




 本文详细介绍了Elasticsearch的核心概念,包括其分布式、实时搜索的特点,RESTful API的使用,以及与传统数据库的区别。讨论了Elasticsearch的节点、集群、文档、索引等关键概念,并探讨了数据类型和元数据。此外,文章还概述了Elasticsearch的架构和交互方式。
本文详细介绍了Elasticsearch的核心概念,包括其分布式、实时搜索的特点,RESTful API的使用,以及与传统数据库的区别。讨论了Elasticsearch的节点、集群、文档、索引等关键概念,并探讨了数据类型和元数据。此外,文章还概述了Elasticsearch的架构和交互方式。
Elasticsearch概念及特点
什么是Elasticsearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
总结来说,Elasticsearch是一个采用RESTful API 标准的高扩展性和高可用性的实时全文数据分析搜索工具。
Lucene是一个全文搜索的框架,它的作者是Hadoop的作者。
特点
- 分布式、可扩展、高可用性
- 实时搜索,实时分析
- 基于RESTful 标准
Elasticsearch涉及到的概念
- Node(节点):单个装有Elasticsearch服务并且提供故障转移和扩展的服务器。
- Cluster(集群):一个集群是由一个或多个node组织在一起的,共同分享整个数据并具有负载均衡功能,对外提供服务。
- Document(文档):一个文档是一个可被索引的基础信息单元。
- Index(索引):索引是一个拥有几分相似特征的文档的集合。每个index都有自己的mapping定义字段名和字段值
- Type(类型):一个索引中,可以定义一种或多种类型。
- Field(列):Filed是Elasticsearch中最小的单位,相当于数据的某一列。
- Shards(分片):Elasticsearch将索引分成若干份,每一部分都是一个shard。
- Replicas(复制):Replicas是索引一份或多分的拷贝。目的是保证高可用。
1、Elasticsearch节点都是对等关系,这样的优点就是去中心化。这样master节点只不过多了一个维护集群状态的功能。
2、Elasticsearch之所以要将Index分片,是因为可能存在Index的大小大于磁盘容量的情况。
Elasticsearch和传统的数据库对比
其实可以把 Elasticsearch 理解为是一种数据库,它和传统数据库比如 MySQL相比,对应关系如下:
| 关系型数据库mysql | 非关系型数据库Elasticsearch |
|---|---|
| 数据库 Database | 索引 Index |
| 表 table | 类型 Type |
| 行 row | 文档 Document |
| 列 Column | 字段 Field |
在6.0之前的版本中一个index下可能有多个type,但是在6.0之后的版本,不允许一个index下有多个type,并且将逐渐取消type概念。
Document的数据类型
Document其实是一个Json Object,由字段(Field)组成,常见的数据类型如下:
- 字符串:text,keyword
- 数值型:long、integer、short、byte、double、float、half_folat、scaled_float
- 布尔:boolean
- 日期:date
- 二进制:binary
- 范围类型:integer_range、float_range、long_range、double_range、date_range
每一个文档都有一个唯一的id标识,生成方式是:es自动生成或自行制定
Document元数据(MetaData)
元数据用于标注文档的相关信息:
_index:文档所在的索引名
_type:文档所在的类型名
_id:文档的唯一id
_uid:组合uid,由_type和_id组成(6.x中_type不再起作用,同_id一样)
_source:文档的原始json数据,可以从这里获取每个字段的内容
_all:整合所有字段内容到该字段,默认禁用
Elasticsearch架构
架构图
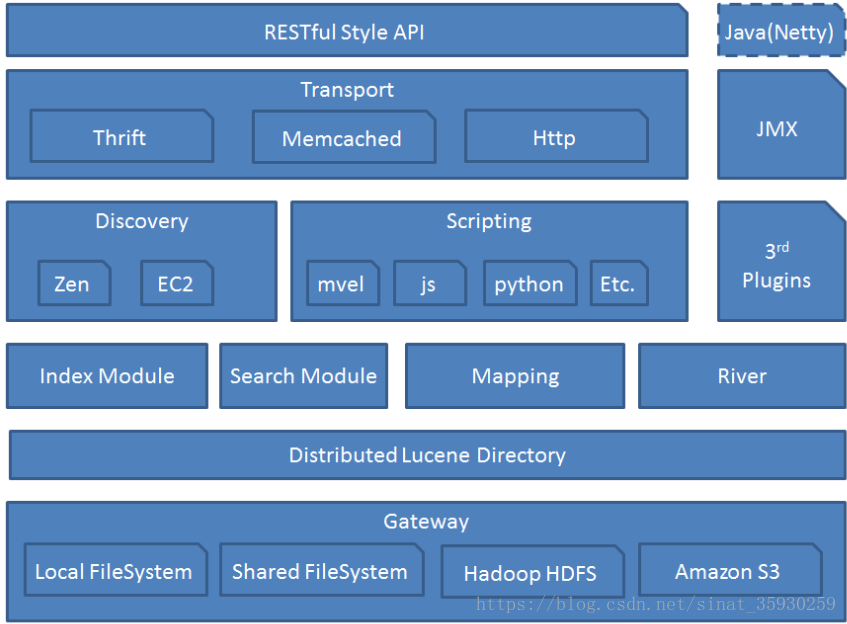
架构图解析
从下往上:
Gateway:用于存储es集群的元数据信息。这部分信息主要包括所有的索引连同索引设置和显式的mapping信息。集群元数据的每一次改变(比如增加删除索引等),这些信息都要通过gateway模块进行持久化。当集群第一次启动的时候,这些信息就会从gateway模块中读出并应用。
Distributed Lucence Directory:Lucence 框架
Index Module等:Elasticsearch 对数据的加工处理方式
Discovery:节点自动发现机制。当master节点故障,则通过选举产生新的master。基于P2P机制,首先通过广播寻找存在的节点,然后通过多播协议进行节点间通信。
Scripting:脚本执行功能,能很方便对查询出的数据进行加工处理。
3rd Plugins:支持第三方插件,比如中文分词,状态监控等
Transport:Elasticsearch 的交互方式,默认使用http协议传输
RESTful style API:RESTful 接口
Java:Elasticsearch 对Java支持度最好
RESTful
什么是RESTful
RESTful中文意思是表现层状态转化。
在RESTful架构中:每一个URI代表一种资源;客户端和服务器之间,传递这种资源的某种表现层;客户端通过四个HTTP动词,对服务器端资源进行操作,实现”表现层状态转化”。
通过URI指定资源,如Index,Document等。
通过Http Method指明资源操作类型,如GET POST PUT DELETE等。
交互方式
curl命令行方式
kibana DevTools
索引API
创建索引
PUT /text_index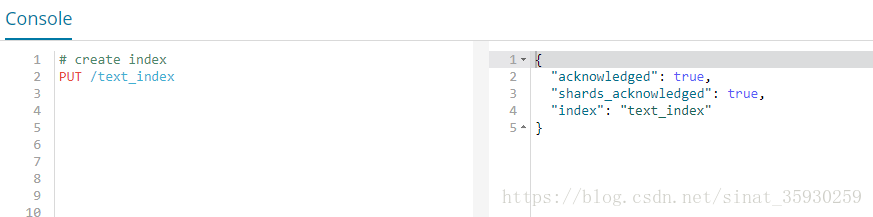
查看索引
GET _cat/indices
删除索引
DELETE /text_index
Document API
创建

当创建文档的时候索引不存在,es会自动创建。
也可以不指定id的方式创建文档:
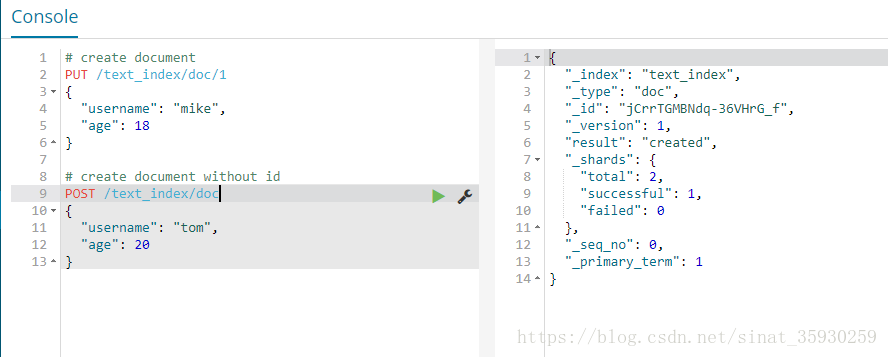
文档的id是es自动生成的。
查询
GET /text_index/doc/1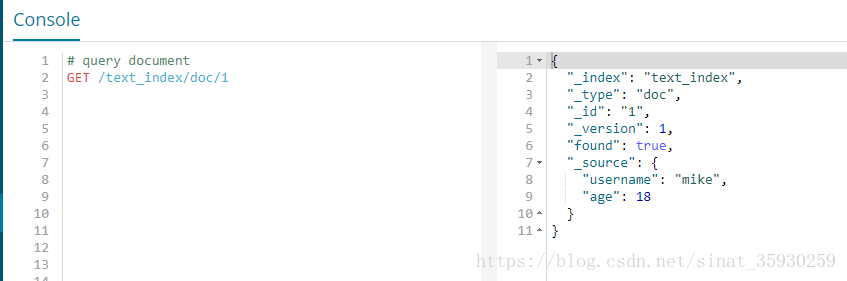
当查询文档不存在将返回false:

可以使用_search来进行索引下全文档的搜索
GET /text_index/doc/_search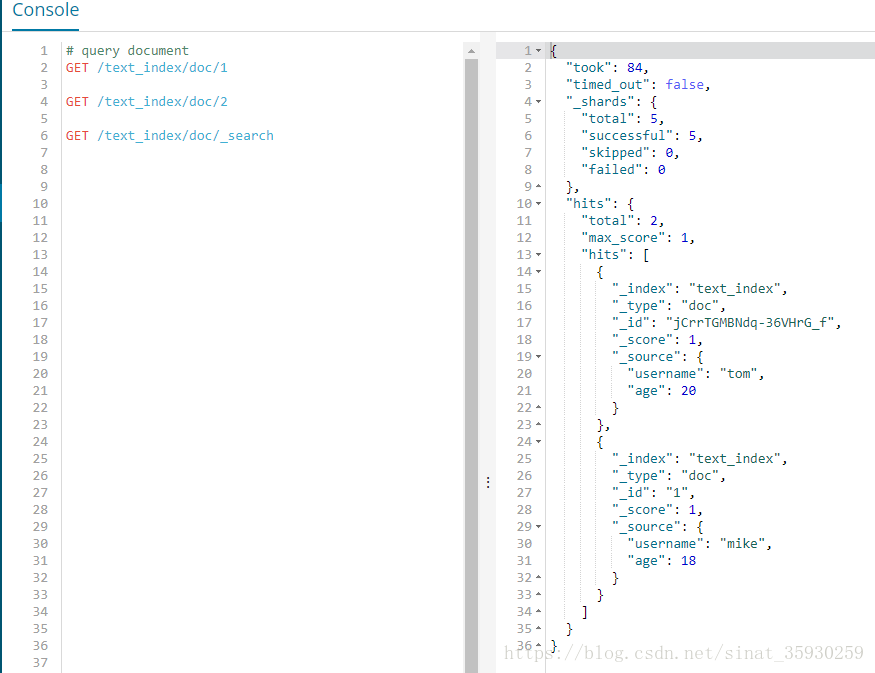
其中,took表示查询耗时,单位毫秒;total表示符合条件的文档数,hits表示返回文档详情数据数组,默认前十个文档;
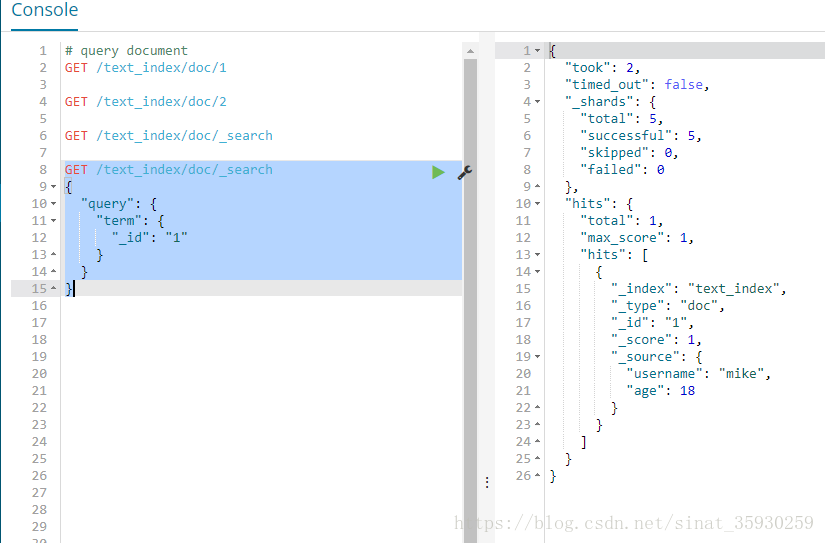
也可以在全文档搜索的时候加上限制条件:
GET /text_index/doc/_search
{
"query": {
"term": {
"_id": "1"
}
}
}
批量查询文档
批量创建文档可以减少网络传输的开销:
GET /_mget
{
"docs": [
{"_index": "text_index","_type": "doc","_id": "2"},
{"_index": "text_index","_type": "doc","_id": "1"}
]
}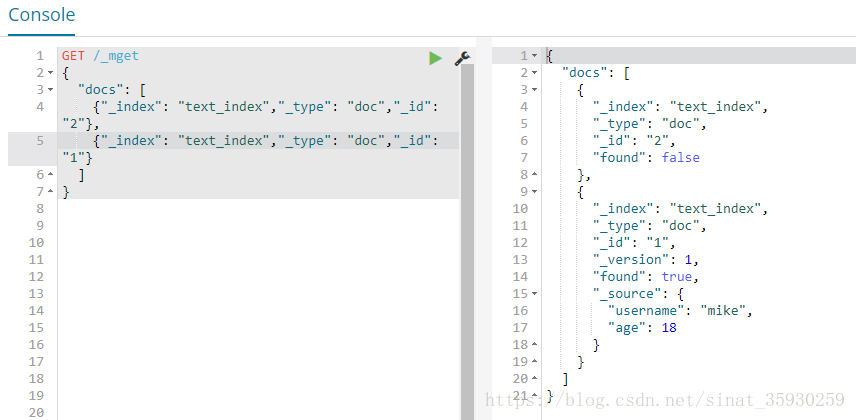
文档不存在则返回false

















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









