




 探讨使用深度学习解决街景图像中门牌号识别问题,介绍数据集特性,采用定长字符识别模型与检测+预测策略,实现模型训练、验证及集成,最终提升识别准确率。
探讨使用深度学习解决街景图像中门牌号识别问题,介绍数据集特性,采用定长字符识别模型与检测+预测策略,实现模型训练、验证及集成,最终提升识别准确率。
1 赛题理解
1.1 题目内容
识别街景图像中的门牌号。
1.2 数据集
数据集来自Google街景图像中的门牌号数据集(The Street View House Numbers Dataset, SVHN),并根据一定方式采样得到比赛数据集。其中训练集30000张图片,检验集10000张图片,测试集A和B各40000张图片。图片大小不一,为三色RGB图片。标记信息为图片中各个数字的位置框和数字信息。
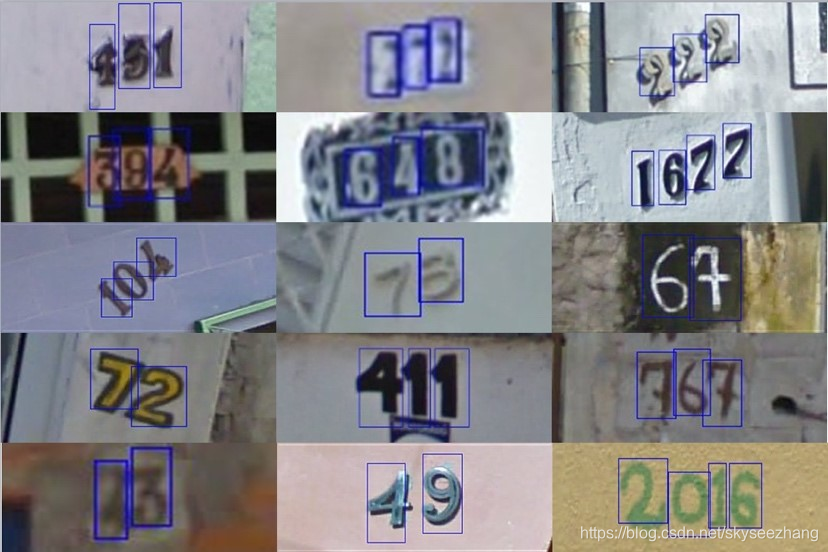
1.3 解题思路:
方法一:将问题看作定长字符串的分类问题,使用深度神经网络直接预测各个数字。
方法二:先对字符进行检测,再进行分类。
2 数据读取与数据扩增
2.1 数据读取
赛题举办方提供的数据包括由30000张图片组成的训练集,10000张图片组成的检验集和40000张图片组成的测试集A,图片格式为png格式。数据标签为json格式。
数据读取方式:torch.utils.data.DataLoader, PIL.Image, glob, json库的使用
# 数据标签的 json格式读取,转化为字典格式
import json
train_json = json.load(open('mchar_train.json'))
# 读取训练图片的路径信息
import glob
train_path = glob.glob('./input/mchar_train/*.png')
train_path.sort()
# 数据读取
class SVHNDataset(Dataset):
def __init__(self, img_path, img_label, transform=None):
self.img_path = img_path
self.img_label = img_label
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
img = Image.open(self.img_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
# 设置最⻓长的字符⻓长度为4个
lbl = np.array(self.img_label[index], dtype=np.int)
lbl = list(lbl) + (4 - len(lbl)) * [10]
return img, torch.from_numpy(np.array(lbl[:4]))
def __len__(self):
return len(self.img_path)
# 这里暂时不使用标签中的图片位置信息,只使用类别信息
train_label = [train_json[x]['label'] for x in train_json]
# 数据扩充
import torchvision.transforms as transforms
# torch中的数据读取方式,利用torch.utils.data.DataLoader 来实现
# transforms 为数据扩充方法
train_loader = torch.utils.data.DataLoader(
SVHNDataset(train_path, train_label,
transforms.Compose([、
# 缩放到固定尺度
transforms.Resize((64, 128)),
# 随机裁剪
transforms.RandomCrop((60, 120)),
# 颜色变换
transforms.ColorJitter(0.3, 0.3, 0.2),
# 随机旋转
transforms.RandomRotation(5),
# 转化为pytorch的tensor
transforms.ToTensor(),
# 图片像素归一化
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])),
batch_size=40,
shuffle=True,
num_workers=0,
)
2.2 数据扩充方法
对于图片的数据扩充方法,有尺度变化、随机裁剪、中心裁剪、随机旋转、水平翻转、垂直翻转、颜色对比度变换等。对于数字识别而言,由于数字6和数字9的相似性,不可以使用随机翻转的方法。在上述代码中,使用了随机裁剪、颜色变换、随机旋转这三种数据扩充方法。
3 字符识别模型
3.1 尝试一:定长字符识别模型
对于数据集中的图片,大多数图片的标签数字数量小于5。训练集中的数字标签数字数量统计结果如下:
含有1个数字:4636, 占比15.45%;
含有2个数字:16262, 占比54.21%;
含有3个数字:7813, 占比26.04%;
含有4个数字:1280, 占比4.27%;
含有5个数字:8, 占比0.03%;
含有6个数字,1, 占比0.00%。
对于定长字符识别模型而言,其做法是设定字符长度,将不定长的字符补全(在10个数字类别之外,补充背景类别)。由于绝大多数图片的字符数量小于5, 因此设定定长字符的长度为4。
同时,模型使用了ResNet预训练模型。在ResNet模型的最后一层,并联接上4个子分支,每个分支由两个全连接层组成,分别预测对应位置的数字。
在使用不同ResNet主干网络的情况下,模型取得了不同的预测效果。在使用相同数据增强方法的情况下,使用ResNet18预训练模型,最终得分为0.52;ResNet52 得分为 0.63; ResNet101得分为0.69。在模型训练的过程中出现了过拟合的现象,训练集的误差不断减小,而检验集上的误差最后却保持在一定范围。为了缓解这样的问题,使用额外的数据增强方法对训练集的数据进行了扩增。包括高斯模糊和加入随机噪声等。最后在使用ResNet101主干网络的情况下,模型得分达到了0.73。
3.2 尝试二:两个定长字符识别模型的组合
在使用定长字符模型时,模型最后的4个子分支分别预测不同位置的数字。但是由于不同位置数字出现频率并不相同,比如所有图片都存在第1位数字,因此预测第1位数字的子分支应该可以取得比较准确的预测结果;而对于预测第4位数字的子分支,由于95.7%的标签标记为背景,其预测的效果可能是有问题的。在这样的分析下,从预测效率上来看,可能出现的情况是:子分支1>子分支2>子分支3>子分支4。
因此,一个比较自然的想法是:训练两个模型,其中一个模型从左往右预测数字,另一个模型从右往左预测数字,最后再综合两个模型的预测结果,确定最后的结果。
初步的实验表明:该方法似乎不起效果。。
3.3 尝试三:使用检测+预测的思路
由于数据标签同时包含类别和位置信息,因此可以使用检测+预测的思路来做。同样包括两种方法,第一种方法是同时做检测和类别预测;第二种方法是先做检测,将数字框识别出来,再对图像做裁剪进行分类预测。目前尝试使用了yolov3和yolov4模型来进行预测。初步的实验结果显示模型预测效果极差,基本不具有预测功能。。。
3.4 其它方法
其它方法还包括不定长字符识别方法,其中典型的代表是CTPN;以及两阶段的检测模型,比如Faster RCNN。之后计划将这两个模型都实现一遍。
4 模型训练与验证
定义型的训练函数和验证函数,设置相应的参数,进行训练。其中训练函数train()包含梯度反向传播和参数更新。
def train(train_loader, model, criterion, optimizer):
# 切换模型为训练模式
model.train()
train_loss = []
T0 = time.time()
for i, (input, target) in enumerate(train_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0, c1, c2, c3 = model(input)
target = target.long()
loss = criterion(c0, target[:, 0]) + \
criterion(c1, target[:, 1]) + \
criterion(c2, target[:, 2]) + \
criterion(c3, target[:, 3])
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
TT = time.time()
print(loss.item(), TT-T0)
T0 = time.time()
train_loss.append(loss.item())
return np.mean(train_loss)
def validate(val_loader, model, criterion):
# 切换模型为预测模型
model.eval()
val_loss = []
# 不不记录模型梯度信息
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0, c1, c2, c3 = model(input)
target = target.long()
loss = criterion(c0, target[:, 0]) + \
criterion(c1, target[:, 1]) + \
criterion(c2, target[:, 2]) + \
criterion(c3, target[:, 3])
val_loss.append(loss.item())
return np.mean(val_loss)
模型训练和验证。将验证结果最好的模型加以保存。
model = SVHN_Model1()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), 0.001)
best_loss = 1000.0
use_cuda = True
if use_cuda:
model = model.cuda()
for epoch in range(5):
train_loss = train(train_loader, model, criterion, optimizer)
val_loss = validate(val_loader, model, criterion)
val_label = [''.join(map(str, x)) for x in val_loader.dataset.img_label]
val_predict_label = predict(val_loader, model, 1)
val_predict_label = np.vstack([
val_predict_label[:, :11].argmax(1),
val_predict_label[:, 11:22].argmax(1),
val_predict_label[:, 22:33].argmax(1),
val_predict_label[:, 33:44].argmax(1),
]).T
val_label_pred = []
for x in val_predict_label:
val_label_pred.append(''.join(map(str, x[x!=10])))
val_char_acc = np.mean(np.array(val_label_pred) == np.array(val_label))
print('Epoch: {0}, Train loss: {1} \t Val loss: {2}'.format(epoch, train_loss, val_loss))
print(val_char_acc)
# 记录下验证集精度
if val_loss < best_loss:
best_loss = val_loss
torch.save(model.state_dict(), './model.pt')
5 模型集成
对于模型集成,使用了两种方法。第一种方法是在训练过程中保留了两个“最优模型”,分别对应于检验集损失最少和准确率最高两种情形,最后将两个“最优模型”集成,进行预测。
# 记录下验证集精度
if val_loss < best_loss:
best_loss = val_loss
torch.save(model.state_dict(), './weights/model.pt')
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), './weights/model_acc.pt')
第二种方法在预测的时候,通过transforms.RandomCrop方法,预测10次,将10次预测结果进行集成。
def predict2(test_loader, model1, model2, tta=10):
model1.eval()
model2.eval()
test_pred_tta = True
# TTA 次数
for _ in range(tta):
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
if use_cuda:
input = input.cuda()
c0, c1, c2, c3 = model1(input)
output = np.concatenate([
c0.data.cpu().numpy(),
c1.data.cpu().numpy(),
c2.data.cpu().numpy(),
c3.data.cpu().numpy()], axis=1)
c0, c1, c2, c3 = model1(input)
output2 = np.concatenate([
c0.data.cpu().numpy(),
c1.data.cpu().numpy(),
c2.data.cpu().numpy(),
c3.data.cpu().numpy()], axis=1)
test_pred.append(output+output2)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
最后,在通过设置动态学习率,补充额外的数据增强方法和进行模型集成之后,预测得分达到了0.84。

















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









