




作者简介:大家好,我是码炫码哥,前中兴通讯、美团架构师,现任某互联网公司CTO,兼职码炫课堂主讲源码系列专题
代表作:《jdk源码&多线程&高并发》,《深入tomcat源码解析》,《深入netty源码解析》,《深入dubbo源码解析》,《深入springboot源码解析》,《深入spring源码解析》,《深入redis源码解析》等
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬。码炫课堂的个人空间-码炫码哥个人主页-面试,源码等
释放21集全网最深ConcurrentHashMap的vip视频,复现每一行源码
Kafka Connect
1、概要介绍
Kafka Connect是一个高伸缩性、高可靠性的数据集成工具,用于在Apache Kafka与其他系统间进行数据搬运以及执行ETL操作,比如Kafka Connect能够将文件系统中某些文件的内容全部灌入Kafka topic中或者是把Kafka topic中的消息导出到外部的数据库系统,如图所示。
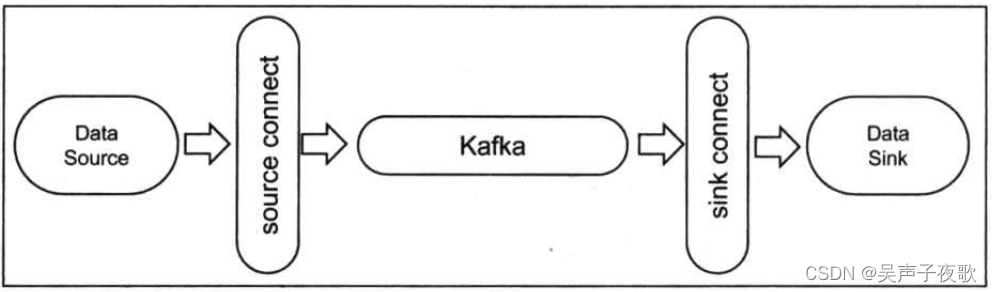
如图所示,Kafka Connect主要由source connector和sink connector组成。事实上,几乎大部分的ETL框架都是由这两大类逻辑组件组成的,如Apache Flume、Kettle等。source connector负责把输入数据从外部系统中导入到Kafka中,而sink connector则负责把输出数据
导出到其他外部系统。
根据Kafka Connect官网的介绍,目前其主要的设计特点如下。
- 通用性:依托底层的Kafka核心系统封装了connector接口,方便开发、部署和管理。
- 兼具分布式(distributed)和单体式(standalone)两种模式:既可以以standalone单进程的方式运行,也可以扩展到多台机器成为分布式ETL系统。
- REST接口:提供常见的REST API方便管理和操作,只适用于分布式模式。
- 自动位移管理:connector自动管理位移,无须开发人员干预,降低开发成本。
- 集成性:方便与流/批处理系统对接。
显然,一个ETL框架或connector系统是否好用的主要标志之一就是,看source connector和sink connector的种类是否丰富。默认提供的connector越多,我们就能集成越多的外部系统,免去了用户自行开发的成本。
2、standalone Connect
在standalone模式下所有的操作都是在一个进程中完成的。这种模式非常适合运行在测试或功能验证环境,抑或是必须是单线程才能完成的场景(比如收集日志文件)。由于是单进程,standalone模式无法充分利用Kafka天然提供的负载均衡和高容错等特性。
2.1、数据抽取与加载示例
下面我们在一个单节点的Kafka集群上运行standalone模式的Kafka Connect,把输入文件foo.txt中的数据通过Kafka传输到输出文件bar.txt中。首先我们制作配置文件。Kafka Connectstandalone模式下通常有3类配置文件:connect配置文件,若干source connector配置文件和若干sink connector配置文件。由于本例分别启动一个source connector读取foo.txt和一个sink connector写入bar.txt,故source和sink配置文件都只有一个,所以总共有如下3个配置文件。
connect-standalone.properties:connect standalone模式下的配置文件。connect--file-source.properties:file source connector配置文件。connect-file-sink.properties:file sink connector配置文件。
首先来编辑connect-standalone.properties文件。实际上,Kafka已经在config目录下为我们提供了一个该文件的模板。我们直接使用该模板并修改对应的字段即可,如下:
# connect-standalone.properties
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
bootstrap.servers:指定Connect要连接的Kafka集群主机名和端口号。本例使用localhost::9092。key/value.converter:设置Kafka消息key/value的格式转化类,本例使用JsonConverter,即把每条Kafka消息转化成一个JSON格式。key/value.converter.schemas.enable:设置是否需要把数据看成纯JSON字符串或者JSON格式的对象。本例设置为tue,即把数据转换成JSON对象。offset.storage.file.filename:connector会定期地将状态写入底层存储中。该参数设定了状态要被写入的底层存储文件的路径。本例使用/tmp/connect.offsets保存connector的
状态。
下面编辑connect-file-source.properties,它在Kafka的config目录下也有一份模板,本例直接在该模板的基础上进行修改:
# connect-file-source.properties
name=test-file-source
connector.class=FileStreamSource
tasks.max=1
file=foo.txt
topic=connect-file-test
name:设置该file source connector的名称。connector.class:设置source connector类的全限定名。有时候设置为类名也是可以的,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









