




 本文详细介绍了传统IO读写操作的流程及存在的问题,并提出了零拷贝技术的两种实现方式:mmap+write和sendfile,以及Linux 2.4内核提供的gather优化方案。
本文详细介绍了传统IO读写操作的流程及存在的问题,并提出了零拷贝技术的两种实现方式:mmap+write和sendfile,以及Linux 2.4内核提供的gather优化方案。
传统读操作
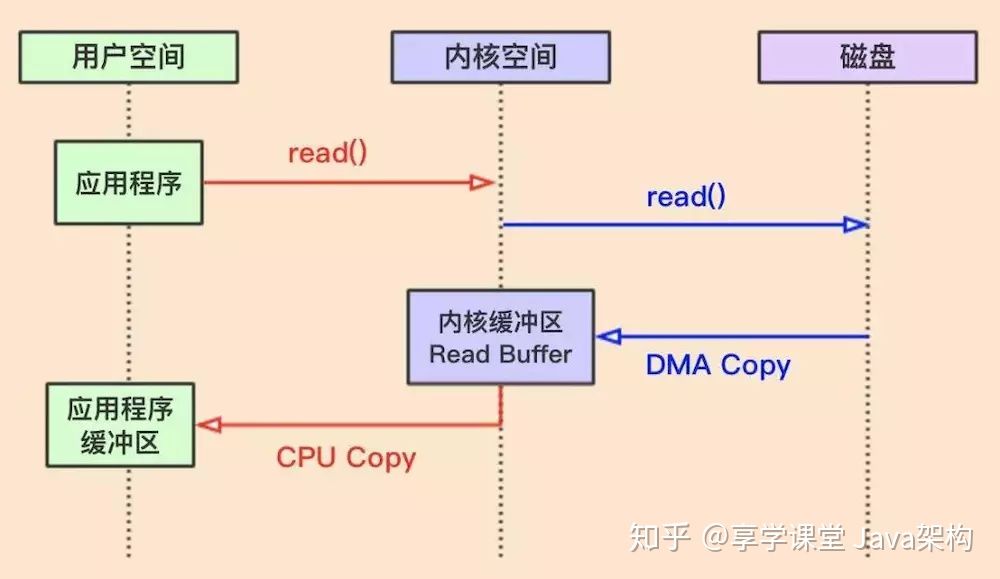
JAVA用传统方式进行读操作时,整体流程如上图,具体如下:
1、应用程序发起读数据操作,JVM会发起read()系统调用。
2、这时操作系统OS会进行一次上下文切换(把用户空间切换到内核空间)
3、通过磁盘控制器把数据copy到内核缓冲区中,这里的就发生了一次DMACopy
4、然后内核将数据copy到用户空间的应用缓冲区中,发生了一次CPU Copy
5、read调用返回后,会再进行一次上下文切换(把内核空间切换到用户空间)
我们看一下一个读操作,发了2次上下文切换,和2次数据copy,一次是DMA Copy,一次是CPU Copy。
注意一点的是 内核从磁盘上面读取数据 是 不消耗CPU时间的,是通过磁盘控制器完成;称之为DMA Copy。
传统写操作
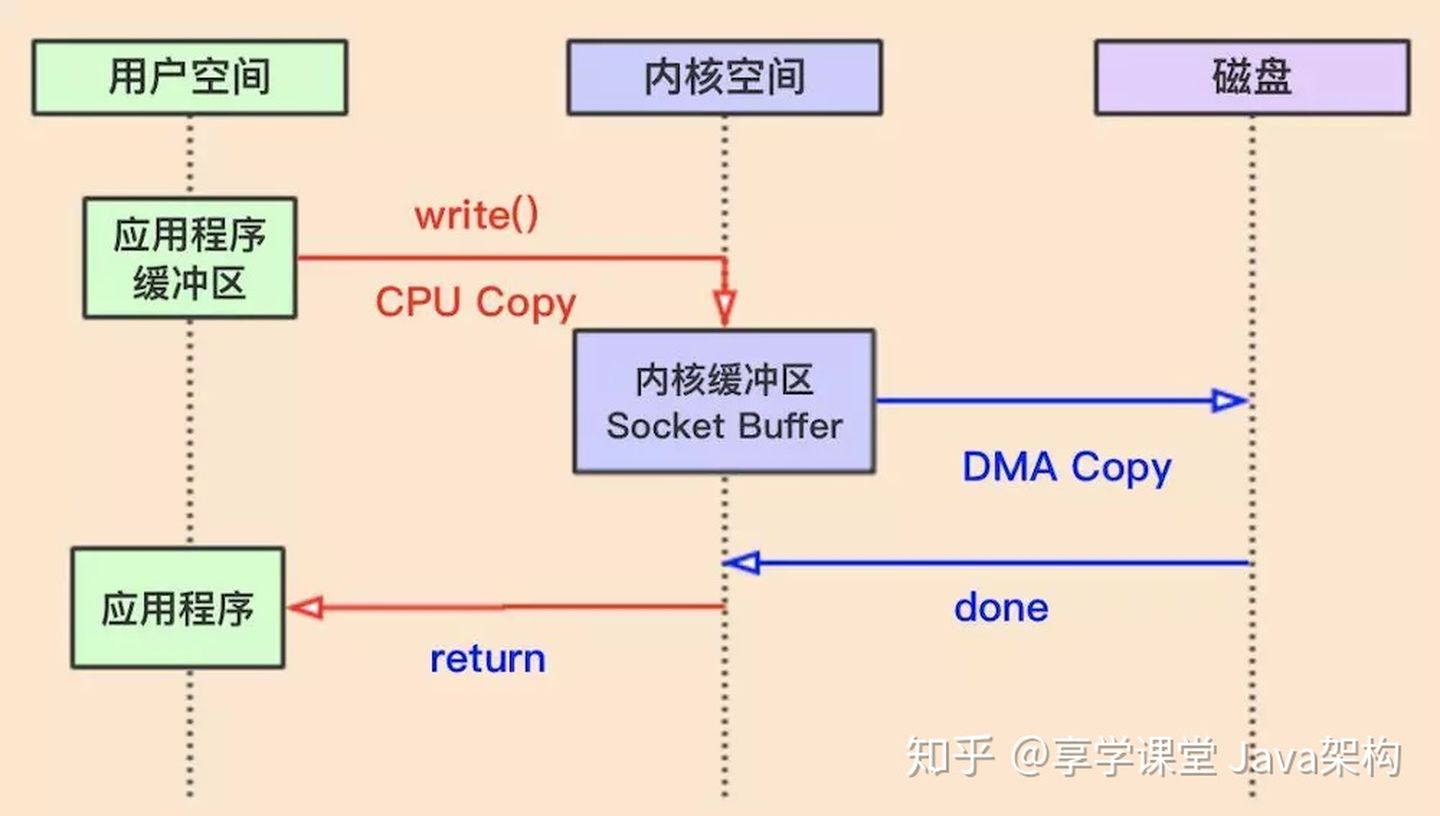
上图是JAVA传统的写操作,具体流程:
1、应用发起写操作,OS进行一次上下文切换(从用户空间切换为内核空间)
2、并且把数据copy到内核缓冲区Socket Buffer,做了一次CPU Copy
3、内核空间再把数据copy到磁盘或其他存储(网卡,进行网络传输),进行了DMA Copy
4、写入结束后返回,又从内核空间切换到用户空间
传统IO
我们可以看出传统的IO读写操作,总共进行了4次上下文切换,4次Copy动作。我们可以看到数据在内核空间和应用空间之间来回复制,其实他们什么都没有做,就是复制而已,这个机制太浪费时间了,而且是浪费的CPU的时间。
那我们能不能让数据不要来回复制呢?零拷贝这个技术就是来解决这个问题。关于零拷贝提供了两种解决方式:mmap+write方式、sendfile方式
虚拟内存
所有现代操作系统都使用虚拟内存,使用虚拟地址取代物理地址,这样做的好处就是:
1、多个虚拟内存可以指向同一个物理地址
2、虚拟内存空间可以远远大于物理内存空间
我们利用第一条特性可以优化一下上面的设计思路,就是把内核空间和用户空间的虚拟地址映射到同一个物理地址,这样就不需要来回复制了,看图:
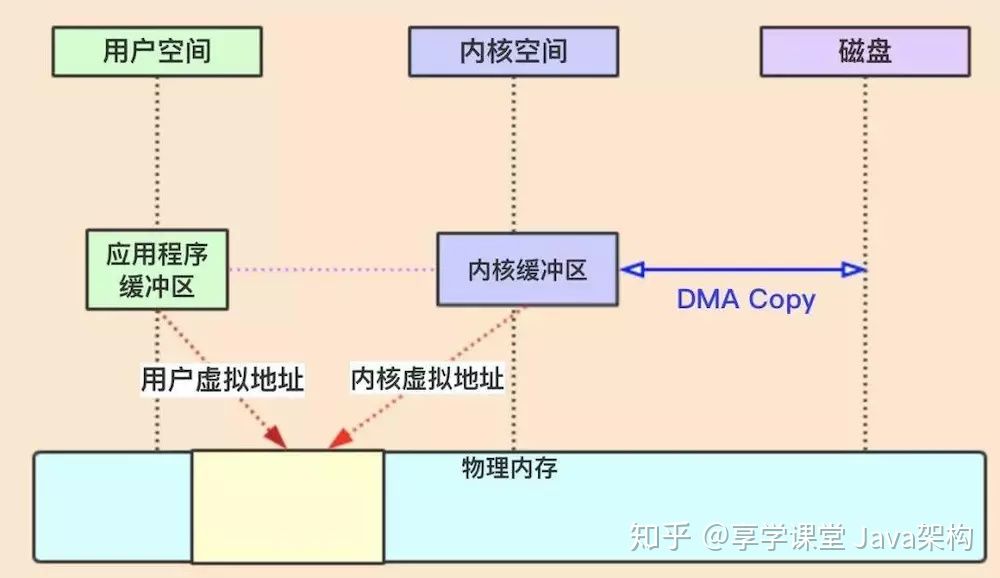
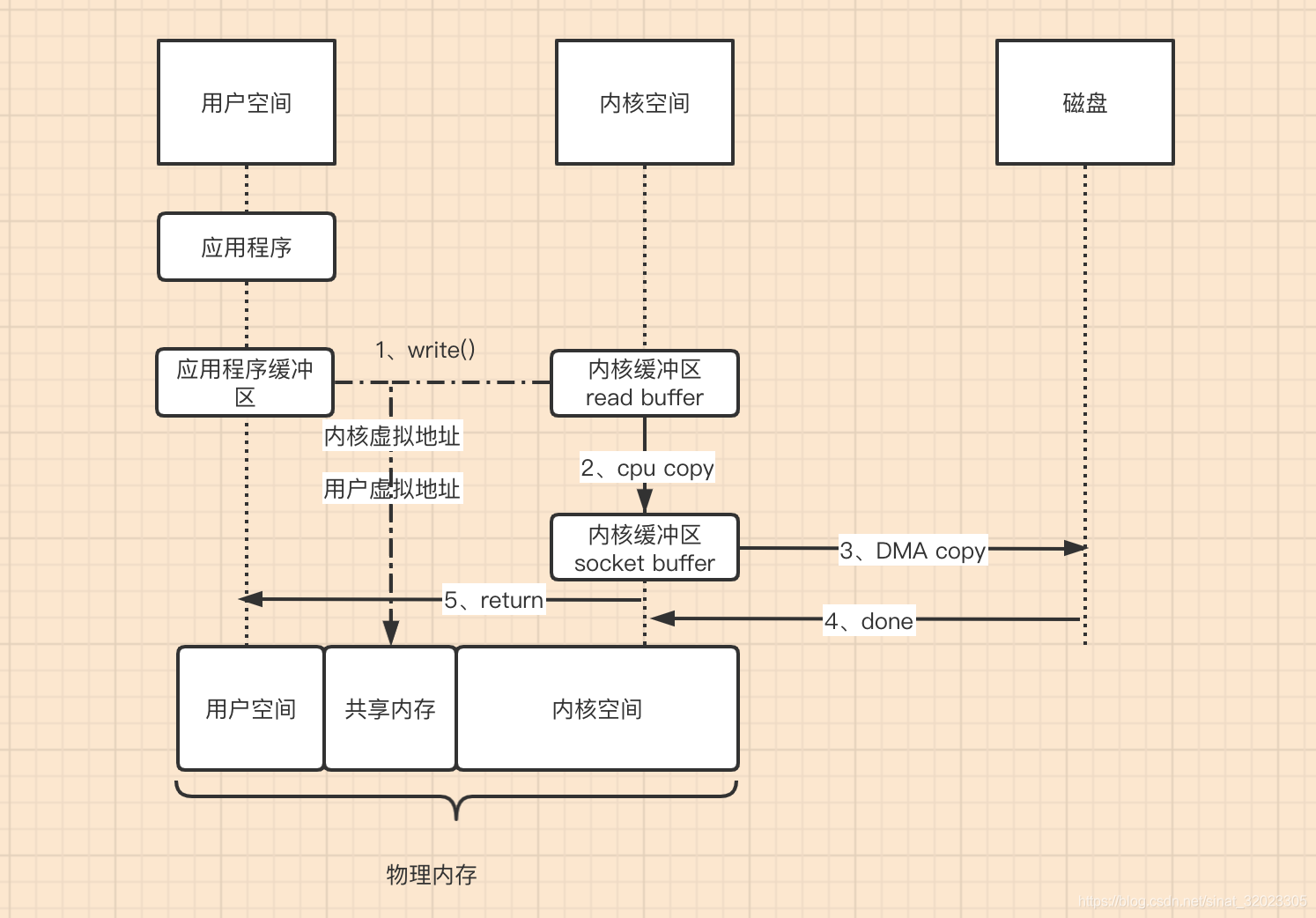
mmap+write方式
使用mmap+write方式替换原来的传统IO方式,就是利用了虚拟内存的特性,看图
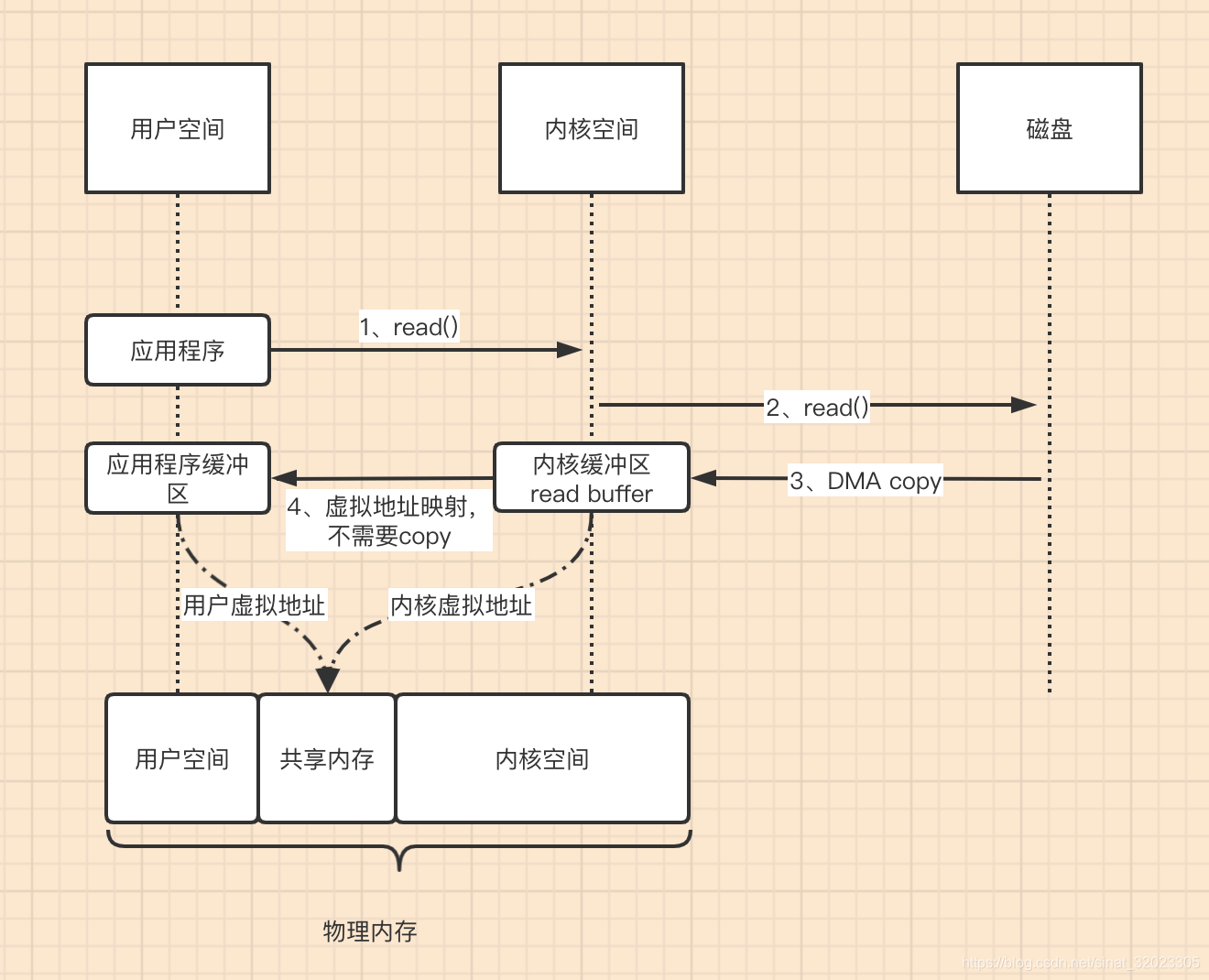
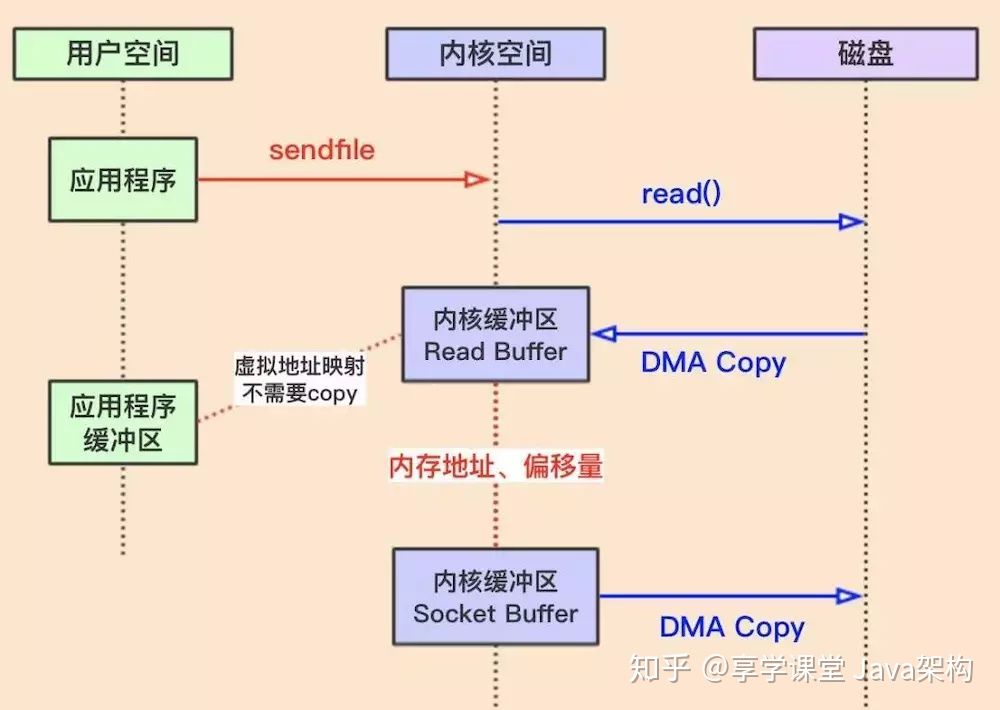
mmap读流程
mmap写流程
整体流程的核心区别就是,把数据读取到内核缓冲区后,应用程序进行写入操作时,直接是把内核的Read Buffer的数据复制到 Socket Buffer 以便进行写入,这次内核之间的复制也是需要CPU参与的。
注意:最后把Socket Buffer数据拷贝到很多地方,统称protocol engine(协议引擎)
这个流程就少了一个CPU Copy,提升了IO的速度。不过发现上下文的切换还是4次,没有减少,因为还是要应用程序发起write操作。那能不能减少上下文切换呢?
sendfile方式
这种方式可以替换上面的mmap+write方式,如:
mmap();
write();
替换为
sendfile();
这样就减少了一次上下文切换,因为少了一个应用程序发起write操作,直接发起sendfile操作。
到这里就只有3次Copy,其中只有1次CPU Copy;3次上下文切换。那能不能把CPU Copy减少到没有呢?
gather
Linux2.4内核进行了优化,提供了gather操作,这个操作可以把最后一次CPU Copy去除,什么原理呢?就是在内核空间Read Buffer和Socket Buffer不做数据复制,而是将Read Buffer的内存地址、偏移量记录到相应的Socket Buffer中,这样就不需要复制(其实本质就是和虚拟内存的解决方法思路一样,就是内存地址的记录),如图:

















 2006
2006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









