



1 awk -v # 设置变量

# 输出第二列包含 "th",并打印第二列与第四列
$ awk '$2 ~ /th/ {print $2,$4}' log.txt
---------------------------------------------
this a实例一:只查看test.txt文件(100行)内第20到第30行的内容(企业面试)
[root@Gin scripts]# awk '{if(NR>=20 && NR<=30) print $1}' test.txt
20
21
22
23
24
25
26
27
28
29
30
-F参数:指定分隔符,可指定一个或多个

统计行数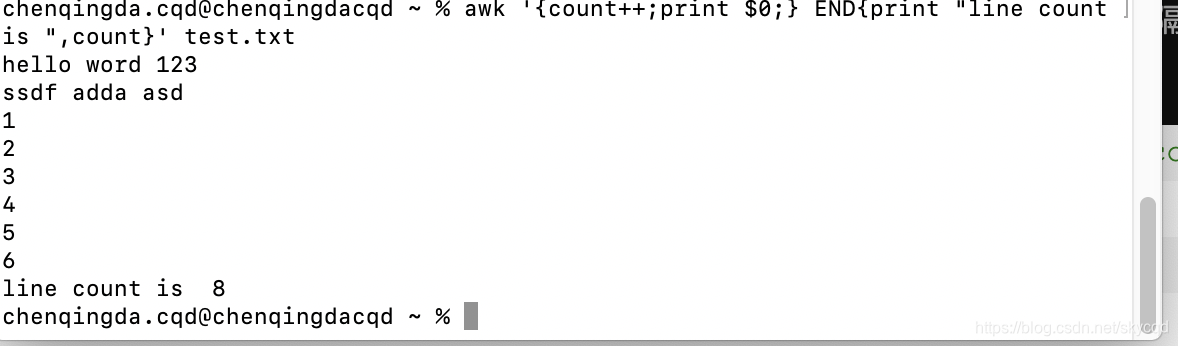
awk 赋值运算符:a+5;等价于: a=a+5;其他同类
| 1 2 |
|
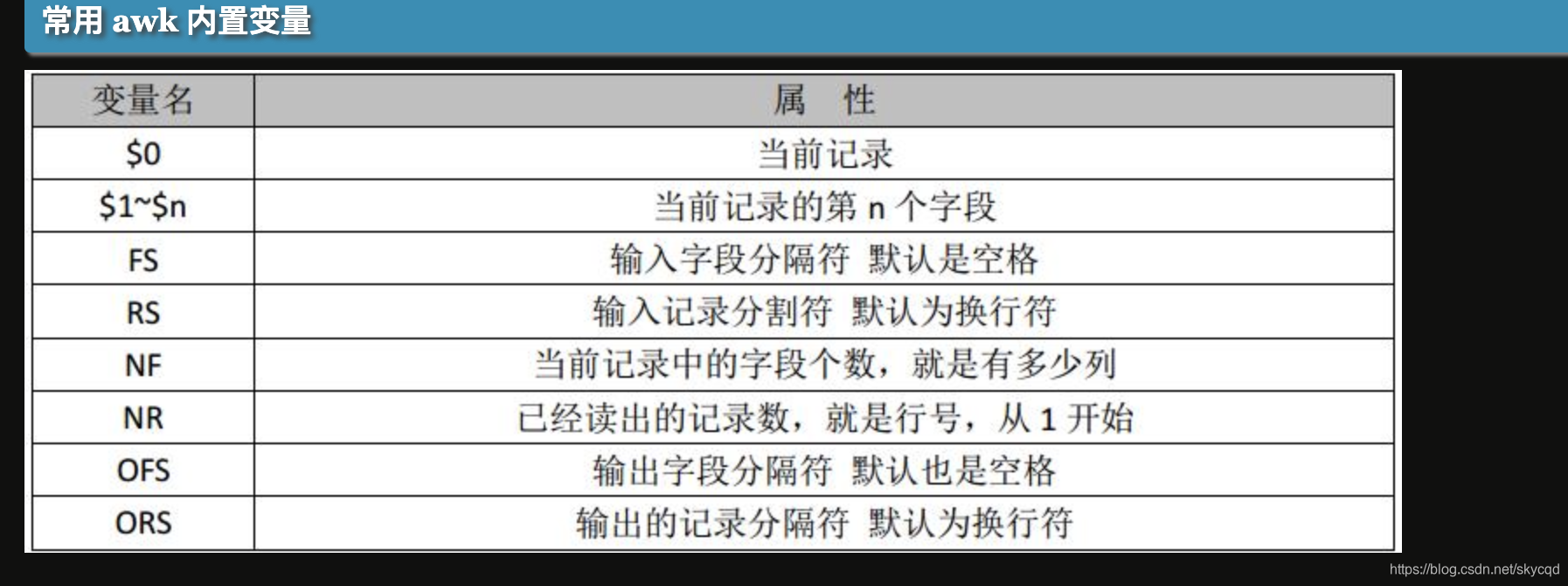
FS="[" ":]+" 以一个或多个空格或:分隔
| 1 2 3 4 |
|
leetcode
awk 'NR==10 {print $0}' file.txt
awk
'BEGIN{a[0]="";i=0}
{
for(i=1;i<=NF;++i)
{
if(NR>1)
{
a[i]=a[i]" "$i
}else
{
a[i]=a[i]$i
}
}
}
END
{
for(i=1;i<=NF;++i)
{
print a[i]
}
}' file.txtawk '/(^(\([0-9]{3}\) |([0-9]{3}-))[0-9]{3}-[0-9]{4}$)/ {print $0}' file.txt
cat words.txt |
awk '{
for(i=1;i<=NF;i++){
count[$i]++
}
} END {
for(k in count){
print k" "count[k]
}
}' |
sort -rnk 2
sort 命令

uniq命令
常用语报告或者消除文件中的重复内容,一般与sort命令结合使用。
命令选项
- -c:在每行开头显示重复行出现的次数;
- -d:仅显示重复的列;
- -f 栏位:忽略指定的栏;
- -s N:指定可以跳过前N个字符;
- -w 字符位数:指定用于比较的最大字符数;
- -u:仅显示出现一次的行列;

















 105
105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









