




 本文概述了数据网格方法,基于四原则(数据所有权、数据作为产品、基础设施平台和联邦治理),强调了从传统数据湖向分布式架构的转变,以应对数据多样化和快速响应需求。文章旨在引导理解体系结构和组织变革,而非详述具体实施细节。
本文概述了数据网格方法,基于四原则(数据所有权、数据作为产品、基础设施平台和联邦治理),强调了从传统数据湖向分布式架构的转变,以应对数据多样化和快速响应需求。文章旨在引导理解体系结构和组织变革,而非详述具体实施细节。
https://martinfowler.com/articles/data-mesh-principles.html
Our aspiration to augment and improve every aspect of business and life with data, demands a paradigm shift in how we manage data at scale. While the technology advances of the past decade have addressed the scale of volume of data and data processing compute, they have failed to address scale in other dimensions: changes in the data landscape, proliferation of sources of data, diversity of data use cases and users, and speed of response to change. Data mesh addresses these dimensions, founded in four principles: domain-oriented decentralized data ownership and architecture, data as a product, self-serve data infrastructure as a platform, and federated computational governance. Each principle drives a new logical view of the technical architecture and organizational structure.
我们希望通过数据来增强和改善业务和生活的各个方面,这要求我们在大规模管理数据的方式上进行范式转变。虽然过去十年的技术进步解决了数据量和数据处理计算的规模,但它们未能解决其他方面的规模:数据格局的变化、数据源的激增、数据用例和用户的多样性以及对变化的响应速度。数据网格解决了这些维度,建立在四个原则基础上:面向领域的分散数据所有权和体系结构、数据作为产品、自助数据基础架构作为平台以及联合计算治理。每项原则都推动了技术架构和组织结构的新逻辑视图。
The original writeup, How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh - which I encourage you to read before joining me back here - empathized with today’s pain points of architectural and organizational challenges in order to become data-driven, use data to compete, or use data at scale to drive value. It offered an alternative perspective which since has captured many organizations’ attention, and given hope for a different future. While the original writeup describes the approach, it leaves many details of the design and implementation to one’s imagination. I have no intention of being too prescriptive in this article, and kill the imagination and creativity around data mesh implementation. However I think it’s only responsible to clarify the architectural aspects of data mesh as a stepping stone to move the paradigm forward.
This article is written with the intention of a follow up. It summarizes the data mesh approach by enumerating its underpinning principles, and the high level logical architecture that the principles drive. Establishing the high level logical model is a necessary foundation before I dive into detailed architecture of data mesh core components in future articles. Hence, if you are in search of a prescription around exact tools and recipes for data mesh, this article may disappoint you. If you are seeking a simple and technology-agnostic model that establishes a common language, come along.
最初的文章《如何超越整体数据湖迁移到分布式数据网格》-我鼓励您在回到这里之前阅读它--同情当今的体系结构和组织挑战的痛点,以便成为数据驱动的,使用数据竞争,或使用规模数据驱动价值。它提供了另一种观点,此后引起了许多组织的注意,并给人们带来了对不同未来的希望。虽然最初的文章描述了这种方法,但它将设计和实现的许多细节留给了人们的想象。我无意在本文中过于规定,并扼杀围绕数据网格实现的想象力和创造力。然而,我认为,澄清数据网格的体系结构方面是推动范式向前发展的垫脚石。
这篇文章是为了后续行动而写的。它通过列举数据网格方法的基础原则以及这些原则驱动的高级逻辑体系结构来总结数据网格方法。在我在未来的文章中深入探讨数据网格核心组件的详细体系结构之前,建立高级逻辑模型是必要的基础。因此,如果您正在寻找关于数据网格的确切工具和食谱的处方,本文可能会让您失望。如果您正在寻找一个简单且与技术无关的模型,以建立一种共同语言,请一起来。
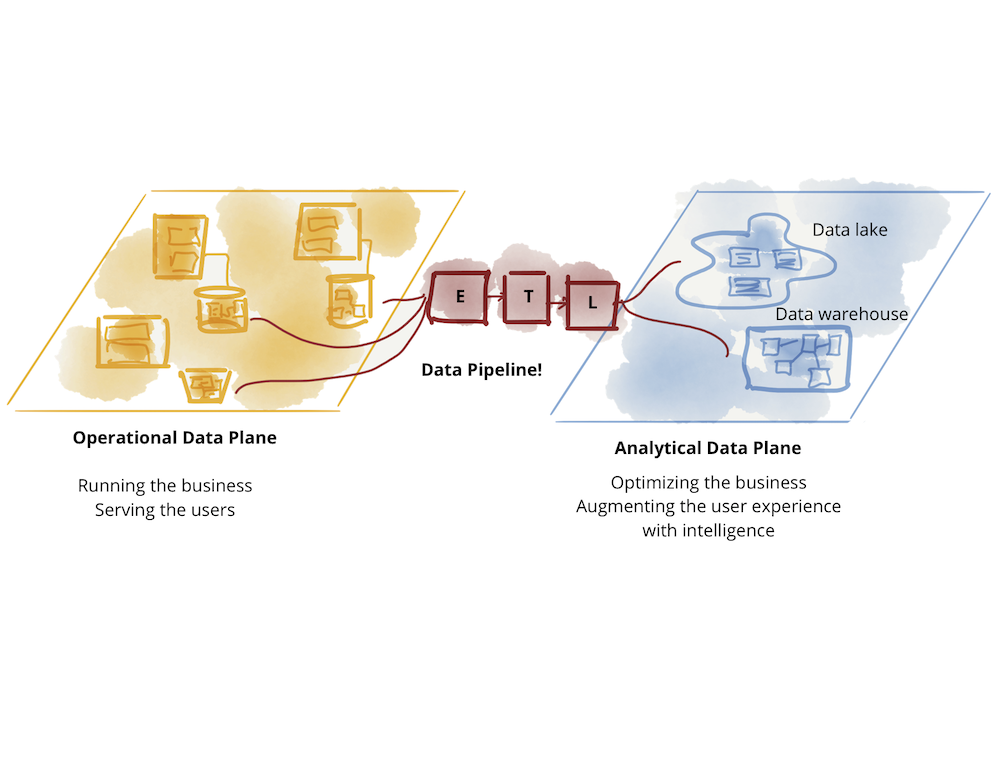
The great divide of data
What do we really mean by data? The answer depends on whom you ask. Today’s landscape is divided into operational data and analytical data. Operational data sits in databases behind business capabilities served with microservices, has a transactional nature, keeps the current state and serves the needs of the applications running the business. Analytical data is a temporal and aggregated view of the facts of the business over time, often modeled to provide retrospective or future-perspective insights; it trains the ML models or feeds the analytical reports.
The current state of technology, architecture and organization design is reflective of the divergence of these two data planes - two levels of existence, integrated yet separate. This divergence has led to a fragile architecture. Continuously failing ETL (Extract, Transform, Load) jobs and ever growing complexity of labyrinth of data pipelines, is a familiar sight to many who attempt to connect these two planes, flowing data from operational data plane to the analytical plane, and back to the operational plane.
https://martinfowler.com/articles/data-mesh-principles/data-planes.png
Figure 1: The great divide of data
我们说的数据到底是什么意思?答案取决于你问的是谁。今天的情况分为业务数据和分析数据。运营数据位于与微服务一起服务的业务功能后面的数据库中,具有事务性,保持当前状态,并满足运行业务的应用程序的需求。分析数据是业务事实随时间推移的时间和聚合视图,通常建模以提供回顾性或未来视角的见解;它训练ML模型或提供分析报告。
技术、体系结构和组织设计的当前状态反映了这两个数据平面的分歧--两个存在级别,集成但独立。这种分歧导致了一个脆弱的建筑。ETL(提取、转换、加载)作业不断失败,数据管道迷宫的复杂性不断增加,对于许多试图连接这两个平面、将数据从操作数据平面流动到分析平面,然后返回操作平面的人来说,是一个熟悉的景象。

















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}