




作者简介:大家好,我是码炫码哥,前中兴通讯、美团架构师,现任某互联网公司CTO,兼职码炫课堂主讲源码系列专题
代表作:《jdk源码&多线程&高并发》,《深入tomcat源码解析》,《深入netty源码解析》,《深入dubbo源码解析》,《深入springboot源码解析》,《深入spring源码解析》,《深入redis源码解析》等
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬。码炫课堂的个人空间-码炫码哥个人主页-面试,源码等
回答
在分库分表中,我们大概率都会选择表的 id 来作为拆分的键,例如我们有一张 tb_user 表,它有四个字段 :id、name、phone、address,我们利用 tb_user 的 id 作为拆分 id。在大多数的场景下,我们都是利用 id 来查询 tb_user 表中的数据,这种情况是没有问题的。但是,有些场景我们需要根据其他不是拆分键的 id 来查询,例如查询 name = '张三',如下:
select * from tb_user where name = '张三'
由于 name 不是拆分键,所以我们无法定位到具体的某张表上去执行这条语句,于是就会对所有的 tb_user 表都执行一次:
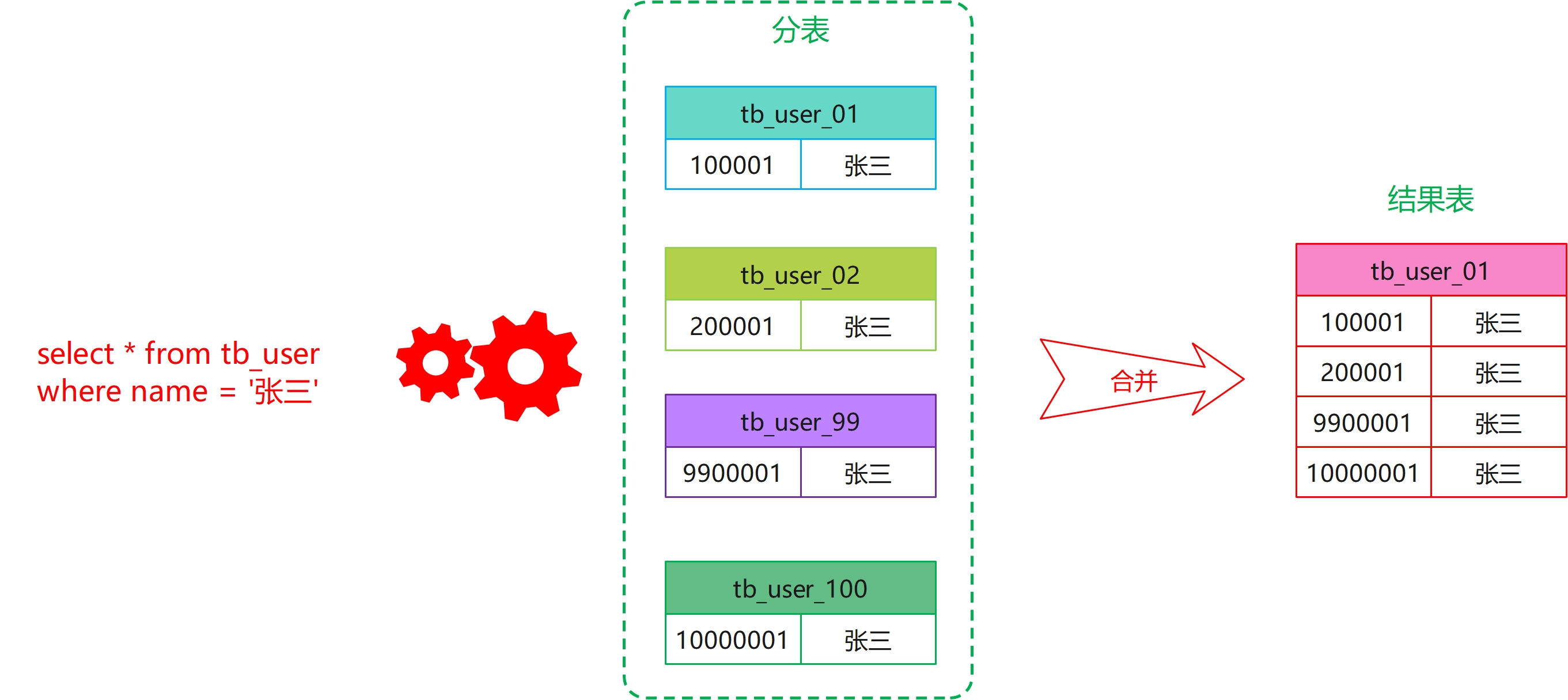
对于这种情况,如果有 100 张表,就要查询 100 次,当然你可以使用 union 操作合并查询,但还是避免不了要查询100 张表。
所以,针对这种随着表越来越多,查询的表就会越来越多,这就说所谓的读扩散。
那怎么解决这种情况呢?目前主流的方案有三种:
- 建索引表
- 引入 ES
- 使用分布式数据库 tidb
建索引表
产生读扩散的根本原因就在于我们无法通过 name 字段来确定到具体的表,所以我们只需要新建一张 name 和 id 的映射表就可以了,这样当我们要通过 name 字段来查询,先到这个索引表里面去找对应的 id,然后再根据 id 去对应的分表找对应的数据:
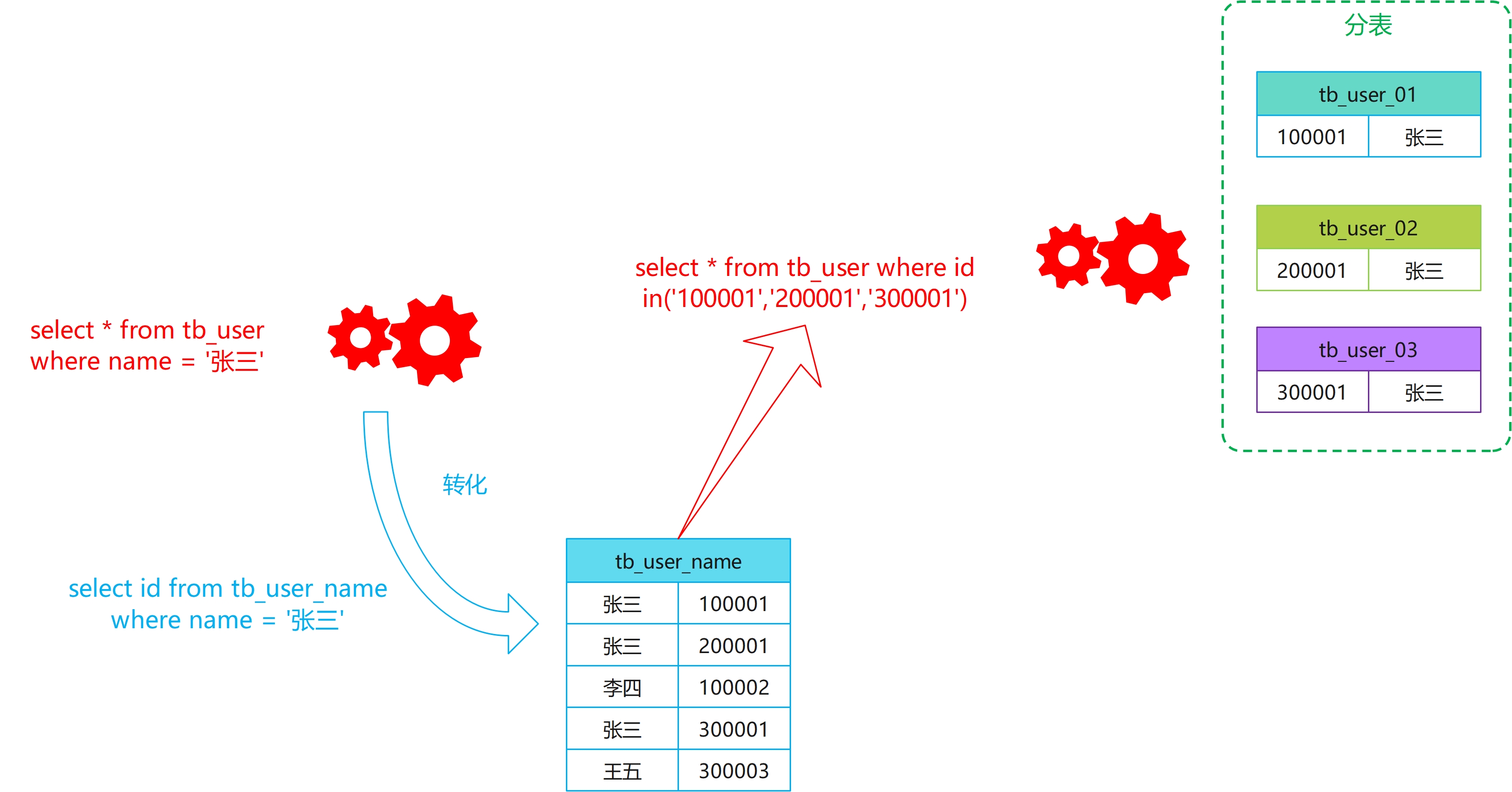
这种方式虽然能解决问题,但是它的缺点非常明显:你需要维护两套表,有任何对 name 字段更新的场景,都需要维护两套表。而且这还是只有一个字段,如果有多个字段呢,就需要维护更多的映射表。而且开发工作量也比较大,所以这种方案,码哥一般都不推荐使用。
引入 ES
建立索引表的思路和倒排索引的思路非常相似,所以对于这种需求,我们直接利用 ES 就可以了。ES 天然支持分片,内部利用倒排索引的形式来加速数据查询。比如上面的需求:
在 ES 中,它内部会以 id 分片键来进行分片,同时还会建立一个 name 到 id 的倒排索引,如果我们想以 phone 来查询,ES 同样会建立 phone 到 id 的倒排索引。利用 ES,我们无需自己维护 name --> id 和 phone --> id 之间的关系。
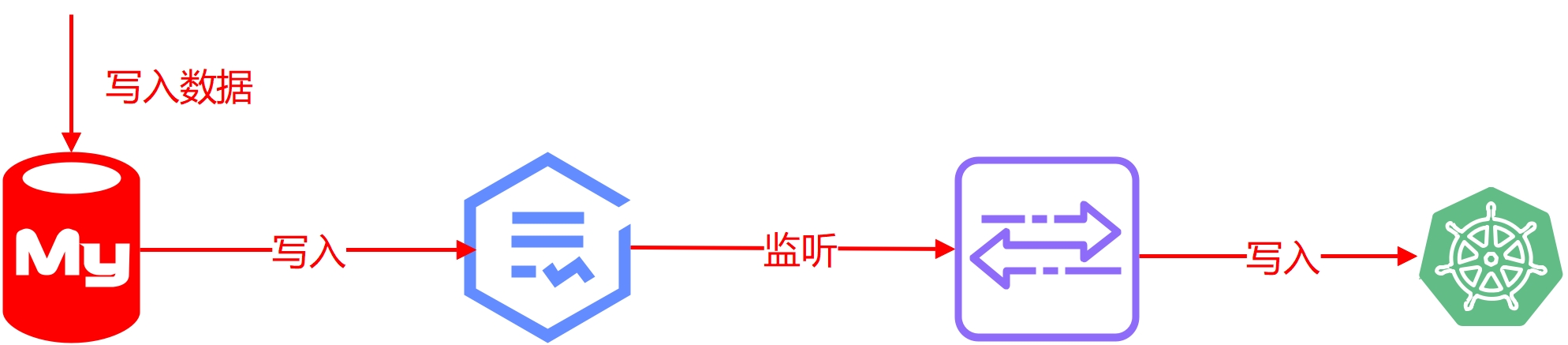
同样,引入 ES 也非常简单,利用开源工具 canal 监听 mysql 的 binlog 日志变更,再将数据解析后写入 ES,我们查询的时候直接查询 ES 就可以了。
使用分布式数据库
我们可以不适用分库分表的架构,直接使用 TiDB 替换。
TiDB 是一个分布式关系型数据库,它兼容 MySQL 协议和 MySQL 5.7 语法,在绝大多数应用下,我们是可以不需要做任何修改能够实现 MySQL 无缝切换到 TiDB 的。
理论上,TiDB 的单表支持十亿级别的数据量是毫无压力的,码哥曾经有个项目,有个表有将近 12 亿的数据量,使用 tidb 查询也没有什么压力。


















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









