



引言
在机器人灵巧操作领域,实现从人类演示到机器人策略的高效迁移始终是核心挑战。长时序双任务面临高维动作空间探索难、人机具身结构差异及时空接触不连续等问题,传统强化学习或模仿学习方法常因早期失败陷入优化困境。近日,斯坦福大学与英伟达联合团队在《DexMachina: Functional Retargeting for Bimanual Dexterous Manipulation》中提出突破性方案,通过 “虚拟对象控制器” 与课程学习框架,让机器人仅需单次人类演示即可掌握复杂操作,为该领域开辟了新路径。
©️【深蓝AI】编译
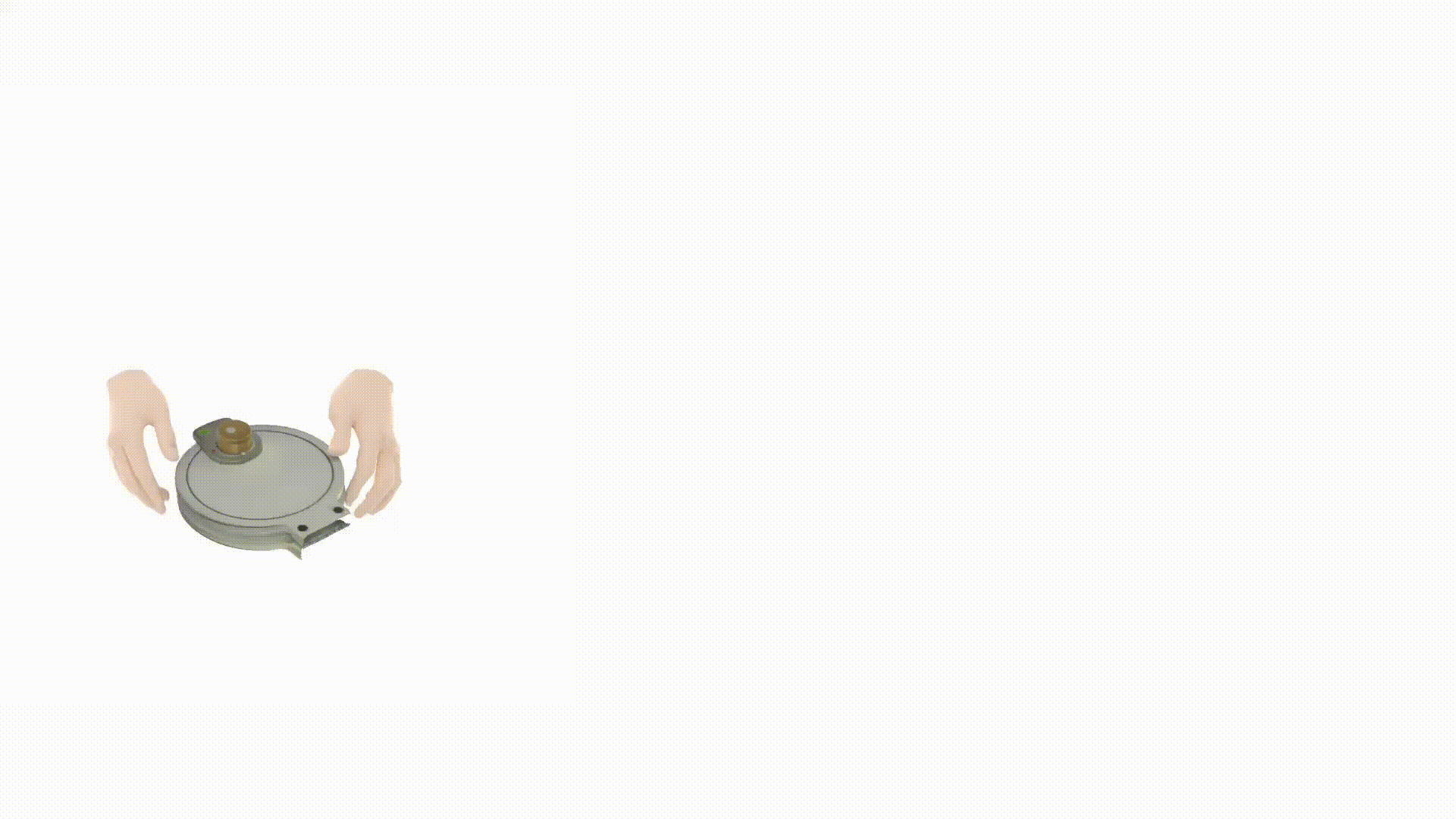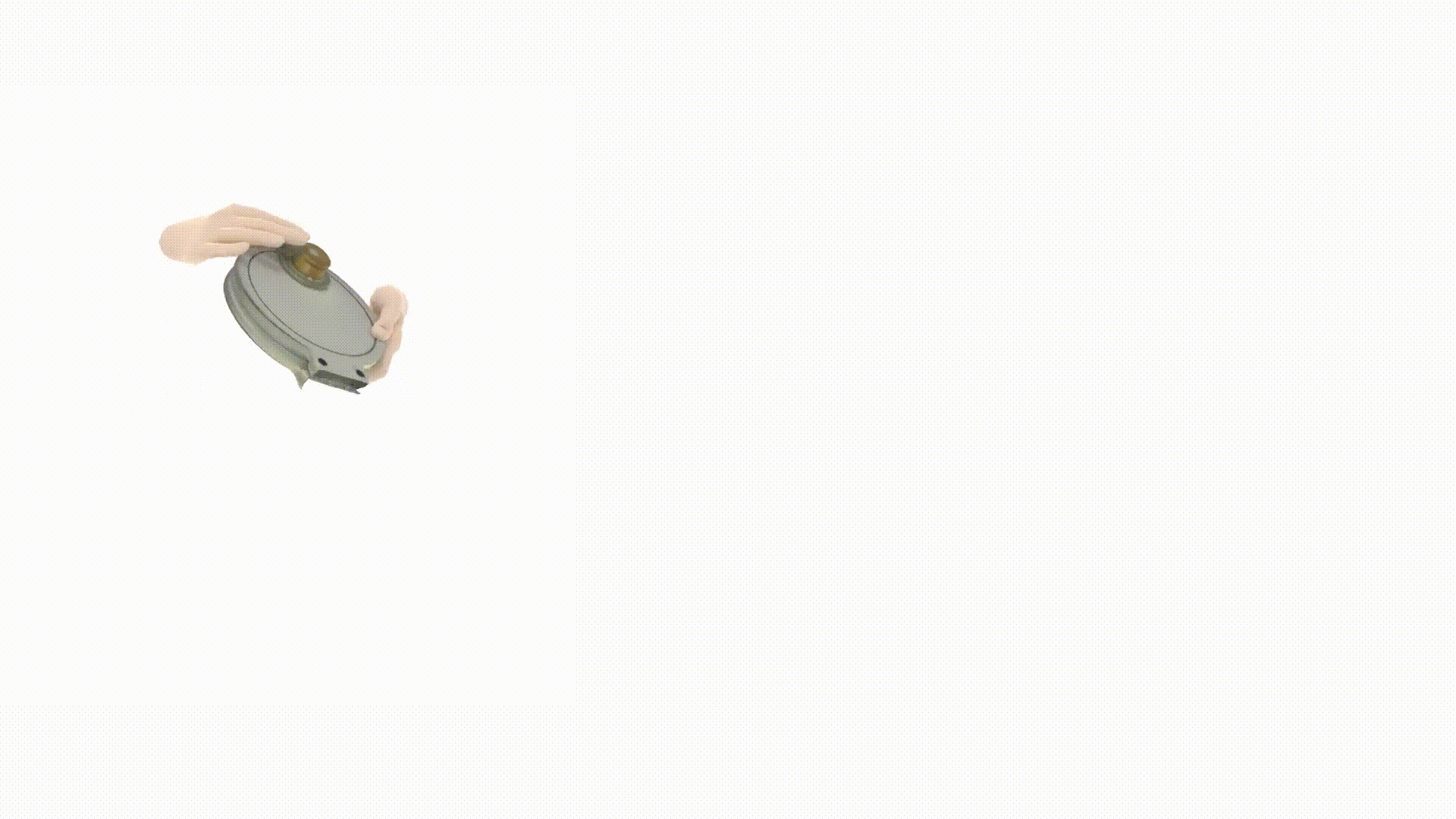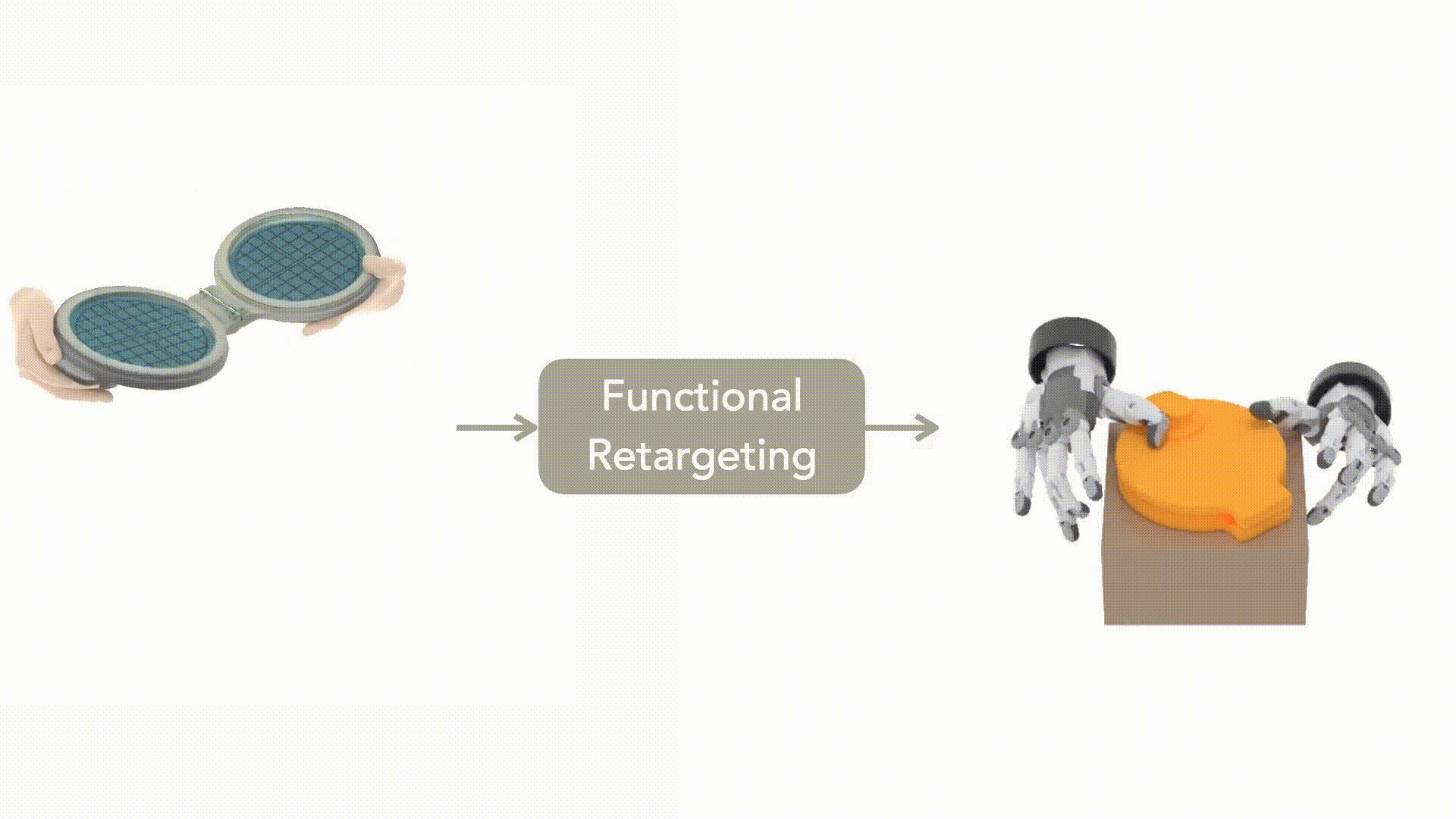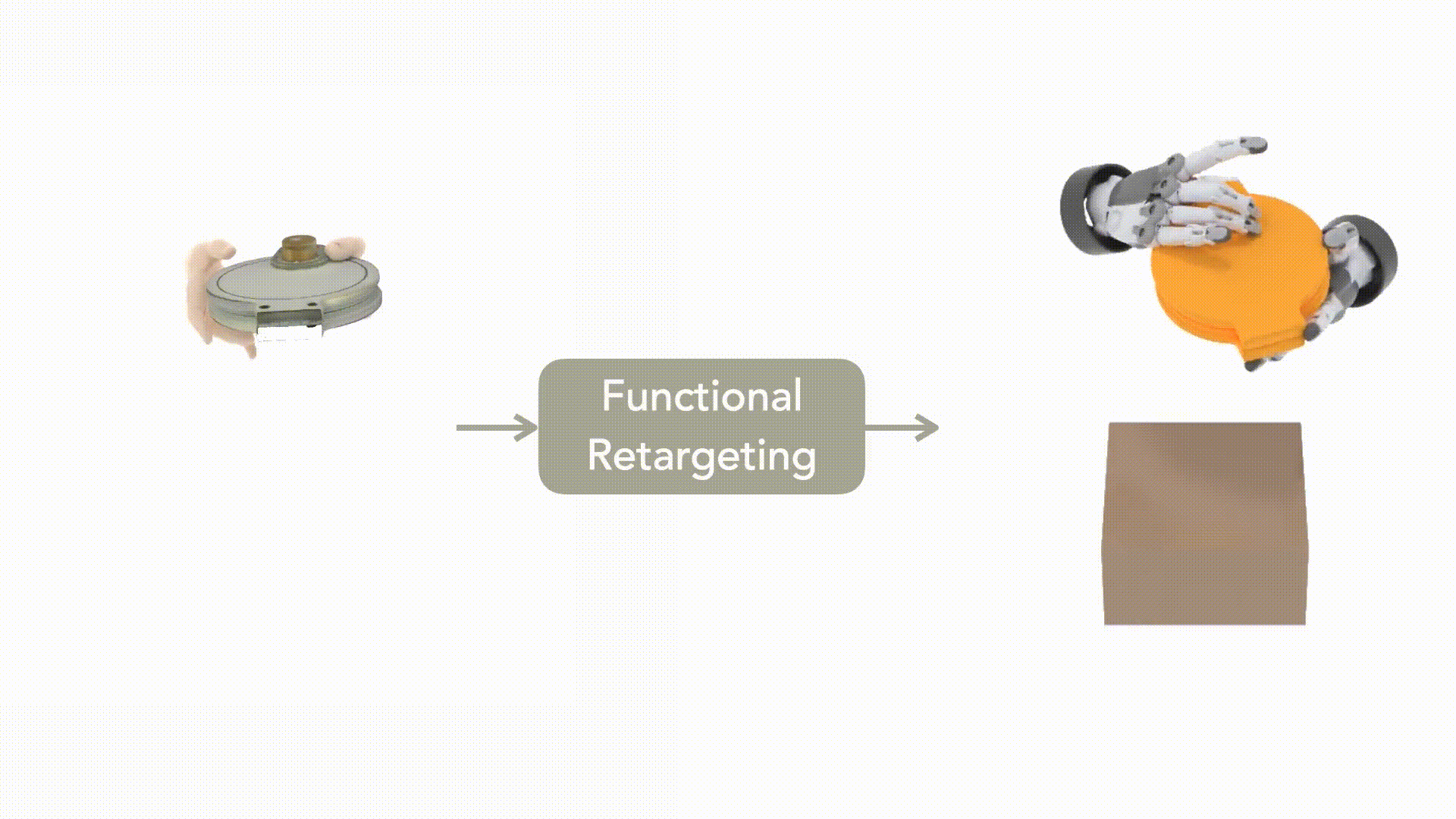
视频1:通过虚拟对象控制器与课程学习示教机器人©️【深蓝AI】编译
该研究的核心突破在于创新的“虚拟对象控制器”与课程学习机制 。训练初期,该控制器会像“教练”一样主动驱动物体沿演示轨迹运动,确保任务总能成功 ;随着机器人策略的进步,控制器的作用会逐渐减弱,最终将控制权完全交还给策略,迫使其独立完成操作 。这种从 “引导” 到 “自主” 的课程学习机制,有效解决了复杂任务中机器人因早期失败无法持续探索的痛点。

整体框架:功能重定向
DexMachina 是基于课程学习的强化学习算法,通过 "虚拟目标控制器" 与多维度奖励工程,旨在解决功能重定向问题。

图1:通过DexMachina 实现从人类演示到一系列现有灵巧手实例的功能重定向©️【深蓝AI】编译
DexMachina 的核心目标是,给定一次人类的手-物交互演示,学习一个机器人策略,该策略能够操控一双灵巧手,使得目标物体可以精确跟上演示中的轨迹。形式上,策略的目标是最小化在所有时间步长T上,实际物体状态与演示目标状态
之间的累积误差:
其中是待学习的机器人策略,
是一个计算位置、旋转和关节角度误差的距离函数。
基础: 任务奖励与环境设定
首先,算法定义了一个基础的任务奖励。用于直接激励策略去追踪物体的目标状态。该奖励由三个部分的乘积构成,分别衡量物体的位置误差
、旋转误差
、和关节角度的追踪精度误差
以鼓励均衡学习。最终的任务奖励公式为:
其中是控制各项误差敏感度的权重超参数。
引导:动作空间与辅助奖励
为了提供更明确的引导并约束探索空间,算法从人类演示中提取了运动和接触信息,并定义了混合动作空间和辅助奖励。
混合动作空间:为了提高学习效率,策略的动作输出被设计为混合模式。对于灵巧手的腕部,策略输出的是残差动作,该动作会与演示中经过运动学重定向的腕部基础动作相加 。对于手指关节,则使用绝对动作。这种设计有效地约束了腕部的探索范围,使其更贴近人类演示 。
辅助奖励: 该奖励包括运动模仿奖励与接触奖励。运动模仿奖励鼓励机器人的手部动作模仿人类,包括基于手部关键点位置匹配的模仿奖励$r_{imi}$以及基于关节角度匹配的行为克隆奖励,具体公式为:
奖接触励通过比较策略产生的接触点与从演示中近似提取的接触点,来引导机器人学习正确的交互方式,具体公式为:
最终,总的奖励是以上各项的加权和:
核心创新:虚拟对象控制器与自动课程
尽管有了辅助奖励,但在长时程、复杂接触的任务中,策略仍容易因早期失败而无法学习。为此,DexMachina引入了其核心创新:虚拟对象控制器与自动课程。
虚拟对象控制器:该控制器在仿真中实现,主要采用PD控制器,在每个时间步,控制器会计算当前物体状态与演示目标状态之间的误差,并据此施加虚拟力,从而驱动物体沿着演示轨迹自主移动。虚拟对象控制器的强度由增益参数控制。
自动课程:自动课程主要包括引导阶段,过渡阶段以及自主阶段三个部分。引导阶段开始时,虚拟对象控制器的增益会设置得非常高。此时,物体几乎完全由虚拟对象控制器驱动,策略即使什么都不做,也能获得很高的任务奖励。这使得策略可以在一个“无失败”的环境中,专注于学习辅助奖励。在过渡阶段,算法会持续追踪策略在各个奖励项上的平均表现。当策略表现足够稳定时,算法会自动以指数级衰减虚拟对象控制器的增益。最后,在自主阶段,虚拟对象控制器逐渐趋于0,策略为了继续获得高任务奖励,必须逐渐学会真正地通过自己的动作来操控物体,最终实现自主完成整个任务 。
这个从易到难的自动课程,让策略能够在一个受保护的环境下探索,然后平滑地过渡到解决完整的、无辅助的复杂操作任务,从而极大地提升了学习的成功率和效率 。

论文通过丰富的实验验证了 DexMachina 算法在功能重定向任务中的有效性,相关结果主要对应图2-4。在核心性能对比中,图2展示了 DexMachina 在 Inspire、Allegro、XHand 和 Schunk 四种代表性灵巧手上的任务成功率,结果显示其在长时序任务中显著优于 Kinematic Only、ObjDex、无课程奖励等基线方法。例如,在 Allegro 手上,DexMachina 在 Mixer-300 任务中成功率达 87.1%,而 ObjDex 仅为 57.6%,无课程奖励方法为 75.4%,体现出课程学习机制的关键作用。
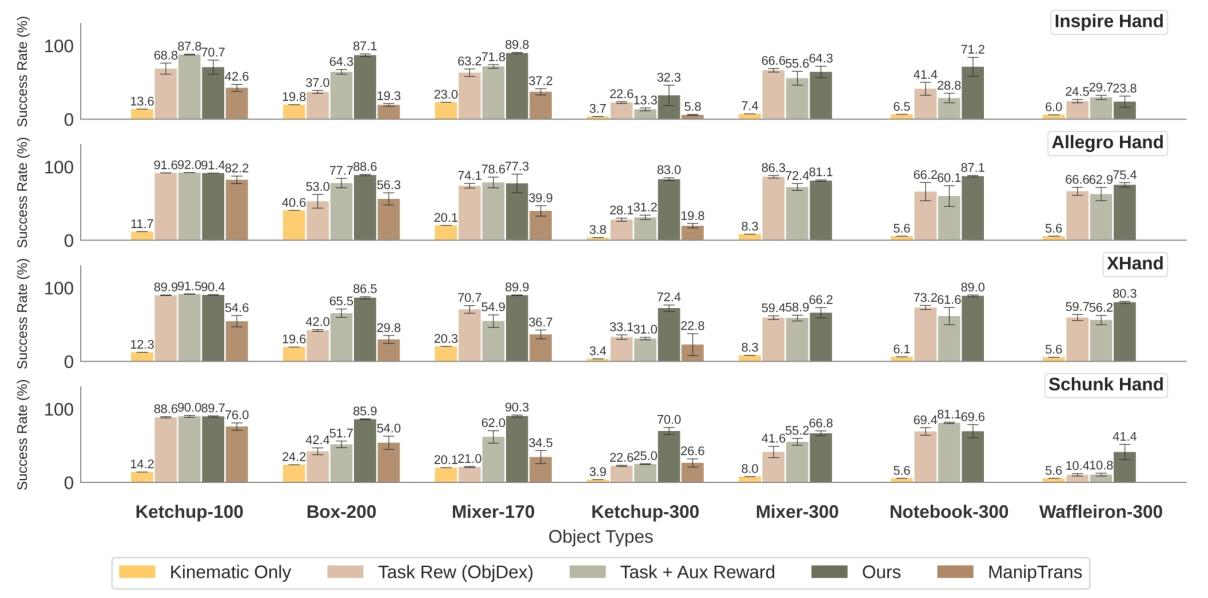
图2:DexMachina与多种基线方法在不同任务上的成功率对比©️【深蓝AI】编译
3评估了包括 Ability、DexRobot 在内的 6 种手部机器人在 4 项长时序任务中的表现,发现全驱动且尺寸较大的 Allegro 手部机器人平均成功率最高(87.1%-90.6%),而 actuated 指尖的 Schunk 手部机器人性能优于同尺寸的 Inspire 和 Ability ,揭示了自由度与硬件尺寸对操作能力的影响。
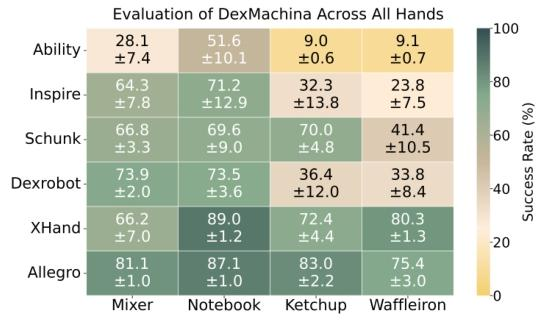
图3:使用 DexMachina 对六种手部机器人任务成功率进行全面评估©️【深蓝AI】编译
在消融实验方面,图4对比了混合动作、绝对动作和残差动作的效果,显示采用腕部约束的混合动作在任务奖励与辅助奖励联合优化下性能最优,例如在 Schunk 手部机器人上,混合动作 + 辅助奖励组合在 Box-200 任务中成功率达 70.8%,较绝对动作提升约 35%,验证了动作空间设计的必要性。此外,与 ManipTrans 的课程对比实验表明,仅衰减物理参数的方法在长时序任务中性能不稳定,而 DexMachina 的虚拟控制器衰减策略能持续提升跟踪精度,进一步凸显了算法设计的优越性。
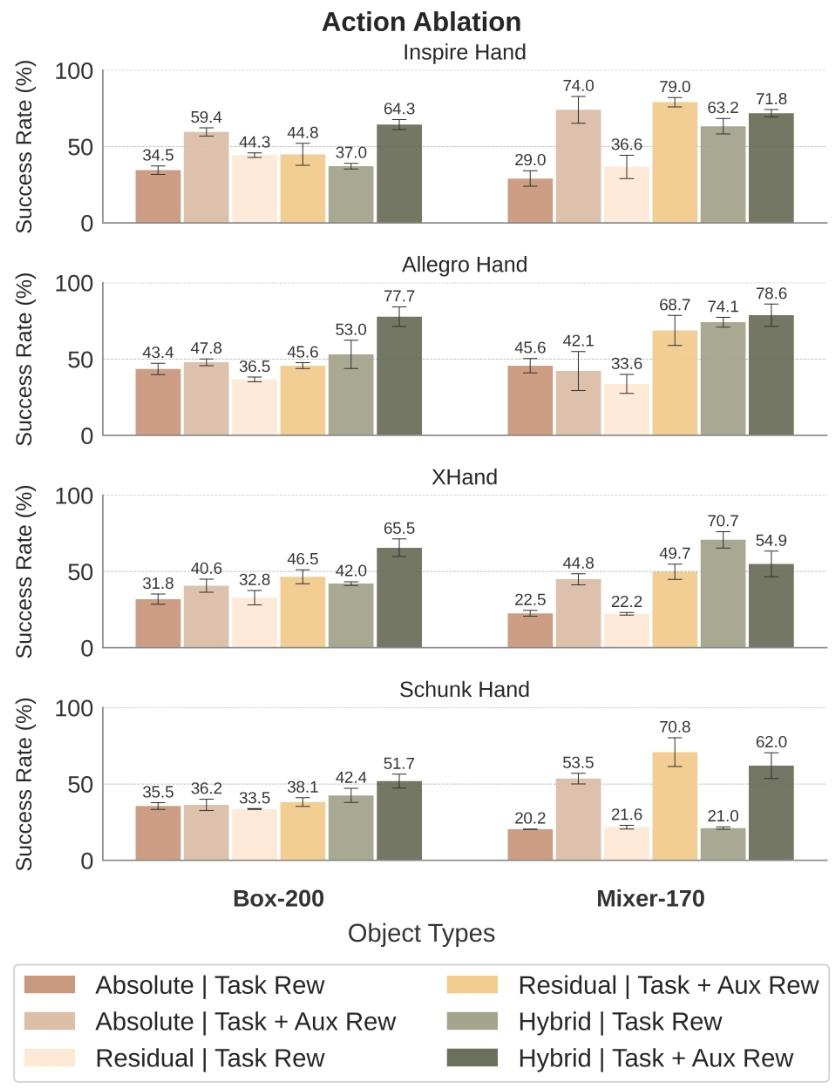
图4:手部机器人混合动作、绝对动作和残差动作的消融实验对比©️【深蓝AI】编译

该论文提出的 DexMachina 算法,旨在解决机器人长时程、双手灵巧操作的学习难题,克服了传统强化学习因早期失败难以探索以及模仿学习因“具身差异”难以成功的局限性。其核心采用一种创新的“虚拟对象控制器”与自动课程学习框架,通过整合基于演示追踪的任务奖励、融合运动与接触引导的辅助奖励系统,以及一个从强力辅助到完全自主、强度可自动衰减的虚拟控制器课程机制,实现了仅从单次人类演示中进行高效的功能性策略迁移。实验证明,该算法在多种灵巧手上的表现显著优于基线方法(例如,在 Allegro 手上的成功率达 87.1%),其混合动作空间设计也能将任务成功率提升约 35%。该研究为机器人从人类演示中学习复杂交互技能提供了一条高效、鲁棒的途径,不仅为不同灵巧手硬件的设计与评估提供了标准化的功能性测试平台,也推动了通用机器人灵巧操作向更高的数据效率和更强的泛化能力方向发展。
论文题目:DexMachina: Functional Retargeting for Bimanual Dexterous Manipulation
论文作者:Zhao Mandi、Yifan Hou、Dieter Fox、Yashraj Narang、Ajay Mandlekar、Shuran Song


















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









