




 本文介绍了如何利用字典树数据结构处理海量字符串查重问题。通过建立字典树,从文件file1和file2中快速找出file2中已存在的字符串。文中包含详细代码实现及测试效果展示。
本文介绍了如何利用字典树数据结构处理海量字符串查重问题。通过建立字典树,从文件file1和file2中快速找出file2中已存在的字符串。文中包含详细代码实现及测试效果展示。
问题背景:
给定两个含海量字符串的文件file1和file2,要求找出file2中哪些字符串存在于file1。处理方法很多,这里主要实现一下字典树的方法
字典树数据结构:
废话少说,直接看图(网上盗的...)
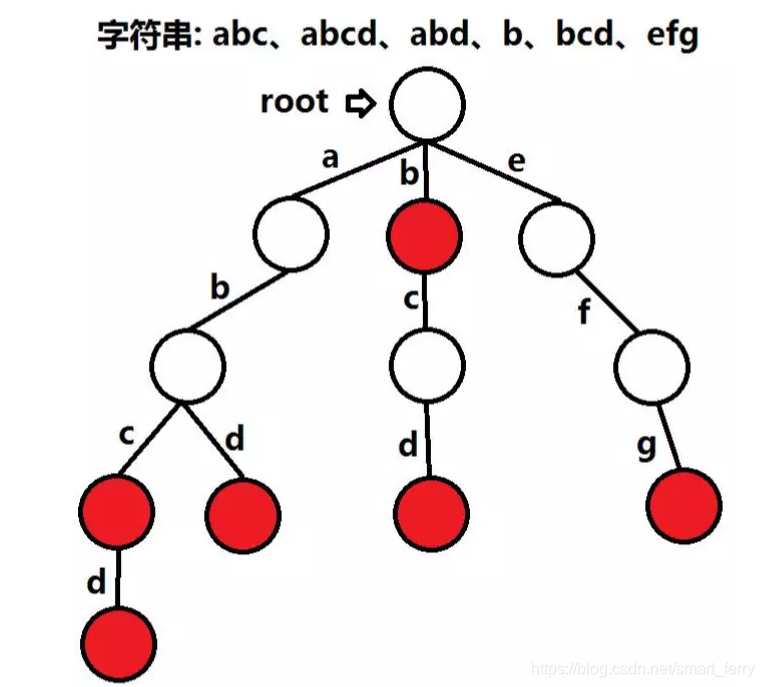
被标红的节点表示从根节点到该节点路径上的单词依次从上至下组成的字符串已经出现过。(节点内的值不重要,重要的是节点到其孩子节点边上的值)
在我的代码里,字典树每个节点数据结构如下:
class Node{
boolean v;
Node[] children = new Node[NUM_CHILD]; // 每个Node有5个孩子 每个孩子都是Node
}详细代码:
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Reader;
import java.io.Writer;
import java.util.Random;
public class DictTree {
private File f = new File("words.txt"), test = new File("test.txt");
private Writer writer = null;
pri 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









