




作者简介:大家好,我是码炫码哥,前中兴通讯、美团架构师,现任某互联网公司CTO,兼职码炫课堂主讲源码系列专题
代表作:《jdk源码&多线程&高并发》,《深入tomcat源码解析》,《深入netty源码解析》,《深入dubbo源码解析》,《深入springboot源码解析》,《深入spring源码解析》,《深入redis源码解析》等
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬。码炫课堂的个人空间-码炫码哥个人主页-面试,源码等
释放21集全网最深ConcurrentHashMap的vip视频,复现每一行源码
回答
要分为两种情况,停机和不停机。
停机迁移
如果可以进行停机迁移,那么就提前几天发布一个公告,通知用户会预计停机多长时间。到了预订时间就关闭应用进行数据迁移,数据完成后进行数据对比,数据对比没有问题就发布新系统。
停机迁移是一个非常理想的情况,可以避免很多麻烦,当然,在绝大多数情况下我们是不会允许停机迁移的,毕竟数据迁移是一个大工程,不是几个小时能够处理好的。码哥经历过一次数据迁移,前前后后搞了两个多月。
不停机迁移
如果需要不停服将单库数据迁移到分库分表系统去的话,我们需要一个数据迁移系统,这个数据迁移系统的职责就是负责将数据从单库按照某种路由规则迁移到分库分表的环境中。如下:

那数据迁移程序怎么做呢?每次从单库单表中查询一批数据(比如每批 5000 条),然后按照路由规则写入到分库分表中。
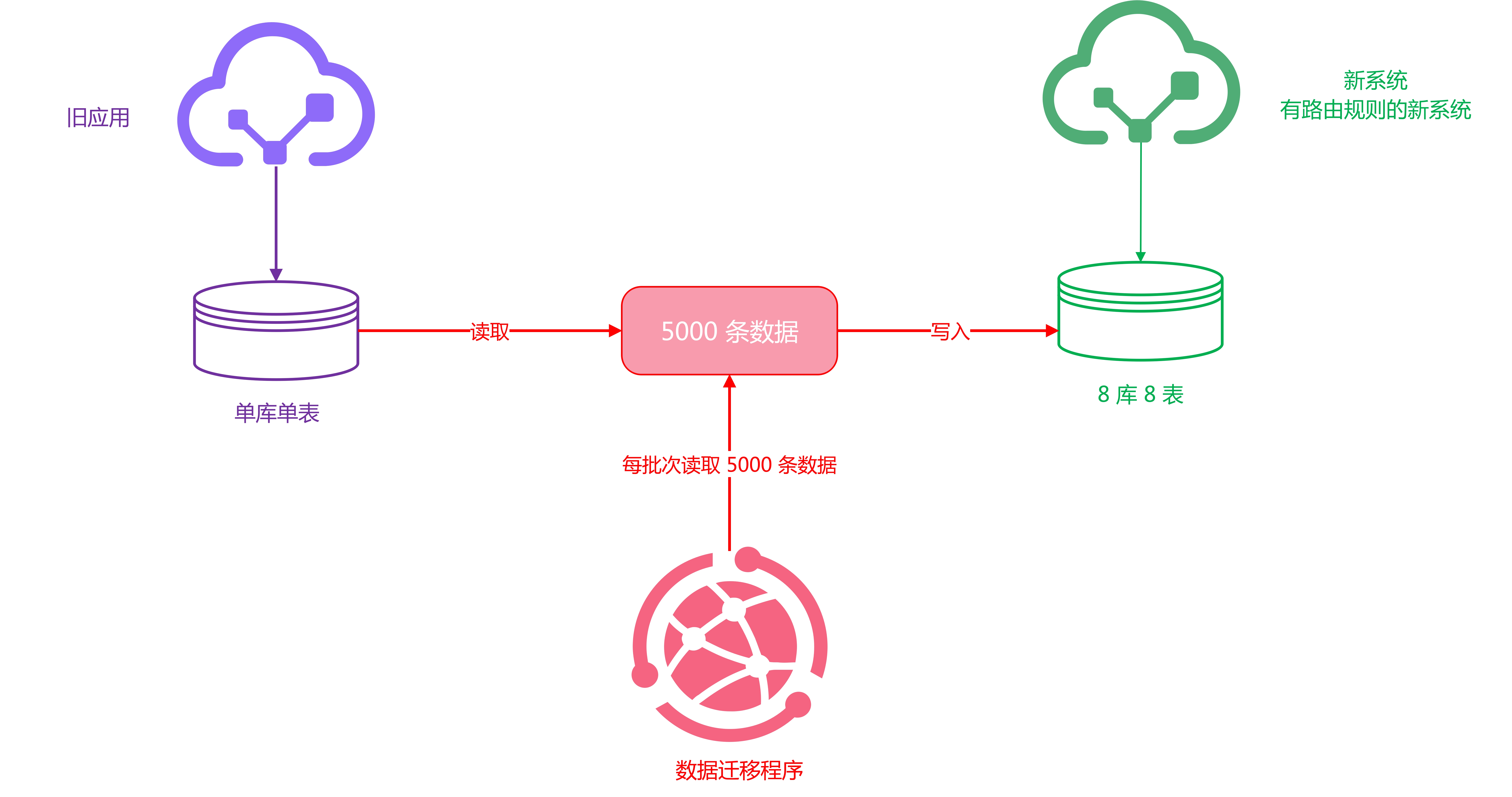
但是这样做会有一个小问题,那就是如果数据迁移程序中途蹦了怎么办?这时你不知道已经同步到哪里了,难道又要重头开始?很明显这是不可能的,所以我们需要将同步记录保留起来,需要新建两个表,一个同步批次表,一个同步详情表。
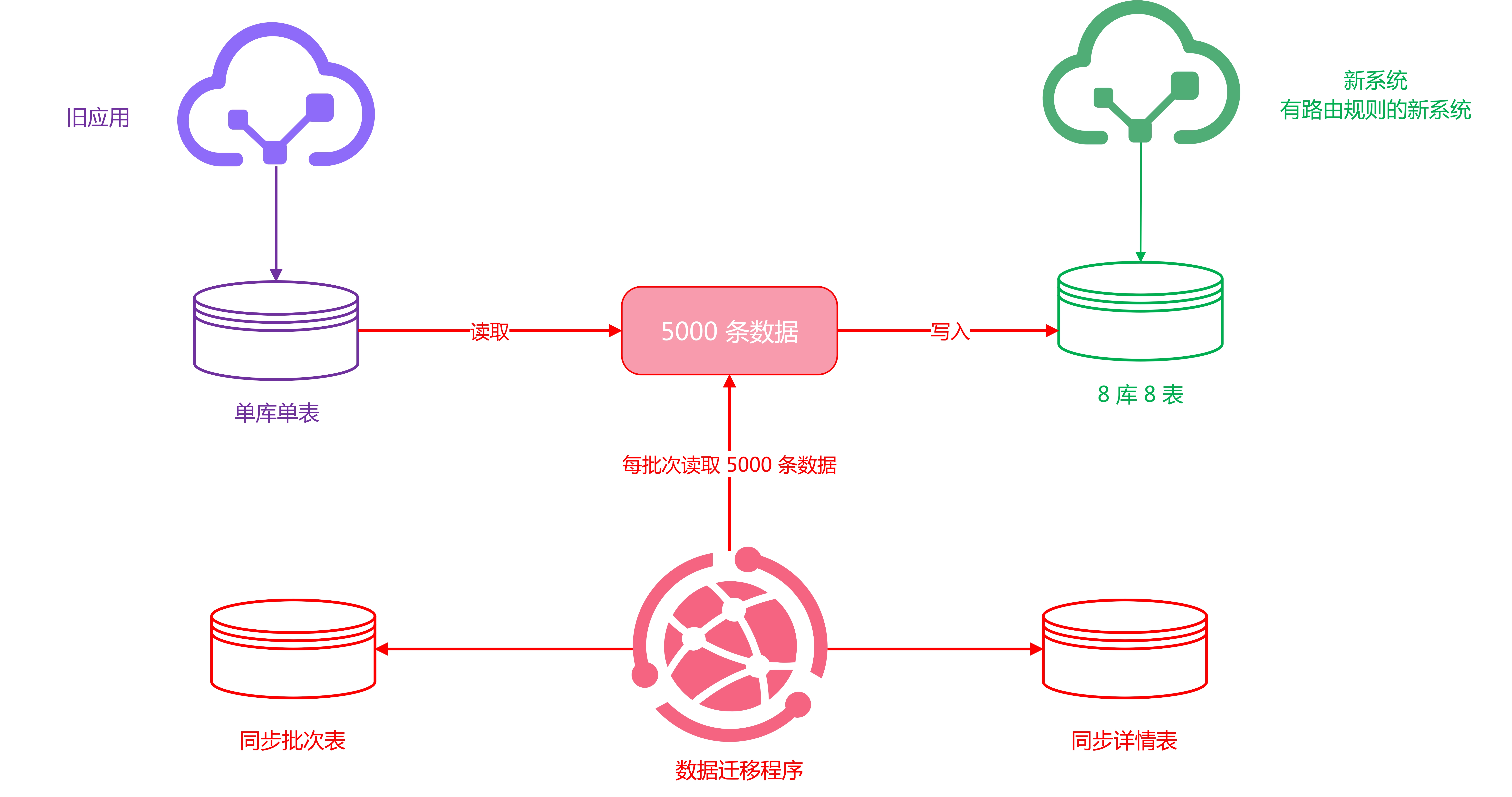
- 同步批次表记录同步进度,即已经同步到哪批次了,该批次是否已同步完成。
- 同步详情表记录每批次的详细情况,即每条记录是否已同步完成。
数据迁移程序每次拿一个批次的数据(也可以是多线程多批次),然后将这个批次插入到「同步批次表」中并标注状态为同步中,然后在「同步详情表」里面插入每条数据的同步情况,当整个批次的数据同步完成后,将「同步批次表」状态更新为已完成。
如果中途数据迁移程序崩溃导致同步中断,则我们可以从「同步批次表」里面拿到状态为同步中的批次数据,从这里重新开始即可。
我们的数据迁移程序一般都是按照某种顺序,比如 id,create_time、update_time,但是在我们开发过程,我们的项目并不是只有 insert,还有 update、delete ,如果我们将某条已经同步过去的数据进行了更新,则是无法通过数据迁移程序将这条变更记录同步到新库中。
所以,我们还需要一个实时同步的操作,能够将旧库中的变更能够实时同步到新库中去。这里我们利用 MySQL 的 binlog 日志即可,如下:
- 通过数据迁移程序的操作我们称之为全量同步。
- 通过
binlog日志的操作我们称之为增量同步。
全量同步我们几乎全是 insert 操作,但是增量同步既有 insert,还有 update、delete 操作,单个同步操作没什么问题,两个同时进行那需要考虑的问题就多了。我们一一来剖析。
insert操作
无论是哪个同步操作先执行完成,后面那个执行都会报主键冲突异常,对于这种异常无非就两种解决方案:
- 不管。这种异常是可以不需要处理了,因为数据已经存在了,后面一个插入不插入已经无所谓了。
insert操作转换为update操作。后面一个操作将insert操作转换为update操作。
对于,码哥而言,我会选择直接不处理,当然,告警日志还是需要来一条。
update操作
update 操作就比较复杂了,需要考虑多种情况。
- 情况 1
增量同步在执行 update 操作时,数据迁移程序已经将数据迁移到新库中去了,那么直接执行 update 操作就可以了,没有问题。
- 情况 2
增量同步在执行 update 操作时,数据迁移程序还没有将数据迁移到新库中去,这个时候增量同步操作执行 update 操作时会执行失败。我们知道,update 操作会返回一个结果值,表示更新的记录条数,如果为 0 则表示一条数据都没有更新成功,我们可以利用这个返回值来处理。如果返回值为 0 ,我们就将这个操作加入到消息队列中,利用消息队列的延迟队列来做处理。当延时到了后,再来执行,如果还是 0 则继续加入,等待数据迁移程序就数据迁入至新库。
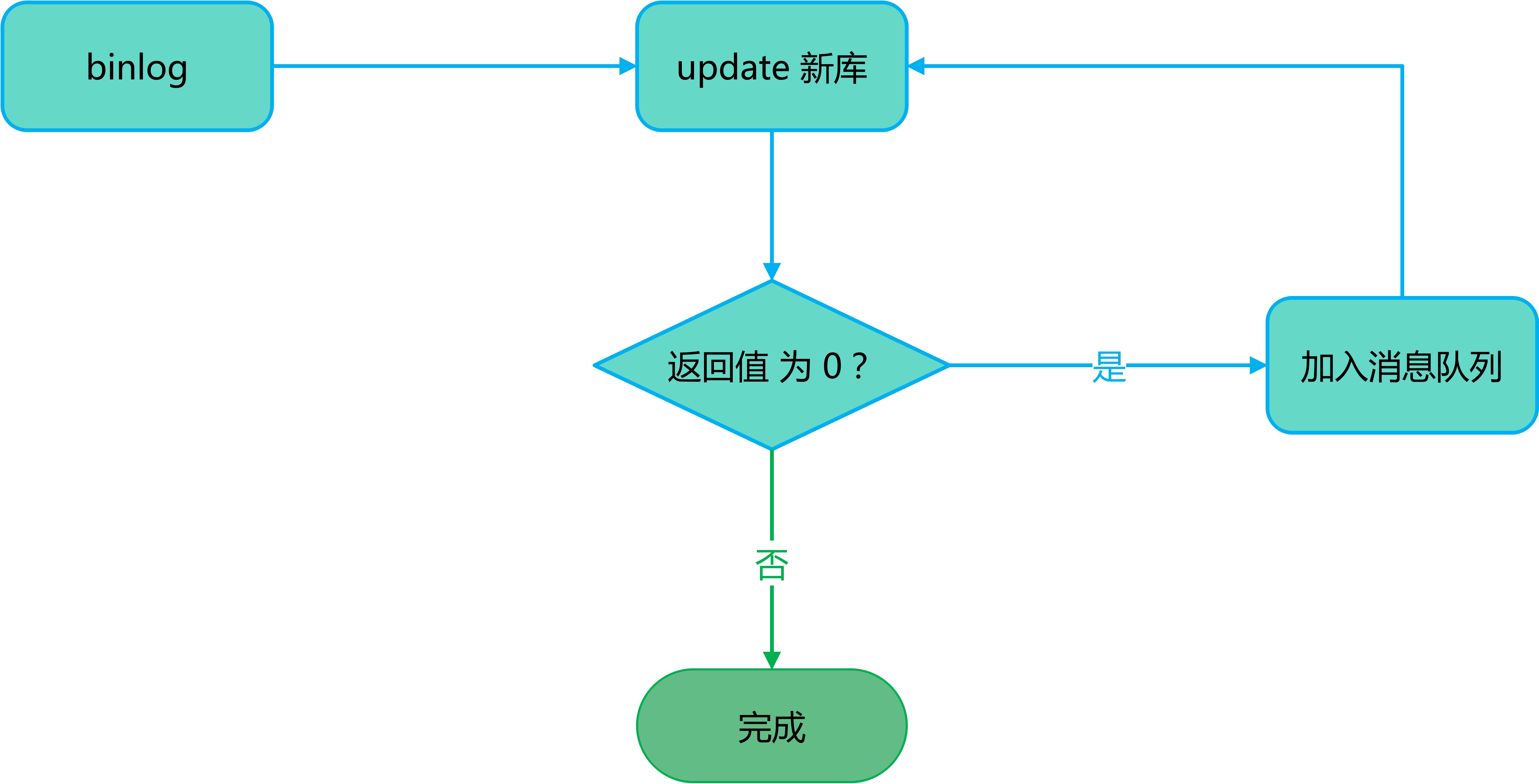
- **情况 3 **
还有一种比较复杂的情况。假如,针对同一条记录,先后有两条 update 语句,前面一条为 update_1、后面一条为 update_2。假如在执行 update_1 时,新库中没有这条记录,则 update_1 加入消息队列中。这时,数据迁移程序将数据同步过来了,update_2 执行成功,这个时候如果 update_1 操作再次执行,则将 update_2 的新数据给覆盖掉,那怎么做呢?
采用版本号(可以是版本号,也可以是时间戳),在处理 update 操作时,我们可以先检查新库中的版本号,如果当前版本比操作中的版本号新,则跳过这个操作。
那又有小伙伴问,那如果 update_1 和 update_2 是操作不同的字段呢?你跳过不就错了吗?其实是没有关系的,因为在同步过程中,新库是不会有流量过来的,在我们迁移数据完成,我们还需要进行两边数据对比和纠正,如果发现新老数据不一致的情况,则一切以老数据为准。而且,这么复杂的情况,原本发生的概率就会很小,但是我们修复这个情况的代价会比较高,同时越复杂的方案越容易出错,所以,针对这种情况,码哥的建议是,不处理,交给后面的数据对比和纠正来处理,保证最终一致性即可。
delete操作
相比 update 操作,delete 的操作就比较简单,直接按照 update 操作的情况1 和 情况 2 处理即可。
数据校验
在全量同步开始时,我们需要记录一个全量同步的终止值,这个值作为全量同步的终止点,到了这个点,全量同步就可以停止了。
当全量同步停止后,我们就需要开启数据校验了,数据校验分为抽样对和全量对,这里码哥推荐全量对,毕竟我们还是需要保证新老数据的一致性。
通过数据校验,我们就可以找到新老数据库的差异了,找到差异就开始修正,修正完成后继续校验,一般这个过程需要持续几轮,以确保数据的完全一致。
当数据完全一致后,我们就可以给启动新库的应用程序了,并循循渐进来下线旧应用。


















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









