




文章目录
count(*) 执行逻辑
innodb 统计时需要去数据库里一条一条扫描,MyISAM把总行数存在磁盘上,使用时直接返回。innodb需要扫描原因:innodb有mvcc多版本,需要知道在这个时刻、那个时刻一致性视图下的总行数,需要实时计算。
优化:行数统计,在非空索引上都行,所以找到最小的非空索引统计行数。
show table status中的行数时采样统计得到的,不准不能用
解决方案:自己计算存起来, 存redis需要分布式事务失败回滚机制保证数据的一致性;存在innodb引擎的文件上,利用事务特性维持唯一性
count(*)、count(1)、count(主键ID)对比
count(*)的优化:扫描表不取值,因为行肯定不为空
count(1): 扫描表不取值
count(主键ID):扫描表取主键ID,server层判断不为空,按行累加
性能:count(*) ≈ count(1) > count(主键ID)
order by执行逻辑
sort buffer
sort buffer: mysql会给一个线程分配一块内存用于排序;sort buffer就像一个临时表
select city,name,age from t where city='杭州' order by name limit 1000;
注意:使用sort buffer是因为数据无序,如果我们有name有序的(name,age,id)二级索引就可以直接返回
sort buffer中能存下全字段
把全字段一条条拿到sort_buffer上(sort_buffer存的下),然后排序返回
 |
|---|
| 图片来自极客时间 丁奇 MySQL实战45讲 |
sort buffer存不下一行的宽度:row id排序
sort buffer存不下一行的宽度(大于max_length_for_sort_data):row id排序
把要排序字段和主键ID存入sort buffer,排序完成后回主键查数据返回
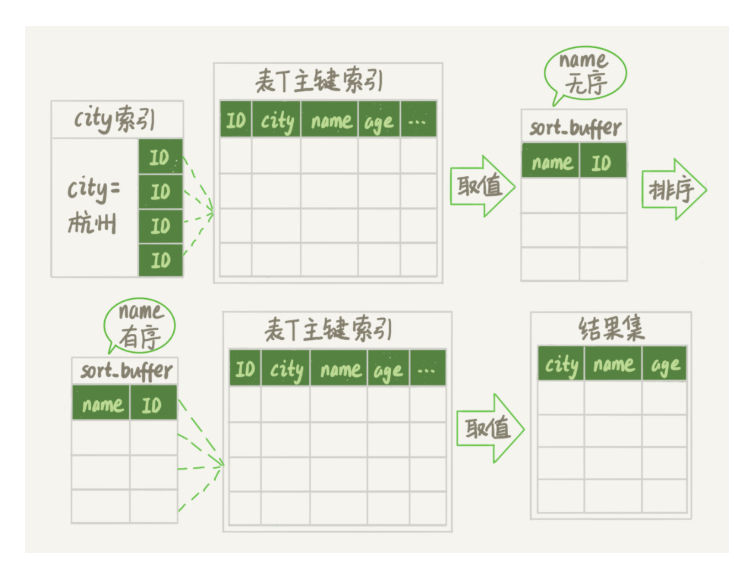 |
|---|
| 图片来自极客时间 丁奇 MySQL实战45讲 |
sort buffer大小不够
sort buffer大小(sort_buffer_size)不够,就需要存到磁盘上,存在多个文件中,多个文件分别完成排序后再进行归并排序
临时表
对于直接取值,无中间过程,返回结果集的不需要临时表;对于取值后,需要额外操作比如排序、计算等,可能需要临时表。
select word from words order by rand() limit 3;
内存临时表
内存临时表中存着每个word字段和对应的随机数。因为内存表取数据不涉及IO操作,很快;所以使用rowid排序。排序完成后取前三行,返回结果。
叫row id排序原因:我们建的内存临时表没有主键,innodb会提供默认自增主键rowid。
 |
|---|
| 图片来自极客时间 丁奇 MySQL实战45讲 |
磁盘临时表
如果临时表大于tmp_table_size,会存在磁盘上。
对于只需要几个返回值,不需要全量排序,innodb使用优先队列算法,扫描所有数据和堆上的数据对比,堆上只放最大的三个。
如果返回数量较大,就需要多个临时文件分别排序后,再归并排序返回。
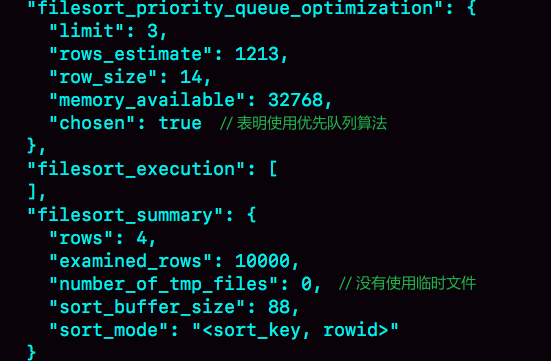 |
|---|
| 图片来自极客时间 丁奇 MySQL实战45讲 |
查找算法优化
上面直接找,需要全表扫描+排序(开销大)。
先简化问题,假设只取一个随机数:
方案一:找到主键ID的最大、最小值,从中rand()出来一个值,去取出来。
问题:主键ID不连续,可能有空洞。而且随机概率不平均,比如ID排布 1,2,3,8,9,4000,40001
方案二:count(*)取出总行数,在行数里rand()出一个数,用limit R,1 取出来
针对方案二,随机取三个字段就是:随机个最大、最小行数(N最小,M最小,R中间),取出limit N, M-N+1这些行,在里面拿出这三行数据
group by执行逻辑
group by跟order by走row id排序的执行逻辑一样:先建临时表存字段,再在sort_buffer排序,再回内存临时表里按序取出结果集
-
group by默认排序,如果没有排序要求,后面加order by null;
-
尽量能用上索引,就不需要临时表存中间数据了,索引有序可以直接根据扫描行数计算count
-
如果group by需要统计的数量不大,默认用的是内存临时表;尽量使用内存临时表,快,可以通过tmp_table_size调大临时表大小
-
如果确认统计数据很大,就直接指明SQL_BIG_RESULT,避免优化器先走内存临时表发现不够又转磁盘临时表
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
什么时候用内存临时表
临时表的特点:每个事务独立有的,会话结束时自动销毁,show tables访问不到;对于同名表和临时表,临时表优先级高于同名表;
- 如果没有中间过程需要内存,一边取数据就能一边直接得到结果,就不需要临时表
- join buffer是无需数组,sort_buffer是有序数据,临时表是二维表结构
- 需要二维表结构的时候用临时表,比如union出一个新表需要唯一索引,group by需要新一个字段存放累计计数

















 5184
5184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









