



目录
1.删除员工
1.1.1 需求
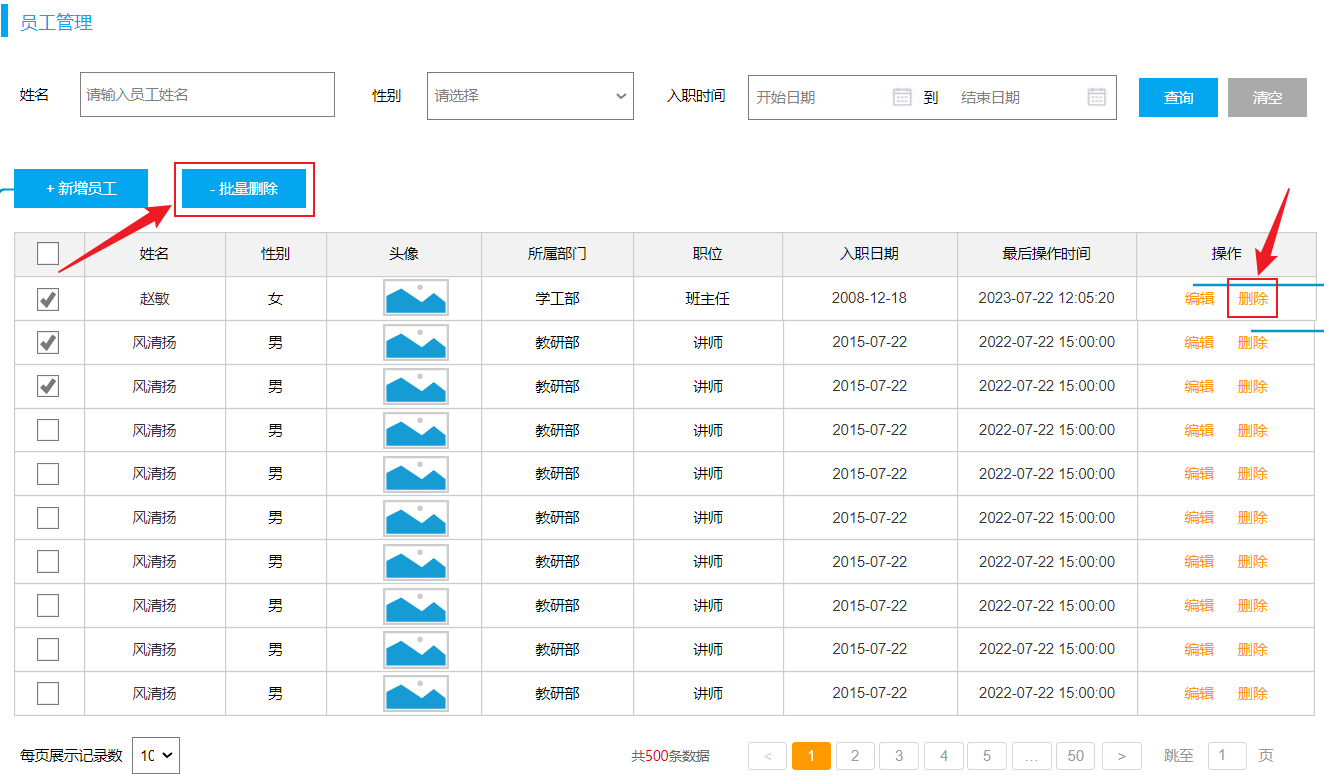
勾选复选框后,实现批量删除员工。
1.1.2 接口文档
删除员工
-
基本信息
请求路径:
/emps请求方式:
DELETE接口描述:该接口用于批量删除员工的数据信息
-
请求参数
参数格式:查询参数
参数说明:
参数名 类型 示例 是否必须 备注 ids 数组 array 1,2,3 必须 员工的id数组 请求参数样例:
/emps?ids=1,2,3- 响应数据
参数格式:application/json
参数说明:
| 参数名 | 类型 | 是否必须 | 备注 |
|---|---|---|---|
| code | number | 必须 | 响应码,1 代表成功,0 代表失败 |
| msg | string | 非必须 | 提示信息 |
| data | object | 非必须 | 返回的数据 |
响应数据样例:
{
"code":1,
"msg":"success",
"data":null
}1.1.3 思路分析
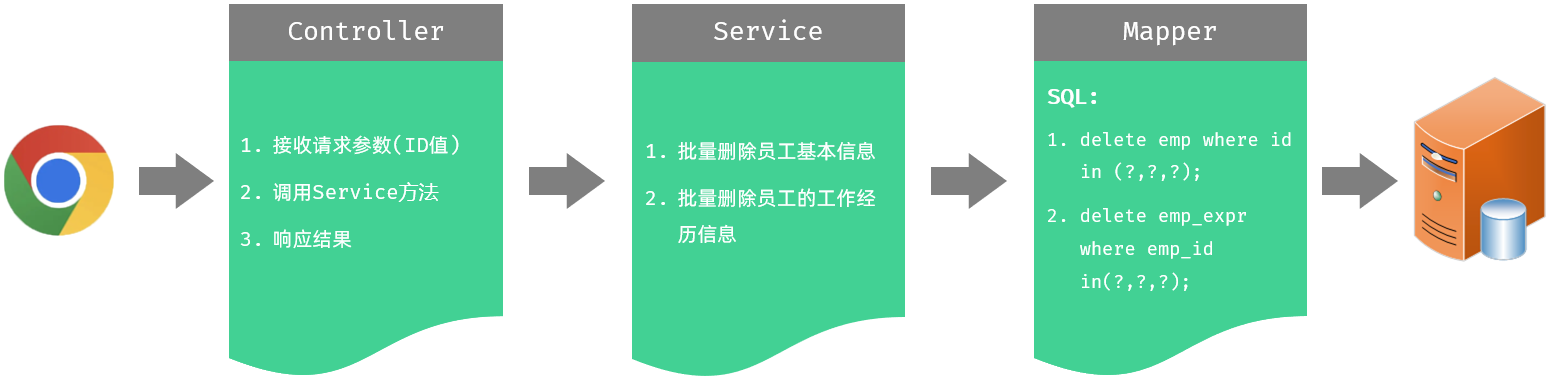
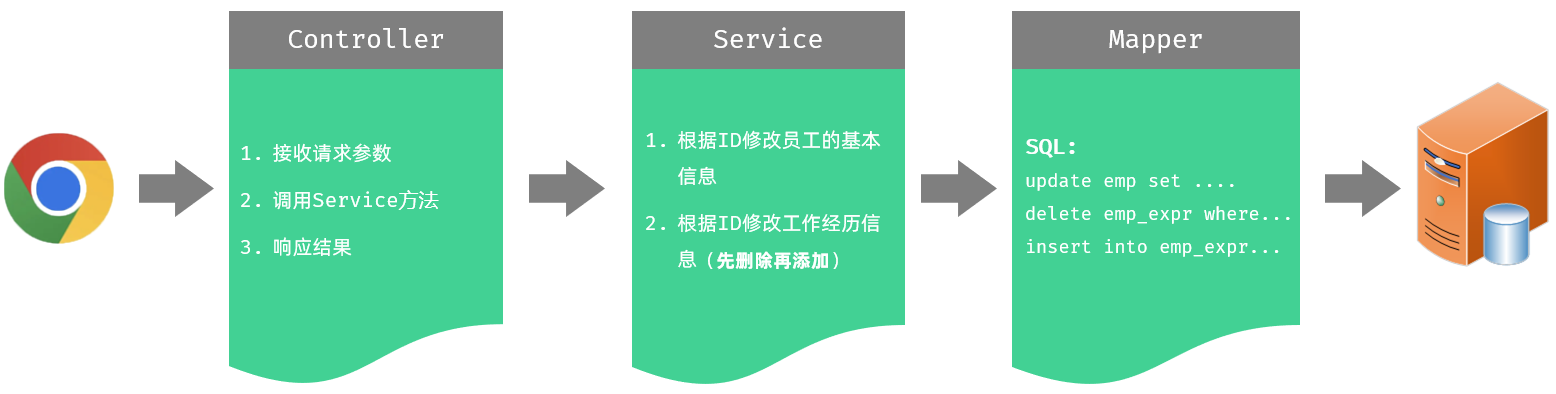
1.1.4 功能开发
1.1.4.1 Controller接收参数
在 EmpController 中增加如下方法 delete ,来执行批量删除员工的操作。
方式一:在Controller方法中通过数组来接收
多个参数,默认可以将其封装到一个数组中,需要保证前端传递的参数名 与 方法形参名称保持一致。
/**
* 批量删除员工
*/
@DeleteMapping
public Result delete(Integer[] ids){
log.info("批量删除部门: ids={} ", Arrays.asList(ids));
return Result.success();
}方式二:在Controller方法中通过集合来接收(推荐,因为集合操作元素会更加方便)
也可以将其封装到一个List<Integer> 集合中,如果要将其封装到一个集合中,需要在集合前面加上 @RequestParam 注解。
/**
* 批量删除员工
*/
@DeleteMapping
public Result delete(@RequestParam List<Integer> ids){
log.info("批量删除部门: ids={} ", ids);
empService.deleteByIds(ids);
return Result.success();
}1.1.4.2 Service
@Transactional //0.开启事务(涉及到多张表的删除)
@Override
public void delete(List<Integer> ids) {
//1.删除员工的基本信息数据 emp表
empMapper.deleteBatch(ids);
//2.删除员工的经历信息数据 emp_expr表
empExprMapper.deleteBatch(ids);
}一定要加开启事务注解@Transactional,由于删除员工信息,包含删除基本信息和工作经历两部分,操作多次的删除,为了保证数据的一致性,所以要进行事务控制。
1.1.4.3 Mapper
1)EmpMapper
//错误写法: @Delete("delete from emp where id in #{ids}")
// 必须基于xml书写动态SQL-foreach,因为参数是List集合类型
void deleteBatch(List<Integer> ids); <!--批量删除员工(1,2,3)-->
<delete id="deleteBatch">
delete from emp where id in
<foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</delete>代码解析如下:
-
<delete id="deleteBatch">:定义了一个删除操作,id="deleteBatch"表示这个操作的唯一标识,在 Java 代码中可以通过这个 id 来调用该删除操作。 -
delete from emp where id in:这是 SQL 语句的一部分,表示要删除emp表中满足id in条件的数据。 -
<foreach>标签:这是 MyBatis 提供的循环标签,用于遍历集合生成对应的 SQL 片段collection="ids":指定要遍历的集合名称为ids(在 Java 代码中传入的参数名)item="id":表示集合中每个元素的别名separator=",":指定元素之间的分隔符为逗号open="(" 和close=")":表示遍历生成的内容会用括号包裹
当传入的ids集合包含 1,2,3 时,这段代码会动态生成如下 SQL 语句:
delete from emp where id in (1, 2, 3)
这样就实现了根据多个 id 批量删除员工数据的功能,相比循环单条删除,这种方式更高效,减少了与数据库的交互次数。
2)EmpExprMapper
//基于xml开发-动态SQL--<foreach>--批量删除员工的经历
void deleteBatch(List<Integer> empIds);<!--批量删除员工经历-->
<delete id="deleteBatch">
delete from emp_expr where emp_id in
<foreach collection="empIds" item="empId" separator="," open="(" close=")">
#{empId}
</foreach>
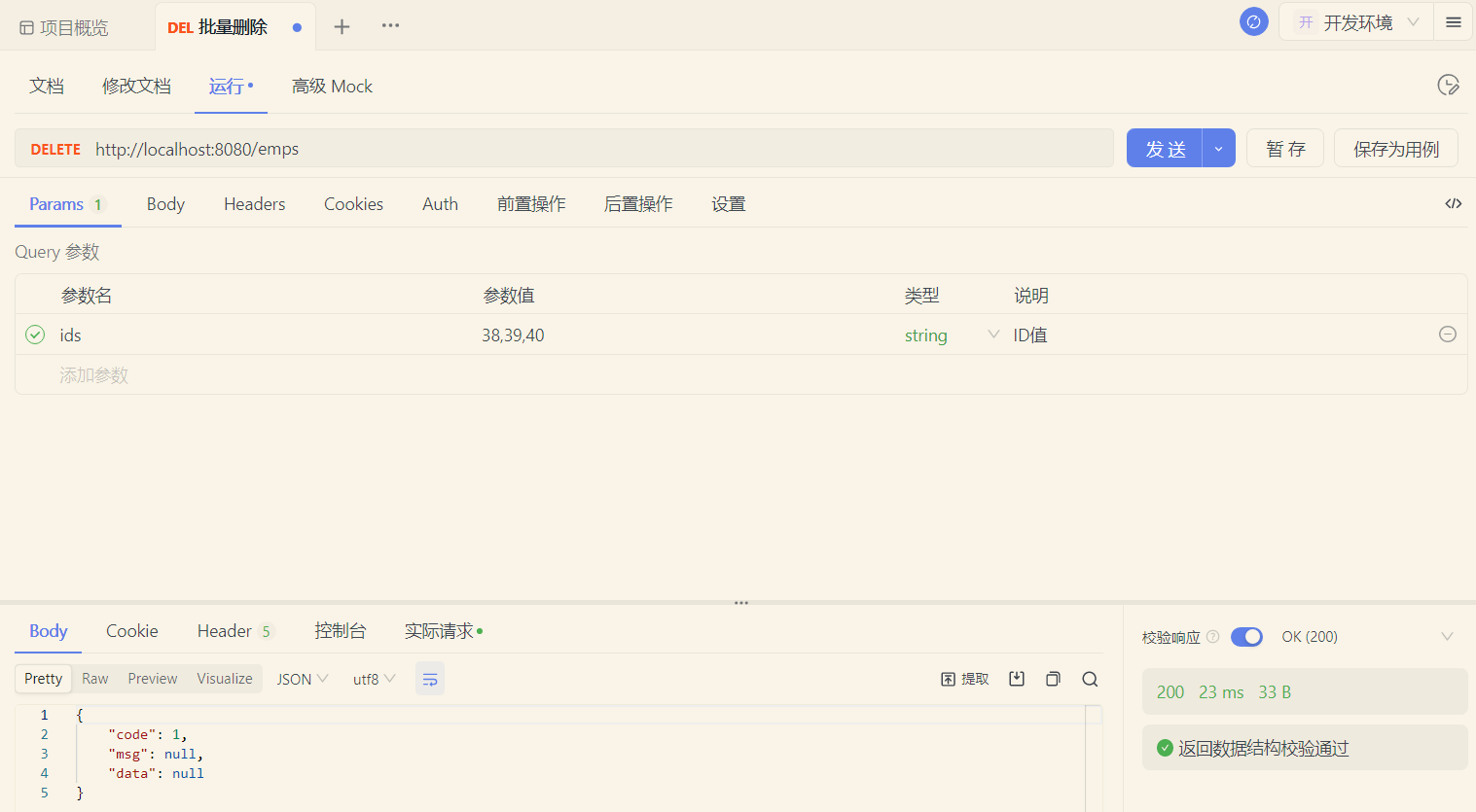
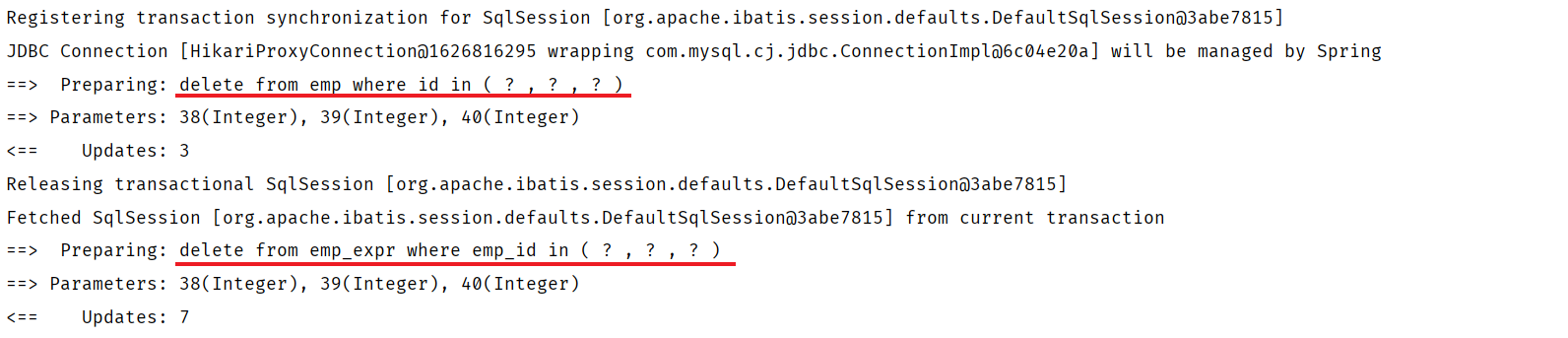
</delete>1.1.5 功能测试
1.1.6 前后端联调
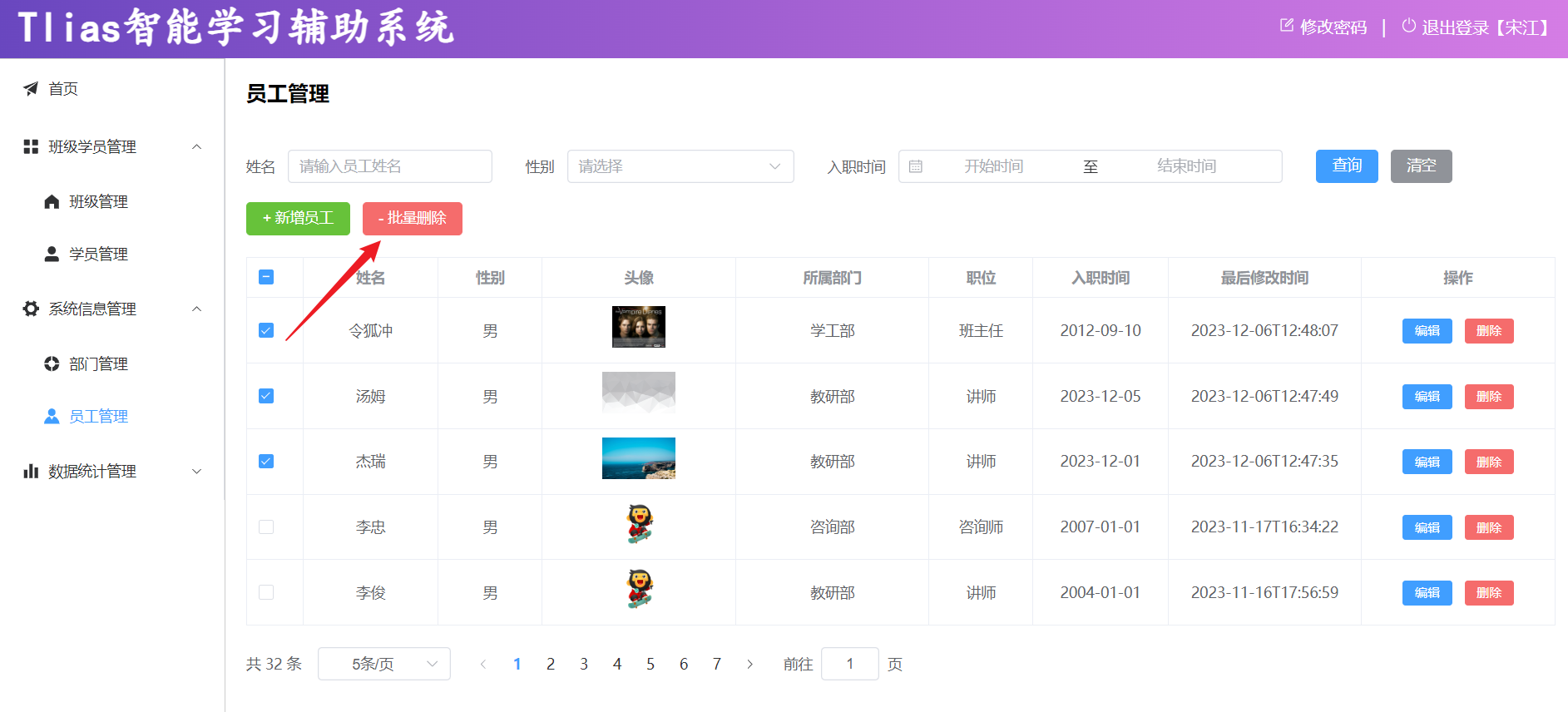
2.修改员工
需要:修改员工信息
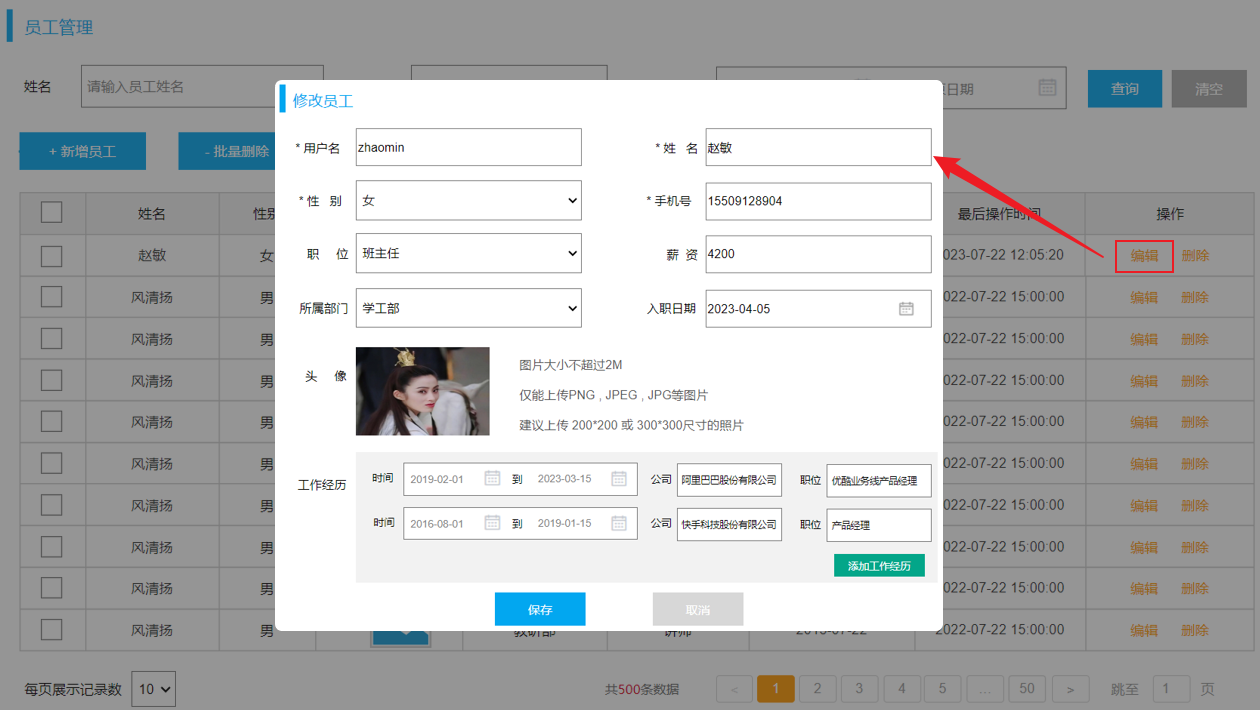
在进行修改员工信息的时候,我们首先先根据员工的ID查询员工的详细信息用于页面回显展示,然后用户修改员工数据之后,点击保存按钮,就可以将修改的数据提交到服务端,保存到数据库。具体操作为:
1.根据ID查询员工信息
2.保存修改的员工信息
2.1 查询回显
2.1.1 接口文档
根据ID查询员工数据
-
基本信息
请求路径:/emps/{id} 请求方式:GET 接口描述:该接口用于根据主键ID查询员工的信息 -
请求参数
参数格式:路径参数
参数说明:
参数名 类型 是否必须 备注 id number 必须 员工ID 请求参数样例:
/emps/1
-
响应数据
参数格式:application/json
参数说明:
名称 类型 是否必须 备注 code number 必须 响应码, 1 成功 , 0 失败 msg string 非必须 提示信息 data object 必须 返回的数据 |- id number 非必须 id |- username string 非必须 用户名 |- name string 非必须 姓名 |- password string 非必须 密码 |- entryDate string 非必须 入职日期 |- gender number 非必须 性别 , 1 男 ; 2 女 |- image string 非必须 图像 |- job number 非必须 职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师 |- salary number 非必须 薪资 |- deptId number 非必须 部门id |- createTime string 非必须 创建时间 |- updateTime string 非必须 更新时间 |- exprList object[] 非必须 工作经历列表 |- id number 非必须 ID |- company string 非必须 所在公司 |- job string 非必须 职位 |- begin string 非必须 开始时间 |- end string 非必须 结束时间 |- empId number 非必须 员工ID
{
"code": 1,
"msg": "success",
"data": {
"id": 2,
"username": "zhangwuji",
"password": "123456",
"name": "张无忌",
"gender": 1,
"image": "https://web-framework.oss-cn-hangzhou.aliyuncs.com/2022-09-02-00-27-53B.jpg",
"job": 2,
"salary": 8000,
"entryDate": "2015-01-01",
"deptId": 2,
"createTime": "2022-09-01T23:06:30",
"updateTime": "2022-09-02T00:29:04",
"exprList": [
{
"id": 1,
"begin": "2012-07-01",
"end": "2019-03-03"
"company": "百度科技股份有限公司"
"job": "java开发",
"empId": 2
},
{
"id": 2,
"begin": "2019-3-15",
"end": "2023-03-01"
"company": "阿里巴巴科技股份有限公司"
"job": "架构师",
"empId": 2
}
]
}
}2.1.2 实现思路
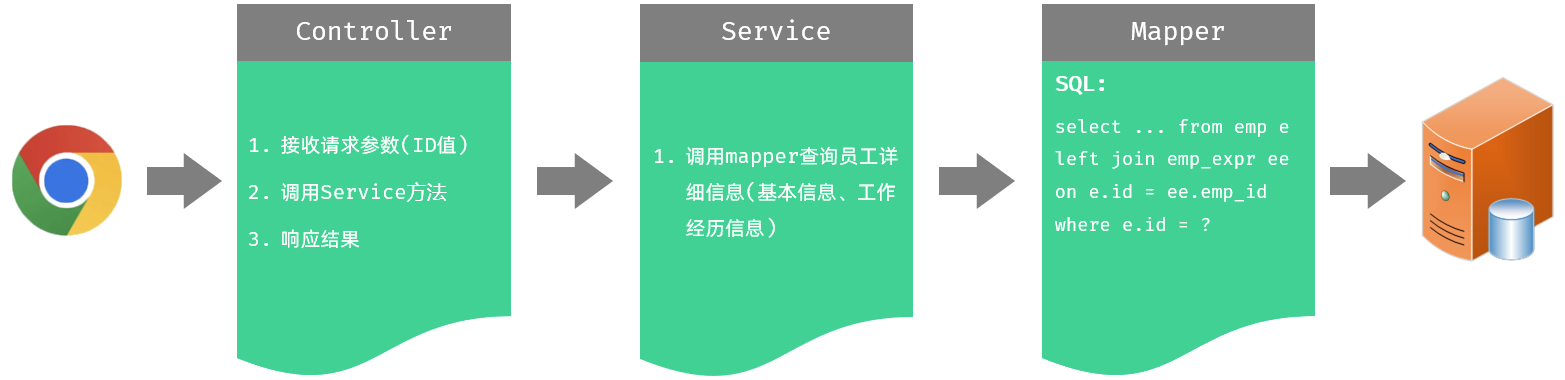
在查询回显时,既需要查询出员工的基本信息,又需要查询出该员工的工作经历信息。
/**
* 员工回显
* @param id
* @return
*/
@GetMapping("/emps/{id}")
public Result getById(@PathVariable Integer id){
log.info("参数回显员工,id = {}", id);
Emp emp = empService.getById(id);
return Result.success(emp);
}我们可以先通过一条SQL语句,查询出指定员工的基本信息,及其员工的工作经历信息。SQL如下:
select e.*,
ee.id ee_id,
ee.begin ee_begin,
ee.end ee_end,
ee.company ee_company,
ee.job ee_job
from emp e left join emp_expr ee on e.id = ee.emp_id where e.id = 39;具体的实现思路如下:
2.1.3 代码实现
1). EmpController 添加 getById 用来根据ID查询员工数据,用于页面回显
/**
* 员工回显
* @param id
* @return
*/
@GetMapping("/emps/{id}")
public Result getById(@PathVariable Integer id){
log.info("参数回显员工,id = {}", id);
Emp emp = empService.getById(id);
return Result.success(emp);
}2). EmpServiceImpl 接口中增加 getById 方法
@Override
public Emp getById(Integer id) {
//1.调用mapper查询方法,获取员工基本信息以及经历列表信息
return empMapper.getById(id);
}3). EmpMapper 接口中增加 getById 方法
/**
* 根据员工id查询员工基本信息以及经历列表信息
* @param id
* @return
*/
//@Select("select * from emp e left join emp_expr ee on e.id = ee.emp_id where e.id = #{id};")
Emp getById(Integer id);4).EmpMapper.xml 配置文件中定义对应的SQL
<!--resultMap标签,进行一对多数据映射,autoMapping设置为true可以进行自动映射-->
<resultMap id="empResultMap" type="com.itheima.entity.Emp" autoMapping="true">
<!--id标签,主键映射-->
<id property="id" column="id"></id>
<!--collection标签:用来封装集合数据,适用于一对多的情况-->
<collection property="exprList" ofType="com.itheima.entity.EmpExpr">
<id column="ee_id" property="id"></id>
<result column="ee_empId" property="empId"></result>
<result column="ee_begin" property="begin"></result>
<result column="ee_end" property="end"></result>
<result column="ee_company" property="company"></result>
<result column="ee_job" property="job"></result>
</collection>
</resultMap>
<!--根据id查询员工基本信息以及经历列表信息-->
<select id="getById" resultMap="empResultMap">
select e.*,
ee.id ee_id,
ee.emp_id ee_empId,
ee.begin ee_begin,
ee.end ee_end,
ee.job ee_job,
ee.company ee_company
from emp e
left join emp_expr ee on e.id = ee.emp_id
where e.id = #{id}
</select>在这种一对多的查询中,我们要想成功的封装的结果,需要手动的基于 <resultMap> 来进行封装结果。
2.1.4 方式二
实现员工信息回显的第二种方式:在Service层调用两次Mapper层的查询方法,分别查询员工的基本信息和工作经历列表
Service层:
@Override
public Emp getById(Integer id) {
//方式一:
//调用mapper查询方法,获取员工基本信息以及经历列表信息
//return empMapper.getById(id);
//方式二
//1.查询员工基本信息,封装到Emp对象中
Emp emp = empMapper.getById2(id);
//2.查询员工经历列表信息,封装到Emp对象中
List<EmpExpr> empExprList = empExprMapper.getByEmpId(id);
emp.setExprList(empExprList);
//3.返回员工Emp对象
return emp;
}EmpMapper:
/**
* 根据员工id查询员工基本信息以及经历列表信息
* @param id
* @return
*/
//@Select("select * from emp e left join emp_expr ee on e.id = ee.emp_id where e.id = 44;")
Emp getById(Integer id);
@Select("select * from emp where id = #{id}")
Emp getById2(Integer id);单纯的查询员工的基本信息可以不用xml,直接用注解的方式实现就好了
EmpExprMapper:
//基于xml开发-动态SQL--<foreach>--批量查询员工经历
List<EmpExpr> getByEmpId(Integer empId);<!--根据id查询员工所有经历-->
<select id="getByEmpId" resultType="com.itheima.entity.EmpExpr">
select * from emp_expr where emp_id = #{id}
</select>也可以使用简单的注解方式。
对于单纯的查询操作,不需要使用事务管理。
原因如下:
查询操作是只读的:事务主要用于保证数据的一致性和完整性,主要在修改、插入、删除等写操作中发挥作用。
MyBatis默认就是非事务查询:查询操作默认在自动提交模式下执行,每条SQL语句执行后立即生效。
当前查询逻辑简单:先查询员工基本信息,再查询员工工作经历,最后组合返回
即使其中一个查询失败,也不会对数据造成不一致的影响
什么时候需要事务?
1.多个写操作需要保持一致性:比如你代码中的保存员工信息方法。2.多个操作需要原子性执行:要么全部成功,要么全部失败。
总结
对于你目前的查询员工基本信息和工作经历的需求,不需要添加事务管理。查询操作本身就是安全的,即使在极少数情况下第二个查询失败,也不会对数据库造成任何影响,最多只是返回不完整的数据,这可以通过其他方式(如异常处理)来解决。
只有在进行数据修改操作时,才需要考虑使用事务来保证数据的一致性。
Mybatis中封装数据查询结果,什么时候用resultType,什么时候用resultMap?
1. resultType:简单直接的 “自动匹配”
适用情况:当数据库查询结果的字段名,和你定义的实体类(比如 Java 的 User 类)的属性名完全一样时,用 resultType。
举个例子:
- 数据库表
user有字段:id、name、age - 你的实体类
User有属性:id、name、age(变量名和字段名完全相同)
这时候在 MyBatis 的 SQL 映射文件里,直接写:
<select id="getUser" resultType="com.example.User">
select id, name, age from user where id = #{id}
</select>MyBatis 会自动把查询到的 id 对应到 User 的 id 属性,name 对应 name 属性,根本不用你操心 —— 这就是 “自动匹配”。
2. resultMap:需要手动 “牵线搭桥”
适用情况:当数据库字段名和实体类属性名不一样,或者实体类里有复杂属性(比如关联了另一个对象)时,必须用 resultMap 手动定义对应关系。
情况 1:字段名和属性名不一样
- 数据库表
user有字段:user_id、user_name(字段名带前缀) - 实体类
User有属性:id、name(属性名没有前缀)
这时候字段名和属性名对不上,MyBatis 不知道 user_id 该放到 id 里,所以需要用 resultMap 手动指定:
<!-- 先定义一个resultMap,告诉MyBatis字段和属性的对应关系 -->
<resultMap id="userMap" type="com.example.User">
<id column="user_id" property="id"/> <!-- 数据库字段user_id对应实体类的id -->
<result column="user_name" property="name"/> <!-- 数据库字段user_name对应实体类的name -->
</resultMap>
<!-- 在查询时使用这个resultMap -->
<select id="getUser" resultMap="userMap">
select user_id, user_name from user where user_id = #{id}
</select>情况 2:实体类有复杂属性(关联对象)
比如 User 类里不仅有基本信息,还有一个 Dept 类型的属性(表示用户所属部门):
public class User {
private int id;
private String name;
private Dept dept; // 关联的部门对象(复杂属性)
}
public class Dept {
private int deptId;
private String deptName;
}数据库查询可能同时查出用户和部门信息(比如 user.id、user.name、dept.dept_id、dept.dept_name),这时候需要用 resultMap 告诉 MyBatis 如何把部门信息装进 User 的 dept 属性里:
<resultMap id="userWithDeptMap" type="com.example.User">
<id column="id" property="id"/>
<result column="name" property="name"/>
<!-- 关联Dept对象,用association标签 -->
<association property="dept" javaType="com.example.Dept">
<id column="dept_id" property="deptId"/>
<result column="dept_name" property="deptName"/>
</association>
</resultMap>
<select id="getUserWithDept" resultMap="userWithDeptMap">
select u.id, u.name, d.dept_id, d.dept_name
from user u
left join dept d on u.dept_id = d.dept_id
where u.id = #{id}
</select>总结
resultType:简单场景用,字段名和属性名完全一致时,MyBatis 自动帮你 “装数据”。resultMap:复杂场景用,当字段名和属性名不一样,或者有关联对象、集合等复杂属性时,需要你手动定义 “对应规则”,告诉 MyBatis 如何 “装数据”。
简单说就是:能自动对应就用 resultType,不能自动对应就用 resultMap 手动配置。
2.2 修改员工
查询回显之后,就可以在页面上修改员工的信息了。
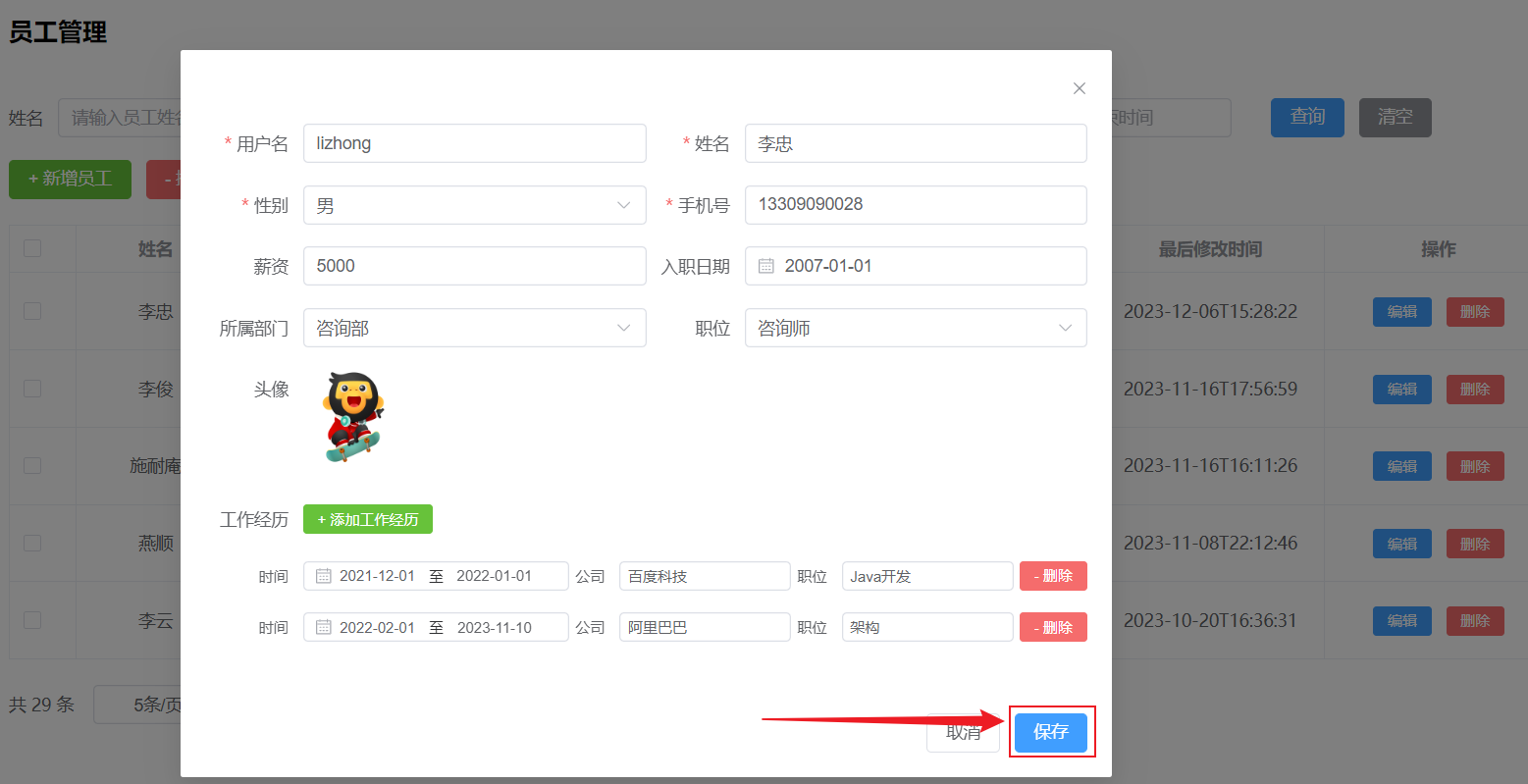
当用户修改完数据之后,点击保存按钮,就需要将数据提交到服务端,然后服务端需要将修改后的数据更新到数据库中 。
而此次更新的时候,既需要更新员工的基本信息; 又需要更新员工的工作经历信息 。
2.2.1 接口文档
-
基本信息
请求路径:/emps 请求方式:PUT 接口描述:该接口用于修改员工的数据信息
-
请求参数
参数格式:application/json
参数说明:
名称 类型 是否必须 备注 id number 必须 id username string 必须 用户名 name string 必须 姓名 gender number 必须 性别, 说明: 1 男, 2 女 image string 非必须 图像 deptId number 非必须 部门id entryDate string 非必须 入职日期 job number 非必须 职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师 salary number 非必须 薪资 exprList object[] 非必须 工作经历列表 |- id number 非必须 ID |- company string 非必须 所在公司 |- job string 非必须 职位 |- begin string 非必须 开始时间 |- end string 非必须 结束时间 |- empId number 非必须 员工ID 请求数据样例:
{
"id": 2,
"username": "zhangwuji",
"name": "张无忌",
"gender": 1,
"image": "https://web-framework.oss-cn-hangzhou.aliyuncs.com/2022-09-02-00-27-53B.jpg",
"job": 2,
"salary": 8000,
"entryDate": "2015-01-01",
"deptId": 2,
"exprList": [
{
"id": 1,
"begin": "2012-07-01",
"end": "2015-06-20"
"company": "中软国际股份有限公司"
"job": "java开发",
"empId": 2
},
{
"id": 2,
"begin": "2015-07-01",
"end": "2019-03-03"
"company": "百度科技股份有限公司"
"job": "java开发",
"empId": 2
}
]
}- 响应数据
参数格式:application/json
参数说明:
| 参数名 | 类型 | 是否必须 | 备注 |
|---|---|---|---|
| code | number | 必须 | 响应码,1 代表成功,0 代表失败 |
| msg | string | 非必须 | 提示信息 |
| data | object | 非必须 | 返回的数据 |
响应数据样例:
{
"code":1,
"msg":"success",
"data":null
}2.2.2 实现思路
2.2.3 代码实现
1)Controller层:
/**
* 修改员工
* @param emp
* @return
*/
@PutMapping
public Result update(@RequestBody Emp emp){
log.info("修改员工:emp={}",emp);
empService.update(emp);
return Result.success();
}2)EmpServiceImpl层实现类实现update方法
@Transactional //开启事务
@Override
public void update(Emp emp) {
//1.修改员工的基本信息 -- emp
//1.1 补充基础属性--更新时间
emp.setUpdateTime(LocalDateTime.now());
empMapper.update(emp);
//2.修改员工的工作经历信息 -- emp_expr
//先删后增
empExprMapper.deleteByEmpId(emp.getId());
List<EmpExpr> exprList = emp.getExprList();
if (!CollectionUtils.isEmpty(exprList)) {
//关联员工id
exprList.forEach(expr -> {
expr.setEmpId(emp.getId());
});
empExprMapper.insertBatch(exprList);
}
}修改员工的工作经历时,我们需要增删改,可以分开调用三个Mapper方法。但是更简便的方法是先删除后增加,在前端页面选择员工后,将id传到后端,接收后先在后端数据库中将此员工对应的经历信息全部删除,删除之后我们再用emp.getExprList()方法将前端传入服务器的员工经历信息重新insert到emp_expr表中,但是我们能直接添加吗?我们在insert前需要做两件事:
- 关联员工id
如果直接添加,数据库中并没有emp_id数据,这些直接添加的数据会变为脏数据,从而没有对应的员工,所以为了避免这个问题我们需要用foreach遍历exprList集合将每一条员工经历信息都与当前emp中的id对应起来(注意这里是员工经历表emp_expr中的emp_id对应emp表中的id)。
- 判断非空
如果前端页面当前员工本来就没有员工数据,可是我们依旧执行了insert操作,此时就会报错,为了解决这个问题,我们可以在关联员工id以及insert操作前进行判断,如果expList集合为非空,再进入进行操作。
3)EmpMapper接口中增加update方法
/**
* 更新员工--动态SQL
* @param emp
*/
//基于xml开发动态SQL
void update(Emp emp);4)EmpMapper.xml 配置文件中定义对应的SQL语句,基于动态SQL更新员工信息
<!--根据ID更新员工信息-->
<update id="update">
update emp
<set>
<if test="username != null and username != ''">username = #{username},</if>
<if test="password != null and password != ''">password = #{password},</if>
<if test="name != null and name != ''">name = #{name},</if>
<if test="gender != null">gender = #{gender},</if>
<if test="phone != null and phone != ''">phone = #{phone},</if>
<if test="job != null">job = #{job},</if>
<if test="salary != null">salary = #{salary},</if>
<if test="image != null and image != ''">image = #{image},</if>
<if test="entryDate != null">entry_date = #{entryDate},</if>
<if test="deptId != null">dept_id = #{deptId},</if>
<if test="updateTime != null">update_time = #{updateTime},</if>
</set>
where id = #{id}
</update>1. 动态更新(部分更新)
这种方式支持动态更新,即只更新用户提供的字段,而不是更新所有字段。这样做的好处包括:
- 避免覆盖未提供字段的值:如果某个字段没有在请求中提供,不会将其更新为null或空值
- 提高性能:只更新需要修改的字段,减少不必要的数据库操作
- 更灵活:前端可以只传递需要修改的字段,而不必传递所有字段
2. 防止SQL语法错误
<set>标签会自动处理SQL语句中的逗号问题:
- 自动添加SET关键字
- 自动去除最后一个更新字段后的逗号
- 如果没有任何字段需要更新,会避免语法错误
3. 安全性
使用<if>标签进行条件判断,确保只有在字段不为空的情况下才进行更新,避免将null或空字符串更新到数据库中。
这里是如何实现只更新前端修改了的字段呢?
1.前端只会传入需要更新的字段,而其余字段为null,eg:
前端只更新员工的用户名和电话号码:
{
"id": 10,
"username": "newUser123",
"phone": "13800138000"
}
2.springboot会自动将json格式的请求数据转换为Emp对象:
Emp emp = new Emp();
emp.setId(10); // 有值:10
emp.setUsername("newUser123"); // 有值:"newUser123"
emp.setPhone("13800138000"); // 有值:"13800138000"
// 其他字段都没有传入,所以都是null
// emp.getPassword() == null
// emp.getName() == null
// emp.getGender() == null
// ...
3. MyBatis处理过程
XML中的每个<if>判断都会检查对应字段:
<!-- username有值,条件满足,会生成这部分SQL -->
<if test="username != null and username != ''">username = #{username},</if>
<!-- password是null,条件不满足,不会生成SQL -->
<if test="password != null and password != ''">password = #{password},</if>
<!-- name是null,条件不满足,不会生成SQL -->
<if test="name != null and name != ''">name = #{name},</if>
<!-- phone有值,条件满足,会生成这部分SQL -->
<if test="phone != null and phone != ''">phone = #{phone},</if>
4. 最终生成的SQL
UPDATE emp SET username = 'newUser123', phone = '13800138000' WHERE id = 10
数据库中其他字段保持原值不变,只有username和phone被更新。
2.2.5 前后端联调测试
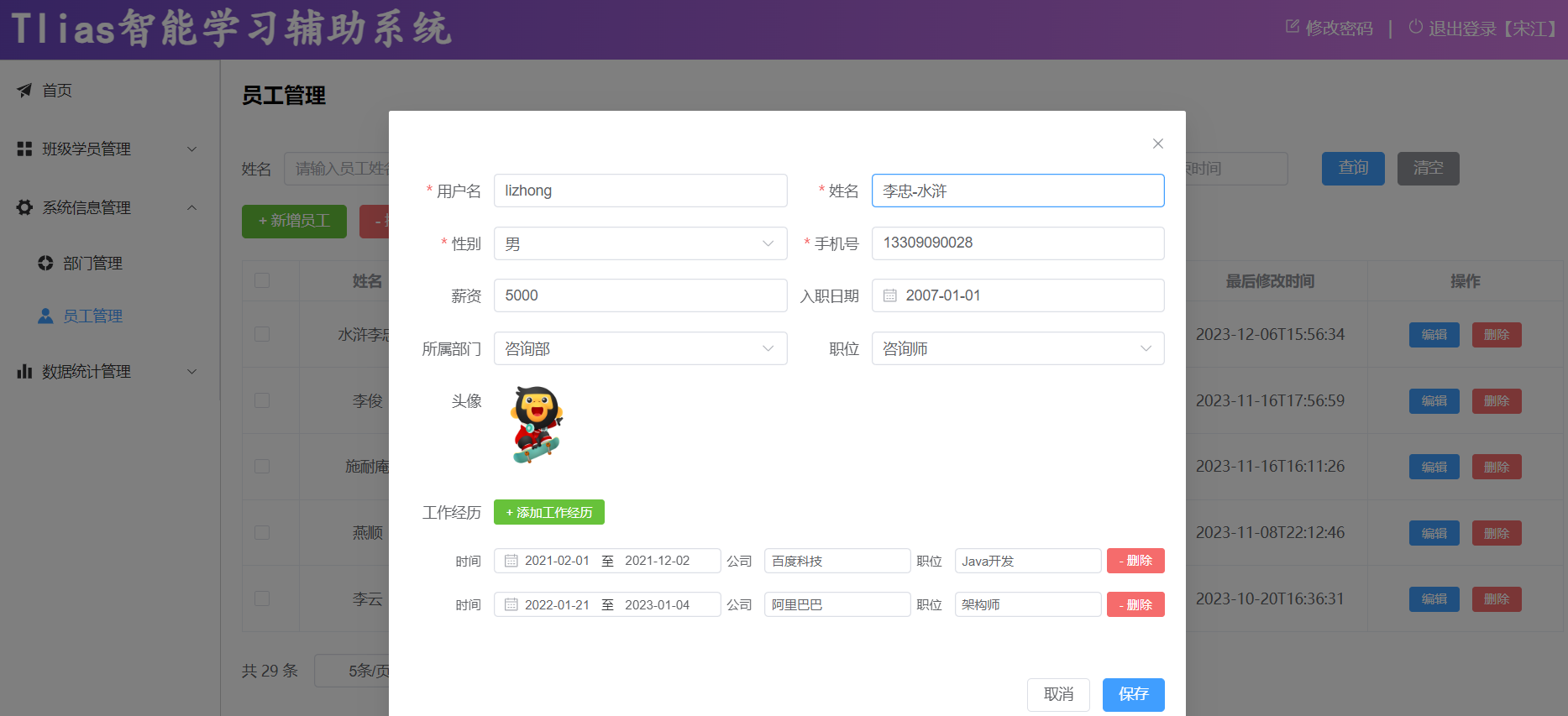
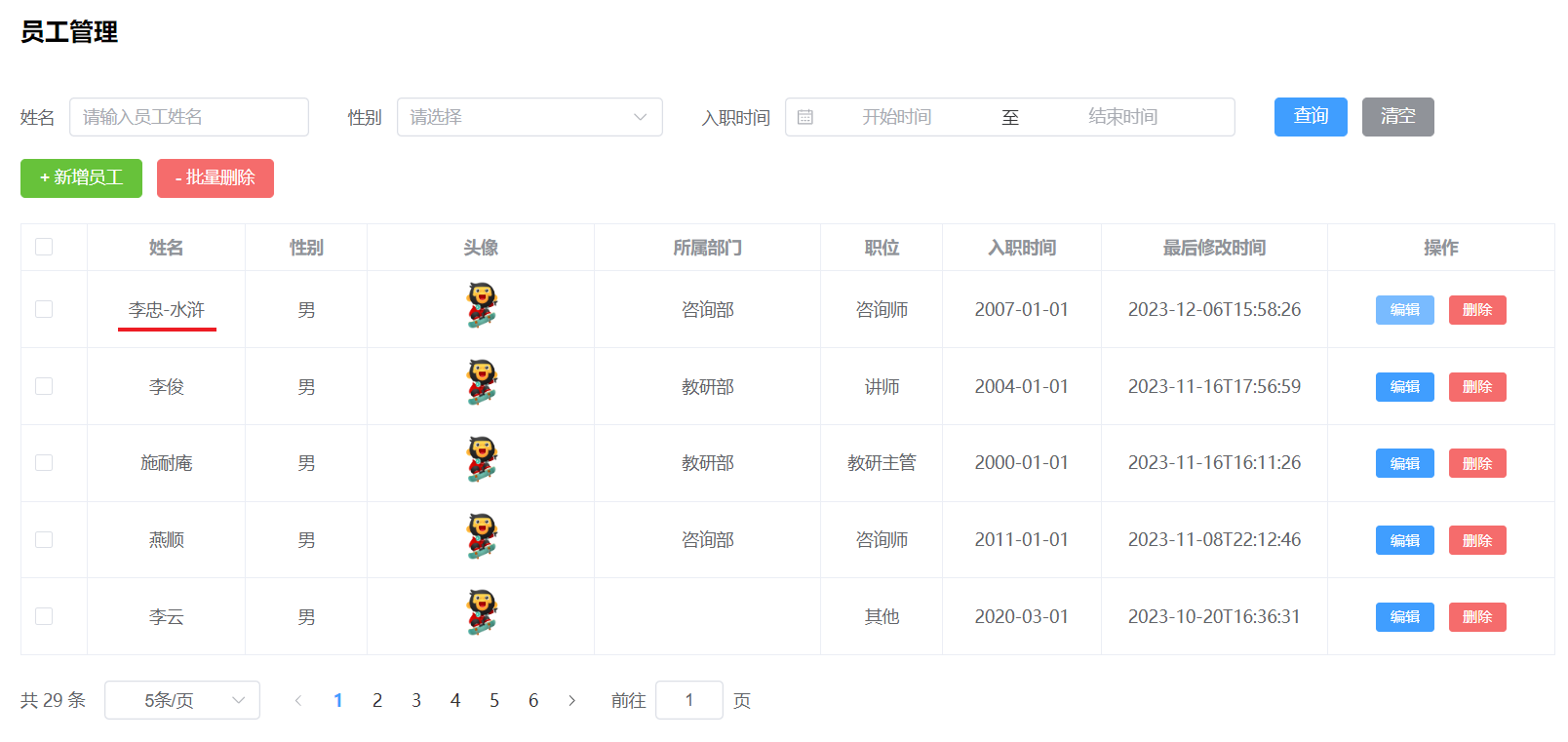
点击保存之后,查看更新后的数据。
3.异常处理
3.1 当前问题
当我们在修改部门数据的时候,如果输入一个在数据库表中已经存在的手机号,点击保存按钮之后,前端提示了错误信息,但是返回的结果并不是统一的响应结果,而是框架默认返回的错误结果
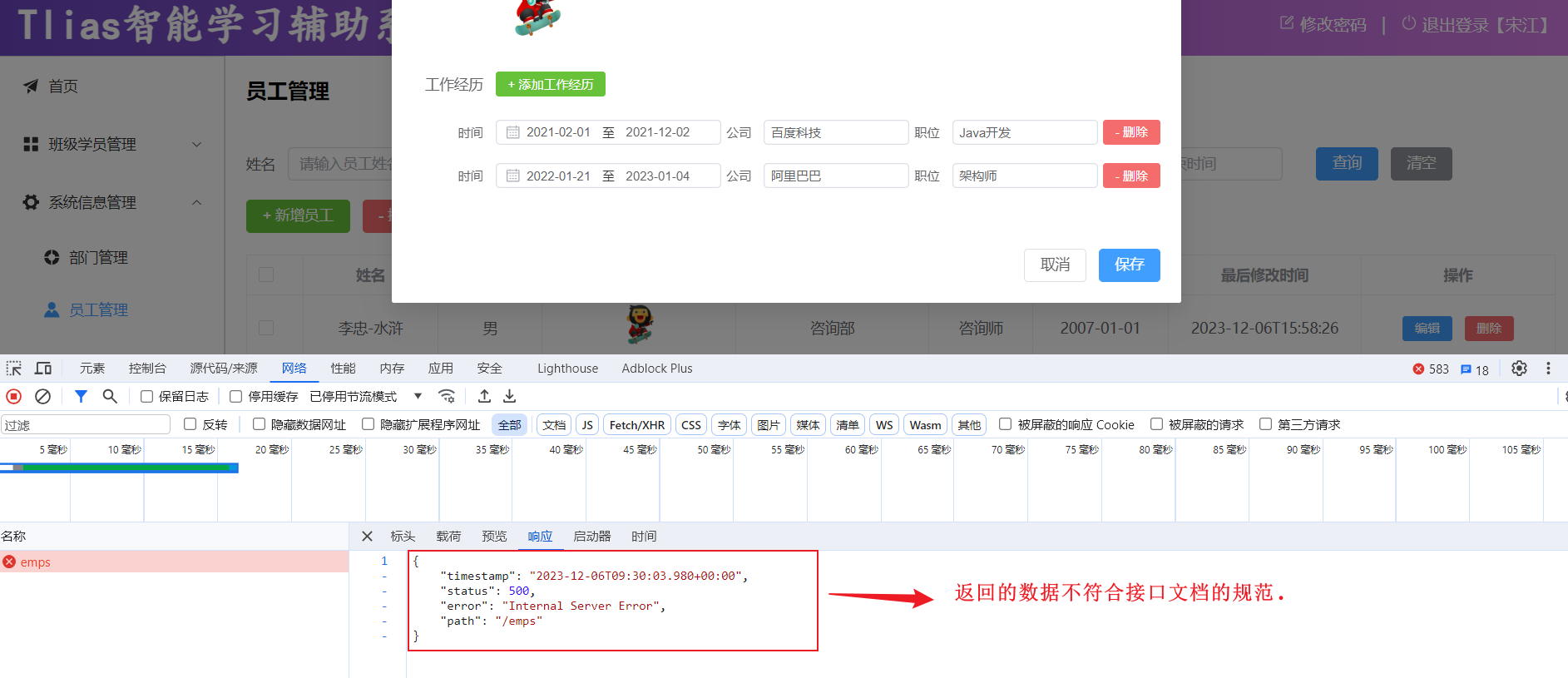
状态码为500,表示服务器端异常,我们打开idea,来看一下,服务器端出了什么问题。

上述错误信息的含义是,emp员工表的phone手机号字段的值重复了,因为在数据库表emp中已经有了13309090001这个手机号了,我们之前设计这张表时,为phone字段建议了唯一约束,所以该字段的值是不能重复的。
而当我们再将该员工的手机号也设置为 13309090001,就违反了唯一约束,此时就会报错。
我们来看一下出现异常之后,最终服务端给前端响应回来的数据长什么样。

响应回来的数据是一个JSON格式的数据。但这种JSON格式的数据还是我们开发规范当中所提到的统一响应结果Result吗?显然并不是。由于返回的数据不符合开发规范,所以前端并不能解析出响应的JSON数据 。
接下来我们需要思考的是出现异常之后,当前案例项目的异常是怎么处理的?
- 答案:没有做任何的异常处理
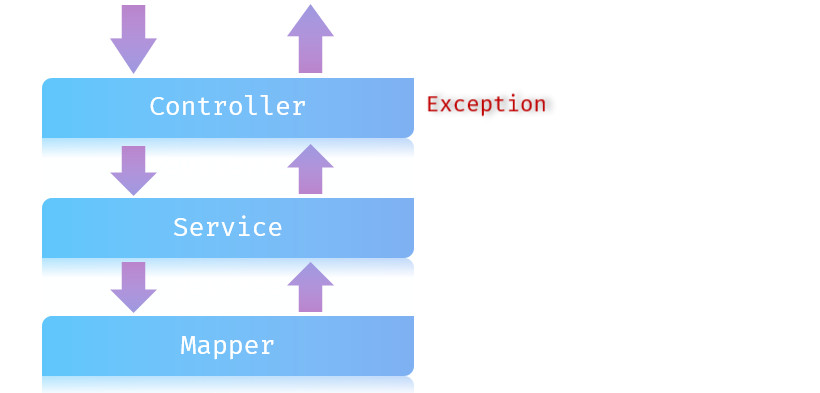
当我们没有做任何的异常处理时,我们三层架构处理异常的方案:
-
Mapper接口在操作数据库的时候出错了,此时异常会往上抛(谁调用Mapper就抛给谁),会抛给service。
-
service 中也存在异常了,会抛给controller。
-
而在controller当中,我们也没有做任何的异常处理,所以最终异常会再往上抛。最终抛给框架之后,框架就会返回一个JSON格式的数据,里面封装的就是错误的信息,但是框架返回的JSON格式的数据并不符合我们的开发规范。
3.2 解决方案
那么在三层构架项目中,出现了异常,该如何处理?
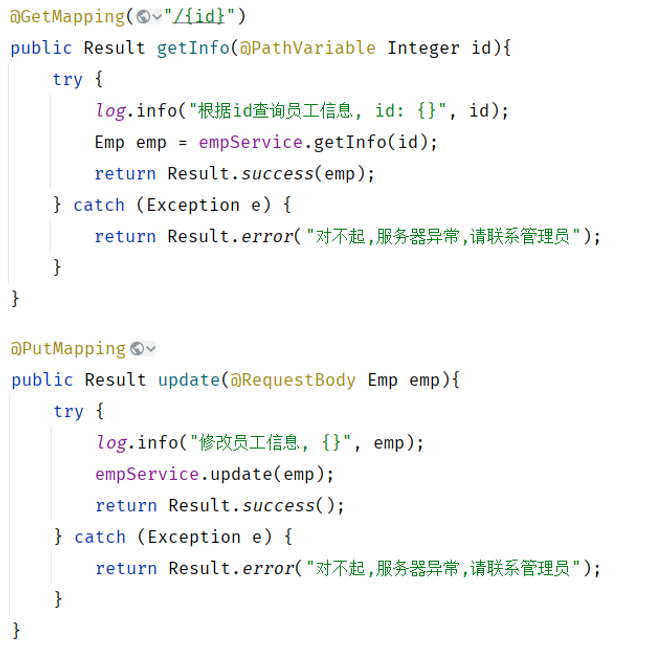
-
方案一:在所有Controller的所有方法中进行try…catch处理
-
缺点:代码臃肿(不推荐)
-
-
方案二:全局异常处理器
-
好处:简单、优雅(推荐)
-
3.3 全局异常处理器
我们该怎么样定义全局异常处理器?
-
定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解@RestControllerAdvice,加上这个注解就代表我们定义了一个全局异常处理器。
-
在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解@ExceptionHandler。通过@ExceptionHandler注解当中的value属性来指定我们要捕获的是哪一类型的异常。
@Slf4j
@RestControllerAdvice //作用:用来捕获控制器controller层抛出的异常
//@ControllerAdvice
//@ResponseBody
public class GlobalExceptionHandler {
@ExceptionHandler //指定处理何种异常,默认处理所有类型异常
public Result doException(Exception ex){
log.error(ex.getMessage());
return Result.error("出错了,请联系管理员!");
}
}
@RestControllerAdvice = @ControllerAdvice + @ResponseBody
处理异常的方法返回值会转换为json后再响应给前端
重新启动SpringBoot服务,打开浏览器,再来测试一下 修改员工 这个操作,我们依然设置已存在的 "13309090001" 这个手机号:
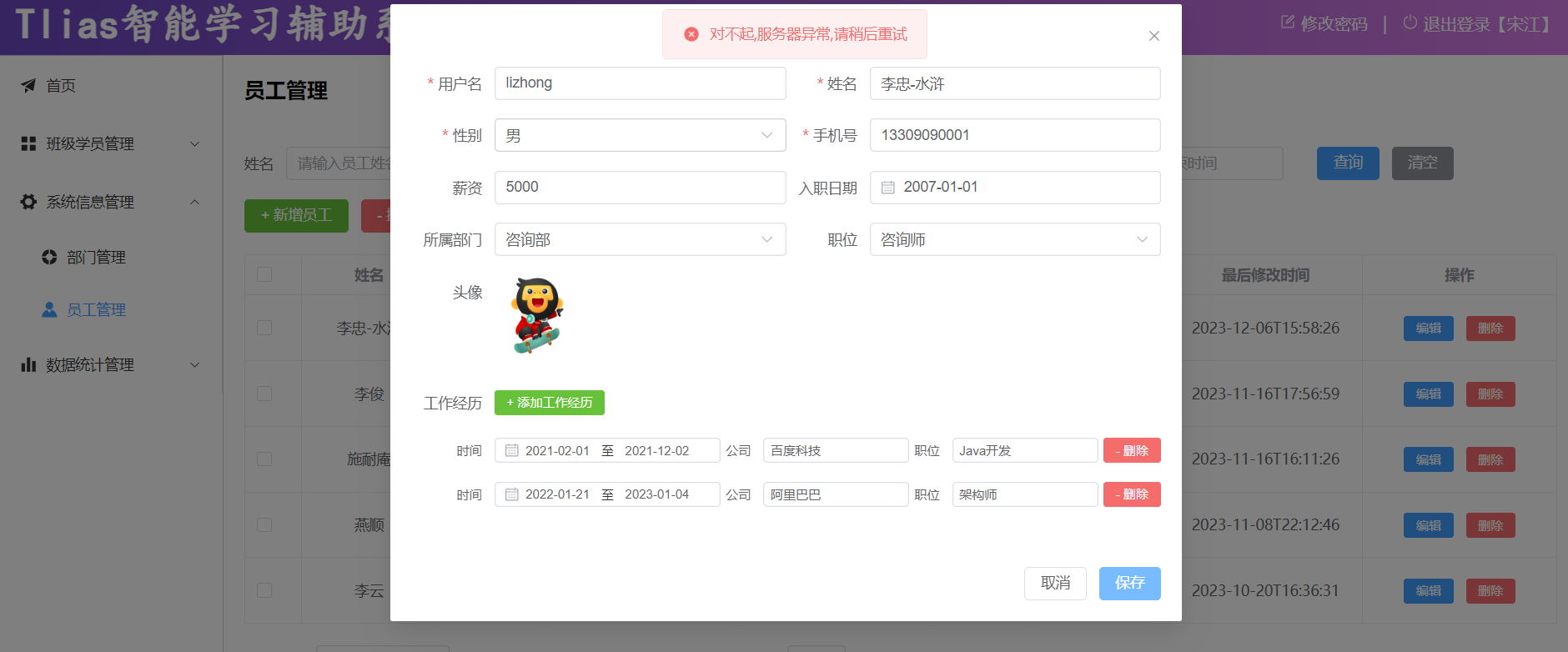
此时,我们可以看到,出现异常之后,异常已经被全局异常处理器捕获了。然后返回的错误信息,被前端程序正常解析,然后提示出了对应的错误提示信息。
以上就是全局异常处理器的使用,主要涉及到两个注解:
@RestControllerAdvice //表示当前类为全局异常处理器
@ExceptionHandler //指定可以捕获哪种类型的异常进行处理
4.员工信息统计
员工管理的增删改查功能我们已经全部实现了,接下来我们再来完成员工信息统计的接口开发。对于这些图形报表的开发,其实都是基于现成的一些图形报表的组件开发的,比如:Echarts、HighCharts等。
而报表的制作,主要是前端人员开发,引入对应的组件(比如:ECharts)即可。 服务端开发人员仅为其提供数据即可。
4.1 职位统计
4.1.1 需求
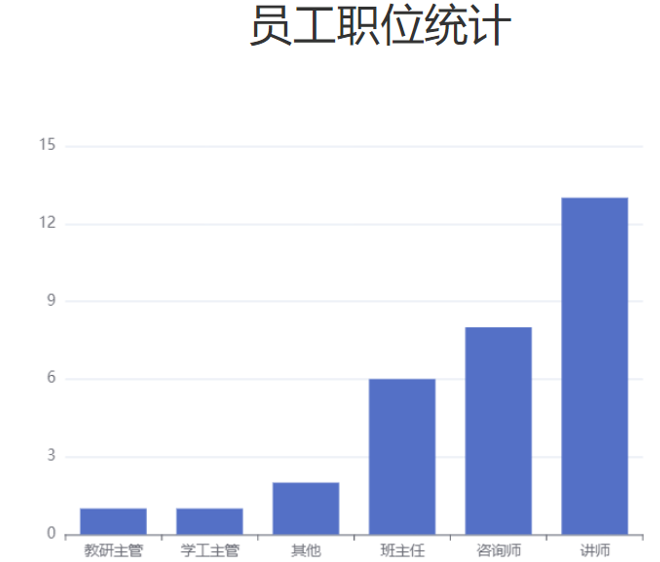
对于这类的图形报表,服务端要做的,就是为其提供数据即可。 我们可以通过官方的示例,看到提供的数据其实就是X轴展示的信息,和对应的数据。
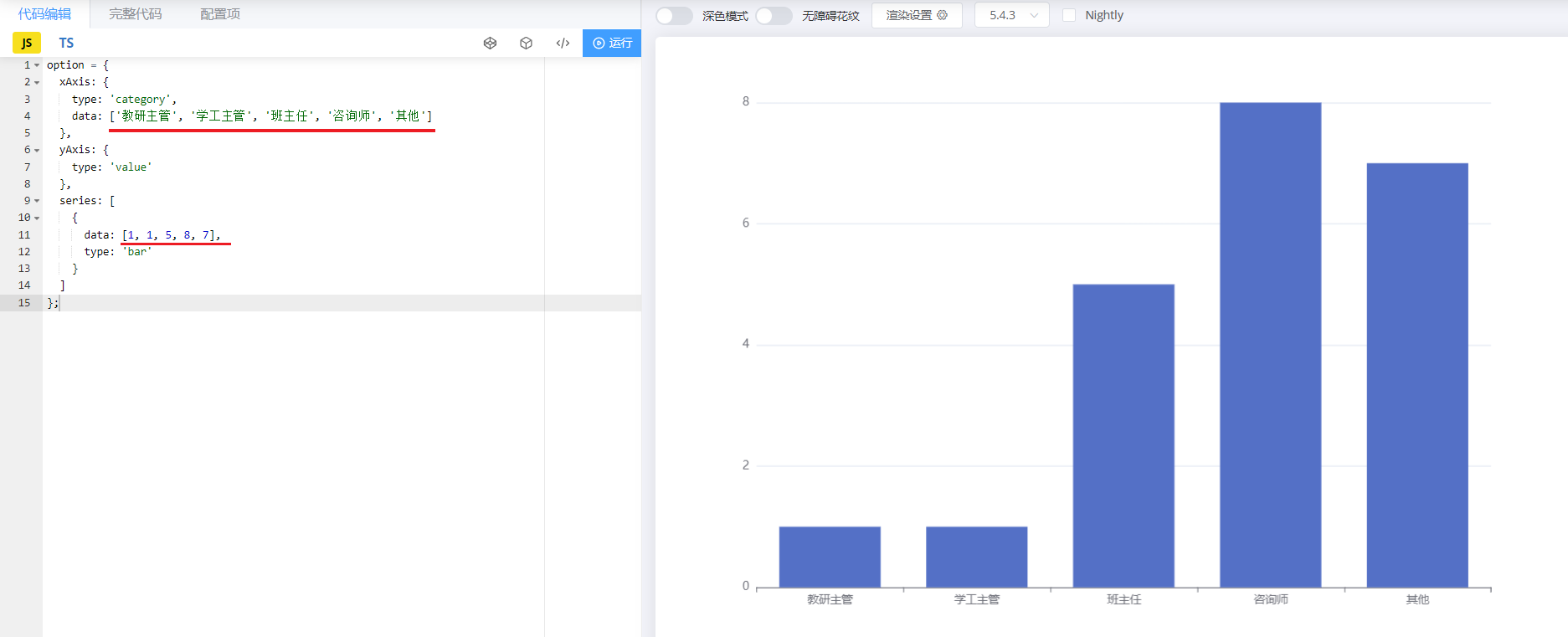
4.1.2 接口文档
1). 基本信息
请求路径:/report/empJobData
请求方式:GET
接口描述:统计各个职位的员工人数
2). 请求参数
无
3). 响应数据
参数格式:application/json
参数说明:
| 参数名 | 类型 | 是否必须 | 备注 |
|---|---|---|---|
| code | number | 必须 | 响应码,1 代表成功,0 代表失败 |
| msg | string | 非必须 | 提示信息 |
| data | object | 非必须 | 返回的数据 |
| |- jobList | string[] | 必须 | 职位列表 |
| |- dataList | number[] | 必须 | 人数列表 |
响应数据样例:
{
"code": 1,
"msg": "success",
"data": {
"jobList": ["教研主管","学工主管","其他","班主任","咨询师","讲师"],
"dataList": [1,1,2,6,8,13]
}
}为了封装上面需要给前端返回的数据,在entity包下再创建一个实体类 JobOption,封装给前端返回的结果:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class JobOption {
private List jobList; //职位列表
private List dataList; //数据列表
}
其实返回给前端的json数据就是两条json格式的数据,一条是树状图x轴的职位名称,一条是y轴的人数,我们可以将这两条数据存到两个集合里然后封装到JobOption对象中返回给前端。
4.1.3 代码实现
1). 定义ReportController,并添加方法。
@Slf4j
@RequestMapping("/report")
@RestController
public class ReportController {
@Autowired
private ReportService reportService;
/**
* 员工职位数据统计
* @return
*/
@GetMapping("/empJobData")
public Result getEmpJobData() {
log.info("开始处理员工职位数据统计");
JobOption jobOption = reportService.getEmpJobData();
return Result.success(jobOption);
}
}
将职位列表和数据列表都封装到JobOption类型的对象中,要通过调用ReportServiceImpl层的getEmpJobData()方法。
2). 定义ReportServiceImpl实现类,并实现方法
@Service
public class ReportServiceImpl implements ReportService {
@Autowired
private EmpMapper empMapper;
@Override
public JobOption getEmpJobData() {
//1.调用mapper接口,获取统计数据
List<Map<String, Object>> list = empMapper.countEmpJobData(); //map: 职位=校验主管,人数=1
//2.组装结果,并返回
List<Object> jobList = list.stream().map(dataMap -> dataMap.get("职位")).toList();
List<Object> dataList = list.stream().map(dataMap -> dataMap.get("人数")).toList();
return new JobOption(jobList, dataList);
}
}
在Java中,List<Map<String, Object>> 这种类型定义中,Map<String, Object> 的键和值的类型是必须指定的。这是因为Java是一门强类型语言,需要在编译时确定泛型类型。
让我来解释一下这个类型定义:
List<Map<String, Object>> 表示一个列表,列表中的每个元素都是一个 Map<String, Object> 类型的对象
Map<String, Object> 表示一个映射表,其中:
- 键(key)的类型是 String
- 值(value)的类型是 Object,这意味着值可以是任何对象类型
虽然键的类型固定为 String,但值的类型是 Object,这在Java中是一个通用的父类,可以接受任何类型的对象。所以值可以是各种不同的类型,比如 String、Integer、Double 等
此方法会调用empMapper层的方法,得到List<Map<String,Object>>类型的Map集合list,接着我们要根据Map集合的Key获取到里面对应的value值,我们可以基于stream流来操作,我们要拿到Map集合,并对Map集合中的数据进行处理,然后封装到新的list中,我们就要使用map()方法。遍历Map集合中职位所对应的每一条value值,然后用toList()封装到新的集合当中。
3). 定义EmpMapper 接口
统计的是员工的信息,所以需要操作的是员工表。 所以代码我们就写在 EmpMapper 接口中即可。
/**
* 统计员工职位数据
* @return
*/
@MapKey("职位")
List<Map<String,Object>> countEmpJobData();如果查询的记录往Map中封装,可以通过@MapKey注解指定返回的map中的唯一标识是那个字段。【也可以不指定】
4). 定义EmpMapper.xml
<!-- 统计各个职位的员工人数 -->
<select id="countEmpJobData" resultType="java.util.Map">
select
(case job when 1 then '班主任'
when 2 then '讲师'
when 3 then '学工主管'
when 4 then '教研主管'
when 5 then '咨询师'
else '其他' end) pos,
count(*) total
from emp group by job
order by total
</select>case流程控制函数:
语法一:case when cond1 then res1 [ when cond2 then res2 ] else res end ;
含义:如果 cond1 成立, 取 res1。 如果 cond2 成立,取 res2。 如果前面的条件都不成立,则取 res。
语法二(仅适用于等值匹配):case expr when val1 then res1 [ when val2 then res2 ] else res end ;
含义:如果 expr 的值为 val1 , 取 res1。 如果 expr 的值为 val2 ,取 res2。 如果前面的条件都不成立,则取 res。
4.2 性别统计
4.2.1 需求
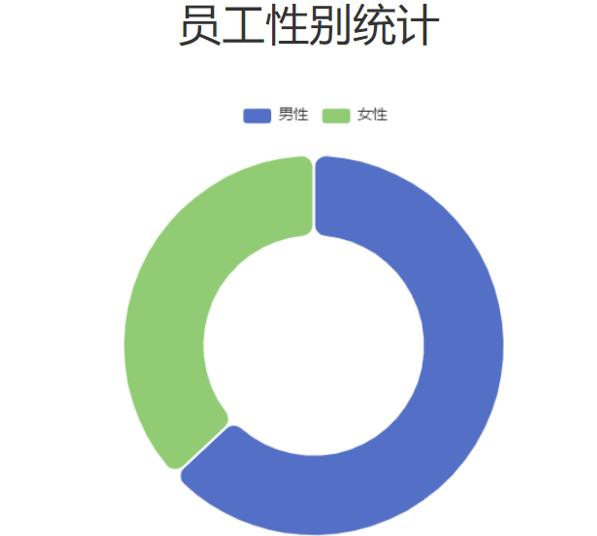
对于这类的图形报表,服务端要做的,就是为其提供数据即可。 我们可以通过官方的示例,看到提供的数据就是一个json格式的数据。
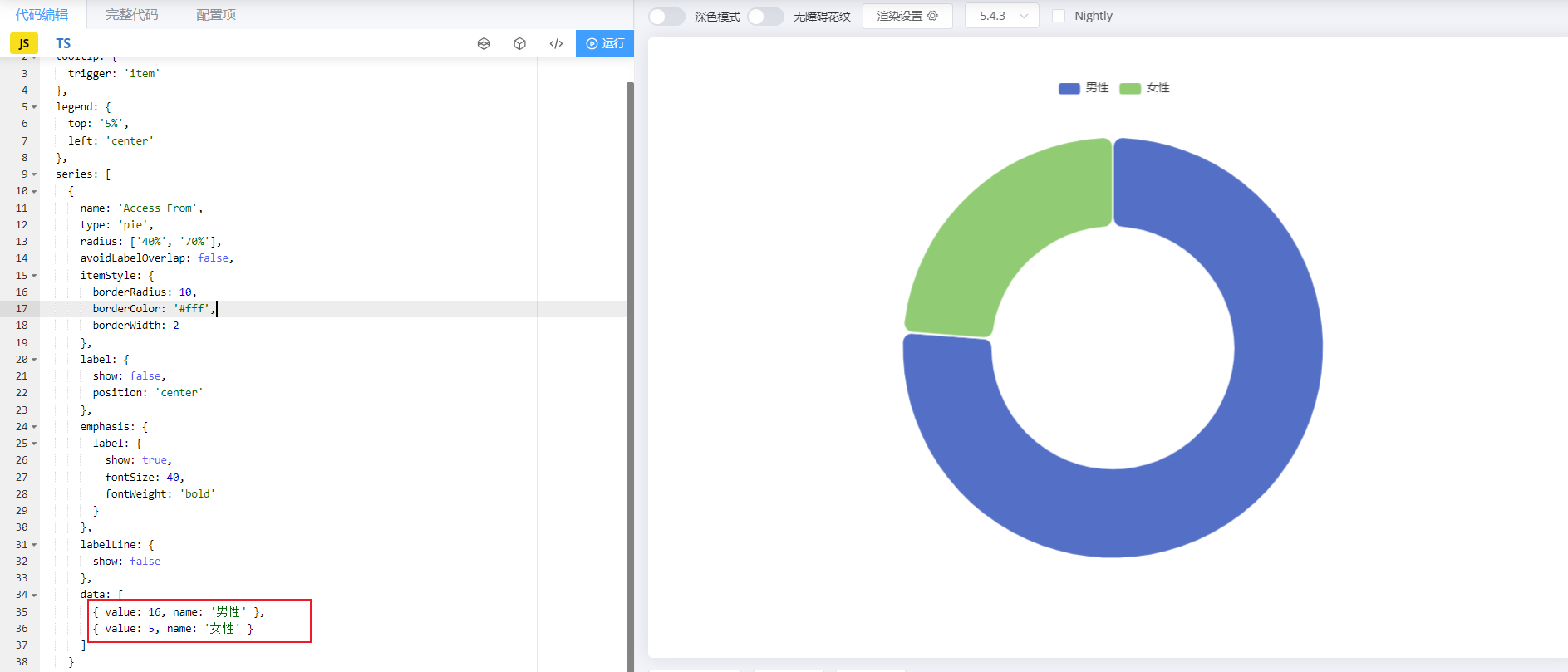
4.2.2 接口文档
1). 基本信息
请求路径:/report/empGenderData
请求方式:GET
接口描述:统计员工性别信息
2). 请求参数
无
3). 响应数据
参数格式:application/json
参数说明:
| 参数名 | 类型 | 是否必须 | 备注 |
|---|---|---|---|
| code | number | 必须 | 响应码,1 代表成功,0 代表失败 |
| msg | string | 非必须 | 提示信息 |
| data | object[] | 非必须 | 返回的数据 |
| |- name | string | 非必须 | 性别 |
| |- value | number | 非必须 | 人数 |
响应数据样例:
{
"code": 1,
"msg": "success",
"data": [
{"name": "男性","value": 5},
{"name": "女性","value": 6}
]
}4.2.3 代码实现
1). 在ReportController,添加方法。
/**
* 员工性别数据统计
* @return
*/
@GetMapping("/empGenderData")
public Result getEmpGenderData() {
log.info("开始处理员工性别数据统计");
List<Map<String,Object>> genderList = reportService.getEmpGenderData();
return Result.success(genderList);
}2). 在ReportService接口,添加接口方法。
/**
* 统计员工性别信息
*/
List<Map<String,Object>> getEmpGenderData();3). 在ReportServiceImpl实现类,实现方法
/**
* 获取员工性别数据
*
* @return
*/
@Override
public List<Map> getEmpGenderData() {
return empMapper.countEmpGenderData();
}4). 定义EmpMapper 接口
/**
* 统计员工性别数据
* @return
*/
@MapKey("name")
List<Map<String,Object>> countEmpGenderData();5). 定义EmpMapper.xml
<!--查询员工性别数据统计-->
<select id="countEmpGenderData">
select
if(gender = 1, '男性员工', '女性员工') name,
count(*) value
from emp
group by gender;
</select>1. SQL 中的 IF 函数
-
作用:
IF函数用于实现条件判断,根据指定的条件返回不同的值。 -
语法:
IF(condition, value_if_true, value_if_false)。 -
示例:在
EmpMapper.xml里的 SQL 语句IF(gender = 1, '男', '女') as name中,condition是gender = 1,当员工的gender字段值为1时,返回'男';当gender字段值不为1时,返回'女'。这样就可以根据gender的值,将其转换为对应的中文性别名称,方便后续展示等操作。
2. SQL 中的 IFNULL 函数
-
作用:
IFNULL函数用于判断第一个表达式是否为NULL,如果是,就返回第二个参数的值;如果不是,就返回第一个参数的值。 -
语法:
IFNULL(expr1, expr2)。 -
示例:比如在查询员工工资时,有些员工工资可能为
NULL,我们希望将其显示为0,可以这样写 SQL 语句:SELECT IFNULL(salary, 0) as salary FROM emp。这里expr1是salary字段,如果salary为NULL,就返回0;否则返回salary本身的值。这样可以保证查询结果中工资字段不会出现NULL,方便后续的数据处理和展示。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









