



近日,DeepSeek公司又推出了名为NSA的先进技术,该框架通过创新的稀疏注意力机制,显著提高了大型语言模型(LLM)在处理长上下文时的效率和性能。紧随其后,Kimi公司也不甘落后,推出了MoBA框架,该框架能够将上下文长度扩展到10M,从而支持更复杂的任务和长文本分析。本文将深入探讨这两个框架的关键差异和各自的优势,以及它们对未来人工智能研究和应用可能产生的影响。
技术报告地址:kimi moba: https://github.com/MoonshotAI/MoBA/blob/master/MoBA_Tech_Report.pdf
deepseek nsa: https://arxiv.org/pdf/2502.11089
其中kimi开源了代码,项目地址:https://github.com/MoonshotAI/MoBA
一、背景
在大型语言模型的军备竞赛中,“上下文窗口长度"已成为衡量模型能力的黄金标准。从GPT-4的128k到Claude 3的1M,再到Kimi近期宣称的10M级窗口,这场竞赛背后隐藏着严峻的技术挑战:传统的全注意力机制(Full Attention)在计算复杂度上呈现O(N²)的爆炸式增长。当处理百万级token时,单次推理的显存占用将超过当前最强GPU(如H100的80GB显存)的物理极限,这使得扩展上下文窗口成为"不可能三角”——既要保持模型性能,又要控制计算资源消耗,还要实现商业可行性。
这解释了为何DeepSeek、Kimi等头部玩家纷纷聚焦稀疏注意力算法(Sparse Attention)的研究。这场技术博弈的本质,是探索如何在人类认知效率与机器计算效率之间找到最优解。
两种方法均提出稀疏注意力算法以降低计算复杂度并扩展上下文处理能力,但在实现路径上存在显著差异。
NSA(Nested Sparse Attention)通过动态分层稀疏策略,采用"粗粒度区域筛选-细粒度特征关联"的双阶段机制,首先对输入特征进行空间维度的区域级压缩,进而在筛选出的关键区域内执行细粒度令牌级注意力计算,这种层级化稀疏架构有效平衡了计算效率与特征捕获能力。
MOBA(Mixture-of-Blocks Attention)则受混合专家(MoE)范式启发,将块级稀疏注意力与动态路由机制相结合,通过可学习的门控网络对输入序列进行分块,并基于内容相似性动态选择最相关的键-值块进行注意力聚合,这种模块化设计显著提升了长程依赖建模的灵活性。下文将详细介绍这两种方法的内容。
二、NSA(Nested Sparse Attention)
NSA采用动态分层稀疏策略,通过结合粗粒度的token压缩与细粒度的token选择,既保留了全局上下文感知能力,也确保了局部精度。我们的方法通过两项关键创新推进了稀疏注意力设计:
(1) 通过算术强度平衡的算法设计实现显著加速,并针对现代硬件进行了实现优化;
(2) 支持端到端训练,在保持模型性能的同时减少预训练计算量。
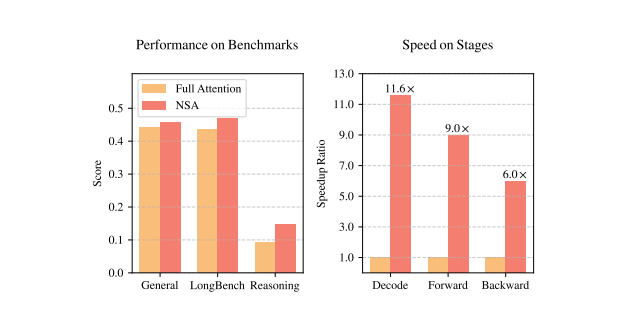
▲图1|完全注意力机制和NSA的效果与性能对比图©️【深蓝AI】编译
如图1所示,实验表明采用NSA预训练的模型在通用基准测试、长上下文任务和基于指令的推理中均保持或超越全注意力模型。同时,NSA在处理64k长度序列时,在解码、前向传播和反向传播阶段均实现了对全注意力模型的显著加速,验证了其在模型全生命周期中的高效性。
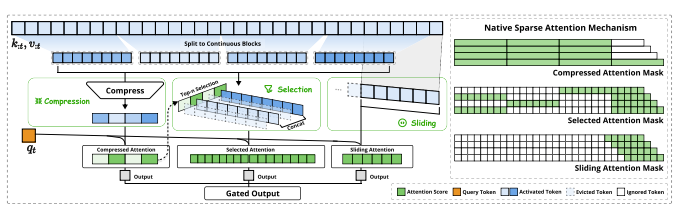
▲图2|NSA架构概览图©️【深蓝AI】编译
如图2所示,NSA通过将键和值组织成时间块,并经由三个注意力路径进行处理,有效降低单次查询的计算量:压缩的粗粒度标记、选择性保留的细粒度标记,以及用于局部上下文信息的滑动窗口。随后通过专用内核实现最大化实际效率。NSA针对前述关键需求引入两大核心创新:(1) 硬件对齐系统:优化块状稀疏注意力以实现张量核心的高效利用和内存访问优化,确保算术强度的平衡性;(2) 训练感知设计:通过高效算法和反向算子实现稳定的端到端训练。这种优化使NSA既能支持高效部署,又能实现端到端训练。
现代稀疏注意力方法在降低Transformer模型的理论计算复杂度方面取得了显著进展。然而,大多数方法主要在推理阶段应用稀疏性,同时保留预训练的全注意力主干网络,这种做法可能引入架构偏差,从而限制了其充分挖掘稀疏注意力优势的能力。为了充分发挥自然稀疏模式下注意力机制的潜力,研究人员提出将完全注意力机制中的原始键值对替换为针对每个查询 q𝑡 生成的更为紧凑且信息密度更高的键值对集合 𝐾𝑡, 𝑉𝑡。具体而言,将优化后的注意力输出形式化定义如下:
然后可以因此设计不同的映射方案以获得不同类别的
如图2所示,NSA有三种不同的映射策略,,分别代表着针对键值对的压缩,选择,以及滑动窗口策略。
是对应策略的gate score。另
代表重映射的键值对:
Token压缩
通过将连续的键或值块聚合成块级表示,我们获得了能捕获整个块信息的压缩键和值。具体而言,压缩键表示的定义形式为:
Token筛选
仅使用压缩后的键和值可能会丢失重要的细粒度信息,这使得需要选择性地保留部分关键键值对。研究人员因此设计了低计算开销的token选择机制,该机制能有效识别并保留最相关的token。
研究人员设计了一种基于Block的筛选机制,首先将键、值序列划分为选择块。为了确定对注意力计算最为重要的块,需要为每个块分配重要性分数。下面计算这些块级重要性分数的方法:
在得到每个block的重要性分数之后,根据分数高低排序得到top n的sparse blocks
滑动窗口
为了避免注意力机制只关注局部的信息,研究人员引入了一个专门的滑动窗口分支来显式处理局部上下文,使其他分支(压缩和选择)能够专注于学习各自特征而不被局部模式捷径化。
NSA简单的伪代码表示如下:
def NSA_attention(query, keys, values,
compress_size=32, # 压缩块大小
select_size=64, # 选择块大小
window_size=512, # 滑动窗口大小
top_n=16): # 选择块数量
# 1. 压缩块注意力
compressed = compress_blocks(keys, values, compress_size)
# 2. 选择重要块
blocks = split_into_blocks(keys, values, select_size)
scores = [score_block(query, block) for block in blocks]
selected = top_k_blocks(scores, top_n)
# 3. 滑动窗口
local = (keys[-window_size:], values[-window_size:])
# 计算三路注意力并组合
attn_outputs = [
flash_attention(query, c_k, c_v) for c_k, c_v in [compressed, selected, local]
]
return sum(g * out for g, out in zip(gate_weights(query), attn_outputs))
三、MOBA(Mixture-of-Blocks Attention)
Kimi团队提出了一种遵循"更少结构"原则的解决方案,使模型能够自主决定关注的位置,而非引入预定义的偏置,即混合块注意力(Mixture of Block Attention,MoBA)。这是一种将专家混合(Mixture of Experts,MoE)原则应用于注意力机制的创新方法。
MoBA方法很好地回答了以下问题,如何设计一种鲁棒且适应性强的注意力架构,使其在保留原始Transformer框架的同时遵循"更少结构"原则,允许模型自主决定关注位置而不依赖预定义的偏置?理想情况下,这种架构应能无缝切换完整注意力模式与稀疏注意力模式,从而最大限度地提升与现有预训练模型的兼容性,实现高效推理和加速训练,且不牺牲模型性能。
MoBA的灵感来源于混合专家网络(MoE)和稀疏注意力技术。前者主要应用于Transformer架构中的前馈网络(FFN)层,而后者被广泛用于扩展Transformer以处理长上下文。我们的方法创新之处在于将MoE原理应用于注意力机制本身,从而实现对长序列更高效、更有效的处理。
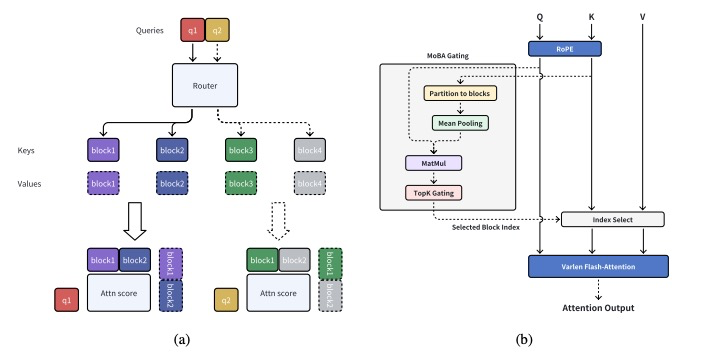
▲图3|MoBA架构示意图©️【深蓝AI】编译
和标准注意力机制中query token对整个上下文进行注意力操作不同的是,MoBA可以使得每个query token只关注Key和Vlaue对中的子集:
![]()
MoBA的关键创新在于块分区和选择策略。将长度为N的完整上下文划分为n个块,其中每个块代表后续标记的子集。为方便起见,假设上下文长度N可被块数量n整除。此时块大小B可表示为B = N/n。
类似地,再通过TopK 筛选机制,可以使得每个query有选择性地关注到不同块的token子集,而不是整个上下文
其中,代表门控机制(gating mechanism),目的是为了给每个token选择最相关的Blocks。MoBA的门控首先计算一个相关性分数,用以衡量query token和每个block的相关性,每个block的门控值由下式给出:
其中,由query token和选中的键值对的平均池化构成
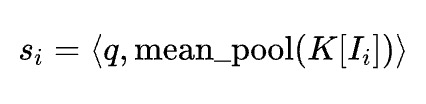
MoBA机制的伪代码示例如下:
def MoBA_attention(query, keys, values, block_size=512, top_k=3):
blocks = split_into_blocks(keys, values, block_size)
scores = [gate(query, block) for block in blocks]
selected = top_k_blocks(scores, top_k)
return flash_attention(query, selected_blocks)
四、评测结果
NSA
NSA和完全attention机制在不同数据集上的评测对比见下表,研究人员评估了预训练的NSA模型和全注意力基线模型在涵盖知识、推理和编码能力的综合基准测试套件上的表现,包括MMLU、MMLU-PRO、CMMLU、BBH、GSM8K、MATH、DROP、MBPP和HumanEval。尽管NSA具有稀疏性,NSA仍实现了更优的综合性能,在9项指标中有7项超越了包括全注意力在内的所有基线模型。这表明虽然NSA在较短序列上可能未充分发挥其效率优势,但仍展现出强劲性能。值得注意的是,NSA在推理相关基准测试中取得显著提升(DROP:+0.042,GSM8K:+0.034),说明基于NSA的预训练有助于模型发展专门的注意力机制。这种稀疏注意力预训练机制迫使模型聚焦于最关键信息,通过过滤无关注意力路径的噪声,潜在地提升了性能。在不同类型评估中表现的一致性也验证了NSA作为通用架构的鲁棒性。

▲表1|NSA在不同数据集上和完全attention机制的对比©️【深蓝AI】编译
MoBA
研究人员对MoBA在各种现实下游任务中进行了全面评估,将其性能与完整注意力模型进行比较。为便于验证,实验从Llama 3.1 8B基础模型开始,该模型被用作长上下文预训练的起点。评估在多个广泛使用的长上下文基准测试中进行。具体而言,在所有评估任务中,MoBA仅用于预填充阶段,而在生成阶段切换为完全注意力机制以获得更好的性能。如表2所示,Llama-8B-1M-MoBA展现出与Llama-8B-1M-Full高度可比的性能。特别值得注意的是,在最长的基准测试RULER中(MoBA在此测试中稀疏度达到1 - 4096×12/128K = 62.5%),Llama-8B-1M-MoBA几乎完全匹配Llama-8B-1M-Full的表现,其得分为0.7818,而后者为0.7849。
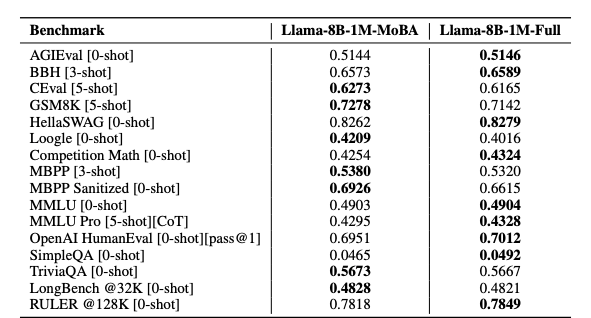
▲表2|MoBA和完全attention机制在不同数据集上的对比©️【深蓝AI】编译
根据综合评估数据显示,NSA与MOBA两种机制在多数自然语言处理任务中展现出与全注意力模型相当甚至更优的性能表现,仅在部分特定场景下存在微幅性能波动。具体而言,NSA机制在逻辑推理类任务中表现尤为突出,其在GSM8K数学推理和DROP阅读理解基准测试中分别取得显著性能跃升。而MoBA在代码生成与长文本编码任务中展现出更强的语义捕捉能力。
五、总结
DeepSeek最近的爆火盖过了之前所有大模型创业明星公司的风头,Kimi这个报告算是第一个正面迎接DeepSeek挑战的工作。尽管DeepSeek的模型十分强大,但它仍然是一个局限于文本模态的LLM。多模态领域(语音,图像,甚至视频模态)的DeepSeek R1 Zero还暂未浮出水面,期待DeepSeek这一波浪潮能够给我们带来更强大的图像大模型,语音大模型,视觉大模型等,希望未来能够看到大模型领域进一步百花齐放,百家争鸣的景象。
正如OpenAI首席科学家Ilya Sutskever所言:“未来三年,算法创新带来的性能提升将超过千倍算力增长。” 或许真正的AGI突破,将来自我们对人类认知机制的更深层解构——这正是NSA与MoBA之争给予我们的最大启示。
编译|Famcous
审核|apr

















 1538
1538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









