策略滚动,避免昂贵的在线试验。世界模型能够将高维观测压缩到潜在空间,捕捉环境动力学,实现安全、高效的策略改进。
基于这一思路,作者提出了 DiWA 框架——一种完全离线的扩散策略微调方法。DiWA 将世界模型视作安全的数据驱动模拟器,在学习到的潜在空间中进行长时序想象滚动,并结合策略梯度进行优化。通过融合扩散模型的表达能力、策略梯度的稳定性以及世界模型的想象能力,DiWA 实现了无需任何额外交互的策略适配,显著提升了样本效率和真实部署的可行性。
作者的主要贡献包括:
1. 提出首个利用世界模型完全离线微调扩散策略的框架,将扩散去噪过程嵌入到世界模型 MDP 中,实现无需真实或仿真交互的策略更新。
2. 通过在无结构的机器人“游戏”数据上训练潜在世界模型,并在想象滚动中细化复杂行为,显著提升了样本效率。
3. 在零额外交互的条件下实现扩散策略的真实机器人部署,验证了离线世界模型微调在真实技能适配中的有效性与安全性。
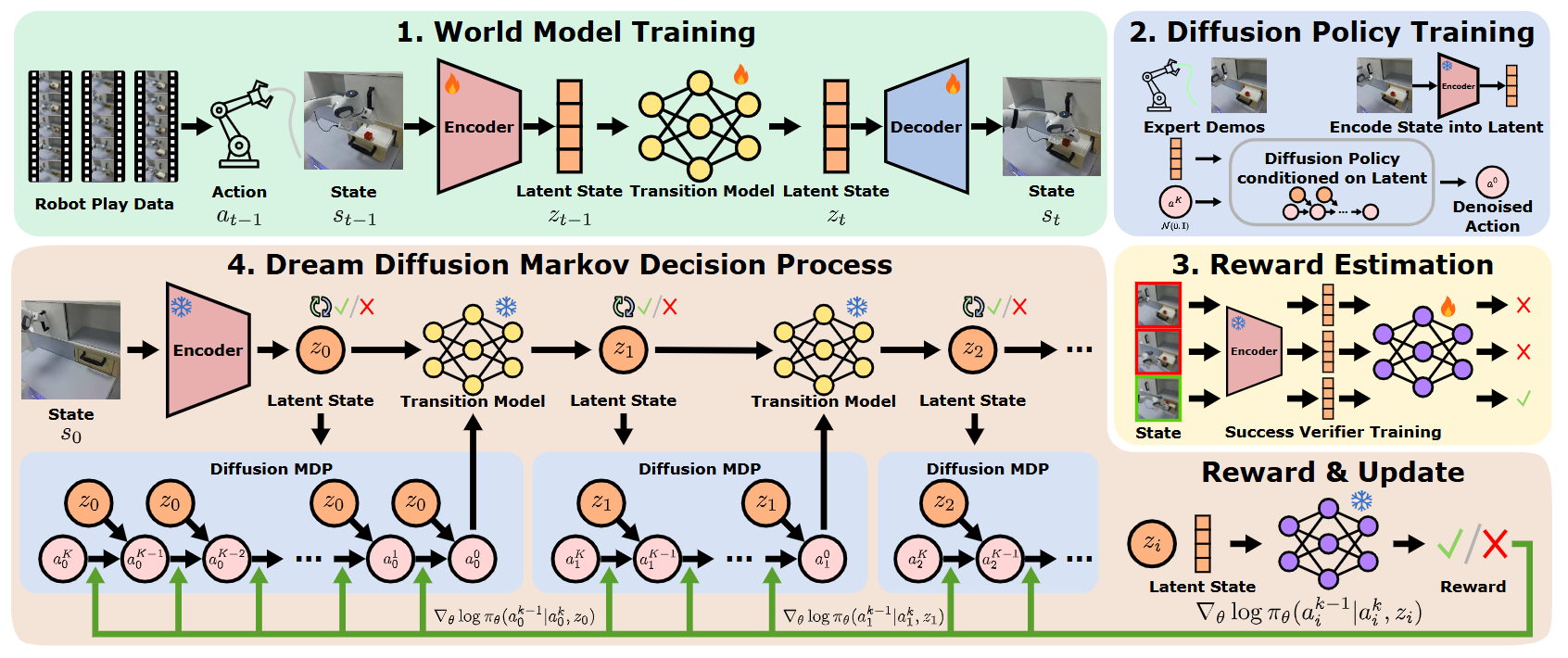
图2|全文方法总览

作者研究的目标是——在完全离线的条件下,对扩散策略(Diffusion Policy)进行微调,以适配新的机器人技能。整个方法建立在两个离线数据集之上:
● 专家示范数据集:规模较小,特定于目标技能;
● 无结构的机器人“游戏”数据集:规模较大,不含任务标签,用于训练世界模型。
问题建模
真实环境被建模为一个部分可观测马尔可夫决策过程(POMDP),包括状态空间 S、连续动作空间 A、状态转移函数 P、奖励函数 R,以及折扣因子 γ。
扩散策略在生成动作时,会先采样高斯噪声,然后通过多步去噪迭代逐渐生成最终动作。该策略首先在专家示范数据集上通过行为克隆进行预训练,学习模仿专家的去噪过程,但纯模仿会受到分布偏移和示范质量的限制。
为解决这一问题,作者希望在不与真实环境交互的前提下,优化策略的期望累积奖励。直接在真实环境中微调策略的代价高且不安全,因此作者引入潜在空间的世界模型,将真实状态映射为潜在状态,并在这个空间中进行想象滚动(imagined rollout),完成完全离线的策略优化
离线微调框架 DiWA
整个 DiWA 训练流程分为四个阶段(见图2):
● 世界模型训练:在无结构的机器人“游戏”数据集上训练一个潜在动力学模型,学习环境在潜在空间中的时序演化规律;
● 扩散策略预训练:利用世界模型的编码器,将专家示范数据集的观测映射到潜在状态,并用行为克隆训练扩散策略去模仿专家动作;
● 奖励分类器训练:在潜在空间中基于专家轨迹训练一个二分类器,用于判断某个潜在状态是否表示任务成功,从而为世界模型提供任务相关的奖励信号;
● 离线微调:在世界模型潜在空间中进行长时序想象滚动,通过策略梯度方法(PPO)优化策略。
世界模型训练
作者采用循环状态空间模型(RSSM)结构,由编码器、动力学预测器和解码器组成:
● 编码器将观测压缩为潜在变量;
● 动力学预测器根据历史潜在状态和动作预测下一个潜在状态;
● 解码器从潜在状态重构观测。
模型的优化目标是最小化负的变分证据下界(ELBO),其中包括重构误差和潜在变量的 KL 正则项。训练完成后,世界模型可以从先验分布中采样潜在状态并滚动预测未来状态,从而在没有新观测的情况下进行长时序想象。
扩散策略预训练
在预训练阶段,扩散策略使用世界模型编码器将专家演示转化为潜在向量,然后学习将随机噪声逐步去噪为专家动作。目标是最大化示范动作在去噪过程中的似然,从而为后续的离线微调提供良好的初始策略。
潜在奖励估计
由于世界模型是在任务无关的数据上训练的,它本身并不具备任务奖励信息。因此,作者在潜在空间中引入奖励分类器:
● 将专家示范中的潜在状态标记为“成功”或“失败”;
● 训练二分类模型预测当前潜在状态的成功概率;
● 在想象滚动中,奖励由该成功概率直接给出。
这种方法将世界模型升级为一个带奖励信号的潜在空间 MDP,支持全离线的策略优化。
Dream Diffusion MDP
此前研究表明,扩散去噪过程本身可以看作一个多步 MDP,且每一步的似然可计算。作者在此基础上,将去噪过程嵌入世界模型的潜在空间 MDP 中,构建Dream Diffusion MDP。
在该 MDP 中:
● 状态包括当前潜在向量和去噪过程的中间动作;
● 如果去噪步 k=1,则生成最终动作、进行世界模型的潜在状态转移并获得奖励;
● 如果 k>1,则继续去噪,中间奖励为 0。
这样可以在去噪过程中分阶段传递奖励,确保梯度可以有效回传
Dream Diffusion MDP 中的策略微调
在想象环境中,作者使用近端策略优化(PPO)对策略进行更新,同时加入行为克隆正则项,鼓励更新后的策略与预训练策略保持接近。这是为了防止策略过度利用世界模型的建模误差,导致在真实环境中失效。
此外,作者在计算优势函数时引入了去噪折扣因子,对去噪早期(噪声较大)步骤的优势贡献进行衰减,提高训练稳定性。

作者希望通过实验回答三个核心问题:
● 可行性:DiWA 是否能够在完全离线的条件下有效微调扩散策略,并在无额外交互的前提下获得高成功率?
● 关键因素影响:世界模型的建模质量和奖励分类器的准确度对策略微调效果有多大影响?
● 可迁移性:离线微调得到的策略能否直接部署到真实机器人中并获得性能提升?
模拟实验
实验环境
● 使用 CALVIN 基准环境 D(7 自由度 Franka Panda 机械臂),包含丰富的桌面操作任务;
● 世界模型训练数据:6 小时遥操作“游戏”数据(约 50 万条转移);
● 每个技能的专家示范:50 条;
● 测试任务:8 个不同的操控任务(如开/关抽屉、推滑块、开/关灯泡、开/关 LED 等)。
对比方法
● DPPO(Vision):原始 DPPO,直接用视觉编码(ViT)输入在线微调;
● DPPO(Vision WM Encoder):用与 DiWA 相同的世界模型编码器输入,但依然需要在线交互;
● DiWA:在潜在空间中离线微调。
主要结果(见图3)
● DiWA 在 8 个任务上全部成功提升成功率,例如“关抽屉”从 59.14% 提升到 91.95%,且无需额外交互;
● DPPO 要达到与 DiWA 相当的性能,通常需要数十万到上百万次在线交互(总计约 250 万~800 万次);
● 使用世界模型潜在编码的 DPPO 版本优于纯视觉输入版本,说明潜在表示更丰富、更符合动力学特性。
作者分析
DiWA 的关键优势在于样本效率和安全性:无需进行任何昂贵且可能有风险的真实环境探索,就能达到与在线 RL 相近甚至更高的性能;
在不同世界模型和奖励设计的对比中(见图4),同时引入场景状态监督和更准确的奖励信号(例如通过解码潜在状态计算奖励)会进一步提升离线微调效果
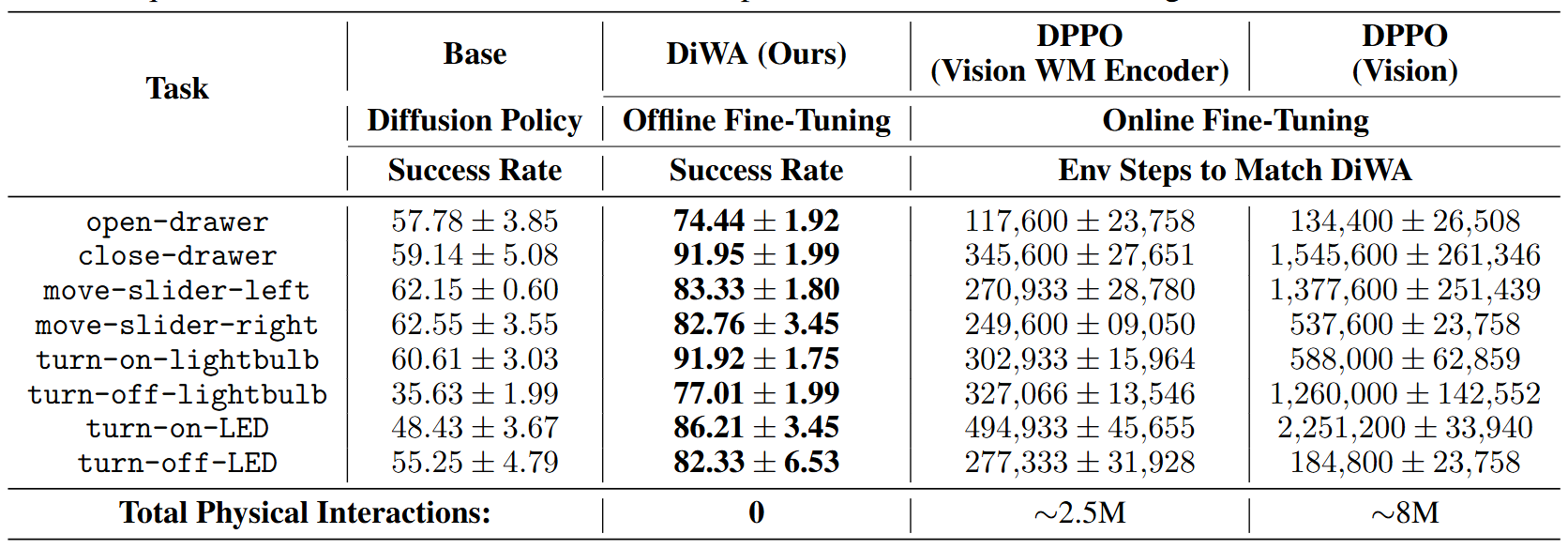
图3|模拟实验量化结果

图4|不同世界模型及奖励设计实验结果
真实机器人实验
实验设置
● 平台:Franka Panda 机械臂,桌面环境包含一个带抽屉的柜子;
● 数据采集:4 小时 VR 遥操作“游戏”数据(约 45 万条转移),包括固定摄像机和手爪摄像机 RGB 画面;
● 每个技能收集 50 条专家示范;
● 评测技能:开抽屉、关抽屉、推滑块至右侧。
结果(见图5-b)
● 预训练策略在三个任务上的成功率普遍较低;
● 离线使用 DiWA 微调后,三个任务的成功率显著提升,且无需任何额外的真实交互;
● 多轮滚动评估表明,性能提升主要来自于离线想象环境中的策略适配,而非对训练数据的记忆。
作者总结
● DiWA 证明了在完全离线的条件下,利用世界模型进行强化学习微调是可行的,并且能够直接迁移到真实机器人执行中;
● 在没有增加物理交互成本的情况下,任务成功率的提升幅度相当可观,验证了该方法在实际部署中的潜力与安全性。
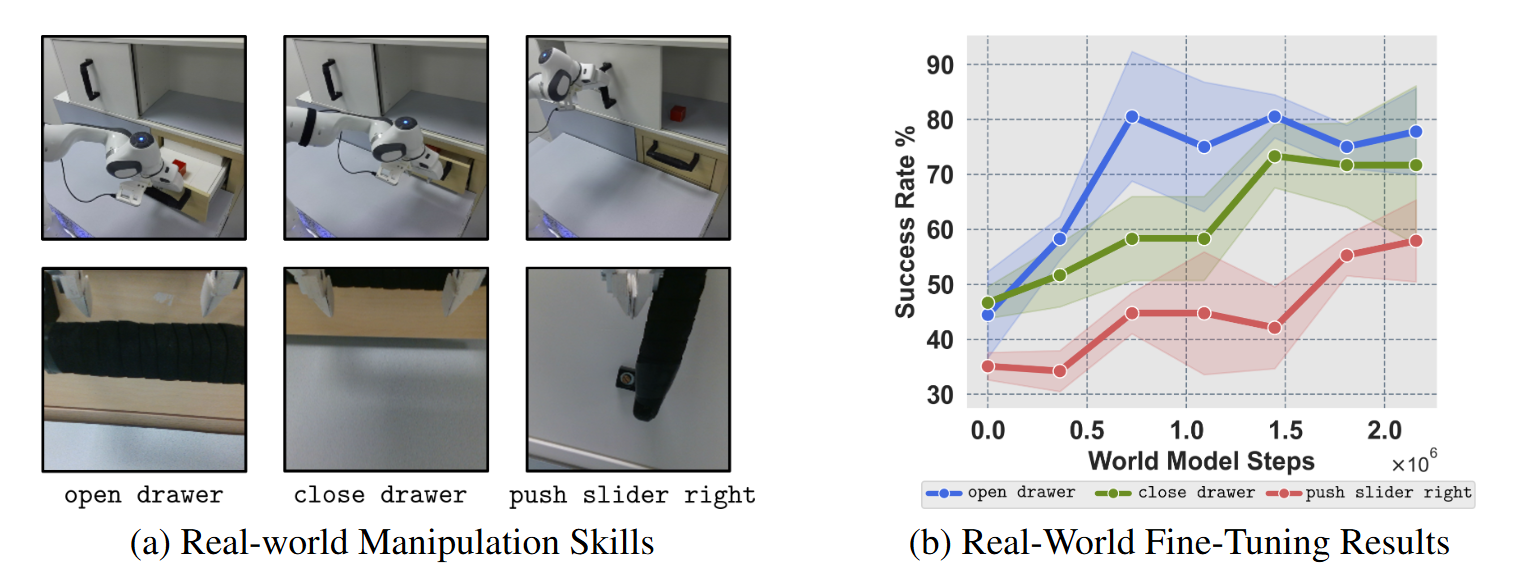
图5|真实机器人实验结果

从整体来看,DiWA 给机器人扩散策略的微调提供了一条全新的思路——把原本昂贵、低效、存在风险的在线强化学习,搬进了由世界模型构建的“想象空间”中完成。这样不仅大幅降低了样本需求和物理交互成本,还让真实部署变得更安全、更可控。在 CALVIN 基准和真实 Franka Panda 机械臂的实验中,它用“零交互”换来了显著的性能提升,这在机器人策略优化领域是一次突破。
小编认为,未来如果结合更精确的奖励建模、在线少量修正,以及跨任务的世界模型复用,DiWA 这种全离线微调的范式有望在更多真实场景落地——不仅适用于桌面操作,也可能扩展到移动机器人、协作机器人等更复杂的任务中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









