



 本文详细介绍了Hadoop分布式文件系统(HDFS)的工作原理,包括NameNode、DataNode和SecondaryNameNode的角色职责,以及MapReduce计算框架的运作流程,帮助读者理解大数据处理的基本架构。
本文详细介绍了Hadoop分布式文件系统(HDFS)的工作原理,包括NameNode、DataNode和SecondaryNameNode的角色职责,以及MapReduce计算框架的运作流程,帮助读者理解大数据处理的基本架构。
总体情况
HDFS 分布式文件系统
NameNode:属于管理层用于管理数据的存储,是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等。
SecondaryNameNode:也属于管理层,辅助NameNode进行管理,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
DataNode:属于应用层,用户进行数据的存储,被NameNode进行管理,要定是的向NameNode进行汇报,执行NameNode分配分发的任务。在本地文件系统存储文件块数据,以及块数据的校验和。
MapReduce:分布式的并行计算框架
JobTracker:属于管理层,管理集群资源和对任务进行资源调度,监控人去执行。负责接收用户提交的作业,负责启动、跟踪任务执行。
TaskTracker:属于应用层,执行JobTracker分配分发的任务,并向JobTracker汇报工作情况。管理各个任务在每个节点上的执行情况。
Hadoop 安装模式
1、本地模式,即单击模式
2、伪分布式模式,一台机器上运行所有的hadoop服务(五个守护进程)
3、完全分布式模式,一台机器一个hadoop
日志格式
日志格式分为以.log和.out两种。
1、以.log结尾的日志
通过log4j日志记录格式进行记录日志,采用的日常滚动文件后缀策略来命名日志文件,内容比较全
2、以.out结尾的日志
记录标准输出和标准错误的日志,内容比较少,默认的情况,系统保留最新的5个日志文件
3、日志的文件存储位置,用户可以自定义区配置:在$HADOOP_HOME/conf/hadoop-env.sh下配置
4、 日志名称意义:hadoop(框架名称)-hadoop(启动守护进程的用户名)-datanode(守护进程名)-hadoop-master(运行守护进行的名称).log
hadoop启动停止的三种方式
1)第一种
分别启动HDFS和mapReduce,命令如下
启动:
start-dfs.sh
start-mapared.sh
停止:
stop-dfs.hs
stop-mapred.sh
2)第二种
全部启动和全部停止
启动:
start-all.sh
启动顺序:NameNode、 DataNode、 SecondaryNameNode 、 JobTracker、 TraskTracker
停止:
stop-all.sh
停止顺序:JobTracker、 TaskTracker、 NameNode、 DataNode 、SecondaryNameNode
3)第三种
每个守护进程逐一启动,启动顺序如下:
NameNode、DataNode SecondaryNameNode JobTracker TaskTracker
命令如下
启动:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start jobtracker
hadoop-daemon.sh start tasktracker
停止:
hadoop-daemon.sh stop jobtracker
hadoop-daemon.sh stop tasktracker
HDFS文件结构
文件结构图
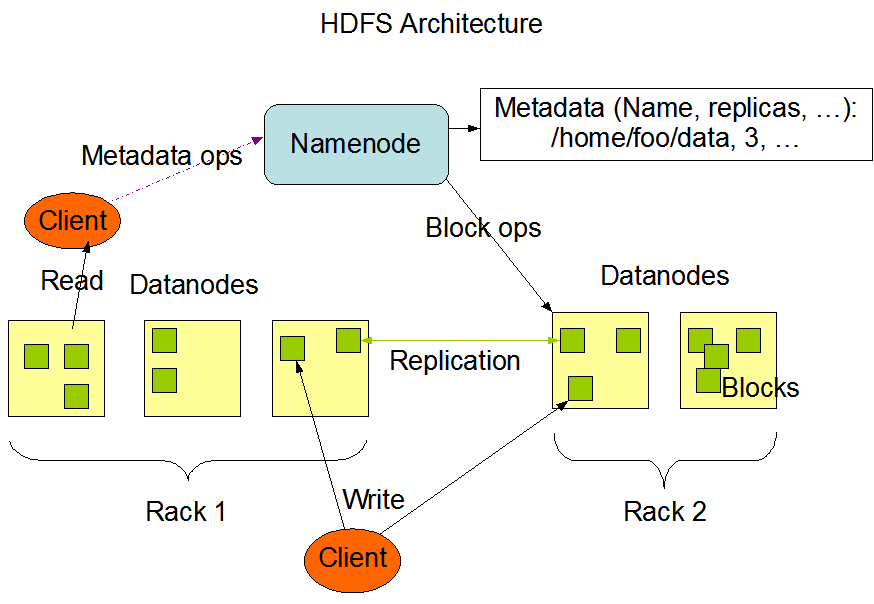
HDFS-文件
A、 文件切分称块(默认大小64M),以块为单位,每个块有多个副本存储在不同的机器上,副本书可在文件生成的时候制定,默认为3份
B、NameNode是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件所在的块列表及块所在的DataNode等
C、DataNode在本地文件系统存储文件块数据,以及块数据对应的校验和。
D、可以创建、删除、移动、重命名文件,当文件创建写入和关闭后不能修改文件内容。
NameNode
A、NameNode是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间及客户端对文件的访问
B、文件操作,NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过NameNode,只会询问它跟哪个DataNode联系,否则NameNode会成为系统的瓶颈
C、副本存放在哪个DataNode由NameNode决定,根据全局情况决定放置块位置,读取文件是NameNode会尽量读取最近的副本,降低带块消耗和读取延时。
D、NameNode全权管理数据块的复制,他周期性地从集群中接受DataNode的心跳和块状态报告(BlockReport),接收到心跳信号意味着该DataNOde正常工作,块状态报告包含了一个该DataNode上所有数据块的列表。
DataNode
A、一个数据块在DataNode上以文件形式存放在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳
B、DataNode启动后向NameNode注册,通过后,周期性的向NameNode汇报所有块的信息
C、心跳每3秒一次,心跳返回结果带有NameNode给该DataNOde的命令如复制块数据到另外一台机器上,或删除某个数据块,如果超过10分钟没有收到某个DataNode的心跳信息,则认为此DataNode不可用了。
D、集群运行中可以安全加入和退出一些机器。
HDFS-保障可靠性的措施
文件损坏处理:一个是用CRC32校验另外一个是用其他副本取代损坏文件
网络或者机器实效处理:DataNode定期向NameNode送HeartBeat
NameNode挂掉:FSImage(文件系统镜像)、EditLog(操作日志) 另外一个是多份存储,当NameNode损坏后可以手动还原。
数据损坏处理
1、当DataNode读取block的时候,他会计算checkSum
2、如果计算后的checknum,与block创建时不一致,说明该block已经损坏
3、client读取其他DN上的block
4、NameNode标记该块数据已经损坏,然后复制block达到预期设置的备份数
5、dataNode在其文件创建后三周验证其checksum。
MapReduce离线分布式计算
MapReduce编程模型
1、一种分布式计算模型框架,解决海量数据的计算问题
2、MapReduce将整个并行计算过程抽象到两个函数
A、Map(映射):对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行
B、Reduce(化简):对一个列表的元素进行合并
3、一个简单的MapReduce程序执行指定map()、reduce()、input和output,剩下的事由框架完成
MapReduce相关概念
1、JobTracker负责接收用户提交的作业,负责启动、跟踪任务执行情况。
2、TaskTracker负责执行有JobTracker分配的任务,管理各个任务在每个节点上的执行情况
3、Job,用户的每一个计算请求,称为一个作业
4、Task,每一个作业,都需要拆分开,交由多个服务器来完成,拆分出来的执行单位,就称为任务
5、Task分为MapTask和ReduceTask两种,分别进行Map操作和Reduce操作,依据Job设置的Map类和Reduce类。
Map Task
1、Map引擎
2、解析每条数据记录,传递给用户编写的map()
3、将Map()输出数据写入本地磁盘(如果是map-only作业,则直接写入HDFS)
Reduce Task
1、从Map Task上远程读取输入数据,
2、对数据排序
3、强数据按照分组传递给用户编写的reduce()
MapReduce 执行流程
Map任务处理
A、读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对,每一个键值对调用一次map函数
B、写自己的逻辑,对输入的key、value处理,转换成新的key、value输出
C、对输出的key、value进行分区
D、对不同分区的数据,按照key进行排序、分组、相同key的value放到一个集合中
E、分组后的数据进行归约
Reduce任务处理
A、对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点
B、对多个Map任务的输出进行合并,排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出
C、把reduce的输出保存到文件中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









