




 本文深入解析Java中的Map接口及其常用实现类,包括无序的HashMap、有序的TreeMap和LinkedHashMap,探讨它们的特点与应用场景。同时,对比分析了HashTable与ConcurrentHashMap在不同JDK版本中的实现原理,如锁机制、扩容策略等关键细节。
本文深入解析Java中的Map接口及其常用实现类,包括无序的HashMap、有序的TreeMap和LinkedHashMap,探讨它们的特点与应用场景。同时,对比分析了HashTable与ConcurrentHashMap在不同JDK版本中的实现原理,如锁机制、扩容策略等关键细节。
1.Map接口下常用的三个子类
HashTable、HashMap(无序)、TreeMap(有序)
2.AbstractMap类
对Map中的公共方法做了一个简单实现。(与AbstractList类似) 具体实现可以在子类中覆写。
3.LinkedHashMap类与TreeMap类序的区别
LinkedHashMap类是HashMap的一个子类,有序。
但是LinkedHashMap和TreeMap的序不同。LinkedHashMap的序是插入序,而TreeMap是两个接口(Compareable和Comparator)实现的方法排序,对Map中的数据进行排序。
TreeMap与HashMap类似。HashMap会根据哈希算法进行散列,因此,TreeMap输出元素的顺序和添加元素的散列不一定相同。而LinkedHashMap维护了链表,将添加元素的顺序依次添加到链表中。
4.Map的相关子类
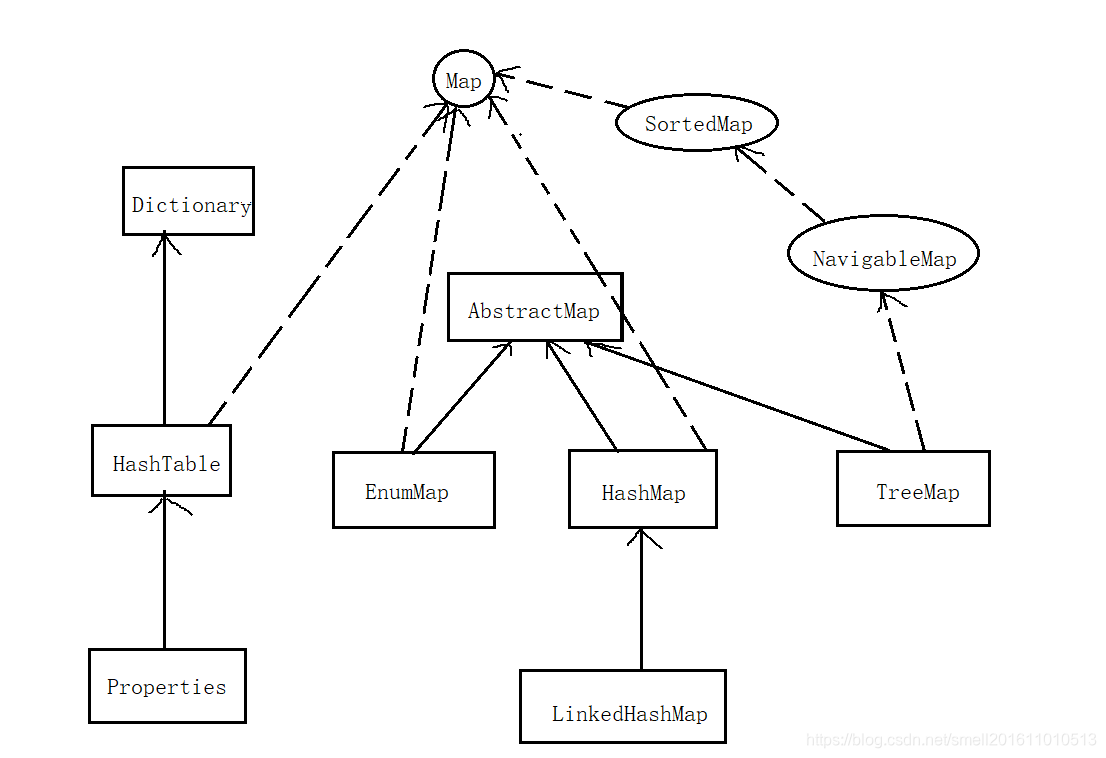
5.Map的操作方法
put(key,value)添加元素,或做替换(key已存在)。
get(key)取得元素
keySet():Set<key> 取得所有key值
values():Collection<value> 取得所有value值
remove(key)
Set<Map.Entry<K,V>> entrySet():将Map变为Set集合用于迭代输出。遍历:
Map没有Iterator接口,因此要先将Map变为Set。
6.HashTable
在JDK1.0就有,而Map接口是在JDK1.2时产生的。因此,早前版本时,HashTable不是Map的子类,而是Dictionary的子类。基于哈希表实现 也有11个桶。是早期版本的Map实现。
初始化策略:
当产生HashTable对象时,就将哈希表初始化。默认11,传多少,初始化多少。不会进行2的n次方处理。
线程安全如何保证?
在put、get、remove方法上使用内键锁,将整个哈希表上锁。使用串行化操作整表,性能较低。(如果要在第一个桶中添加数据,锁住了整个表,就不能在其它桶中进行操作了)
如何优化HashTable的性能?
将锁细粒度化,将整锁拆成多个锁进行优化。 即使用分段锁
7.ConcurrentHashMap
7.1JDK1.7实现
基于分段锁Segment来实现,每个Segment都是ReentrantLock的子类。
1.结构:将哈希表拆分为16个Segment,每个Segment下又是一个小的哈希表
2.关于锁:将原先整表的一把锁细粒度化为每个Segment一把锁,并且不同Segment之间互不干扰。
每个Segment实际上都是ReentrantLock的子类。
3.扩容机制:Segment在初始化后无法扩容(默认初始化为16),扩容实际上是Segment对应的每个小的哈希表,并且不同
Segment之间的扩容完全隔离。
7.2JDK1.8实现
1.结构上:与JDK1.8的HashMap如出一辙,也是哈希表+红黑树的底层结构。原先的Segment仍然保留,但是没有实际意义,
仅仅用作序列化。
2.关于锁:将原先锁一片区域再次细粒度化,只锁桶中的头节点。使用CAS+同步代码块(synchronized)
7.3对比JDK7与JDK8的ConcurrentHashMap
1.结构上的变化:
JDK7是基于分段锁的Segment
JDK8是哈希表+红黑树
2.锁的使用
JDK7使用ReentrantLock将Segment上锁。
JDK8使用CAS+synchronized代码块。

















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









