




 本文探讨了LeetCode上单词阶梯问题的多种解决方案,包括深度优先搜索(DFS)、广度优先搜索(BFS)及优化后的双端BFS算法。通过对各算法的详细解析和对比,展示了如何高效地寻找从beginWord到endWord的最短转换路径。
本文探讨了LeetCode上单词阶梯问题的多种解决方案,包括深度优先搜索(DFS)、广度优先搜索(BFS)及优化后的双端BFS算法。通过对各算法的详细解析和对比,展示了如何高效地寻找从beginWord到endWord的最短转换路径。
链接:
https://leetcode.com/problems/word-ladder/
大意:
给定一个单词beginWord以及单词endWord,还有一个词典wordList。要求找出从beginWord转换为endWord的最短序列长度,且每次转换候的单词都必须是wordList中单词,且每次转换只能是两个仅有一位(且是同一位置)不同的字符串进行转换。例子:

思路:
dfs回溯+剪枝。
从endWord往beginWord进行回溯,最终超时...
请看zhazhad代码。
代码:(超时)
class Solution {
int minCount = Integer.MAX_VALUE;
int curCount = 1; // 初始为1
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
if (!wordList.contains(endWord))
return 0;
// 一次转换即可 转换序列长度为2
if (oneWordDifferent(beginWord, endWord))
return 2;
// 从endWord开始dfs逆推表演 将endWord的访问标志置为true
boolean[] visited = new boolean[wordList.size()];
for (int i = 0; i < wordList.size(); i++) {
if (wordList.get(i).equals(endWord)) {
visited[i] = true;
break;
}
}
dfs(beginWord, endWord, wordList, visited);
return minCount == Integer.MAX_VALUE ? 0 : minCount;
}
public void dfs(String beginWord, String curWord, List<String> wordList, boolean[] visited) {
// System.out.println(beginWord + ":" + curWord + ":" + curCount);
if (oneWordDifferent(beginWord, curWord)) {
minCount = curCount + 1;
return ;
}
curCount++;
int idx = 0;
// 剪枝
while (curCount < minCount && idx < wordList.size()) {
if (!visited[idx] && oneWordDifferent(curWord, wordList.get(idx))) {
visited[idx] = true;
dfs(beginWord, wordList.get(idx), wordList, visited);
visited[idx] = false; // 回溯
}
idx++;
}
curCount--;
}
// 判断两个单词是否只有对应一位不同
public boolean oneWordDifferent(String beginWord, String curWord) {
int c = 0, idx = 0;
while (idx < beginWord.length()) {
if (beginWord.charAt(idx) != curWord.charAt(idx))
c++;
idx++;
}
return c == 1;
}
}结果:
超时。思考:也许得用BFS。。。
改进:
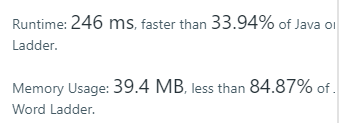
使用广度优先遍历算法解决。虽然通过了,但是效率好低啊(蠢哭... 急需大神代码安慰
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
if (!wordList.contains(endWord))
return 0;
// 一次转换即可 转换序列长度为2
if (oneWordDifferent(beginWord, endWord))
return 2;
boolean[] visited = new boolean[wordList.size()];
int count = 1;
for (int i = 0; i < wordList.size(); i++) {
if (wordList.get(i).equals(endWord)) {
visited[i] = true;
break;
}
}
List<String> curWords = new ArrayList<>();
curWords.add(endWord);
while (curWords.size() > 0) {
List<String> tmp = new ArrayList<>();
for (String s : curWords) {
for (int i = 0; i < wordList.size(); i++) {
if (!visited[i] && oneWordDifferent(s, wordList.get(i))) {
tmp.add(wordList.get(i));
visited[i] = true;
// 快速判断
if (wordList.get(i).equals(beginWord))
return count + 1;
if (oneWordDifferent(wordList.get(i), beginWord))
return count + 2;
}
}
}
count += 1;
curWords = tmp;
}
return 0;
}
// 判断两个单词是否只有对应一位不同
public boolean oneWordDifferent(String beginWord, String curWord) {
int c = 0, idx = 0;
while (idx < beginWord.length()) {
if (beginWord.charAt(idx) != curWord.charAt(idx))
c++;
idx++;
}
return c == 1;
}
}
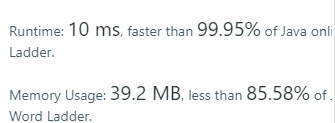
最佳:
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
if (beginWord == null || endWord == null || wordList == null) {
return 0;
}
// 将list转为set 查找速度转为O(1)
Set<String> dict = new HashSet<>(wordList);
if (!dict.contains(endWord)) {
return 0;
}
Set<String> set1 = new HashSet<>();
Set<String> set2 = new HashSet<>();
set1.add(beginWord);
set2.add(endWord);
return bfs(set1, set2, dict, 1);
}
private int bfs(Set<String> set1, Set<String> set2, Set<String> dict, int len) {
// 确保每次bfs都是对含元素少的set进行bfs
if (set1.size() > set2.size()) {
return bfs(set2, set1, dict, len);
}
Set<String> nextSet = new HashSet<>();
for (String word : set1) {
char[] chs = word.toCharArray();
for (int i = 0; i < chs.length; i++) {
char oldChar = chs[i];
for (char c = 'a'; c <= 'z'; c++) {
// 依次修改chs的每个位置上的字母(改为'a'-'z') 查看set2是否含有新单词
if (c != oldChar) {
chs[i] = c;
}
String newWord = new String(chs);
if (set2.contains(newWord)) {
return len + 1;
}
if (dict.contains(newWord)) {
nextSet.add(newWord);
dict.remove(newWord);
}
}
chs[i] = oldChar; // 将chs[i]修改为原来的字母 下一步修改下一位置的字母
}
}
// nextSet为空表明set1中所有元素都转不成dict中的字符串
if (nextSet.isEmpty()) {
return 0;
}
return bfs(nextSet, set2, dict, len + 1);
}
}
结论:
看着大神写的代码,就是心旷神怡。(本菜鸡还是得多联系...

















 3569
3569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









