



 JOIN是MySQL用于联表查询的方式,包括LEFTJOIN、RIGHTJOIN和INNERJOIN等。驱动表是多表查询时首先处理的表,选择结果集小的表作为驱动表能优化性能。文章介绍了SimpleNested-LoopJoin、IndexNested-LoopJoin和BlockNested-LoopJoin三种JOIN算法,以及JOIN优化方法,如使用小结果集驱动大结果集、添加索引、增大JOIN缓冲区大小和减少不必要的字段查询。建议通过索引和优化驱动表选择来提升JOIN效率。
JOIN是MySQL用于联表查询的方式,包括LEFTJOIN、RIGHTJOIN和INNERJOIN等。驱动表是多表查询时首先处理的表,选择结果集小的表作为驱动表能优化性能。文章介绍了SimpleNested-LoopJoin、IndexNested-LoopJoin和BlockNested-LoopJoin三种JOIN算法,以及JOIN优化方法,如使用小结果集驱动大结果集、添加索引、增大JOIN缓冲区大小和减少不必要的字段查询。建议通过索引和优化驱动表选择来提升JOIN效率。
定义
JOIN是MySQL用来进行联表操作的,用来匹配两个表的数据,筛选并合并符合我们要求的结果集
常用的联接方式有:
- 左外连接 LEFT JOIN
- 右外连接 RIGHT JOIN
- 内连接 INNER JOIN
什么是驱动表?
- 多表关联查询时,第一个被处理的表就是驱动表,使用驱动表去关联其他表。
- 驱动表的确定非常的关键,会直接影响多表关联的顺序,也决定后续关联查询的性能
驱动表的选择要遵循一个规则:
- 在对最终的结果集没有影响的前提下,优先选择结果集最小的那张表作为驱动表
三种JOIN算法
1.Simple Nested-Loop Join(简单的嵌套循环连接)
- 简单来说嵌套循环连接算法就是一个双层for 循环,通过循环外层表的行数据,逐个与内层表的所有行数据进行比较来获取结果
- 这种算法是最简单的方案,性能也一般。
- 对内循环没优化。例如有这样一条SQL:
-- 连接用户表与订单表连接条件是 uid =ouser id
select * from user tl left join order t2 on tl.id = t2.user_id;
-- user表为驱动表order表为被驱动表
SNL的特点
- 简单粗暴容易理解,就是通过双层循环比较数据来获得结果
- 查询效率会非常慢假设A表有N行,B表有M行。SNL的开销如下:
- A 表扫描 1 次
- B 表扫描M次。
- 一共有 N个内循环,每个内循环要M次,一共有内循环 N*M次
2.Index Nested-Loop Join ( 索引嵌套循环连接)
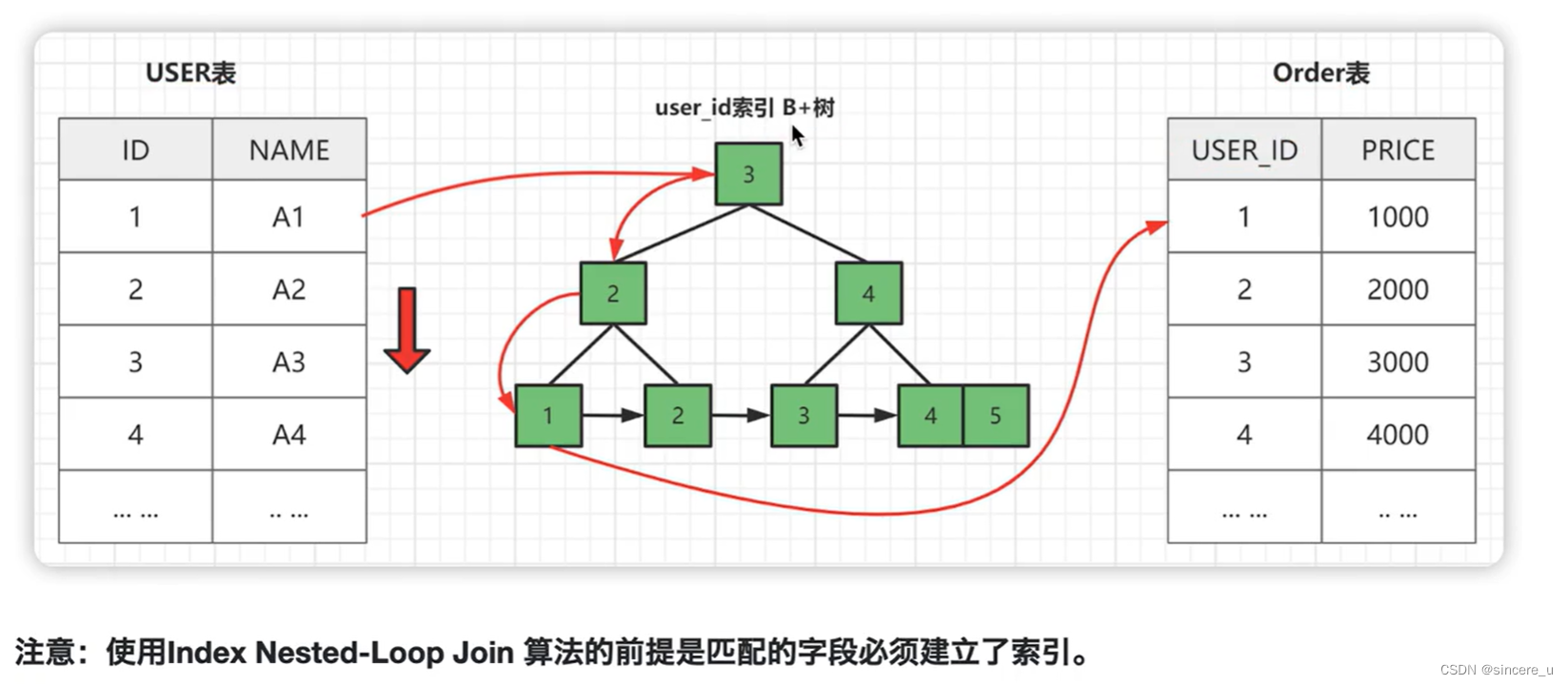
- Index Nested-Loop Join 其优化的思路: 主要是为了减少内层表数据的匹配次数,最大的区别在于,用来进行join的字段已经在被驱动表中建立了索引。
- 从原来的 匹配次数 = 外层表行数 x内层表行数,变成了匹配次数 外层表的行数x内层表索引的高度,极大的提升了join性能。
- 当order表的user_id为索引时,执行过程会如下图:
3. Block Nested-Loop Join( 块嵌套循环连接)
如果 join 的字段有索引,MySQL 会使用INL 算法。如果没有的话,MySQL 会如何处理?
因为不存在索引了,所以被驱动表需要进行扫描。这里 MySQL 并不会简单粗暴的应用SNL算法,而是加入了buffer 缓冲区,降低了内循环的个数,也就是被驱动表的扫描次数。
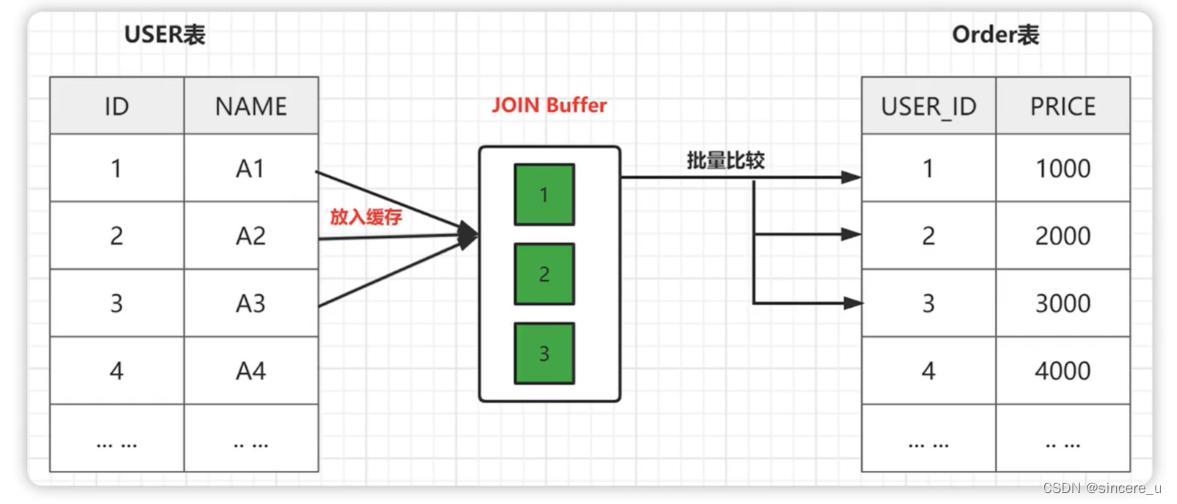
- 在外层循环扫描 user表中的所有记录。扫描的时候,会把需要进行 ioin 用到的列都缓存到 buffer 中。buffel中的数据有一个特点,里面的记录不需要一条一条地取出来和 order 表进行比较,而是整个 buffer 和 order表进行批量比较。
- 如果我们把 buffer 的空间开得很大,可以容纳下 user 表的所有记录,那么 order 表也只需要访问一次。
- MySQL默认 buffer 大小256K,如果有n个ioin 操作,会生成n-1 个ioin buffer。
JOIN优化总结
- 1.永用小结果集驱动大结果集(其本质就是减少外层循环的数据数量)
- 2.为匹配的条件增加索引(减少内层表的循环匹配次数)
- 3.增大ioin buffer size的大小(一次缓存的数据越多,那么内层包的扫表次数就越少)
- 4.减少不必要的字段查询(字段越少,join buffer 所缓存的数据就越多)
在这些优化方法中:
- BKA 优化是 MySQL 已经内置支持的,建议你默认使用;
- BNL 算法效率低,建议你都尽量转成 BKA 算法。优化的方向就是给被驱动表的关联字段加上索引;
- 基于临时表的改进方案,对于能够提前过滤出小数据的 join 语句来说,效果还是很好的;
- MySQL 目前的版本还不支持 hash join,但你可以配合应用端自己模拟出来,理论上效果要好于临时表的方案。

















 784
784



 到【灌水乐园】发言
到【灌水乐园】发言








