




 本文深入探讨循环神经网络(RNN),包括RNN的用途、符号表示、结构、反向传播以及不同类型的RNN架构,如Many-to-One、Many-to-Many等。还介绍了梯度消失问题、GRU和LSTM单元的作用,以及双向RNN的概念,为理解序列模型在自然语言处理等领域的应用打下基础。
本文深入探讨循环神经网络(RNN),包括RNN的用途、符号表示、结构、反向传播以及不同类型的RNN架构,如Many-to-One、Many-to-Many等。还介绍了梯度消失问题、GRU和LSTM单元的作用,以及双向RNN的概念,为理解序列模型在自然语言处理等领域的应用打下基础。
课程来源:吴恩达 深度学习课程 《序列模型》
笔记整理:王小草
时间:2018年4月28日
吴恩达的课程一直是我深爱喜绝的,深入浅出,10分钟可以讲完一个可能要一个小时或者半天理解的知识点,并且讲得老少都懂,男女皆晓。因此这次早起晚睡抽出时间来整理他课程的笔记,便于之后回顾与复习。
本文要介绍的是序列模型的第一课,将详细介绍序列模型RNN的结构,基础知识等。
1.什么要使用序列模型 Why sequence models
本教程要讲的是神经网络的序列模型RNN,全称Recurrent Neural Network Model,可翻译成循环神经网络,是神经网络的其中一种类型。那么它有什么用处呢?本节将简单介绍RNN在学术界与工业界的一些主要的应用。
1.1 RNN的用途:
简单地介绍下RNN目前最常用的应用场景:
(1)语音识别
(2)音乐生成
(3)情感分析
(4)DNA序列分析
(5)机器翻译
(6)视频行为识别
(7)命名实体识别

1.2 不同的应用场景,使用的模型也不同
比如有些场景下,输入与输出都是等长的序列;而有些场景下只是输入或输出为序列。等等许多应用需要具体问题具体问分析。
但无论如何,上面几个应用肯定有一些是你生活中已经享用到了,比如翻译,比如语音识别。也可以看出这些应用大多数是与语言有关。虽然业界对AI夸夸其谈者不胜枚举,但人工智能在自然语言上,尤其是中文自然语言上的成果,虽也可圈可点,但最多也只能给个中评都算勉强。而可以说RNN的确给垂死挣扎的自然语言患者带了一线生机,相信学术界与工业界共同的努力下,自然语言可以在深度学习中找到真命天子。
那么就从现在开始,学习RNN循环神经网络吧~
2.数学符号说明 Notation
上一节中,了解了序列模型广泛的应用,在进入深入学习之前,我们需要来定义一些数学符号,以方便接下去的课程中的表示与共识
1.开胃小栗子
假设有这样一句话:
X:Harry Potter and Hermoine Granger invented a new spell.
目的是想识别出句子中的实体词。所谓实体词包括人名, 地名,组织机构名称等等。
可见,输入的句子可以看成是单词的序列,那么我们期望的输出应是如下对应的输出:
Y:1 1 0 1 1 0 0 0 0
1代表的是“是实体”;0代表的是“非实体”
(当然,实际的命名实体识别比这输出要复杂得多,还需要表示实体词的结束位置与开始位置,在这个栗子中我们暂且选择以上这种简单的输出形式来讲解)
显而易见,输入的x与输出的y的序列个数一致,且索引位置相对应,我们用如下符号来表示输入与输出:

t表示第t时刻的输入;
Tx 表示样本x的序列长度;Ty 表示样本x输入模型后,输出序列的词长度,在本例中,输出与输出序列的长度相等,为9;
样本往往有很多个,用以下符号表示,第i个样本t时刻的输入与输出:

用以下符号表示第i个样本的输入序列的长度与输出序列的长度:

若换一个句子,句子有15个单词,则输入与输出的序列长度变为了5
2.2 representing words
上面讲了输入的序列是一句话中的单词,但是的但是,文字无法直接用于计算,预想将它表示称数字符号的形式。于是我们来讲一讲,如何来表示句子里的单词。
(1)首先,要建立一个词典,以List的形式存储,将语料中的所有单词去重后以一定的顺序放进list中。
如下是一个长度10000的词典(词典的长度是和你的语料有关的)

(2)然后,遍历你的样本,将每一个单词转换成词向量,比如,Harry在词典的索引为4075,则用一个长度为10000的词向量表示,这个词向量在4075的位置上为1,其他位置上都为0;同理其他每个词都一用这样一个向量来表示,如下图:

这样的词表示方法,我们叫独热编码one-hot
3.循环神经网络 Recurrent Neural Network Model
上一节了解了循环神经网络中的符号表示,这一节要正式揭开RNN神秘的面纱了:即学习构建模型,来实现输入x到输出y的映射。
3.1 Why not a standard network?
首先需要解释一个疑问,那就是为什么处理序列的问题,不能用标准的神经网络,或者卷积神经网络。有以下两个主要原因:
(1)不同的样本的输入与输出的序列长度是不同的。对于图片样本可以实现统一的像素大小作为输入,输出也是给定的,于是神经网络的输入层与输出层的神经元个数也是给定的;但对于文本,每次输入的句子长度都往往相异,因而输出的长度也相异。
(2)一般的神经网络不会对不同位置上的文本进行共享特征。意思是第一个单词Harry是人名,其特征影响第二个单词的预测,而若使用传统的神经网络,每个单词之间都不共享彼此的特征,丧失了序列上的特性。
3.2 What is the Recurrent Neural Networks
为什么叫循环神经网络呢?看了它的结构就明白了。
仍然使用这句话作为例子
X:Harry otter and Hermoine Granger invented a new spell.
首先将第一个词Harry作为第一个输入x,中间经过一堆隐藏层,然后输出y:

接着将第二个词Potter作为第二个输入, 通用经过相同的隐藏层结构,获得输出。但这次,输入不但来自于第二个单词Potter, 还有一个来自上一个单词隐藏层中出来的信息(一般叫做激活值)a作为输入:

同理,接着是输入第3个词and, 同样也会输入来自第二个词的激活值;以此类推,直到最后一个词:

另外,第一个单词前面也需要一个激活值,这个可以人为编造,可以是0向量,也可以是用一些方法随机初始化的值。

再一些论文中会出现以下形式表示RNN,但有点不简明易懂,因此本课程中采用以上的画法:

词一个一个输入的,可以看成每个时间输入一次,所有输入的隐藏层是共享参数的。设输入层到隐藏层到参数为wa_x,激活值到隐藏层到参数记为wa_a.
根据以上结构,显而易见,第一次输入的单词会通过激活值影响下一个单词的预测,甚至影响接下去的所有单词的预测,这就是循环神经网络。
但是有一个问题是,以上网络,只体现了前面的单词对后面的单词的影响,然而实际上序列的后面部分也会对前面部分有影响,比如以下例子:

第一句话中的Teddy是人名,第二句话中的Teddy是小熊,但两句话中的Teddy前面的信息都是一样的,我们需要读了后面的词之后才能分辨,因此后面的信息对前面的预测也是至关重要呢。
要解决这个问题很简单,在之后的课程中会介绍双向神经网络BRNN。
3.3 Forward Propagation
知道了RNN的结构,现在来详细学习其计算过程

a<0>是人为初始化的到的;
x<1>是t=1时刻的输入;
输入层的权重是Wax;
激活层的权重是Waa;
输出层的权重是Wy1;
要计算的是每个时刻的激活值a<t>与输出值y<t>
a<1>的计算:
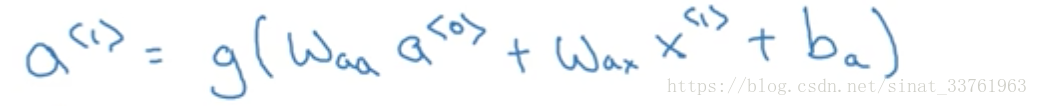
y<1&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2394
2394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









