



导读
在具身智能和机器人学习快速发展的今天,来自西湖大学工程学院的 MiLAB(Machine Intelligence Laboratory) 是国内在该领域活跃度极高的研究团队之一。实验室由王东临副教授创立并担任负责人,王老师是国家科技创新 2030 重大项目的首席科学家,曾在加拿大和美国长期从事机器人智能相关研究,是西湖大学首位全职工院教师。
MiLAB 的研究聚焦于机器人学习(Robot Learning),具体包括:
● 强化学习理论(Reinforcement Learning)
● 元学习理论(Meta-Learning)
● 机器人行为智能(Behavior Intelligence)
团队目标是赋予真实机器人更高的灵活性、更快的适应能力和自主学习能力,核心方法涵盖深度学习、数据驱动建模与智能决策等。自 2017 年成立以来,MiLAB 已发表高水平论文 50 余篇,涵盖 ICLR、ICML、CoRL、RA-L、ICRA、IROS 等多个机器人与 AI 领域顶级会议。
为了帮助大家了解这个实验室在具身智能方向的研究进展,我们对其 2025 年上半年发表的论文进行了梳理与分类。本次盘点从MiLAB上半年发表的共21篇论文中遴选出12篇代表性论文,覆盖 VLA 模型构建、多模态策略优化、强化学习等关键方向,全面展示了 MiLAB 在“机器人如何自主感知世界、理解任务并完成动作决策”这条路径上的持续探索。
在具身智能系统中,感知不仅关乎“看到什么”,更决定了“如何理解并行动”。为了应对机器人在复杂环境中执行任务时所面临的模态差异、语言歧义和感知延迟等问题,MiLAB 团队在 2025 年上半年围绕视觉语言行动(VLA)模型展开了一系列创新研究。相关工作致力于提升多模态模型的实时性、泛化能力与鲁棒性,构建更高效、更稳定的机器人感知理解基础。

QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning【ICRA】
地址:[2412.15576] QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning
主要内容:
QUART-Online 提出了一种无延迟的四足机器人多模态语言模型(MLLM)部署方案。论文通过“动作块离散化”(ACD)机制,将连续动作映射为代表性离散向量,有效压缩动作空间并保留语义信息,使得模型能与控制器实时协同运行。相较传统压缩方法对语言模型性能的破坏,QUART-Online 在保持语言理解能力的同时,显著提升了推理效率与任务完成率(+65%),为高频率场景下的具身决策提供了实用解法。
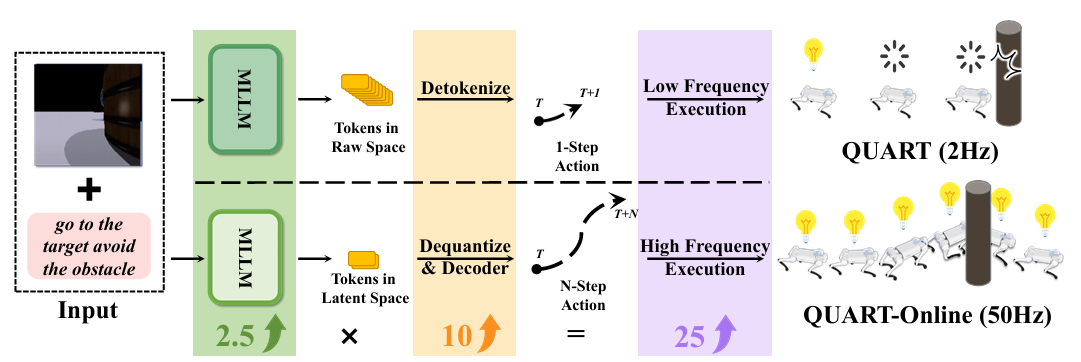
▲图1|QUART-Online方法框架
MoRE: Unlocking Scalability in Reinforcement Learning for Quadruped Vision-Language-Action Models 【ICRA】
主要内容:
MoRE 提出了一种稀疏激活的混合专家架构,用于扩展大型多模态语言模型在四足机器人上的任务适应能力。该方法将多个低秩适配器(LoRA)作为不同专家嵌入模型中,并引入强化学习式的 Q-function 训练目标,使其能在混合质量数据上进行高效学习。MoRE 展示了在六种技能上的领先表现与优异的泛化能力,并成功实机部署,为多任务控制奠定基础。
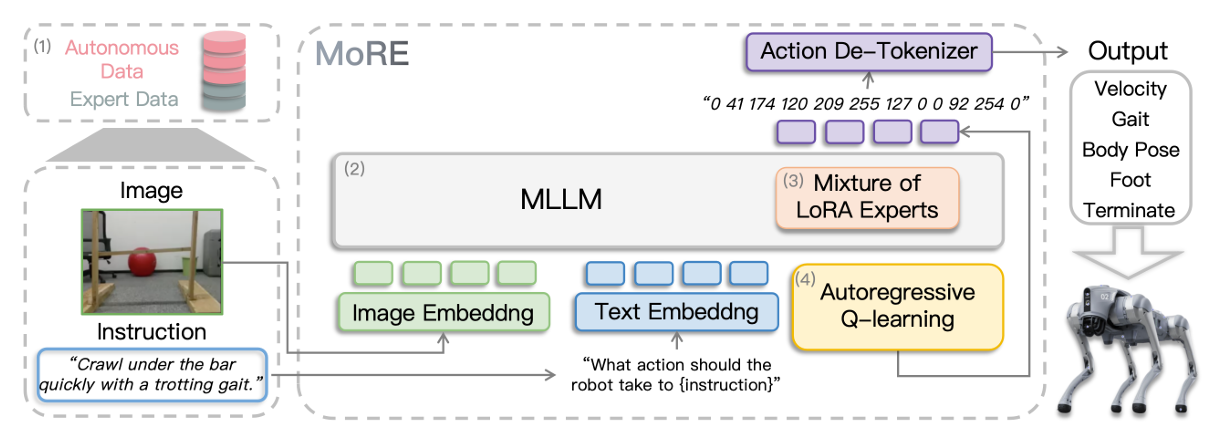
▲图2|MoRE方法框架
VLAS: Vision-Language-Action Model with Speech Instructions for Customized Robot Manipulation【ICLR】
地址:https://arxiv.org/pdf/2502.13508
主要内容:
该研究针对稀疏奖励和轨迹覆盖不足的问题,提出了 RBS(Retrospective Backward Synthesis),通过在目标条件 GFlowNets 中合成反向轨迹,丰富训练数据的多样性和质量,有效缓解稀疏奖励带来的学习困难。实验证明该方法显著提升了采样效率,并在多个标准基准上超越现有强基线
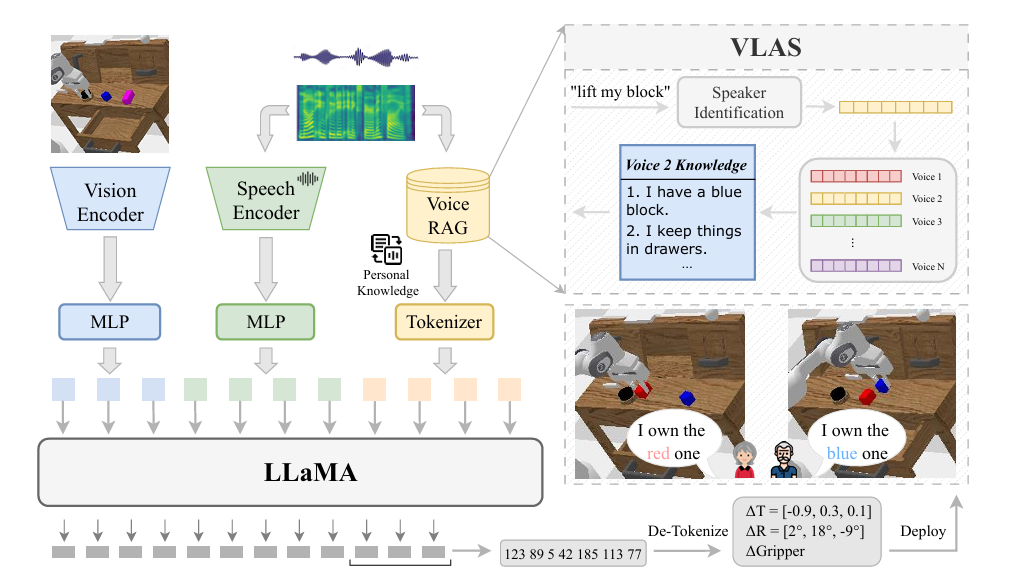
▲图3|VLAS方法框架
GEVRM: Goal-Expressive Video Generation Model For Robust Visual Manipulation【ICL】
地址:https://arxiv.org/pdf/2502.09268
主要内容:
GEVRM 聚焦 VLA 模型在实际部署中面对扰动信息时的鲁棒性问题,借鉴内部模型控制(IMC)理念,设计了一个视频生成引导的闭环决策系统。通过生成未来视觉目标、构建“扰动响应模拟嵌入”,并结合原型对比学习优化,GEVRM 能显式感知和补偿外部扰动,显著提升在标准与受扰环境下的操作稳定性,在 CALVIN 基准与真实任务中取得 SOTA 表现。
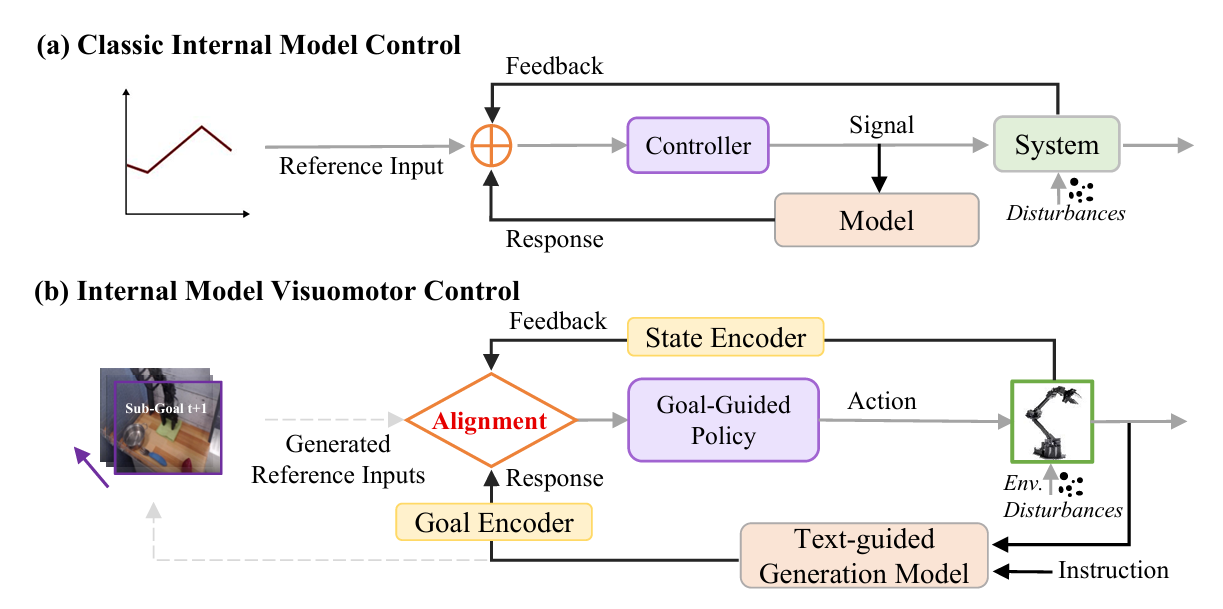
▲图4|GEVRM方法框架

具身智能的核心在于“感知-决策-行动”的闭环执行,而强化学习(RL)正是链接感知与行为的关键技术。MiLAB 团队在 2025 年上半年持续推动 RL 与模仿学习、多任务控制、策略泛化等方向的融合,推出了一系列高质量研究成果。
Stay Hungry, Keep Learning: Sustainable Plasticity for Deep Reinforcement Learning【ICML】
地址:https://openreview.net/pdf?id=hTrSxX3kiV
主要内容:
深度强化学习面临神经元“早期偏倚”与“死亡神经元”问题,限制了策略的持续学习能力。为此,研究团队提出了 SBP 框架,通过“周期重置+内蒸馏”的神经元再生机制,实现全网络的有机更新。结合 PPO 算法,形成了 Plastic PPO(P3O),显著提升了策略的可塑性与样本效率。
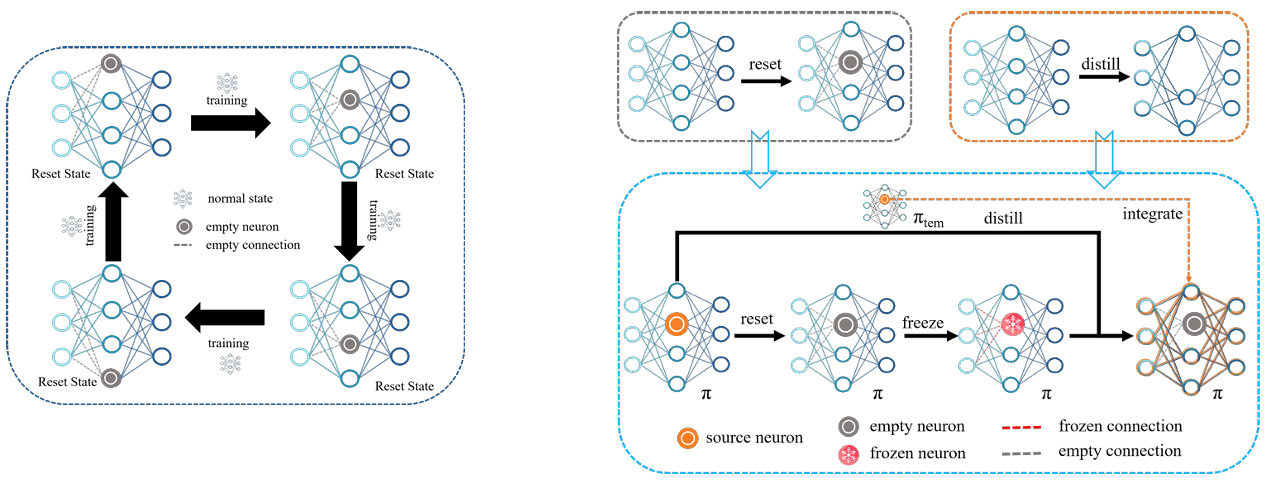
▲图5|P3O方法框架
ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning【ICML】
地址:https://arxiv.org/pdf/2505.07395
主要内容:
传统 VLA 模型依赖模仿学习,难以应对训练数据质量不一的挑战。ReinboT 将强化学习引入 VLA 框架,通过预测密集式回报来刻画操作任务的细粒度价值信息,使得模型能更鲁棒地生成决策动作。该方法在 CALVIN 混合质量数据集上表现优异,在真实任务中也展现出强大的小样本学习与泛化能力。
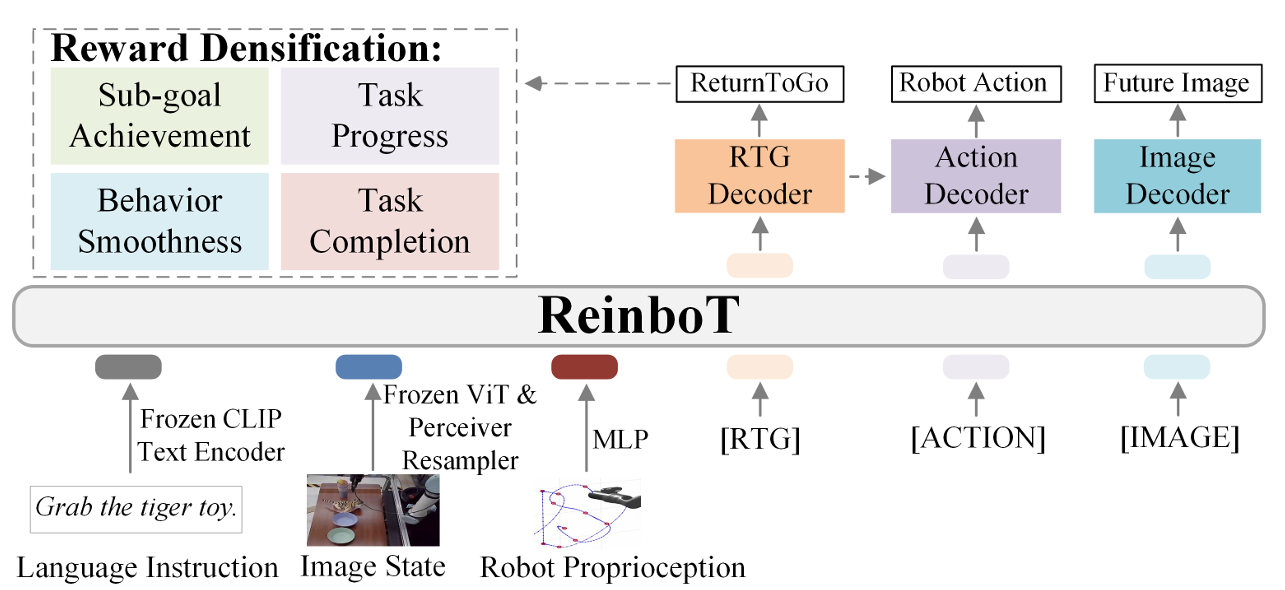
▲图6|ReinboT方法框架
Score-Based Diffusion Policy Compatible with Reinforcement Learning via Optimal Transport【ICML】
主要内容:
OTPR 创新性地将扩散策略模型与强化学习目标结合,通过最优传输(OT)理论建立两者之间的数学联系。Q 函数被视作传输代价,策略被建模为 OT 映射,同时引入了掩码机制与兼容性重采样来提升训练稳定性。这一融合方法不仅提升了扩散策略在稀疏奖励场景下的表现,也为 IL 与 RL 的联合优化提供了新的范式。
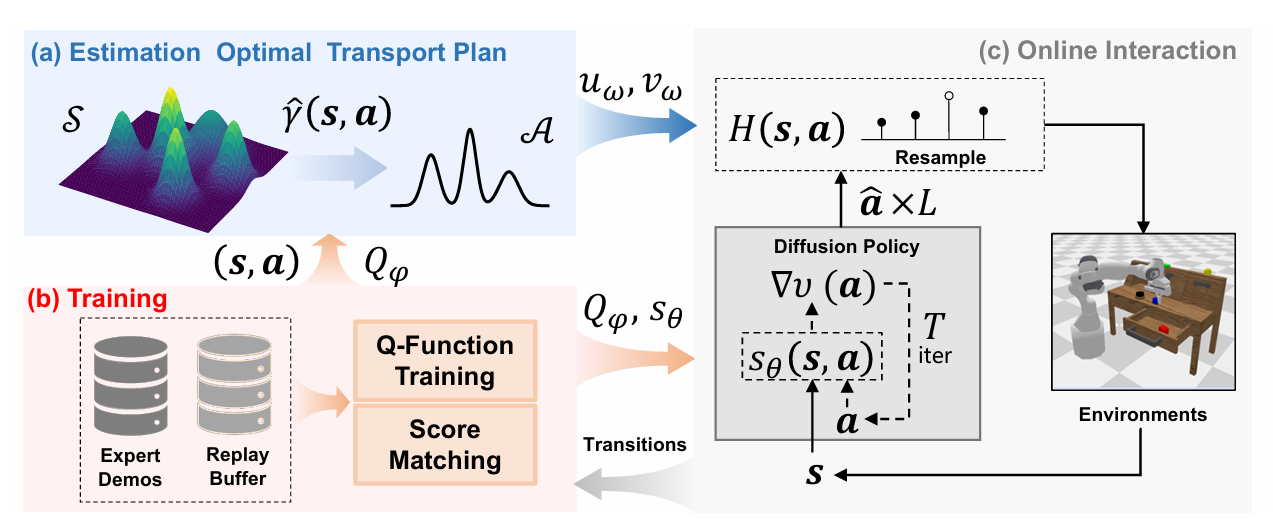
▲图7|OTPR方法框架
Multi-Task Multi-Agent Reinforcement Learning via Skill Graphs【RAL】
地址:https://arxiv.org/pdf/2507.06690
主要内容:
面向多任务与多智能体控制场景,MiLAB 团队提出了基于技能图的层次式强化学习架构。高层模块使用任务无关的技能图建模通用策略迁移能力,低层模块采用标准 MARL 算法独立训练,突破了现有方法对任务相关性和知识共享的限制,显著提升了泛化性能与适应性。
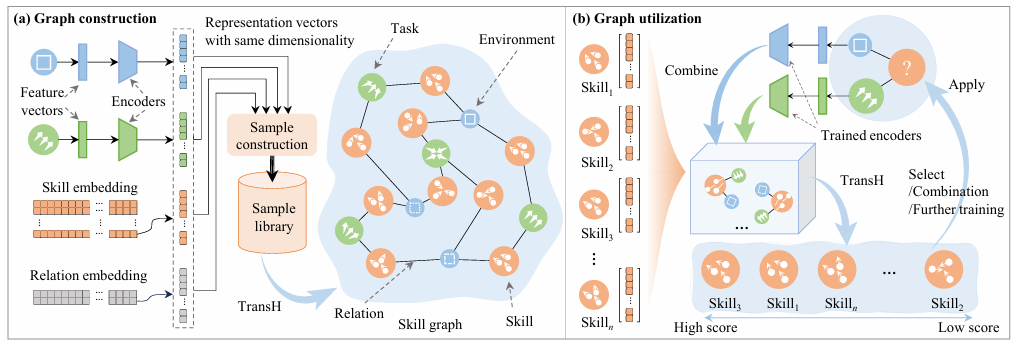
▲图8|方法框架
CARP: Visuomotor Policy Learning via Coarse-to-Fine Autoregressive Prediction【ICCV】
主要内容:
在动作策略建模上,传统的自回归模型高效但精度有限,而扩散模型虽精准却计算开销大。MiLAB 提出的 CARP(Coarse-to-Fine AutoRegressive Policy)打破这一对立,将动作序列生成拆解为“粗到细”的多尺度自回归过程。该方法先通过动作自编码器捕捉多尺度信息,再用 Transformer 逐层细化,最终实现比肩扩散模型精度的同时,将推理效率提升近 10 倍。这种兼顾性能与效率的新范式,展示了在机器人动作生成上更具实用性的方向。
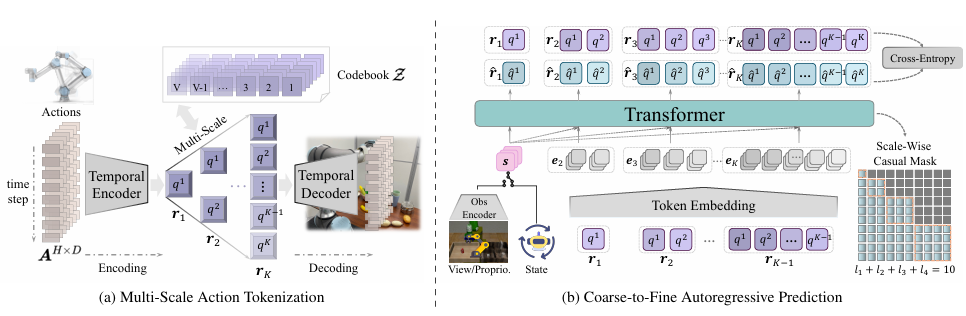
▲图9|CARP方法框架
Rethinking Latent Redundancy in Behavior Cloning:An Information Bottleneck Approach for Robot Manipulation【ICML】
地址:BC-IB for Robot Manipulation
主要内容:
尽管行为克隆(BC)是机器人模仿学习的核心方法,但其潜在表征常被冗余信息干扰,制约了泛化能力。为此,MiLAB 从信息论出发,引入互信息与信息瓶颈理论,构建了首个系统性分析 latent 冗余的行为克隆框架。在多个主流基准测试上,该方法显著提升了策略性能,验证了“少即是多”的感知建模哲学:压缩无关信息,提取关键特征,方能更好地服务下游控制任务。
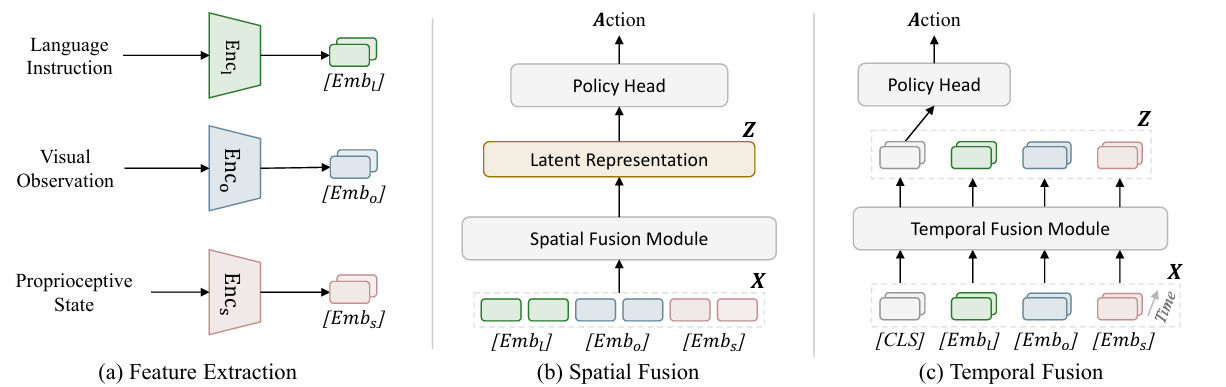
▲图10|方法框架
The Robotic Guide Dog for Individuals with Visual Impairments【Nature Reviews Electrical Engineering】
主要内容:
本文面向视障人群出行辅助需求,提出一套“机器人导盲犬”系统。该系统集成了路径规划、环境感知与人机交互等模块,意在替代传统导盲犬工具,提升视障者的出行独立性。论文不仅介绍了系统整体架构,也探讨了从技术研发到商业化落地过程中的实际挑战,展示了具身智能在特殊人群辅助中的落地潜力。

▲图11|机器狗导盲犬示例图
Koopman-Based Robust Learning Control With Extended State Observer【RAL】
主要内容:
本文提出一种结合 Koopman 操作子建模与扩展状态观测器(ESO)的鲁棒学习控制框架,旨在提升具身智能系统在未知扰动环境下的控制稳定性与训练数据利用率。方法通过主动学习机制引导高效数据采集,并借助 ESO 实现对外部扰动的精确补偿。实验验证表明,该方法显著提升了控制精度和泛化性能,为实际部署中的高可靠性控制提供了新解法。
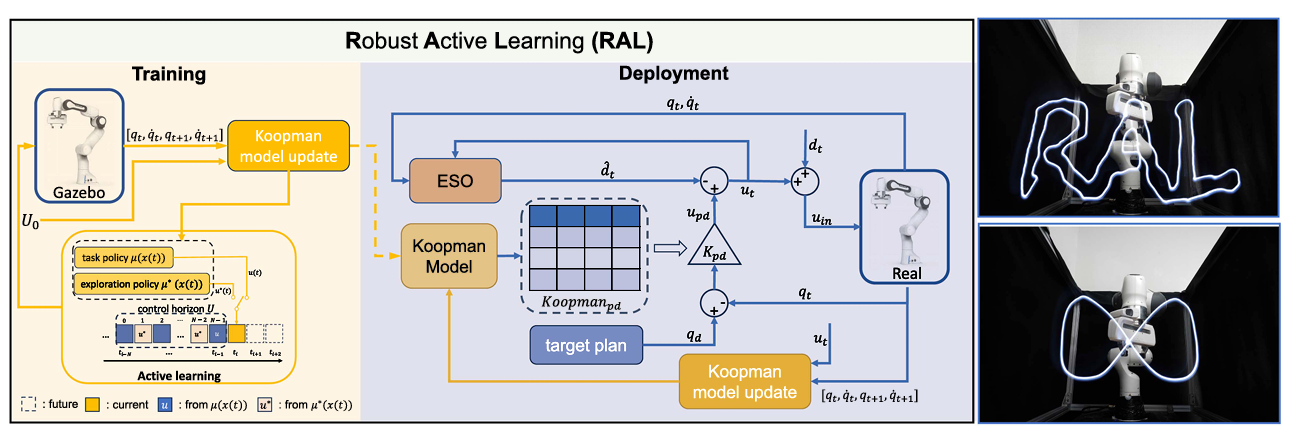
▲图12|RAL方法框架
回顾 2025 上半年,MiLAB 在具身智能的多个核心方向持续发力,产出了一系列高质量成果:从推动 VLA 模型在真实任务中的长时序执行与模态扩展,到探索强化学习与模仿学习的边界融合,从提升感知-控制策略的效率与泛化能力,到面向真实社会需求的系统级落地实践。无论是底层算法创新,还是系统集成与人机协作,MiLAB 的研究工作都展现出强烈的问题导向与技术突破力。
如果你对哪篇论文感兴趣,或者还想看我们盘点、解读哪些实验室的最新工作,欢迎在评论区告诉我们!我们会继续带来更多前沿的具身智能研究动态。

















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









